En la siguiente sección de objetivos se incluye información sobre los requisitos de los datos, el archivo de esquema de entrada/salida y el formato de los archivos de importación de datos (JSON Lines y CSV) definidos por el esquema.
Detección de objetos
Requisitos de datos
| Requisitos generales de las imágenes | |
|---|---|
| Tipos de archivo admitidos |
|
| Tipos de imágenes | Los modelos de AutoML están optimizados para fotografías de objetos del mundo real. |
| Tamaño del archivo de imagen de entrenamiento (MB) | Tamaño máximo de 30 MB. |
| Tamaño del archivo de imagen de predicción* (MB) | Tamaño máximo de 1,5 MB. |
| Tamaño de la imagen (en píxeles) | Se recomienda que las imágenes tengan unas dimensiones máximas de 1024 x 1024 píxeles. En el caso de las imágenes mucho más grandes que 1024x1024 píxeles, es posible que se pierda calidad durante el proceso de normalización de imágenes de Vertex AI. |
| Requisitos de etiquetas y recuadros delimitadores | |
|---|---|
| Los siguientes requisitos se aplican a los conjuntos de datos que se usan para entrenar modelos de AutoML. | |
| Etiquetar instancias para el entrenamiento | 10 anotaciones (instancias) como mínimo. |
| Requisitos de las anotaciones | En cada etiqueta debes tener al menos 10 imágenes, cada una con al menos una anotación (cuadro de delimitación y etiqueta). Sin embargo, para entrenar el modelo, te recomendamos que uses unas 1000 anotaciones por etiqueta. En general, cuantas más imágenes por etiqueta tengas, mejor será el rendimiento de tu modelo. |
| Relación de etiquetas (etiqueta más común a etiqueta menos común): | El modelo funciona mejor cuando hay como máximo 100 veces más imágenes de la etiqueta más común que de la menos común. Para mejorar el rendimiento del modelo, te recomendamos que elimines las etiquetas de frecuencia muy baja. |
| Longitud del borde del cuadro delimitador | Al menos 0,01 * longitud de un lado de una imagen. Por ejemplo, una imagen de 1000x900 píxeles requeriría cuadros delimitadores de al menos 10x9 píxeles. Tamaño mínimo del cuadro delimitador: 8x8 píxeles. |
| Los siguientes requisitos se aplican a los conjuntos de datos que se usan para entrenar modelos de AutoML o modelos entrenados personalizados. | |
| Cuadros delimitadores por imagen distinta | 500 como máximo. |
| Cuadros delimitadores devueltos de una solicitud de predicción | 100 (valor predeterminado) y 500 (valor máximo). |
| Requisitos de los datos de entrenamiento y del conjunto de datos | |
|---|---|
| Los siguientes requisitos se aplican a los conjuntos de datos que se usan para entrenar modelos de AutoML. | |
| Características de las imágenes de entrenamiento | Los datos de entrenamiento deben ser lo más parecidos posible a los datos con los que se van a hacer las predicciones. Por ejemplo, si tu caso práctico implica imágenes borrosas y de baja resolución (como las de una cámara de seguridad), tus datos de entrenamiento deben estar compuestos por imágenes borrosas y de baja resolución. En general, también deberías proporcionar varios ángulos, resoluciones y fondos para las imágenes de entrenamiento. Por lo general, los modelos de Vertex AI no pueden predecir etiquetas que los humanos no pueden asignar. Por lo tanto, si no se puede entrenar a una persona para que asigne etiquetas mirando la imagen durante 1 o 2 segundos, es probable que tampoco se pueda entrenar al modelo para que lo haga. |
| Preprocesamiento interno de imágenes | Una vez importadas las imágenes, Vertex AI preprocesa los datos. Las imágenes preprocesadas son los datos que se usan para entrenar el modelo. El preprocesamiento de la imagen (cambio de tamaño) se produce cuando el lado más pequeño de la imagen es mayor que 1024 píxeles. Si el lado más pequeño de la imagen es superior a 1024 píxeles, se reduce a 1024 píxeles. Los cuadros delimitadores y especificados se reducen en la misma proporción que el lado más pequeño. Por lo tanto, se eliminarán las anotaciones (cuadros delimitadores y etiquetas) que se hayan reducido si tienen menos de 8x8 píxeles. Las imágenes cuyo lado más pequeño sea inferior o igual a 1024 píxeles no se someten a un cambio de tamaño previo al procesamiento. |
| Los siguientes requisitos se aplican a los conjuntos de datos que se usan para entrenar modelos de AutoML o modelos entrenados personalizados. | |
| Imágenes de cada conjunto de datos | Máximo de 150.000 |
| Número total de cuadros delimitadores anotados en cada conjunto de datos | Máximo: 1.000.000 |
| Número de etiquetas de cada conjunto de datos | Mínimo: 1, máximo: 1000 |
Archivo de esquema YAML
Utilice el siguiente archivo de esquema de acceso público para importar anotaciones de detección de objetos de imagen (cuadros delimitadores y etiquetas). Este archivo de esquema determina el formato de los archivos de entrada de datos. La estructura de este archivo sigue el esquema de OpenAPI.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
Archivo de esquema completo
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
Archivos de entrada
JSON Lines
JSON en cada línea:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}Notas de campo:
imageGcsUri: el único campo obligatorio.annotationResourceLabels: puede contener cualquier número de pares de cadenas clave-valor. El único par clave-valor reservado por el sistema es el siguiente:- "aiplatform.googleapis.com/annotation_set_name" : "value"
value es uno de los nombres visibles de los conjuntos de anotaciones del conjunto de datos.
dataItemResourceLabels: puede contener cualquier número de pares de cadenas clave-valor. El único par clave-valor reservado por el sistema es el siguiente, que especifica el conjunto de usos de aprendizaje automático del elemento de datos:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
Ejemplo de líneas JSON: object_detection.jsonl
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
Formato CSV:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(opcional). Para dividir los datos al entrenar un modelo. Usa TRAINING, TEST o VALIDATION. Para obtener más información sobre la división manual de datos, consulta Acerca de las divisiones de datos para los modelos de AutoML.GCS_FILE_PATH. Este campo contiene el URI de Cloud Storage de la imagen. En los URIs de Cloud Storage se distingue entre mayúsculas y minúsculas.LABEL. Las etiquetas deben empezar por una letra y solo pueden contener letras, números y guiones bajos.BOUNDING_BOX. Un cuadro delimitador de un objeto de la imagen. Para especificar un cuadro delimitador, se necesita más de una columna.
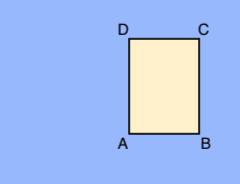
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
Cada vértice se especifica mediante los valores de las coordenadas x e y. Las coordenadas son valores flotantes normalizados [0,1]; 0,0 es X_MIN o Y_MIN, y 1,0 es X_MAX o Y_MAX.
Por ejemplo, un cuadro delimitador de toda la imagen se expresa como (0.0,0.0,,,1.0,1.0,,) o (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0).
El cuadro delimitador de un objeto se puede especificar de dos formas:
- Dos vértices (dos conjuntos de coordenadas x e y) que son puntos opuestos en diagonal del rectángulo:
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
como se muestra en este ejemplo:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - Los cuatro vértices especificados, tal como se muestra en:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
Si los cuatro vértices especificados no forman un rectángulo paralelo a los bordes de la imagen, Vertex AI especifica los vértices que sí forman un rectángulo de este tipo.
- Dos vértices (dos conjuntos de coordenadas x e y) que son puntos opuestos en diagonal del rectángulo:
Ejemplo de CSV: object_detection.csv
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...