En esta página se muestra cómo escribir, desplegar y activar una ejecución de flujo de procesamiento mediante una función de Cloud Functions basada en eventos con un activador de Cloud Pub/Sub. Sigue estos pasos:
Define un flujo de procesamiento de aprendizaje automático con el SDK de Kubeflow Pipelines (KFP) y compílalo en un archivo YAML.
Sube la definición de la canalización compilada a un segmento de Cloud Storage.
Usa funciones de Cloud Run para crear, configurar y desplegar una función que se active con un tema de Pub/Sub nuevo o ya creado.
Definir y compilar un flujo de procesamiento
Con el SDK de Kubeflow Pipelines, crea una canalización programada y compílala en un archivo YAML.
Ejemplo de hello-world-scheduled-pipeline:
from kfp import compiler
from kfp import dsl
# A simple component that prints and returns a greeting string
@dsl.component
def hello_world(message: str) -> str:
greeting_str = f'Hello, {message}'
print(greeting_str)
return greeting_str
# A simple pipeline that contains a single hello_world task
@dsl.pipeline(
name='hello-world-scheduled-pipeline')
def hello_world_scheduled_pipeline(greet_name: str):
hello_world_task = hello_world(greet_name)
# Compile the pipeline and generate a YAML file
compiler.Compiler().compile(pipeline_func=hello_world_scheduled_pipeline,
package_path='hello_world_scheduled_pipeline.yaml')
Subir el archivo YAML de la canalización compilada a un depósito de Cloud Storage
Abre el navegador de Cloud Storage en la Google Cloud consola
.Haga clic en el segmento de Cloud Storage que ha creado al configurar su proyecto.
Sube el archivo YAML de la canalización compilado (en este ejemplo,
hello_world_scheduled_pipeline.yaml) a una carpeta nueva o a una que ya tengas.Haga clic en el archivo YAML subido para acceder a los detalles. Copia el URI de gsutil para usarlo más adelante.
Crear funciones de Cloud Run con un activador de Pub/Sub
Ve a la página de Cloud Run Functions en la consola.
Haz clic en el botón Crear función.
En la sección Información básica, asigna un nombre a la función (por ejemplo,
my-scheduled-pipeline-function).En la sección Activador, selecciona Cloud Pub/Sub como tipo de activador.
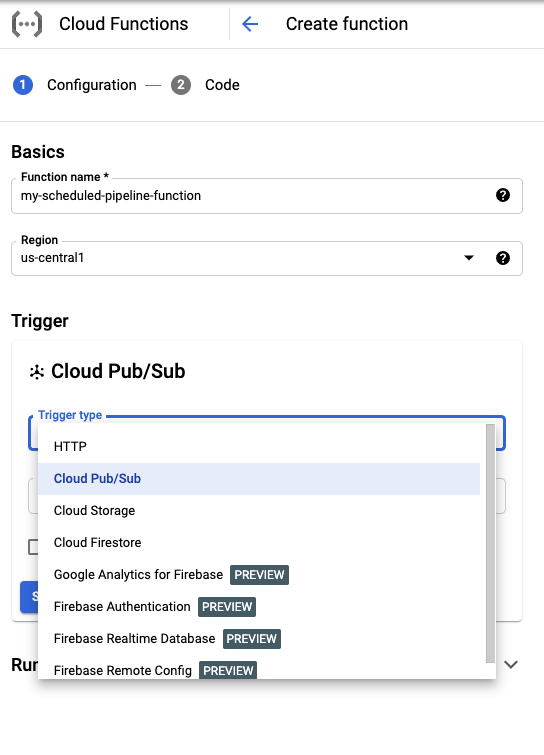
En la lista Seleccionar un tema de Cloud Pub/Sub, haz clic en Crear un tema.
En el cuadro Crear un tema, asigna un nombre al tema (por ejemplo,
my-scheduled-pipeline-topic) y selecciona Crear tema.Deje el resto de los campos con los valores predeterminados y haga clic en Guardar para guardar la configuración de la sección Activador.
Deja el resto de los campos con los valores predeterminados y haz clic en Siguiente para ir a la sección Código.
En Entorno de ejecución, selecciona Python 3.7.
En Punto de entrada, introduce "subscribe" (el nombre de la función del punto de entrada del código de ejemplo).
En Código fuente, selecciona Editor insertado si aún no lo has hecho.
En el archivo
main.py, añade el siguiente código:import base64 import json from google.cloud import aiplatform PROJECT_ID = 'your-project-id' # <---CHANGE THIS REGION = 'your-region' # <---CHANGE THIS PIPELINE_ROOT = 'your-cloud-storage-pipeline-root' # <---CHANGE THIS def subscribe(event, context): """Triggered from a message on a Cloud Pub/Sub topic. Args: event (dict): Event payload. context (google.cloud.functions.Context): Metadata for the event. """ # decode the event payload string payload_message = base64.b64decode(event['data']).decode('utf-8') # parse payload string into JSON object payload_json = json.loads(payload_message) # trigger pipeline run with payload trigger_pipeline_run(payload_json) def trigger_pipeline_run(payload_json): """Triggers a pipeline run Args: payload_json: expected in the following format: { "pipeline_spec_uri": "<path-to-your-compiled-pipeline>", "parameter_values": { "greet_name": "<any-greet-string>" } } """ pipeline_spec_uri = payload_json['pipeline_spec_uri'] parameter_values = payload_json['parameter_values'] # Create a PipelineJob using the compiled pipeline from pipeline_spec_uri aiplatform.init( project=PROJECT_ID, location=REGION, ) job = aiplatform.PipelineJob( display_name='hello-world-pipeline-cloud-function-invocation', template_path=pipeline_spec_uri, pipeline_root=PIPELINE_ROOT, enable_caching=False, parameter_values=parameter_values ) # Submit the PipelineJob job.submit()Haz los cambios siguientes:
- PROJECT_ID: el Google Cloud proyecto en el que se ejecuta esta canalización.
- REGION: la región en la que se ejecuta este flujo de procesamiento.
- PIPELINE_ROOT: especifica un URI de Cloud Storage al que pueda acceder la cuenta de servicio de tus canalizaciones. Los artefactos de las ejecuciones de tu flujo de procesamiento se almacenan en la raíz del flujo de procesamiento.
En el archivo
requirements.txt, sustituye el contenido por los siguientes requisitos del paquete:google-api-python-client>=1.7.8,<2 google-cloud-aiplatformHaz clic en Desplegar para desplegar la función.
Siguientes pasos
- Consulta más información sobre Google Cloud Pub/Sub.
- Visualiza y analiza los resultados del flujo de procesamiento.
- Consulta cómo crear activadores en Cloud Run a partir de eventos de Pub/Sub.
- Para ver ejemplos de código sobre cómo usar Pub/Sub, consulta el Google Cloud explorador de ejemplos.