Vertex AI 모델은 기본적으로 자체 가상 머신(VM) 인스턴스에 배포됩니다. Vertex AI는 동일한 VM에서 모델을 공동 호스팅하는 기능을 제공합니다. 이는 다음과 같은 이점이 있습니다.
- 여러 배포 간 리소스 공유
- 비용 효율적인 모델 서빙
- 향상된 메모리 및 컴퓨팅 리소스 사용률
이 가이드에서는 Vertex AI에서 여러 배포 간에 리소스를 공유하는 방법을 설명합니다.
개요
모델 공동 호스팅 지원에는 단일 VM 내에서 리소스를 공유하는 모델 배포를 그룹화하는 DeploymentResourcePool 개념이 도입되었습니다. 여러 엔드포인트를 DeploymentResourcePool 내에서 동일한 VM에 배포할 수 있습니다. 각 엔드포인트에는 하나 이상의 배포된 모델이 있습니다. 지정된 엔드포인트의 배포된 모델을 동일한 또는 다른 DeploymentResourcePool에 그룹화할 수 있습니다.
다음 예시에는 4개 모델과 2개 엔드포인트가 있습니다.
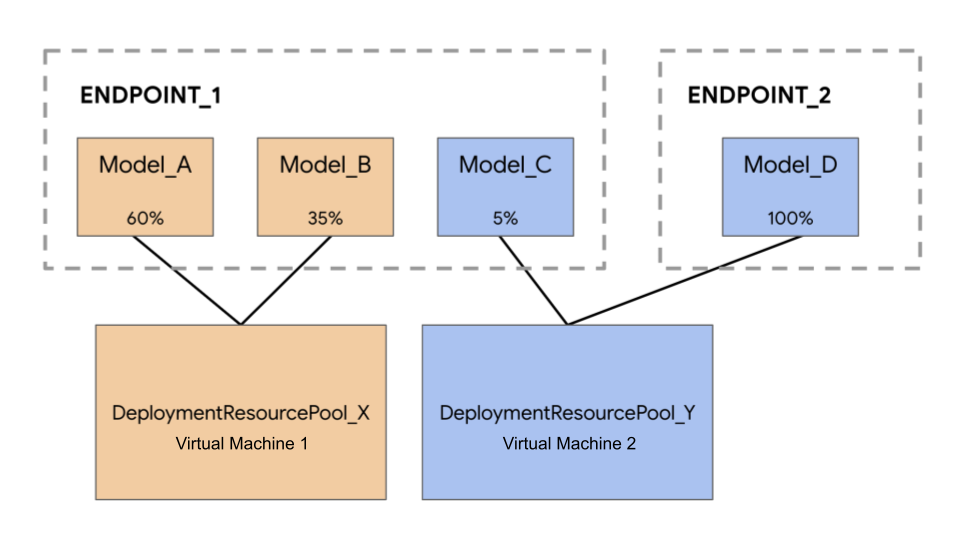
Model_A, Model_B, Model_C는 트래픽이 모두 라우팅된 상태로 Endpoint_1에 배포됩니다. Model_D는 Endpoint_2에 배포되어 이 엔드포인트의 트래픽을 100% 수신합니다.
각 모델을 별도의 VM에 할당하는 대신 다음 방법 중 하나로 모델을 그룹화할 수 있습니다.
Model_A및Model_B를 그룹화하여 VM을 공유하면DeploymentResourcePool_X의 일부가 됩니다.Model_C및Model_D(현재는 같은 엔드포인트에 없음)를 그룹화하여 VM을 공유하여DeploymentResourcePool_Y의 일부로 만듭니다.
다른 배포 리소스 풀은 VM을 공유할 수 없습니다.
고려사항
단일 배포 리소스 풀에 배포할 수 있는 모델 수에는 상위 한도가 없습니다. 이는 선택한 VM 모양, 모델 크기, 트래픽 패턴에 따라 달라집니다. 공동 호스팅은 희소 트래픽을 포함하는 배포된 모델이 많을 때 잘 작동합니다. 따라서 전용 머신을 각 배포된 모델에 할당해도 리소스가 효과적으로 사용되지 않습니다.
모델을 동일한 배포 리소스 풀에 동시에 배포할 수 있습니다. 하지만 동시 배포 요청은 한 번에 20개로 제한됩니다.
비어 있는 배포 리소스 풀은 리소스 할당량을 소비하지 않습니다. 리소스는 첫 번째 모델이 배포될 때 배포 리소스 풀에 프로비저닝되고 마지막 모델이 배포 해제될 때 프로비저닝 해제됩니다.
단일 배포 리소스 풀의 모델은 서로 격리되지 않으며 CPU 및 메모리 경쟁이 발생할 수 있습니다. 다른 모델이 동시에 추론 요청을 처리하는 경우 한 모델의 성능이 저하될 수 있습니다.
제한사항
리소스 공유를 사용 설정하여 모델을 배포할 때는 다음과 같은 제한사항이 있습니다.
- 이 기능은 다음 구성에서만 지원됩니다.
- TensorFlow용 사전 빌드된 컨테이너를 사용하는 TensorFlow 모델 배포
- PyTorch용 사전 빌드된 컨테이너를 사용하는 PyTorch 모델 배포
- 다른 프레임워크용으로 구성된 사전 빌드된 컨테이너는 지원되지 않습니다.
- 맞춤 컨테이너는 지원되지 않습니다.
- 커스텀 학습 모델 및 가져온 모델만 지원됩니다. AutoML 모델은 지원되지 않습니다.
- TensorFlow 또는 PyTorch용 추론을 위한 Vertex AI 사전 빌드된 컨테이너의 동일한 컨테이너 이미지(프레임워크 버전 포함)가 있는 모델만 동일한 배포 리소스 풀에 배포할 수 있습니다.
- Vertex Explainable AI는 지원되지 않습니다.
모델 배포
DeploymentResourcePool에 모델을 배포하려면 다음 단계를 완료합니다.
- 필요한 경우 배포 리소스 풀을 만듭니다.
- 필요한 경우 엔드포인트를 만듭니다.
- 엔드포인트 ID를 검색합니다.
- 배포 리소스 풀의 엔드포인트에 모델을 배포합니다.
배포 리소스 풀 만들기
기존 DeploymentResourcePool에 모델을 배포하는 경우 이 단계를 건너뜁니다.
CreateDeploymentResourcePool을 사용하여 리소스 풀을 만듭니다.
Cloud Console
Google Cloud 콘솔에서 Vertex AI 배포 리소스 풀 페이지로 이동합니다.
만들기를 클릭하고 양식을 작성합니다(아래 참조).

REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION_ID: Vertex AI를 사용하는 리전입니다.
- PROJECT_ID: 프로젝트 ID입니다.
-
MACHINE_TYPE: 선택사항. 이 배포의 각 노드에 사용되는 머신 리소스. 기본 설정은
n1-standard-2입니다. 머신 유형에 대해 자세히 알아보세요. - ACCELERATOR_TYPE: 머신에 연결할 가속기 유형. ACCELERATOR_COUNT가 지정되지 않았거나 0인 경우 선택사항입니다. GPU가 아닌 이미지를 사용하는 AutoML 모델 또는 커스텀 학습 모델에 사용하지 않는 것이 좋습니다. 자세히 알아보기
- ACCELERATOR_COUNT: 사용할 각 복제본의 가속기 수. (선택사항) GPU가 아닌 이미지를 사용하는 AutoML 모델 또는 커스텀 학습 모델의 경우 0이거나 지정되지 않은 상태여야 합니다.
- MIN_REPLICA_COUNT: 이 배포의 최소 노드 수. 추론 로드 시 필요에 따라 노드 수를 최대 노드 수까지 늘리거나 이 노드 수까지 줄일 수 있습니다. 값은 1 이상이어야 합니다.
- MAX_REPLICA_COUNT: 이 배포의 최대 노드 수. 추론 로드 시 필요에 따라 노드 수를 이 노드 수까지 늘리거나 최소 노드 수까지 줄일 수 있습니다.
- REQUIRED_REPLICA_COUNT: 선택사항. 이 배포가 성공으로 표시되기 위해 필요한 노드 수입니다. 1 이상이고 최소 노드 수 이하여야 합니다. 지정하지 않으면 기본값은 최소 노드 수입니다.
-
DEPLOYMENT_RESOURCE_POOL_ID:
DeploymentResourcePool의 이름입니다. 최대 길이는 63자(영문 기준)이며 유효한 문자는 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/입니다.
HTTP 메서드 및 URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
JSON 요청 본문:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
응답에 "done": true가 포함될 때까지 작업 상태를 폴링할 수 있습니다.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
다음을 바꿉니다.
DEPLOYMENT_RESOURCE_POOL_ID:DeploymentResourcePool의 이름입니다. 최대 길이는 63자(영문 기준)이며 유효한 문자는 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/입니다.MACHINE_TYPE: 선택사항. 이 배포의 각 노드에 사용되는 머신 리소스입니다. 기본값은n1-standard-2입니다. 머신 유형에 대해 자세히 알아보세요.MIN_REPLICA_COUNT: 이 배포의 최소 노드 수입니다. 추론 로드 시 필요에 따라 노드 수를 최대 노드 수까지 늘리거나 이 노드 수까지 줄일 수 있습니다. 값은 1 이상이어야 합니다.MAX_REPLICA_COUNT: 이 배포의 최대 노드 수입니다. 추론 로드 시 필요에 따라 노드 수를 이 노드 수까지 늘리거나 최소 노드 수까지 줄일 수 있습니다.
엔드포인트 만들기
엔드포인트를 만들려면 gcloud CLI 또는 Vertex AI API를 사용하여 공개 엔드포인트 만들기를 참조하세요. 이 단계는 단일 모델 배포와 동일합니다.
엔드포인트 ID 검색
엔드포인트 ID를 검색하려면 gcloud CLI 또는 Vertex AI API를 사용하여 모델 배포를 참조하세요. 이 단계는 단일 모델 배포와 동일합니다.
배포 리소스 풀에 모델 배포
DeploymentResourcePool 및 엔드포인트를 만든 후 DeployModel API 메서드를 사용하여 배포할 수 있습니다. 이 프로세스는 단일 모델 배포와 비슷합니다. DeploymentResourcePool이 있으면 배포하는 DeploymentResourcePool의 리소스 이름으로 DeployModel의 shared_resources를 지정합니다.
Cloud Console
Google Cloud 콘솔에서 Vertex AI Model Registry 페이지로 이동합니다.
모델을 찾아 엔드포인트에 배포를 클릭합니다.
모델 설정(아래 참조)에서 공유 배포 리소스 풀에 배포를 선택합니다.

REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION_ID: Vertex AI를 사용하는 리전입니다.
- PROJECT: 프로젝트 ID입니다.
- ENDPOINT_ID: 엔드포인트의 ID입니다.
- MODEL_ID: 배포할 모델의 ID입니다.
-
DEPLOYED_MODEL_NAME:
DeployedModel의 이름입니다.DeployedModel의Model표시 이름도 사용할 수 있습니다. -
DEPLOYMENT_RESOURCE_POOL_ID:
DeploymentResourcePool의 이름입니다. 최대 길이는 63자(영문 기준)이며 유효한 문자는 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/입니다. - TRAFFIC_SPLIT_THIS_MODEL: 이 작업과 함께 배포되는 모델로 라우팅될 이 엔드포인트에 대한 예측 트래픽 비율입니다. 기본값은 100입니다. 모든 트래픽 비율의 합은 100이 되어야 합니다. 트래픽 분할에 대해 자세히 알아보기
- DEPLOYED_MODEL_ID_N: 선택사항. 다른 모델이 이 엔드포인트에 배포된 경우 모든 비율의 합이 100이 되도록 트래픽 분할 비율을 업데이트해야 합니다.
- TRAFFIC_SPLIT_MODEL_N: 배포된 모델 ID 키의 트래픽 분할 비율 값
- PROJECT_NUMBER: 프로젝트의 자동으로 생성된 프로젝트 번호
HTTP 메서드 및 URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
JSON 요청 본문:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
MODEL_ID를 배포할 모델의 ID로 바꿉니다.
동일한 배포 리소스 풀에 여러 모델을 배포하려면 동일한 공유 리소스를 가진 여러 모델에 대해 이전의 요청을 반복합니다.
추론 가져오기
Vertex AI에 배포된 다른 모델에서와 마찬가지로 DeploymentResourcePool의 모델로 추론 요청을 전송할 수 있습니다.