Die folgenden Zielabschnitte enthalten Informationen zu Datenanforderungen, zur Eingabe/Ausgabe-Schemadatei und zum Format der Datenimportdateien (JSON Lines und CSV), die vom Schema definiert werden.
Objekterkennung
Datenanforderungen
| Allgemeine Anforderungen für Bilder | |
|---|---|
| Unterstützte Dateitypen |
|
| Bildarten | AutoML-Modelle sind für Fotos von Objekten aus dem richtigen Leben optimiert. |
| Größe der Trainingsbilddatei (MB) | Maximal 30 MB |
| Größe der Vorhersage-Bilddatei* (MB) | Maximal 1,5 MB |
| Bildgröße (Pixel) | Maximal 1.024 x 1.024 Pixel empfohlen Bei Bildern, die deutlich größer als 1.024 x 1.024 Pixel sind, kann während des Bildnormalisierungprozesses von Vertex AI etwas Bildqualität verloren gehen.. |
| Anforderungen an Labels und Begrenzungsrahmen | |
|---|---|
| Die folgenden Anforderungen gelten für Datasets, die zum Trainieren von AutoML-Modellen verwendet werden. | |
| Labelinstanzen für das Training | Mindestens 10 Annotationen (Instanzen). |
| Annotationsvoraussetzungen | Für jedes Label müssen mindestens 10 Bilder mit mindestens jeweils einer Annotation enthalten sein (Begrenzungsrahmen und das Label). Für das Modelltraining empfehlen wir jedoch, etwa 1000 Annotationen pro Label zu verwenden. Generell gilt: Je mehr Bilder pro Label Sie haben, desto besser wird Ihr Modell. |
| Labelverhältnis (zwischen dem am häufigsten und dem am wenigsten verwendeten Label): | Das Modell funktioniert am besten, wenn für das am häufigsten verwendete Label höchstens 100 Mal mehr Bilder vorhanden sind als für das am wenigsten verwendete Label. Für die Modellleistung wird empfohlen, Labels mit sehr niedriger Häufigkeit zu entfernen. |
| Randlänge des Begrenzungsrahmens | Mindestens 0,01 × Länge einer Seite eines Bildes. Beispiel: Für ein Bild mit 1.000 × 900 Pixel sind Begrenzungsrahmen mit mindestens 10 × 9 Pixel erforderlich. Größe des Begrenzungsrahmens: 8 x 8 Pixel. |
| Die folgenden Anforderungen gelten für Datasets, die zum Trainieren von AutoML- oder benutzerdefinierten Modellen verwendet werden. | |
| Begrenzungsrahmen pro Bild | Maximal 500 |
| Begrenzungsrahmen, die von einer Vorhersageanfrage zurückgegeben werden | 100 (Standard), maximal 500 |
| Anforderungen an Trainingsdaten und Datasets | |
|---|---|
| Die folgenden Anforderungen gelten für Datasets, die zum Trainieren von AutoML-Modellen verwendet werden. | |
| Eigenschaften von Trainingsbildern | Die Trainingsdaten sollten den Daten, für die Vorhersagen getroffen werden sollen, möglichst ähnlich sein. Wenn Ihr Anwendungsfall z. B. verschwommene Bilder mit niedriger Auflösung (z. B. von einer Überwachungskamera) beinhaltet, sollten auch Ihre Trainingsdaten aus verschwommenen Bildern mit niedriger Auflösung bestehen. Sie sollten außerdem mehrere Blickwinkel, Auflösungen und Hintergründe für Ihre Trainingsbilder bereitstellen. Vertex AI-Modelle können in der Regel keine Labels vorhersagen, die von Menschen nicht zugewiesen werden können. Wenn also ein Mensch nicht darin unterwiesen werden kann, beim Betrachten eines Bildes innerhalb von 1 bis 2 Sekunden ein Label zuzuweisen, kann Ihr Modell wahrscheinlich auch nicht darin trainiert werden. |
| Interne Bildvorverarbeitung | Nachdem die Bilder importiert wurden, führt Vertex AI die Vorverarbeitung der Daten aus. Die vorverarbeiteten Bilder sind die tatsächlichen Daten, die zum Trainieren des Modells verwendet werden. Die Bildvorverarbeitung (Änderung der Größe) tritt auf, wenn der kleinste Rand des Bildes größer als 1.024 Pixel ist. In Fällen, in denen die kleinere Seite des Bildes größer als 1.024 Pixel ist, wird diese kleinere Seite auf 1.024 Pixel herunterskaliert. Die größere Seite und die angegebenen Begrenzungsrahmen werden beide um die gleiche Größe skaliert wie die kleinere Seite. Folglich werden alle verkleinerten Annotationen (Begrenzungsrahmen und Labels) entfernt, wenn sie kleiner als 8 x 8 Pixel sind. Bei Bildern mit einer kleineren Seite, die kleiner oder gleich 1.024 Pixel ist, kann die Vorverarbeitung nicht geändert werden. |
| Die folgenden Anforderungen gelten für Datasets, die zum Trainieren von AutoML- oder benutzerdefinierten Modellen verwendet werden. | |
| Bilder in jedem Dataset | Maximal 150.000 |
| Gesamtzahl der annotierten Begrenzungsrahmen in jedem Dataset | Maximal 1.000.000 |
| Anzahl der Labels pro Dataset | Mindestens 1, maximal 1.000 |
YAML-Schemadatei
Mit der folgenden öffentlich zugänglichen Schemadatei können Sie Annotationen zur Bildobjekterkennung importieren (Begrenzungsrahmen und Labels). Diese Schemadatei bestimmt das Format der Dateneingabedateien. Die Struktur dieser Datei folgt dem OpenAPI-Schema.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
Vollständige Schemadatei
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
Eingabedateien
JSON Lines
JSON in jeder Zeile:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}Feldhinweise:
imageGcsUri: Das einzige Pflichtfeld.annotationResourceLabels: Kann beliebig viele Schlüssel/Wert-Stringpaare enthalten. Das einzige vom System reservierte Schlüssel/Wert-Paar ist:- "aiplatform.googleapis.com/annotation_set_name" : "value"
Dabei ist value einer der Anzeigenamen der vorhandenen Annotationssätze im Dataset.
dataItemResourceLabels: Kann beliebig viele Schlüssel/Wert-Stringpaare enthalten. Das einzige vom System reservierte Schlüssel/Wert-Paar ist das im Folgenden aufgeführte Paar, das den Nutzungssatz des Datenelements für das maschinelle Lernen angibt:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
Beispiel für JSON Lines – object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
CSV-Format:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(Optional). Für das Aufteilen von Daten beim Training eines Modells. Verwenden Sie TRAINING, TEST oder VALIDATION. Weitere Informationen zur manuellen Datenaufteilung finden Sie unter Datenaufteilungen für AutoML-Modelle.GCS_FILE_PATH. Dieses Feld enthält den Cloud Storage-URI für das Bild. Bei Cloud Storage-URIs wird zwischen Groß- und Kleinschreibung unterschieden.LABEL. Labels müssen mit einem Buchstaben beginnen und dürfen nur Buchstaben, Zahlen und Unterstriche enthalten.BOUNDING_BOX. Ein Begrenzungsrahmen für ein Objekt im Bild. Die Angabe eines Begrenzungsrahmens umfasst mehr als eine Spalte.
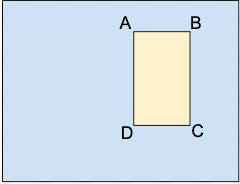
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
Jeder Eckpunkt wird durch x- und y-Koordinatenwerte angegeben. Koordinaten sind normalisierte Gleitkommawerte [0,1]; 0,0 ist X_MIN oder Y_MIN, 1,0 ist X_MAX oder Y_MAX.
Zum Beispiel wird ein Begrenzungsrahmen für das gesamte Bild als (0.0,0.0,,,1.0,1.0,,), oder (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0) ausgedrückt.
Der Begrenzungsrahmen für ein Objekt kann auf zwei Arten angegeben werden:
- Zwei Eckpunkte (zwei Sets x- und y-Koordinaten), die diagonal gegenüberliegende Punkte des Rechtecks sind:
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
wie in diesem Beispiel gezeigt:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - Alle vier Eckpunkte, wie angegeben:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
Wenn die vier angegebenen Eckpunkte kein Rechteck parallel zu den Bildkanten bilden, gibt Vertex AI Eckpunkte an, die ein solches Rechteck bilden.
- Zwei Eckpunkte (zwei Sets x- und y-Koordinaten), die diagonal gegenüberliegende Punkte des Rechtecks sind:
CSV-Beispieldatei - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...