Vertex AI 提供了模型评估指标,可帮助您确定模型的性能,例如精确率和召回率指标。Vertex AI 使用测试集来计算评估指标。
如何使用模型评估指标
模型评估指标提供模型在测试集上的表现的量化测量结果。如何解读和使用这些指标取决于您的业务需求和模型训练所要解决的问题。例如,假正例的容忍度可能低于假负例,反之亦然。这些问题会影响您重点关注的指标。
如需详细了解如何迭代模型以改善其性能,请参阅迭代模型。
Vertex AI 返回的评估指标
Vertex AI 会返回几个不同的评估指标,例如精确率、召回率和置信度阈值。Vertex AI 返回的指标取决于您的模型目标。例如,与图片对象分类模型相比,Vertex AI 为图片对象检测模型提供了不同的评估指标。
架构文件可从 Cloud Storage 位置下载,它决定了 Vertex AI 为每个目标提供的评估指标。以下标签提供了架构文件的链接,并描述了每个模型目标的评估指标。
您可以从以下 Cloud Storage 位置查看和下载架构文件:
gs://google-cloud-aiplatform/schema/modelevaluation/
- IoU 阈值:用于确定返回哪些推理的交并比阈值。模型会返回不低于此值的推理结果。阈值越高,预测边界框值必须越接近实际的边界框值。
- 平均精确率均值:也称为平均精确率。此值的范围在 0 到 1 之间,值越大表示模型质量越高。
- 置信度阈值:用于确定要返回的推理结果的置信度得分。模型会返回不低于此值的推理结果。如果提高置信度阈值,精确率会相应地提高,但召回率会降低。Vertex AI 以不同的阈值返回置信度指标,以显示阈值如何影响精确率和召回率。
- 召回率:对于有关此类别的推理,模型正确预测出此类别的推理结果所占的比例。也称为真正例率。
- 精确率:在模型生成的分类推理中,正确推理结果所占的比例。
- F1 得分:精确率和召回率的调和平均数。F1 是一个很实用的指标,当您希望在精确率和召回率之间取得平衡,而类别分布又不均匀时,该指标会非常有帮助。
-
边界框平均精度均值:边界框评估的单一指标:所有
boundingBoxMetrics的平均值meanAveragePrecision。
获取评估指标
您可以获取模型的一组总体评估指标,以及针对特定类或标签的评估指标。特定类或标签的评估指标也称为评估切片。以下内容介绍如何使用 Google Cloud 控制台或 API 获取总体评估指标和评估切片。
Google Cloud 控制台
在 Google Cloud 控制台的 Vertex AI 部分中,前往模型页面。
在区域下拉列表中,选择您的模型所在的区域。
在模型列表中,点击您的模型以打开模型的评估标签页。
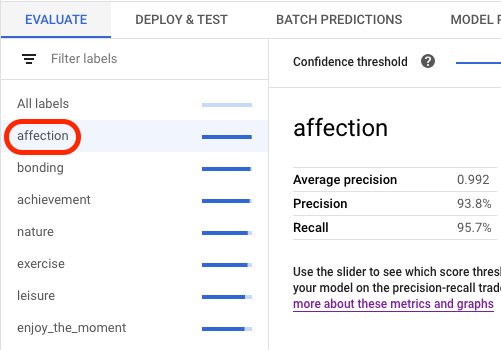
在评估标签页中,您可以查看模型的总体评估指标,例如平均精确率和召回率。
如果模型目标具有评估切片,则控制台会显示标签列表。您可以点击标签来查看该标签的评估指标,如以下示例所示:
API
对于每种数据类型和目标,获取评估指标的 API 请求是相同的,但输出有所不同。以下示例显示了相同的请求和不同的响应。
获取聚合模型评估指标
总体模型评估指标提供有关整个模型的信息。如需查看特定切片的相关信息,请列出模型评估切片。
如需查看总体模型评估指标,请使用 projects.locations.models.evaluations.get 方法。
对于边界框指标,Vertex AI 会返回一组采用不同 IoU 阈值(介于 0 和 1 之间)和置信度阈值(介于 0 和 1 之间)的指标值。例如,您可以采用 IoU 阈值 0.85 和置信度阈值 0.8228 来缩小评估指标范围。通过查看这些不同的阈值,您可以看到它们如何影响其他指标,例如精确率和召回率。
选择与您的语言或环境对应的标签页:
REST
在使用任何请求数据之前,请先进行以下替换:
- LOCATION:存储模型的区域。
- PROJECT:您的项目 ID。
- MODEL_ID:模型资源的 ID。
- PROJECT_NUMBER:自动生成的项目编号。
- EVALUATION_ID:模型评估的 ID(显示在响应中)。
HTTP 方法和网址:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations
如需发送请求,请选择以下方式之一:
curl
执行以下命令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations"
PowerShell
执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations" | Select-Object -Expand Content
您应该收到类似以下内容的 JSON 响应:
Java
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Java 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Java API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Node.js 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Node.js API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
列出所有评估切片
projects.locations.models.evaluations.slices.list 方法可列出您的模型的所有评估切片。您必须拥有模型的评估 ID,才能在查看总体评估指标时获得此 ID。
您可以使用模型评估切片来确定模型在特定标签上的表现。value 字段指示与指标对应的标签。
对于边界框指标,Vertex AI 会返回一组采用不同 IoU 阈值(介于 0 和 1 之间)和置信度阈值(介于 0 和 1 之间)的指标值。例如,您可以采用 IoU 阈值 0.85 和置信度阈值 0.8228 来缩小评估指标范围。通过查看这些不同的阈值,您可以看到它们如何影响其他指标,例如精确率和召回率。
REST
在使用任何请求数据之前,请先进行以下替换:
- LOCATION:模型所在的区域。例如
us-central1。 - PROJECT:。
- MODEL_ID:您的模型的 ID。
- EVALUATION_ID:包含要列出评估切片的模型评估的 ID。
HTTP 方法和网址:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices
如需发送请求,请选择以下方式之一:
curl
执行以下命令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices"
PowerShell
执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices" | Select-Object -Expand Content
您应该收到类似以下内容的 JSON 响应:
Java
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Java 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Java API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Node.js 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Node.js API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
获取单个切片的指标
如需查看单个切片的评估指标,请使用 projects.locations.models.evaluations.slices.get 方法。您必须拥有切片 ID(该 ID 会在您列出所有切片时提供)。以下示例适用于所有数据类型和目标。
REST
在使用任何请求数据之前,请先进行以下替换:
- LOCATION:模型所在的区域。例如 us-central1。
- PROJECT:。
- MODEL_ID:您的模型的 ID。
- EVALUATION_ID:包含要检索的评估切片的模型评估 ID。
- SLICE_ID:要获取的评估切片的 ID。
- PROJECT_NUMBER:自动生成的项目编号。
- EVALUATION_METRIC_SCHEMA_FILE_NAME:定义要返回的评估指标的架构文件名称,例如
classification_metrics_1.0.0。
HTTP 方法和网址:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID
如需发送请求,请选择以下方式之一:
curl
执行以下命令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID"
PowerShell
执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID" | Select-Object -Expand Content
您应该收到类似以下内容的 JSON 响应:
Java
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Java 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Java API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Node.js 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Node.js API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
迭代模型
当模型未达到您的预期时,模型评估指标可为您提供调试模型的起点。例如,低精确率和召回率可能表明您的模型需要额外的训练数据或者存在不一致的标签。完美的精确率和召回率可能表明测试数据难以预测,并且可能无法有效泛化。
您可以迭代训练数据并创建新模型。创建新模型后,您可以比较现有模型和新模型的评估指标。
以下建议可帮助您改进为各项添加标签的模型(例如对象检测或检测模型):
- 建议在您的训练数据中添加更多样本或范围更广的示例。例如,对于图片对象检测模型,您可以添加角度更宽的图片、分辨率更高或更低的图片或不同的视角。如需更多指导,请参阅准备数据。
- 考虑移除没有大量样本的类或标签。样本不足会导致模型无法一致、自信地对这些类或标签进行预测。
- 机器无法解读类或标签的名称,也无法理解它们之间的细微差别,例如“door”和“door_with_knob”。您必须提供数据来帮助机器识别这些细微差别。
- 使用更多的真正例和真负例样本来扩充您的数据,尤其是靠近决策边界的样本,以降低模型混淆。
- 指定您自己的数据拆分(训练、验证和测试)。Vertex AI 会为每个集合随机分配项。因此,相似的重复项可能会分配在训练集和验证集中,这可能导致过拟合,进而造成测试集性能不佳。如需详细了解如何设置您自己的数据拆分,请参阅 AutoML 模型的数据拆分简介。
- 如果模型的评估指标包含混淆矩阵,您可以查看模型是否会混淆两个标签,其中模型预测特定标签明显比真实标签多。查看您的数据,并确保正确标记样本。
- 如果您的训练时间很短(较低的节点最大小时数),您可以延长训练时间来获得质量更高的模型(较高的节点数上限)。