Cette page explique comment écrire, déployer et déclencher une exécution de pipeline à l'aide d'une fonction Cloud basée sur les événements avec un déclencheur Cloud Pub/Sub. Procédez comme suit :
Définissez un pipeline de ML à l'aide du SDK Kubeflow Pipelines (KFP) et compilez-le dans un fichier YAML.
Importez la définition du pipeline compilé dans un bucket Cloud Storage.
Utilisez les fonctions Cloud Run pour créer, configurer et déployer une fonction déclenchée par un sujet Pub/Sub nouveau ou existant.
Définir et compiler un pipeline
À l'aide du SDK Kubeflow Pipelines, créez un pipeline planifié et compilez-le dans un fichier YAML.
Échantillon hello-world-scheduled-pipeline :
from kfp import compiler
from kfp import dsl
# A simple component that prints and returns a greeting string
@dsl.component
def hello_world(message: str) -> str:
greeting_str = f'Hello, {message}'
print(greeting_str)
return greeting_str
# A simple pipeline that contains a single hello_world task
@dsl.pipeline(
name='hello-world-scheduled-pipeline')
def hello_world_scheduled_pipeline(greet_name: str):
hello_world_task = hello_world(greet_name)
# Compile the pipeline and generate a YAML file
compiler.Compiler().compile(pipeline_func=hello_world_scheduled_pipeline,
package_path='hello_world_scheduled_pipeline.yaml')
Importer le fichier YAML du pipeline compilé dans un bucket Cloud Storage
Ouvrez le navigateur Cloud Storage dans la Google Cloud console.
Cliquez sur le bucket Cloud Storage que vous avez créé lors de la configuration de votre projet.
À l'aide d'un dossier existant ou d'un nouveau dossier, importez le fichier YAML de votre pipeline compilé (dans cet exemple,
hello_world_scheduled_pipeline.yaml) dans le dossier sélectionné.Cliquez sur le fichier YAML importé pour accéder aux détails. Copiez l'URI gsutil pour une utilisation ultérieure.
Créer une fonction Cloud Run avec un déclencheur Pub/Sub
Accédez à la page Cloud Run Functions dans la console.
Cliquez sur le bouton Créer une fonction.
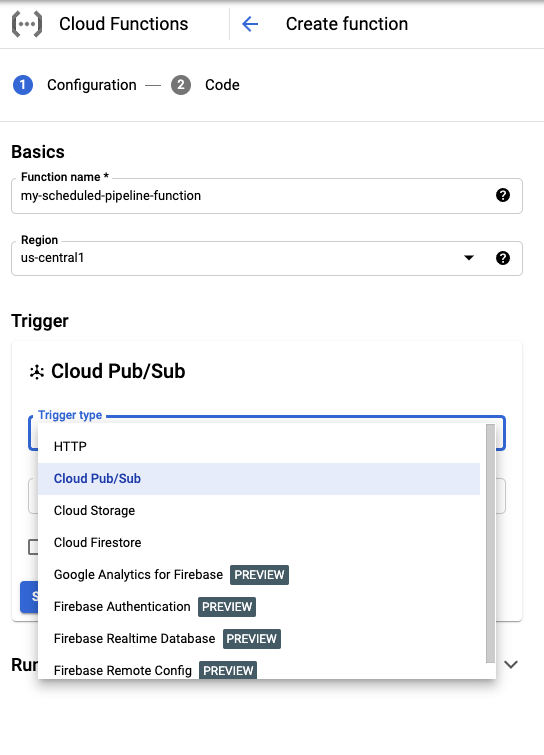
Dans la section Basics (Informations générales), attribuez un nom à votre fonction (par exemple,
my-scheduled-pipeline-function).Dans la section Trigger (Déclencheur), sélectionnez Cloud Pub/Sub comme type de déclencheur.
Dans la liste Sélectionner un sujet Cloud Pub/Sub, cliquez sur Créer un sujet.
Dans la zone Créer un sujet, attribuez un nom au nouveau sujet (par exemple,
my-scheduled-pipeline-topic), puis sélectionnez Créer un sujet.Laissez tous les autres champs par défaut et cliquez sur Save (Enregistrer) pour enregistrer la configuration de la section "Trigger" (Déclencheur).
Laissez tous les autres champs par défaut et cliquez sur Next (Suivant) pour passer à la section "Code".
Sous Environnement d'exécution, sélectionnez Python 3.7.
Dans Point d'entrée, saisissez "subscribe" (exemple de nom de fonction en tant que point d'entrée du code).
Sous Code source, sélectionnez Éditeur intégré, si ce n'est pas déjà fait.
Dans le fichier
main.py, ajoutez le code suivant :import base64 import json from google.cloud import aiplatform PROJECT_ID = 'your-project-id' # <---CHANGE THIS REGION = 'your-region' # <---CHANGE THIS PIPELINE_ROOT = 'your-cloud-storage-pipeline-root' # <---CHANGE THIS def subscribe(event, context): """Triggered from a message on a Cloud Pub/Sub topic. Args: event (dict): Event payload. context (google.cloud.functions.Context): Metadata for the event. """ # decode the event payload string payload_message = base64.b64decode(event['data']).decode('utf-8') # parse payload string into JSON object payload_json = json.loads(payload_message) # trigger pipeline run with payload trigger_pipeline_run(payload_json) def trigger_pipeline_run(payload_json): """Triggers a pipeline run Args: payload_json: expected in the following format: { "pipeline_spec_uri": "<path-to-your-compiled-pipeline>", "parameter_values": { "greet_name": "<any-greet-string>" } } """ pipeline_spec_uri = payload_json['pipeline_spec_uri'] parameter_values = payload_json['parameter_values'] # Create a PipelineJob using the compiled pipeline from pipeline_spec_uri aiplatform.init( project=PROJECT_ID, location=REGION, ) job = aiplatform.PipelineJob( display_name='hello-world-pipeline-cloud-function-invocation', template_path=pipeline_spec_uri, pipeline_root=PIPELINE_ROOT, enable_caching=False, parameter_values=parameter_values ) # Submit the PipelineJob job.submit()Remplacez les éléments suivants :
- PROJECT_ID : projet Google Cloud dans lequel ce pipeline s'exécute.
- REGION: région dans laquelle ce pipeline s'exécute.
- PIPELINE_ROOT : spécifiez un URI Cloud Storage auquel votre compte de service de pipelines peut accéder. Les artefacts des exécutions de votre pipeline sont stockés dans la racine du pipeline.
Dans le fichier
requirements.txt, remplacez le contenu par les conditions suivantes du package :google-api-python-client>=1.7.8,<2 google-cloud-aiplatformCliquez sur Déployer pour déployer la fonction.
Étapes suivantes
- En savoir plus sur Google Cloud Pub/Sub
- Visualiser et analyser les résultats du pipeline
- Découvrez comment créer des déclencheurs dans Cloud Run à partir d'événements Pub/Sub.
- Pour afficher des exemples de code d'utilisation de Pub/Sub, consultez l'exemple de navigateurGoogle Cloud .