Les hôtes sur site peuvent accéder à un point de terminaison de prédiction en ligne Vertex AI via l'Internet public ou en mode privé via une architecture de mise en réseau hybride qui utilise Private Service Connect (PSC) sur Cloud VPN ou Cloud Interconnect. Les deux options proposent le chiffrement SSL/TLS. Toutefois, l'option privée offre de bien meilleures performances et est donc recommandée pour les applications critiques.
Dans ce tutoriel, vous allez utiliser un VPN haute disponibilité pour accéder à un point de terminaison de prédiction en ligne en mode public, via Cloud NAT, et en mode privé, entre deux réseaux cloud privé virtuel pouvant servir de base pour la connectivité multicloud et sur site
Ce tutoriel est destiné aux administrateurs réseau d'entreprise, aux data scientists et aux chercheurs qui connaissent déjà Vertex AI, le cloud privé virtuel (VPC), la console Google Cloud et Cloud Shell. Une connaissance de Vertex AI Workbench est utile, mais pas obligatoire.
Objectifs
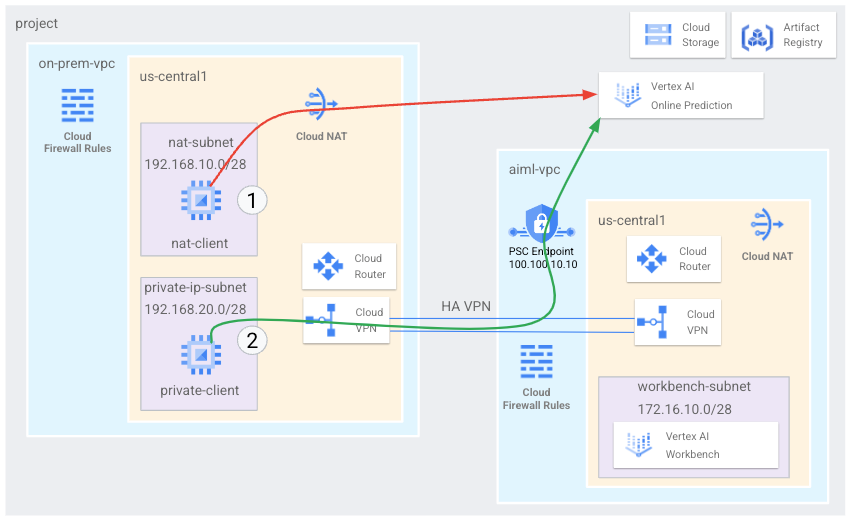
- Créer deux réseaux cloud privés virtuels (VPC), comme illustré dans le schéma précédent :
- L'un (
on-prem-vpc) représente un réseau sur site. - L'autre (
aiml-vpc) permet de créer et de déployer un modèle de prédiction en ligne Vertex AI.
- L'un (
- Déployer des passerelles VPN haute disponibilité, des tunnels Cloud VPN et des routeurs Cloud Router pour connecter
aiml-vpceton-prem-vpc. - Créer et déployer un modèle de prédiction en ligne Vertex AI.
- Créer un point de terminaison Private Service Connect (PSC) pour transférer des requêtes de prédiction en ligne privées vers le modèle déployé.
- Activez le mode d'annonce personnalisé Cloud Router dans
aiml-vpcpour annoncer les routes du point de terminaison Private Service Connect àon-prem-vpc. - Créer deux instances de VM Compute Engine dans
on-prem-vpcpour représenter les applications clientes :- L'une (
nat-client) envoie des requêtes de prédiction en ligne via l'Internet public (via Cloud NAT). Cette méthode d'accès est indiquée par une flèche rouge et le chiffre 1 dans le schéma. - L'autre (
private-client) envoie des requêtes de prédiction en mode privé sur un VPN haute disponibilité. Cette méthode d'accès est indiquée par une flèche verte et le chiffre 2.
- L'une (
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Ouvrez Cloud Shell pour exécuter les commandes répertoriées dans ce tutoriel. Cloud Shell est un environnement shell interactif pour Google Cloud qui vous permet de gérer vos projets et ressources depuis un navigateur Web.
- Dans Cloud Shell, définissez le projet actuel sur votre ID de projet Google Cloud , puis stockez le même ID de projet dans la variable de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
Créer les réseaux VPC
Dans cette section, vous allez créer deux réseaux VPC, l'un pour créer un modèle de prédiction en ligne et le déployer sur un point de terminaison, l'autre pour l'accès privé à ce point de terminaison. Dans chacun des deux réseaux VPC, vous créez un routeur Cloud Router et une passerelle Cloud NAT. Une passerelle Cloud NAT fournit une connectivité sortante pour les instances de machines virtuelles (VM) Compute Engine sans adresse IP externe.
Créer le réseau VPC pour le point de terminaison de prédiction en ligne (aiml-vpc)
Créez le réseau VPC :
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=customCréez un sous-réseau nommé
workbench-subnetavec une plage IPv4 principale de172.16.10.0/28:gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCréez un routeur Cloud Router régional nommé
cloud-router-us-central1-aiml-nat:gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1Ajoutez une passerelle Cloud NAT au routeur Cloud Router :
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Créer le réseau VPC "sur site" (on-prem-vpc)
Créez le réseau VPC :
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=customCréez un sous-réseau nommé
nat-subnetavec une plage IPv4 principale de192.168.10.0/28:gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1Créez un sous-réseau nommé
private-ip-subnetavec une plage IPv4 principale de192.168.20.0/28:gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1Créez un routeur Cloud Router régional nommé
cloud-router-us-central1-on-prem-nat:gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1Ajoutez une passerelle Cloud NAT au routeur Cloud Router :
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Créer le point de terminaison Private Service Connect (PSC)
Dans cette section, vous créez le point de terminaison Private Service Connect (PSC) que les instances de VM du réseau on-prem-vpc utilisent pour accéder au point de terminaison de prédiction en ligne via l'API Vertex AI.
Le point de terminaison Private Service Connect (PSC) est une adresse IP interne du réseau on-prem-vpc qui est accessible directement aux clients de ce réseau. Ce point de terminaison est créé en déployant une règle de transfert qui dirige le trafic réseau correspondant à l'adresse IP du point de terminaison PSC vers un groupe d'API Google.
L'adresse IP du point de terminaison PSC (100.100.10.10) sera annoncée ultérieurement à partir du routeur Cloud Router aiml-cr-us-central1, en tant que route annoncée personnalisée pointant vers le réseau on-prem-vpc.
Réservez des adresses IP pour le point de terminaison PSC :
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpcCréez le point de terminaison PSC :
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apisRéférencez les points de terminaison configurés PSC et vérifiez que le point de terminaison
pscvertexa été créé :gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --globalObtenez les détails du point de terminaison PSC configuré et vérifiez que l'adresse IP est
100.100.10.10:gcloud compute forwarding-rules describe pscvertex \ --global
Configurer la connectivité hybride
Dans cette section, vous allez créer deux passerelles (VPN haute disponibilité) connectées l'une à l'autre. Chaque passerelle contient un routeur Cloud Router et une paire de tunnels VPN.
Créez la passerelle VPN haute disponibilité pour le réseau VPC
aiml-vpc:gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1Créez la passerelle VPN haute disponibilité pour le réseau VPC
on-prem-vpc:gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1Dans Google Cloud Console, accédez à la page VPN.
Sur la page VPN, cliquez sur l'onglet Passerelles Cloud VPN.
Dans la liste des passerelles VPN, vérifiez qu'il existe deux passerelles et que chacune d'entre elles possède deux adresses IP.
Dans Cloud Shell, créez un routeur Cloud Router pour le réseau cloud privé virtuel
aiml-vpc:gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001Créez un routeur Cloud Router pour le réseau cloud privé virtuel
on-prem-vpc:gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
Créer les tunnels VPN pour aiml-vpc
Créez un tunnel VPN appelé
aiml-vpc-tunnel0:gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0Créez un tunnel VPN appelé
aiml-vpc-tunnel1:gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
Créer les tunnels VPN pour on-prem-vpc
Créez un tunnel VPN appelé
on-prem-vpc-tunnel0:gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0Créez un tunnel VPN appelé
on-prem-vpc-tunnel1:gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1Dans Google Cloud Console, accédez à la page VPN.
Sur la page VPN, cliquez sur l'onglet Tunnels Cloud VPN.
Dans la liste des tunnels VPN, vérifiez que quatre tunnels VPN ont été établis.
Établir des sessions BGP
Cloud Router utilise le protocole BGP (Border Gateway Protocol) pour échanger des routes entre votre réseau VPC (dans ce cas, aiml-vpc) et votre réseau sur site (représenté par on-prem-vpc). Sur Cloud Router, vous configurez une interface et un pair BGP pour votre routeur sur site.
Ensemble, l'interface et la configuration du pair BGP forment une session BGP.
Dans cette section, vous allez créer deux sessions BGP pour aiml-vpc et deux pour on-prem-vpc.
Établir des sessions BGP pour aiml-vpc
Dans Cloud Shell, créez la première interface BGP :
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1Créez le premier pair BGP :
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1Créez la deuxième interface BGP :
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central1Créez le deuxième pair BGP :
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
Établir des sessions BGP pour on-prem-vpc
Créez la première interface BGP :
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1Créez le premier pair BGP :
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1Créez la deuxième interface BGP :
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central1Créez le deuxième pair BGP :
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
Valider la création de la session BGP
Dans Google Cloud Console, accédez à la page VPN.
Sur la page VPN, cliquez sur l'onglet Tunnels Cloud VPN.
Dans la liste des tunnels VPN, vous devriez maintenant voir la valeur de la colonne État de la session BGP pour chacun des quatre tunnels passer de Configurer la session BGP à Session BGP établie. Vous devrez peut-être actualiser l'onglet du navigateur de la console Google Cloud pour afficher les nouvelles valeurs.
Vérifier que aiml-vpc a appris les routes de sous-réseau via un VPN haute disponibilité
Dans la console Google Cloud, accédez à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
aiml-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que le réseau VPC
aiml-vpca appris les routes du sous-réseaunat-subnet(192.168.10.0/28) et du sous-réseauprivate-ip-subnet(192.168.20.0/28) des réseaux VPCon-prem-vpc.
Vérifier que on-prem-vpc a appris les routes de sous-réseau via un VPN haute disponibilité
Dans la console Google Cloud, accédez à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
on-prem-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que le réseau VPC
on-prem-vpca appris les routes du sous-réseauworkbench-subnet(172.16.10.0/28) des réseaux VPCaiml-vpc.
Créer une route annoncée personnalisée pour aiml-vpc
L'adresse IP du point de terminaison Private Service Connect n'est pas automatiquement annoncée par le routeur cloud aiml-cr-us-central1, car le sous-réseau n'est pas configuré dans le réseau VPC.
Par conséquent, vous devrez créer une route annoncée personnalisée à partir du routeur Cloud Router aiml-cr-us-central pour l'adresse IP du point de terminaison 100.100.10.10 qui sera annoncée dans l'environnement sur site via BGP vers on-prem-vpc.
Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs Cloud Router, cliquez sur
aiml-cr-us-central1.Sur la page Détails du routeur, cliquez sur Modifier.
Dans la section Routes annoncées, sélectionnez Créer des routes personnalisées pour le paramètre Routes.
Cliquez sur Ajouter une route personnalisée.
Dans Source, sélectionnez Plage d'adresses IP personnalisée.
Dans Plage d'adresses IP, saisissez
100.100.10.10.Dans Description, saisissez
Private Service Connect Endpoint IP.Cliquez sur OK, puis sur Enregistrer.
Vérifier que on-prem-vpc a appris l'adresse IP du point de terminaison PSC via un VPN haute disponibilité
Dans la console Google Cloud, accédez à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
on-prem-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que le réseau VPC
on-prem-vpca appris l'adresse IP du point de terminaison PSC (100.100.10.10).
Créer une route annoncée personnalisée pour on-prem-vpc
Le routeur Cloud Router on-prem-vpc annonce tous les sous-réseaux par défaut, mais seul le sous-réseau private-ip-subnet est nécessaire.
Dans la section suivante, mettez à jour les annonces de routage à partir du routeur Cloud Router on-prem-cr-us-central1.
Dans Google Cloud Console, accédez à la page Routeurs cloud.
Dans la liste des routeurs Cloud Router, cliquez sur
on-prem-cr-us-central1.Sur la page Détails du routeur, cliquez sur Modifier.
Dans la section Routes annoncées, sélectionnez Créer des routes personnalisées pour le paramètre Routes.
Si la case Diffuser tous les sous-réseaux visibles par Cloud Router est cochée, décochez-la.
Cliquez sur Ajouter une route personnalisée.
Dans Source, sélectionnez Plage d'adresses IP personnalisée.
Dans Plage d'adresses IP, saisissez
192.168.20.0/28.Dans Description, saisissez
Private Service Connect Endpoint IP subnet (private-ip-subnet).Cliquez sur OK, puis sur Enregistrer.
Confirmez que aiml-vpc a appris la route private-ip-subnet à partir de on-prem-vpc.
Dans la console Google Cloud, accédez à la page Réseaux VPC.
Dans la liste des réseaux VPC, cliquez sur
aiml-vpc.Cliquez sur l'onglet Routes.
Sélectionnez us-central1 (Iowa) dans la liste Région, puis cliquez sur Afficher.
Dans la colonne Plage d'adresses IP de destination, vérifiez que le réseau VPC
aiml-vpca appris la routeprivate-ip-subnet(192.168.20.0/28).
Créer les instances de VM de test
Créer un compte de service géré par l'utilisateur
Si vous avez des applications qui doivent appeler des API, Google vous recommande d'associer un compte de service géré par l'utilisateur à la VM sur laquelle l'application ou la charge de travail est en cours d'exécution. Google Cloud Par conséquent, dans cette section, vous allez créer un compte de service géré par l'utilisateur à appliquer aux instances de VM que vous créerez plus loin dans ce tutoriel.
Dans Cloud Shell, créez le compte de service :
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"Attribuez le rôle IAM Administrateur d'instances Compute (v1) (
roles/compute.instanceAdmin.v1) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"Attribuez le rôle IAM Utilisateur Vertex AI (
roles/aiplatform.user) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
Créer les instances de VM de test
Au cours de cette étape, vous allez créer des instances de VM de test pour valider différentes méthodes permettant d'accéder aux API AI Vertex, en particulier :
- L'instance
nat-clientutilise Cloud NAT pour résoudre les problèmes d'accès de Vertex AI au point de terminaison de prédiction en ligne via l'Internet public. - L'instance
private-clientutilise l'adresse IP de Private Service Connect100.100.10.10pour accéder au point de terminaison de prédiction en ligne via un VPN haute disponibilité.
Pour autoriser Identity-Aware Proxy (IAP) à se connecter à vos instances de VM, vous devez créer une règle de pare-feu qui :
- S'applique à toutes les instances de VM que vous souhaitez rendre accessibles via IAP.
- Autorise le trafic TCP via le port 22 à partir de la plage d'adresses IP
35.235.240.0/20. Contient toutes les adresses IP qu'IAP utilise pour le transfert TCP.
Créez l'instance de VM
nat-client:gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Créez l'instance de VM
private-client:gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Créez la règle de pare-feu IAP :
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Créer une instance Vertex AI Workbench
Créer un compte de service géré par l'utilisateur pour Vertex AI Workbench
Lorsque vous créez une instance Vertex AI Workbench, Google vous recommande vivement de spécifier un compte de service géré par l'utilisateur au lieu d'utiliser le compte de service Compute Engine par défaut.
Si votre organisation n'applique pas la contrainte de règle d'administration iam.automaticIamGrantsForDefaultServiceAccounts, le compte de service Compute Engine par défaut (et donc toute personne que vous spécifiez en tant qu'utilisateur d'instance) se voit attribuer le rôle Éditeur (roles/editor) sur votre projetGoogle Cloud . Pour désactiver ce comportement, consultez la section Désactiver les attributions automatiques de rôles pour les comptes de service par défaut.
Dans Cloud Shell, créez un compte de service nommé
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Attribuez le rôle IAM Administrateur de l'espace de stockage (
roles/storage.admin) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Attribuez le rôle IAM Utilisateur Vertex AI (
roles/aiplatform.user) au compte de service :gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Attribuez le rôle IAM Administrateur Artifact Registry au compte de service :
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
Créer l'instance Vertex AI Workbench
Dans Cloud Shell, créez une instance Vertex AI Workbench en spécifiant le compte de service
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
Créer et déployer un modèle de prédiction en ligne
Préparer votre environnement
Dans la console Google Cloud, accédez à l'onglet Instances sur la page Vertex AI Workbench.
À côté du nom de votre instance Vertex AI Workbench (
workbench-tutorial), cliquez sur Ouvrir JupyterLab.Votre instance Vertex AI Workbench ouvre JupyterLab.
Dans la suite de cette section, jusqu'au déploiement de modèle inclus, vous allez travailler dans JupyterLab, et non dans la console Google Cloud ou Cloud Shell.
Sélectionnez Fichier > Nouveau > Terminal.
Dans le terminal JupyterLab (et non dans Cloud Shell), définissez une variable d'environnement pour votre projet. en remplaçant PROJECT_ID par votre ID de projet :
PROJECT_ID=PROJECT_IDCréez un répertoire nommé
cpr-codelabetcddans ce répertoire (toujours dans le terminal JupyterLab) :mkdir cpr-codelab cd cpr-codelabDans l'explorateur de fichiers , double-cliquez sur le nouveau dossier
cpr-codelab.Si ce dossier n'apparaît pas dans l'explorateur de fichiers, actualisez l'onglet du navigateur de la console Google Cloud, puis réessayez.
Sélectionnez Fichier > Nouveau > Notebook.
Dans le menu Sélectionner le kernel, sélectionnez Python [conda env:base] * (Local), puis cliquez sur Sélectionner.
Renommez le nouveau fichier notebook comme suit :
Dans l'explorateur de fichiers , effectuez un clic droit sur l'icône de fichier
Untitled.ipynb, puis saisisseztask.ipynb.Votre répertoire
cpr-codelabdevrait se présenter comme suit :+ cpr-codelab/ + task.ipynbDans les étapes suivantes, vous allez créer votre modèle dans le notebook JupyterLab en créant des cellules de notebook, en y collant du code, puis en exécutant les cellules.
Installez les dépendances comme suit.
Lorsque vous ouvrez le nouveau notebook, une cellule de code par défaut vous permet de saisir du code. Elle se présente comme
[ ]:suivi d'un champ de texte. Ce champ de texte vous permet de coller votre code.Collez le code suivant dans la cellule, puis cliquez sur Run the selected cells and advance (Exécuter les cellules sélectionnées et avancer) pour créer un fichier
requirements.txtà utiliser en entrée de l'étape suivante :%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2À cette étape et à chacune des étapes suivantes, ajoutez une cellule de code en cliquant sur Insert a cell below (Insérer une cellule ci-dessous), collez le code dans la cellule, puis cliquez sur Run the selected cells and advance (Exécuter les cellules sélectionnées et avancer).
Utilisez
Pippour installer des dépendances dans l'instance de notebooks :!pip install -U --user -r requirements.txtUne fois l'installation terminée, sélectionnez Kernel > Restart kernel (Noyau > Redémarrer le noyau) pour redémarrer le noyau et vous assurer que la bibliothèque est disponible pour l'importation.
Collez le code suivant dans une nouvelle cellule de notebook pour créer les répertoires servant à stocker le modèle et prétraiter les artefacts :
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
Dans l'explorateur de fichiers , la structure de votre répertoire
cpr-codelabdoit maintenant se présenter comme suit :+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
Entraîner le modèle
Continuez à ajouter des cellules de code au notebook task.ipynb, puis collez et exécutez le code suivant dans chaque nouvelle cellule :
Importez les bibliothèques :
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)Définissez les variables suivantes en remplaçant PROJECT_ID par l'ID de votre projet :
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"Créez un bucket Cloud Storage :
!gcloud storage buckets create $BUCKET_NAME --location=us-central1Chargez les données depuis la bibliothèque Seaborn, puis créez deux cadres de données, l'un avec les fonctionnalités et l'autre avec l'étiquette :
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])Examinez les données d'entraînement et vérifiez que chaque ligne représente un losange.
x_train.head()Examinez les étiquettes, qui sont les prix correspondants.
y_train.head()Définissez une transformation de colonne sklearn pour effectuer un encodage one-hot des caractéristiques catégorielles et ajustez les caractéristiques numériques :
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))Définissez le modèle de forêt d'arbres décisionnels :
regr = RandomForestRegressor(max_depth=10, random_state=0)Créez un pipeline sklearn. Ce pipeline prend des données d'entrée, les encode et les met à l'échelle, puis les transmet au modèle.
my_pipeline = make_pipeline(column_transform, regr)Entraîner le modèle
my_pipeline.fit(x_train, y_train)Appelez la méthode de prédiction sur le modèle en transmettant un échantillon de test.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])Des avertissements tels que
"X does not have valid feature names, but"s'affichent, mais vous pouvez les ignorer.Enregistrez le pipeline dans le répertoire
model_artifactset copiez-le dans votre bucket Cloud Storage :joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Enregistrer un artefact de prétraitement
Créez un artefact de prétraitement. Cet artefact sera chargé dans le conteneur personnalisé au démarrage du serveur de modèles. Votre artefact de prétraitement peut se présenter sous n'importe quel format, par exemple un fichier pickle, mais dans ce cas, vous allez écrire un dictionnaire dans un fichier JSON :
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
Créer un conteneur de diffusion personnalisé à l'aide du serveur de modèles CPR
La caractéristique
clarityde nos données d'entraînement était toujours au format abrégé (par exemple, "FL" au lieu de "Flawless"). Au moment de la diffusion, nous voulons vérifier que les données de cette caractéristique sont également abrégées. En effet, notre modèle sait comment effectuer un encodage one-hot de "FL", mais pas de "Flawless". Vous écrirez cette logique de prétraitement personnalisée plus tard. Pour le moment, il vous suffit d'enregistrer cette table de conversion dans un fichier JSON, puis de l'écrire dans votre bucket Cloud Storage :import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/Dans l'explorateur de fichiers , votre structure de répertoires doit maintenant ressembler à ceci :
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynbDans votre notebook, collez et exécutez le code suivant pour sous-classer le
SklearnPredictoret écrivez-le dans un fichier Python dans lesrc_dir/. Notez que dans cet exemple, nous ne personnalisons que les méthodes de chargement, de prétraitement et de post-traitement, et non la méthode de prédiction.%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}Utilisez le SDK Vertex AI pour Python pour créer l'image à l'aide de routines de prédiction personnalisées. Le fichier Dockerfile est généré et une image est créée automatiquement.
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )Écrivez un fichier de test avec deux exemples de prédiction. L'une des instances porte le nom abrégé, mais l'autre doit d'abord être convertie.
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)Testez le conteneur localement en déployant un modèle local.
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()Vous pouvez afficher les résultats de la prédiction avec :
predict_response.contentLa sortie ressemble à ceci :
b'{"predictions": ["$479.0", "$586.0"]}'
Déployer le modèle sur le point de terminaison du modèle de prédiction en ligne
Maintenant que vous avez testé le conteneur localement, il est temps de transférer l'image vers Artifact Registry et d'importer le modèle dans Vertex AI Model Registry.
Configurer Docker pour accéder à Artifact Registry
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quietTransférez l'image.
local_model.push_image()Importez le modèle.
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)Déployez le modèle :
endpoint = model.deploy(machine_type="n1-standard-2")Attendez que votre modèle soit déployé avant de passer à l'étape suivante. Le déploiement prend environ 10 à 15 minutes.
Testez le modèle déployé en obtenant une prédiction :
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])La sortie ressemble à ceci :
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
Valider l'accès Internet public aux API Vertex AI
Dans cette section, vous vous connectez à l'instance de VM nat-client dans un onglet de session Cloud Shell, puis utilisez un autre onglet de session pour valider la connectivité aux API Vertex AI en exécutant la commande dig et tcpdump sur le domaine us-central1-aiplatform.googleapis.com.
Dans Cloud Shell (onglet 1), exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Connectez-vous à l'instance de VM
nat-clientà l'aide d'IAP :gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapExécutez la commande
dig:dig us-central1-aiplatform.googleapis.comDepuis la VM
nat-client(onglet 1), exécutez la commande suivante pour valider la résolution DNS lorsque vous envoyez une requête de prédiction en ligne au point de terminaison.sudo tcpdump -i any port 53 -nOuvrez une nouvelle session Cloud Shell (onglet 2) en cliquant sur ouvrir un nouvel onglet dans Cloud Shell.
Dans la nouvelle session Cloud Shell (onglet 2), exécutez les commandes suivantes, en remplaçant PROJECT_ID par votre ID de projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Connectez-vous à l'instance de VM
nat-client:gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"Depuis la VM
nat-client(onglet 2), utilisez un éditeur de texte tel quevimounanopour créer un fichierinstances.json. Vous devez ajoutersudopour pouvoir écrire dans le fichier, par exemple :sudo vim instances.jsonAjoutez la chaîne de données suivante au fichier :
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Enregistrez le fichier comme suit :
- Si vous utilisez
vim, appuyez sur la toucheEsc, puis saisissez:wqpour enregistrer le fichier et quitter. - Si vous utilisez
nano, saisissezControl+Oet appuyez surEnterpour enregistrer le fichier, puis saisissezControl+Xpour quitter.
- Si vous utilisez
Recherchez l'ID de point de terminaison de prédiction en ligne pour le point de terminaison PSC :
Dans la console Google Cloud, dans la section Vertex AI, accédez à l'onglet Points de terminaison de la page Prédiction en ligne.
Recherchez la ligne du point de terminaison que vous avez créé, nommée
diamonds-cpr_endpoint.Recherchez l'ID du point de terminaison à 19 chiffres dans la colonne ID et copiez-le.
Dans Cloud Shell, à partir de la VM
nat-client(onglet 2), exécutez les commandes suivantes, en remplaçant PROJECT_ID par l'ID de votre projet et ENDPOINT_ID par l'ID de point de terminaison PSC :projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_IDDepuis la VM
nat-client(onglet 2), exécutez la commande suivante pour envoyer une requête de prédiction en ligne :curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
Maintenant que vous avez exécuté la prédiction, vous constatez que les résultats tcpdump (onglet 1) montrent l'instance de VM nat-client (192.168.10.2) en train d'exécuter une requête Cloud DNS sur le serveur DNS local (169.254.169.254) pour le domaine API Vertex AI (us-central1-aiplatform.googleapis.com). La requête DNS renvoie les adresses IP virtuelles publiques (VIP) pour les API Vertex AI.
Valider l'accès privé aux API Vertex AI
Dans cette section, vous vous connectez à l'instance de VM private-client à l'aide d'Identity-Aware Proxy dans une nouvelle session Cloud Shell (onglet 3), puis vous validez la connectivité aux API Vertex AI en exécutant la commande suivante dig sur le domaine Vertex AI (us-central1-aiplatform.googleapis.com).
Ouvrez une nouvelle session Cloud Shell (onglet 3) en cliquant sur Ouvrir un nouvel onglet dans Cloud Shell. Il s'agit de l'onglet 3.
Dans la nouvelle session Cloud Shell (onglet 3), exécutez les commandes suivantes, en remplaçant PROJECT_ID par l'ID de votre projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Connectez-vous à l'instance de VM
private-clientà l'aide d'IAP :gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapExécutez la commande
dig:dig us-central1-aiplatform.googleapis.comDans l'instance de VM
private-client(onglet 3), utilisez un éditeur de texte tel quevimounanopour ajouter la ligne suivante au fichier/etc/hosts:100.100.10.10 us-central1-aiplatform.googleapis.comCette ligne attribue l'adresse IP du point de terminaison PSC (
100.100.10.10) au nom de domaine complet de l'API Google Vertex AI (us-central1-aiplatform.googleapis.com). Le fichier modifié doit se présenter comme suit :127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleDepuis la VM
private-client(onglet 3), pinguez le point de terminaison Vertex AI etControl+Cpour quitter lorsque le résultat s'affiche :ping us-central1-aiplatform.googleapis.comLa commande
pingrenvoie le résultat suivant contenant l'adresse IP du point de terminaison PSC :PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.Depuis la VM
private-client(onglet 3), utiliseztcpdumppour exécuter la commande suivante afin de valider la résolution DNS et le chemin d'accès aux données IP lorsque vous envoyez une requête de prédiction en ligne au point de terminaison :sudo tcpdump -i any port 53 -n or host 100.100.10.10Ouvrez une nouvelle session Cloud Shell (onglet 4) en cliquant sur Ouvrir un nouvel onglet dans Cloud Shell.
Dans la nouvelle session Cloud Shell (onglet 4), exécutez les commandes suivantes en remplaçant PROJECT_ID par l'ID de votre projet :
projectid=PROJECT_ID gcloud config set project ${projectid}Dans l'onglet 4, connectez-vous à l'instance
private-client:gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"Depuis la VM
private-client(onglet 4), à l'aide d'un éditeur de texte tel quevimounano, créez un fichierinstances.jsoncontenant la chaîne de données suivante :{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Depuis la VM
private-client(onglet 4), exécutez les commandes suivantes, en remplaçant PROJECT_ID par le nom de votre projet et ENDPOINT_ID par l'ID de point de terminaison PSC :projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_IDDepuis la VM
private-client(onglet 4), exécutez la commande suivante pour envoyer une requête de prédiction en ligne :curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.jsonDepuis la VM
private-clientdans Cloud Shell (onglet 3), vérifiez que l'adresse IP du point de terminaison PSC (100.100.10.10) a été utilisée pour accéder aux API Vertex AI.Depuis le terminal
private-clienttcpdumpdans Cloud Shell (onglet 3), vous constatez qu'une résolution DNS versus-central1-aiplatform.googleapis.comn'est pas nécessaire, car la ligne que vous avez ajoutée à/etc/hostsest prioritaire, et l'adresse IP PSC100.100.10.10est utilisée dans le chemin d'accès aux données.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre Google Cloud compte, supprimez le projet contenant les ressources, ou conservez le projet et supprimez chaque ressource individuellement.
Vous pouvez supprimer les ressources individuelles du projet comme suit :
Supprimez l'instance Vertex AI Workbench comme suit:
Dans la console Google Cloud, dans la section Vertex AI, accédez à l'onglet Instances de la page Workbench.
Sélectionnez l'instance Vertex AI Workbench
workbench-tutorial, puis cliquez sur Supprimer.
Supprimez l'image de conteneur comme suit :
Dans la console Google Cloud, accédez à la page Artifact Registry.
Sélectionnez le conteneur Docker
diamonds, puis cliquez sur Supprimer.
Supprimez le bucket de stockage comme suit :
Dans la console Google Cloud, accédez à la page Cloud Storage.
Sélectionnez votre bucket de stockage, puis cliquez sur Supprimer.
Annulez le déploiement du modèle sur le point de terminaison comme suit :
Dans la section Vertex AI de la console Google Cloud, accédez à la page Points de terminaison.
Cliquez sur
diamonds-cpr_endpointpour accéder à la page d'informations du point de terminaison.Sur la ligne correspondant à votre modèle,
diamonds-cpr, cliquez sur annuler le déploiement du modèle .Dans la boîte de dialogue Annuler le déploiement du modèle sur le point de terminaison, cliquez sur Annuler le déploiement.
Supprimez le modèle comme suit :
Dans la section Vertex AI de la console Google Cloud, accédez à la page Model Registry.
Sélectionnez le modèle
diamonds-cpr.Pour supprimer le modèle, cliquez sur Actions, puis sur Supprimer le modèle.
Supprimez le point de terminaison de prédiction en ligne comme suit :
Dans la section Vertex AI de la console Google Cloud, accédez à la page Prédiction en ligne.
Sélectionnez le point de terminaison
diamonds-cpr_endpoint.Pour supprimer le point de terminaison, cliquez sur Actions, puis sur Supprimer le point de terminaison.
Dans Cloud Shell, supprimez les ressources restantes en exécutant les commandes suivantes.
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
Étapes suivantes
- Découvrez les options de mise en réseau d'entreprise pour accéder aux points de terminaison et aux services Vertex AI.
- Découvrez comment fonctionne Private Service Connect et ses avantages significatifs en termes de performances.
- Découvrez comment utiliser VPC Service Controls pour créer des périmètres sécurisés afin d'autoriser ou de refuser l'accès à Vertex AI et à d'autres API Google sur votre point de terminaison de prédiction en ligne.
- Découvrez comment et pourquoi utiliser une zone de transfert DNS plutôt que de modifier le fichier
/etc/hostsdans des environnements de production à grande échelle.