Halaman ini menjelaskan cara menggunakan Pemantauan Model Vertex AI dengan Vertex Explainable AI untuk mendeteksi skew dan penyimpangan untuk atribusi fitur dari fitur input kategori dan numerik.
Ringkasan pemantauan berbasis atribusi fitur
Atribusi fitur menunjukkan seberapa besar kontribusi setiap fitur dalam model Anda terhadap prediksi untuk setiap instance tertentu. Saat meminta prediksi, Anda mendapatkan nilai prediksi yang sesuai untuk model Anda. Saat meminta penjelasan, Anda akan mendapatkan prediksi beserta informasi atribusi fitur.
Skor atribusi sebanding dengan kontribusi fitur terhadap prediksi model. Parameter ini biasanya ditandai, yang menunjukkan apakah suatu fitur membantu mendorong prediksi ke atas atau ke bawah. Atribusi di seluruh fitur harus ditambahkan ke skor prediksi model.
Dengan memantau atribusi fitur, Pemantauan Model melacak perubahan kontribusi fitur terhadap prediksi model dari waktu ke waktu. Perubahan skor atribusi fitur utama sering kali menandakan bahwa fitur tersebut telah berubah dengan cara yang dapat memengaruhi akurasi prediksi model.
Untuk informasi tentang cara penghitungan skor atribusi fitur, lihat Metode atribusi fitur.
Skew dan penyimpangan prediksi atribusi fitur penayangan pelatihan
Saat Anda membuat tugas pemantauan untuk model dengan Vertex Explainable AI yang diaktifkan, Pemantauan Model akan memantau kecondongan atau penyimpangan untuk distribusi fitur dan atribusi fitur. Untuk mengetahui informasi tentang kemiringan dan penyimpangan distribusi fitur, lihat Pengantar Pemantauan Model Vertex AI.
Untuk atribusi fitur:
Skew penayangan pelatihan terjadi saat skor atribusi fitur dalam produksi menyimpang dari skor atribusi fitur di data pelatihan yang asli.
Penyimpangan prediksi terjadi saat skor atribusi fitur dalam produksi berubah secara signifikan dari waktu ke waktu.
Anda dapat mengaktifkan deteksi skew jika memasukkan set data pelatihan asli untuk model Anda; jika tidak, Anda harus mengaktifkan deteksi penyimpangan. Anda juga dapat mengaktifkan deteksi skew dan penyimpangan sekaligus.
Prasyarat
Untuk menggunakan Pemantauan Model dengan Vertex Explainable AI, lakukan hal-hal berikut:
Jika Anda mengaktifkan deteksi skew, upload data pelatihan atau output tugas penjelasan batch untuk set data pelatihan ke Cloud Storage atau BigQuery. Dapatkan link URI ke data. Untuk deteksi penyimpangan, data pelatihan atau dasar penjelasan tidak diperlukan.
Memiliki model yang tersedia di Vertex AI yang berupa AutoML tabular atau jenis pelatihan kustom tabular yang diimpor:
Model tabular AutoML memiliki Vertex Explainable AI yang telah dikonfigurasi secara otomatis, sehingga Anda dapat langsung mengaktifkan deteksi skew atau penyimpangan. Perhatikan bahwa hanya model klasifikasi dan regresi yang didukung.
Model terlatih kustom yang diimpor harus dikonfigurasi untuk Vertex Explainable AI saat Anda membuat, mengimpor, atau men-deploy model tersebut.
Konfigurasi model Anda untuk menggunakan Vertex Explainable AI saat membuat, mengimpor, atau men-deploy model. Kolom
ExplanationSpec.ExplanationParameterswajib terisi untuk model Anda.Opsional: Untuk model yang dilatih khusus, upload skema instance analisis untuk model Anda ke Cloud Storage. Pemantauan Model memerlukan skema untuk memulai proses pemantauan dan menghitung distribusi dasar pengukuran untuk deteksi diferensiasi performa. Jika Anda tidak memberikan skema selama pembuatan tugas, tugas akan tetap dalam status tertunda sampai Pemantauan Model dapat secara otomatis mengurai skema dari 1000 permintaan prediksi pertama yang diterima model.
Aktifkan deteksi skew atau penyimpangan
Untuk menyiapkan deteksi skew atau deteksi penyimpangan, buat tugas pemantauan deployment model:
Konsol
Untuk membuat tugas pemantauan deployment model menggunakan konsolGoogle Cloud , buat endpoint:
Di konsol Google Cloud , buka halaman Vertex AI Endpoints.
Klik Buat Endpoint.
Di panel Endpoint baru, beri nama endpoint dan tetapkan region.
Klik Lanjutkan.
Di kolom Nama model, pilih pelatihan kustom atau model AutoML tabular yang diimpor.
Di kolom Versi, pilih versi untuk model Anda.
Klik Lanjutkan.
Di panel Pemantauan model, pastikan Aktifkan pemantauan model untuk endpoint ini diaktifkan. Setiap setelan pemantauan yang Anda konfigurasi berlaku untuk semua model yang di-deploy ke endpoint.
Masukkan Nama tampilan tugas pemantauan.
Masukkan Panjang jendela pemantauan.
Untuk Notification emails, masukkan satu atau beberapa alamat email yang dipisahkan koma untuk menerima pemberitahuan saat model melebihi nilai minimum pemberitahuan.
(Opsional) Untuk Notification channels, pilih saluran Cloud Monitoring untuk menerima pemberitahuan saat model melebihi nilai minimum pemberitahuan. Anda dapat memilih saluran Cloud Monitoring yang sudah ada atau membuat yang baru dengan mengklik Manage notifikasi channels. Konsol mendukung saluran notifikasi PagerDuty, Slack, dan Pub/Sub.
Masukkan Frekuensi sampling.
Opsional: Masukkan Skema input prediksi dan Skema input analisis.
Klik Lanjutkan. Panel Pemantauan objektif akan terbuka, dengan opsi deteksi diferensiasi performa atau penyimpangan:
Deteksi diferensiasi performa
- Pilih Deteksi diferensiasi performa pelatihan dan penayangan.
- Di bagian Sumber data pelatihan, masukkan sumber data pelatihan.
- Di bagian Kolom target, masukkan nama kolom dari data pelatihan yang ingin diprediksi oleh model. Bidang ini dikecualikan dari analisis pemantauan.
- Opsional: Di bagian Nilai minimum pemberitahuan, tentukan nilai minimum untuk memicu pemberitahuan. Untuk mengetahui informasi tentang cara memformat nilai minimum, arahkan kursor ke ikon Bantuan .
- Klik Buat.
Deteksi penyimpangan
- Pilih Deteksi penyimpangan prediksi.
- Opsional: Di bagian Nilai minimum pemberitahuan, tentukan nilai minimum untuk memicu pemberitahuan. Untuk mengetahui informasi tentang cara memformat nilai minimum, arahkan kursor ke ikon Bantuan .
- Klik Buat.
gcloud
Untuk membuat tugas pemantauan deployment model menggunakan gcloud CLI, deploy model Anda ke endpoint terlebih dahulu.
Konfigurasi tugas pemantauan berlaku untuk semua model yang di-deploy berdasarkan endpoint.
Jalankan perintah gcloud ai model-monitoring-jobs create:
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
dengan:
PROJECT_ID adalah ID project Google Cloud Anda. Contohnya,
my-project.REGION adalah lokasi untuk tugas pemantauan Anda. Contoh,
us-central1.MONITORING_JOB_NAME adalah nama tugas pemantauan Anda. Contoh,
my-job.EMAIL_ADDRESS adalah alamat email tempat Anda ingin menerima pemberitahuan dari Pemantauan Model. Contoh,
example@example.com.ENDPOINT_ID adalah ID endpoint tempat model Anda di-deploy. Contoh,
1234567890987654321.Opsional: FEATURE_1=THRESHOLD_1 adalah nilai minimum pemberitahuan untuk setiap fitur yang ingin Anda pantau. Misalnya, jika Anda menentukan
Age=0.4, Pemantauan Model akan mencatat pemberitahuan saat [jarak statistik][jarak statistik] antara distribusi input dan dasar pengukuran untuk fiturAgemelebihi 0,4.Opsional: SAMPLING_RATE adalah fraksi permintaan prediksi masuk yang ingin Anda catat. Contoh,
0.5. Jika tidak ditentukan, Pemantauan Model akan mencatat semua permintaan prediksi.Opsional: MONITORING_FREQUENCY adalah frekuensi yang Anda inginkan untuk menjalankan tugas pemantauan pada input yang baru-baru ini dicatat ke dalam log. Perincian minimum adalah 1 jam. Nilai defaultnya adalah 24 jam. Contoh,
2.(hanya diperlukan untuk deteksi skew) TARGET_FIELD adalah kolom yang diprediksi oleh model. Kolom ini dikecualikan dari analisis pemantauan. Contoh,
housing-price.(hanya diperlukan untuk deteksi diferensiasi performa) BIGQUERY_URI adalah link ke set data pelatihan yang disimpan di BigQuery, menggunakan format berikut:
bq://\PROJECT.\DATASET.\TABLE
Contoh,
bq://\my-project.\housing-data.\san-francisco.Anda dapat mengganti flag
bigquery-uridengan link alternatif ke set data pelatihan Anda:Untuk file CSV yang disimpan di bucket Cloud Storage, gunakan
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Untuk file TFRecord yang disimpan di bucket Cloud Storage, gunakan
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Untuk [set data AutoML terkelola berbentuk tabel][ID set data], gunakan
--dataset=DATASET_ID.
Python SDK
Untuk mengetahui informasi tentang alur kerja Model Monitoring API menyeluruh secara lengkap, lihat contoh notebook.
REST API
Jika Anda belum melakukannya, deploy model Anda ke endpoint.
Ambil ID model yang di-deploy untuk model Anda dengan mendapatkan informasi endpoint. Catat DEPLOYED_MODEL_ID, yang merupakan nilai
deployedModels.iddalam respons.Buat permintaan tugas pemantauan model. Petunjuk di bawah ini menunjukkan cara membuat tugas pemantauan dasar untuk deteksi penyimpangan dengan atribusi. Untuk deteksi skew, tambahkan objek
explanationBaselineke kolomexplanationConfigdalam isi JSON permintaan dan masukkan salah satu hal berikut:Output dari tugas penjelasan batch untuk set data pelatihan Anda.
TrainingDatasettempat layanan menjalankan tugasBatchExplainuntuk menghasilkan dasar pengukuran.
Untuk mengetahui detail selengkapnya, lihat Referensi pekerjaan pemantauan.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: adalah ID Google Cloud project Anda. Misalnya,
my-project. - LOCATION: adalah lokasi untuk tugas pemantauan Anda. Contoh,
us-central1. - MONITORING_JOB_NAME: adalah nama tugas pemantauan Anda. Contoh,
my-job. - PROJECT_NUMBER: adalah nomor untuk Google Cloud project Anda. Misalnya,
1234567890. - ENDPOINT_ID adalah ID untuk endpoint tempat model Anda di-deploy. Contoh,
1234567890. - DEPLOYED_MODEL_ID: adalah ID untuk model yang di-deploy.
- FEATURE:VALUE adalah nilai minimum pemberitahuan untuk setiap fitur yang ingin Anda pantau. Misalnya,
"housing-latitude": {"value": 0.4}. Pemberitahuan dicatat saat jarak statistik antara distribusi fitur input dan dasar pengukurannya melebihi nilai minimum yang ditentukan. Secara default, setiap fitur kategori dan numerik dipantau, dengan nilai minimum 0,3. - EMAIL_ADDRESS: adalah alamat email untuk menerima pemberitahuan dari Pemantauan Model. Contoh,
example@example.com. - NOTIFICATION_CHANNELS:
daftar
saluran notifikasi Cloud Monitoring
tempat Anda ingin menerima pemberitahuan dari Pemantauan Model. Gunakan nama resource
untuk saluran notifikasi, yang dapat Anda ambil dengan
mencantumkan saluran notifikasi
dalam project Anda. Contohnya,
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"
Isi JSON permintaan:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan menerima respons JSON yang mirip seperti berikut:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
Setelah tugas pemantauan dibuat, Model Monitoring akan mencatat permintaan prediksi yang masuk ke dalam tabel BigQuery yang dihasilkan dengan nama PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Jika logging permintaan-respons diaktifkan, Pemantauan Model akan mencatat permintaan masuk di tabel BigQuery yang sama dengan yang digunakan untuk logging permintaan-respons.
Lihat Menggunakan Pemantauan Model untuk mengetahui petunjuk cara melakukan tugas-tugas opsional berikut:
Memperbarui tugas Pemantauan Model.
Mengonfigurasi pemberitahuan untuk tugas Pemantauan Model
Konfigurasikan notifikasi untuk anomali.
Menganalisis skew atribusi fitur dan penyimpangan data
Anda dapat menggunakan konsol Google Cloud untuk memvisualisasikan atribusi fitur dari setiap fitur yang dipantau dan mempelajari perubahan mana yang menyebabkan skew atau penyimpangan. Untuk mengetahui informasi tentang cara menganalisis data distribusi fitur, lihat Menganalisis data skew dan penyimpangan.
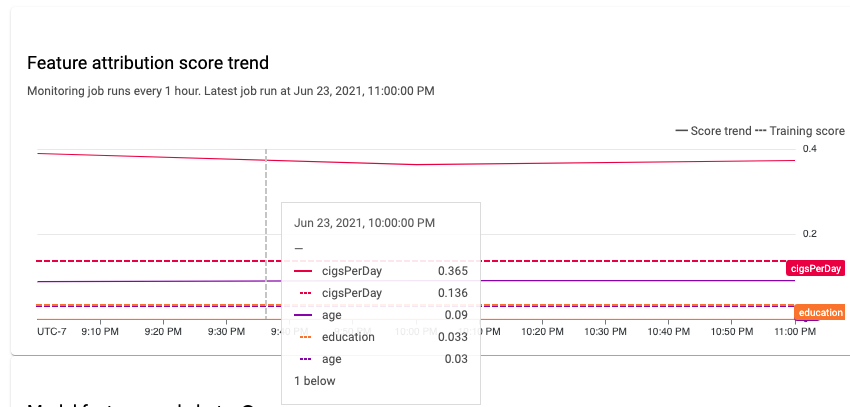
Dalam sistem machine learning yang stabil, tingkat kepentingan relatif fitur umumnya tetap relatif stabil dari waktu ke waktu. Jika fitur yang penting mengalami penurunan nilai kepentingan, hal ini mungkin menandakan bahwa ada sesuatu tentang fitur tersebut yang telah berubah. Penyebab umum penyimpangan atau skew kepentingan fitur meliputi hal-hal berikut:
- Perubahan sumber data.
- Perubahan skema data dan logging.
- Perubahan pada campuran atau perilaku pengguna akhir (misalnya, karena perubahan musiman atau peristiwa pencilan).
- Perubahan upstream pada fitur yang dihasilkan oleh model machine learning lain.
Sebagai contoh:
- Update model yang menyebabkan peningkatan atau penurunan cakupan (secara keseluruhan atau untuk nilai klasifikasi individual).
- Perubahan performa model (yang mengubah arti fitur).
- Update pada pipeline data, yang dapat menyebabkan penurunan cakupan secara keseluruhan.
Selain itu, pertimbangkan hal-hal berikut saat menganalisis atribusi fitur yang skew dan data peyimpangan:
Lacak fitur yang paling penting. Perubahan besar dalam atribusi ke suatu fitur berarti kontribusi fitur tersebut terhadap prediksi telah berubah. Karena skor prediksi sama dengan jumlah kontribusi fitur, pergeseran atribusi yang besar dari fitur yang paling penting biasanya menunjukkan penyimpangan yang besar dalam prediksi model.
Pantau semua representasi fitur. Atribusi fitur selalu numerik, apa pun jenis fitur yang mendasarinya. Karena sifatnya, atribusi ke fitur multi-dimensi seperti embedding dapat dikurangi menjadi satu nilai numerik dengan menjumlahkan atribusi di seluruh dimensi. Hal ini memungkinkan Anda menggunakan metode deteksi penyimpangan universal standar untuk semua jenis fitur.
Perhitungkan interaksi fitur. Atribusi ke fitur memperhitungkan kontribusi fitur tersebut terhadap prediksi, baik secara individual maupun oleh interaksinya dengan fitur lain. Jika interaksi fitur dengan fitur lain berubah, distribusi atribusi ke fitur berubah, meskipun distribusi marginal fitur tetap sama.
Pantau grup fitur. Karena atribusi bersifat aditif, Anda dapat menambahkan atribusi ke fitur terkait untuk mendapatkan atribusi grup fitur. Misalnya, dalam model pinjaman kredit, menggabungkan atribusi ke semua fitur yang terkait dengan jenis pinjaman (misalnya, "grade", "sub_grade", "tujuan") untuk mendapatkan atribusi pinjaman tunggal. Atribusi tingkat grup ini kemudian dapat dilacak untuk memantau perubahan pada grup fitur.
Langkah berikutnya
- Bekerja dengan Pemantauan Model dengan mengikuti dokumen API.
- Bekerja dengan Pemantauan Model dengan mengikuti dokumen gcloud CLI.
- Coba notebook contoh di Colab atau lihat di GitHub.
- Pelajari cara Model Monitoring menghitung diferensiasi performa dan penyimpangan prediksi pelatihan dan penayangan.