O Ray é uma framework de código aberto para dimensionar aplicações de IA e Python. O Ray fornece a infraestrutura para realizar computação distribuída e processamento paralelo para o seu fluxo de trabalho de aprendizagem automática (AA).
Se já usa o Ray, pode usar o mesmo código de open source do Ray para escrever programas e desenvolver aplicações na Vertex AI com alterações mínimas. Em seguida, pode usar as integrações do Vertex AI com outros Google Cloud serviços, como a inferência do Vertex AI e o BigQuery, como parte do seu fluxo de trabalho de aprendizagem automática.
Se já usa o Vertex AI e precisa de uma forma mais simples de gerir recursos de computação, pode usar o código Ray para dimensionar a preparação.
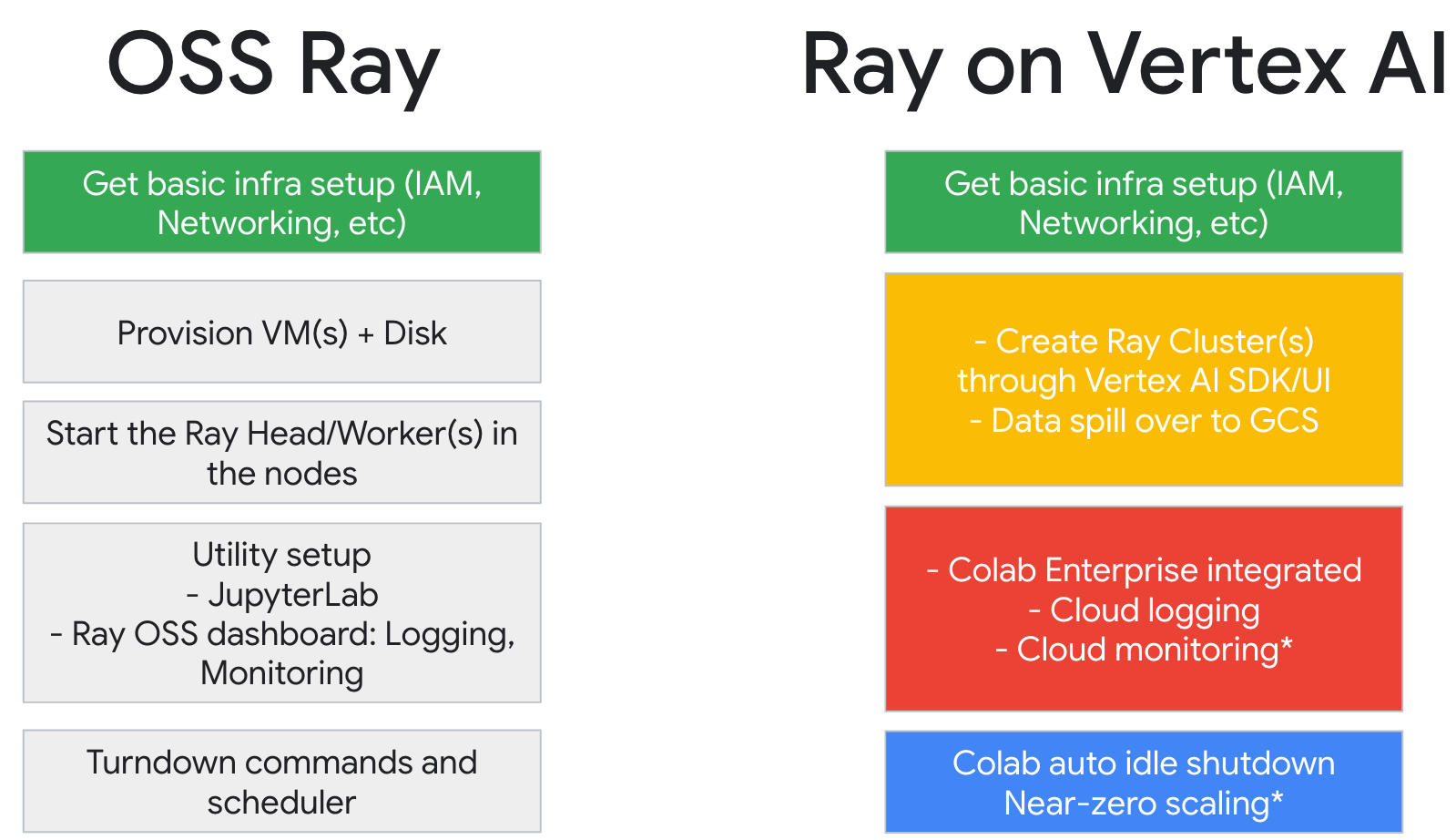
Fluxo de trabalho para usar o Ray no Vertex AI
Use o Colab Enterprise e o SDK Vertex AI para Python para se ligar ao cluster do Ray.
| Passos | Descrição |
|---|---|
| 1. Configuração do Ray no Vertex AI | Configure o seu projeto Google, instale a versão do SDK Vertex AI para Python que inclui a funcionalidade do Ray Client e configure uma rede de peering de VPC, que é opcional. |
| 2. Crie um cluster do Ray no Vertex AI | Crie um cluster do Ray na Vertex AI. É necessária a função de administrador do Vertex AI. |
| 3. Desenvolva uma aplicação Ray no Vertex AI | Estabeleça ligação a um cluster do Ray na Vertex AI e desenvolva uma aplicação. É necessária a função de utilizador do Vertex AI. |
| 4. (Opcional) Use o Ray na Vertex AI com o BigQuery | Ler, escrever e transformar dados com o BigQuery. |
| 5. (Opcional) Implemente um modelo no Vertex AI e obtenha inferências | Implemente um modelo num ponto final online do Vertex AI e obtenha inferências. |
| 6. Monitorize o seu cluster do Ray no Vertex AI | Monitorize os registos gerados no Cloud Logging e as métricas no Cloud Monitoring. |
| 7. Elimine um cluster do Ray no Vertex AI | Elimine um cluster do Ray no Vertex AI para evitar a faturação desnecessária. |
Vista geral
Os clusters do Ray estão incorporados para garantir a disponibilidade de capacidade para cargas de trabalho de ML críticas ou durante épocas de pico. Ao contrário das tarefas personalizadas, em que o serviço de preparação liberta o recurso após a conclusão da tarefa, os clusters Ray permanecem disponíveis até serem eliminados.
Nota: use clusters Ray de execução prolongada nestes cenários:
- Se enviar a mesma tarefa do Ray várias vezes, pode beneficiar da colocação em cache de dados e imagens executando as tarefas no mesmo cluster do Ray de execução prolongada.
- Se executar muitas tarefas do Ray de curta duração em que o tempo de processamento real é inferior ao tempo de início da tarefa, pode ser vantajoso ter um cluster de longa duração.
Os clusters do Ray no Vertex AI podem ser configurados com conetividade pública ou privada. Os diagramas seguintes mostram a arquitetura e o fluxo de trabalho do Ray na Vertex AI. Consulte o artigo Conetividade pública ou privada para mais informações.
Arquitetura com conetividade pública
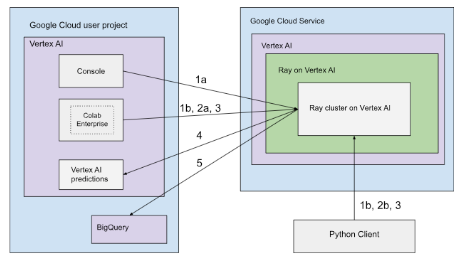
Crie o cluster do Ray no Vertex AI com as seguintes opções:
a. Use a Google Cloud consola para criar o cluster do Ray na Vertex AI.
b. Crie o cluster do Ray no Vertex AI através do SDK Vertex AI para Python.
Ligue-se ao cluster do Ray no Vertex AI para desenvolvimento interativo usando as seguintes opções:
a. Use o Colab Enterprise na Google Cloud consola para uma ligação perfeita.
b. Use qualquer ambiente Python acessível à Internet pública.
Desenvolva a sua aplicação e prepare o seu modelo no cluster do Ray no Vertex AI:
Use o SDK da Vertex AI para Python no seu ambiente preferencial (Colab Enterprise ou qualquer bloco de notas Python).
Escreva um script Python com o seu ambiente preferido.
Envie uma tarefa do Ray para o cluster do Ray na Vertex AI através do SDK da Vertex AI para Python, da CLI de tarefas do Ray ou da API de envio de tarefas do Ray.
Implemente o modelo preparado num ponto final online do Vertex AI para inferência em direto.
Use o BigQuery para gerir os seus dados.
Arquitetura com VPC
O diagrama seguinte mostra a arquitetura e o fluxo de trabalho do Ray no Vertex AI depois de configurar o Google Cloud projeto e a rede de VPC, o que é opcional:
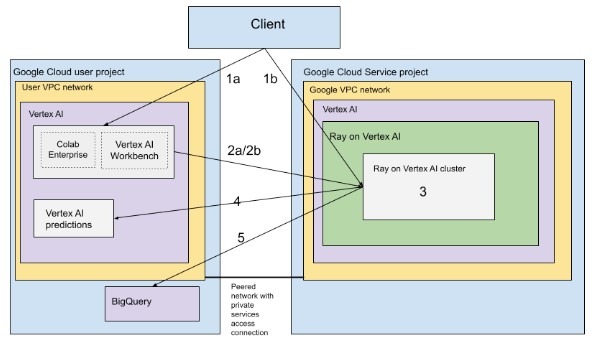
Configure (a) o projeto Google e (b) a rede VPC.
Crie o cluster do Ray no Vertex AI com as seguintes opções:
a. Use a Google Cloud consola para criar o cluster do Ray na Vertex AI.
b. Crie o cluster do Ray no Vertex AI através do SDK Vertex AI para Python.
Ligue-se ao cluster do Ray no Vertex AI através de uma rede com peering de VPC usando as seguintes opções:
Use o Colab Enterprise na Google Cloud consola.
Use um bloco de notas do Vertex AI Workbench
Desenvolva a sua aplicação e prepare o seu modelo no cluster do Ray no Vertex AI através das seguintes opções:
Use o SDK da Vertex AI para Python no seu ambiente preferencial (Colab Enterprise ou um bloco de notas do Vertex AI Workbench).
Escreva um script Python com o seu ambiente preferido. Envie uma tarefa do Ray para o cluster do Ray na Vertex AI através do SDK da Vertex AI para Python, da CLI de tarefas do Ray ou do painel de controlo do Ray.
Implemente o modelo preparado num ponto final online do Vertex AI para inferências.
Use o BigQuery para gerir os seus dados.
Terminologia
Para ver uma lista completa de termos, consulte o glossário do Vertex AI para IA preditiva.
-
autoscaling
- A escala automática é a capacidade de um recurso de computação, como o conjunto de trabalhadores de um cluster do Ray, ajustar automaticamente o número de nós para cima ou para baixo com base nas exigências da carga de trabalho, otimizando a utilização de recursos e o custo. Para mais informações, consulte o artigo Dimensione os clusters do Ray na Vertex AI: dimensionamento automático.
-
inferência em lote
- A inferência em lote recebe um grupo de pedidos de inferência e produz os resultados num ficheiro. Para mais informações, consulte o artigo Vista geral da obtenção de inferências na Vertex AI.
-
BigQuery
- O BigQuery é um armazém de dados empresarial totalmente gerido, sem servidor e altamente escalável fornecido pelo Google Cloud, concebido para analisar conjuntos de dados massivos através de consultas SQL a velocidades incrivelmente elevadas. O BigQuery permite uma Business Intelligence e uma análise poderosas sem exigir que os utilizadores geram qualquer infraestrutura. Para mais informações, consulte o artigo Do armazém de dados à plataforma autónoma de dados e IA.
-
Cloud Logging
- O Cloud Logging é um serviço de registo em tempo real totalmente gerido fornecido pelo Google Cloud que lhe permite recolher, armazenar, analisar e monitorizar registos de todos os seus recursos do Google Cloud, aplicações no local e até origens personalizadas. O Cloud Logging centraliza a gestão de registos, o que facilita a resolução de problemas, a auditoria e a compreensão do comportamento e do estado de funcionamento das suas aplicações e infraestrutura. Para mais informações, consulte a vista geral do Cloud Logging.
-
Colab Enterprise
- O Colab Enterprise é um ambiente de blocos de notas do Jupyter colaborativo e gerido que oferece a popular experiência do utilizador do Google Colab no Google Cloud, com capacidades de segurança e conformidade de nível empresarial. O Colab Enterprise oferece uma experiência centrada em blocos de notas e sem configuração, com recursos de computação geridos pelo Vertex AI, e integra-se com outros serviços do Google Cloud, como o BigQuery. Para mais informações, consulte o artigo Introdução ao Colab Enterprise.
-
imagem de contentor personalizada
- Uma imagem de contentor personalizada é um pacote executável autónomo que inclui o código da aplicação do utilizador, o respetivo tempo de execução, bibliotecas, dependências e configuração do ambiente. No contexto do Google Cloud, particularmente do Vertex AI, permite ao utilizador agrupar o respetivo código de preparação de aprendizagem automática ou aplicação de publicação com as respetivas dependências exatas, garantindo a reprodutibilidade e permitindo ao utilizador executar uma carga de trabalho em serviços geridos com versões de software específicas ou configurações únicas não fornecidas por ambientes padrão. Para mais informações, consulte os requisitos do contentor personalizado para inferência.
-
endpoint
- Recursos nos quais pode implementar modelos preparados para publicar inferências. Para mais informações, consulte o artigo Escolha um tipo de ponto final.
-
Autorizações da gestão de identidade e de acesso (IAM)
- As autorizações da gestão de identidade e de acesso (IAM) são capacidades detalhadas específicas que definem quem pode fazer o quê em que recursos do Google Cloud. São atribuídas a responsáveis (como utilizadores, grupos ou contas de serviço) através de funções, o que permite um controlo preciso sobre o acesso a serviços e dados num projeto ou numa organização do Google Cloud. Para mais informações, consulte o artigo Controlo de acesso com a IAM.
-
inferência
- No contexto da plataforma Vertex AI, a inferência refere-se ao processo de execução de pontos de dados através de um modelo de aprendizagem automática para calcular uma saída, como uma única pontuação numérica. Este processo também é conhecido como "operacionalizar um modelo de aprendizagem automática" ou "colocar um modelo de aprendizagem automática em produção". A inferência é um passo importante no fluxo de trabalho de aprendizagem automática, uma vez que permite que os modelos sejam usados para fazer inferências sobre novos dados. No Vertex AI, a inferência pode ser realizada de várias formas, incluindo inferência em lote e inferência online. A inferência em lote envolve a execução de um grupo de pedidos de inferência e a saída dos resultados num ficheiro, enquanto a inferência online permite inferências em tempo real em pontos de dados individuais.
-
Sistema de arquivos de rede (NFS)
- Um sistema cliente/servidor que permite aos utilizadores aceder a ficheiros numa rede e tratá-los como se estivessem num diretório de ficheiros local. Para mais informações, consulte o artigo Monte uma partilha NFS para preparação personalizada.
-
Inferência online
- Obter inferências em instâncias individuais de forma síncrona. Para mais informações, consulte o artigo Inferência online.
-
recurso persistente
- Um tipo de recurso de computação do Vertex AI, como um cluster do Ray, que permanece atribuído e disponível até ser explicitamente eliminado, o que é benéfico para o desenvolvimento iterativo e reduz a sobrecarga de arranque entre tarefas. Para mais informações, consulte o artigo Obtenha informações persistentes sobre recursos.
-
pipeline
- Os pipelines de AA são fluxos de trabalho de AA portáteis e escaláveis baseados em contentores. Para mais informações, consulte o artigo Introdução aos pipelines da Vertex AI.
-
Contentor pré-criado
- Imagens de contentores fornecidas pelo Vertex AI que vêm pré-instaladas com frameworks e dependências de ML comuns, o que simplifica a configuração para tarefas de preparação e inferência. Para mais informações, consulte o artigo Contentores pré-criados para a preparação personalizada .
-
Private Service Connect (PSC)
- O Private Service Connect é uma tecnologia que permite aos clientes do Compute Engine mapear IPs privados na respetiva rede para outra rede da VPC ou para APIs Google. Para mais informações, consulte o Private Service Connect.
-
Cluster do Ray no Vertex AI
- Um cluster do Ray no Vertex AI é um cluster gerido de nós de computação que pode ser usado para executar aplicações de aprendizagem automática (ML) e Python distribuídas. Fornece a infraestrutura para realizar computação distribuída e processamento paralelo para o seu fluxo de trabalho de ML. Os clusters do Ray estão integrados no Vertex AI para garantir a disponibilidade de capacidade para cargas de trabalho de AA críticas ou durante épocas de pico. Ao contrário das tarefas personalizadas, em que o serviço de preparação liberta o recurso após a conclusão da tarefa, os clusters do Ray permanecem disponíveis até serem eliminados. Para mais informações, consulte o artigo Vista geral do Ray na Vertex AI.
-
Ray on Vertex AI (RoV)
- O Ray no Vertex AI foi concebido para que possa usar o mesmo código Ray de código aberto para escrever programas e desenvolver aplicações no Vertex AI com alterações mínimas. Para mais informações, consulte o artigo Vista geral do Ray na Vertex AI.
-
Ray no SDK Vertex AI para Python
- O Ray no SDK Vertex AI for Python é uma versão do SDK Vertex AI for Python que inclui a funcionalidade do cliente Ray, do conector Ray BigQuery, da gestão de clusters do Ray no Vertex AI e das inferências no Vertex AI. Para mais informações, consulte o artigo Introdução ao SDK Vertex AI para Python.
-
Ray no SDK Vertex AI para Python
- O Ray no SDK Vertex AI for Python é uma versão do SDK Vertex AI for Python que inclui a funcionalidade do cliente Ray, do conector Ray BigQuery, da gestão de clusters do Ray no Vertex AI e das inferências no Vertex AI. Para mais informações, consulte o artigo Introdução ao SDK Vertex AI para Python.
-
conta de serviço
- As contas de serviço são contas especiais do Google Cloud usadas por aplicações ou máquinas virtuais para fazer chamadas de API autorizadas aos serviços Google Cloud. Ao contrário das contas de utilizador, não estão associadas a um indivíduo, mas atuam como uma identidade para o seu código, permitindo o acesso seguro e programático aos recursos sem necessitar de credenciais humanas. Para mais informações, consulte o artigo Vista geral das contas de serviço.
-
Vertex AI Workbench
- O Vertex AI Workbench é um ambiente de desenvolvimento unificado baseado no Jupyter Notebook que suporta todo o fluxo de trabalho de ciência de dados, desde a exploração e análise de dados ao desenvolvimento, preparação e implementação de modelos. O Vertex AI Workbench oferece uma infraestrutura gerida e escalável com integrações incorporadas a outros serviços do Google Cloud, como o BigQuery e o Cloud Storage, o que permite aos cientistas de dados realizar as respetivas tarefas de aprendizagem automática de forma eficiente sem gerir a infraestrutura subjacente. Para mais informações, consulte o artigo Introdução ao Vertex AI Workbench.
-
nó trabalhador
- Um nó de trabalho refere-se a uma máquina individual ou a uma instância computacional num cluster responsável pela execução de tarefas ou pela realização de trabalho. Em sistemas como clusters do Kubernetes ou do Ray, os nós são as unidades fundamentais de computação.
-
conjunto de trabalhadores
- Componentes de um cluster Ray que executam tarefas distribuídas. Os conjuntos de trabalhadores podem ser configurados com tipos de máquinas específicos e suportam o dimensionamento automático e o dimensionamento manual. Para mais informações, consulte o artigo Estrutura do cluster de preparação.
Preços
O preço do Ray no Vertex AI é calculado da seguinte forma:
Os recursos de computação que usa são cobrados com base na configuração da máquina que seleciona quando cria o cluster do Ray no Vertex AI. Para ver os preços do Ray no Vertex AI, consulte a página de preços.
Relativamente aos clusters do Ray, a cobrança só é feita durante os estados RUNNING e UPDATING. Não são cobrados outros estados. O valor cobrado baseia-se no tamanho real do cluster no momento.
Quando realiza tarefas com o cluster do Ray no Vertex AI, os registos são gerados automaticamente e cobrados com base nos preços do Cloud Logging.
Se implementar o seu modelo num ponto final para inferências online, consulte a secção "Previsão e explicação" da página de preços do Vertex AI.
Se usar o BigQuery com o Ray na Vertex AI, consulte os preços do BigQuery.