Las inferencias por lotes son solicitudes asíncronas que solicitan inferencias directamente del recurso del modelo sin necesidad de desplegar el modelo en un endpoint.
En este tutorial, usarás la VPN de alta disponibilidad (HA VPN) para enviar solicitudes de inferencia por lotes a un modelo entrenado de forma privada entre dos redes de nube privada virtual que pueden servir de base para la conectividad privada multicloud y on-premise.
Este tutorial está dirigido a administradores de redes empresariales, científicos de datos e investigadores que estén familiarizados con Vertex AI, la nube privada virtual (VPC), la consola de Google Cloud y Cloud Shell. Familiarizarse con Vertex AI Workbench es útil, pero no obligatorio.
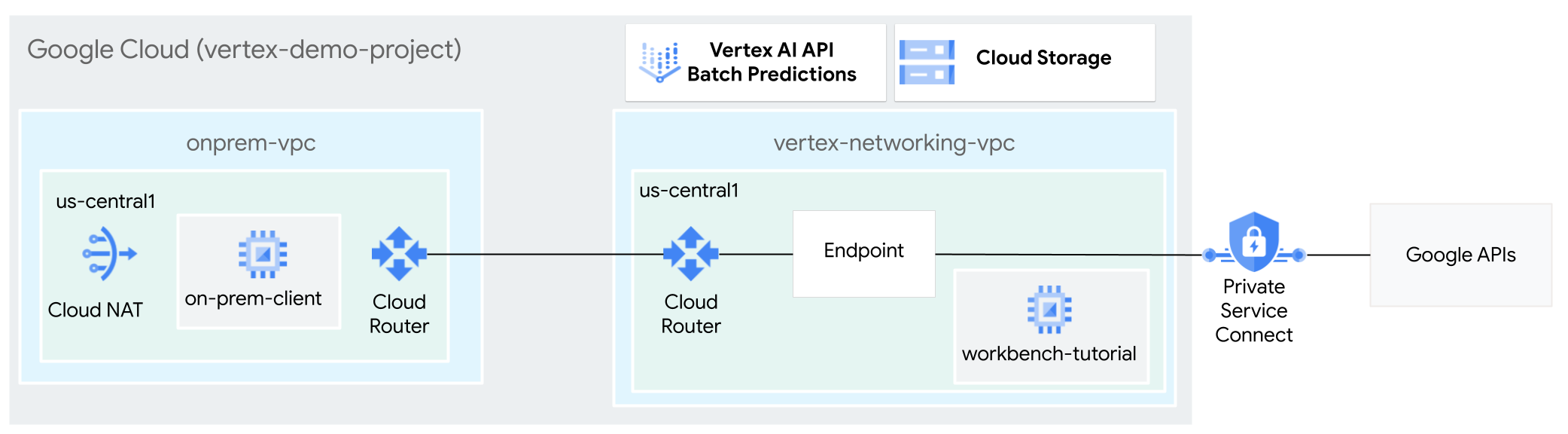
Crear las redes de VPC
En esta sección, crearás dos redes de VPC: una para acceder a las APIs de Google para la inferencia por lotes y otra para simular una red local. En cada una de las dos redes de VPC, crea un router de Cloud Router y una pasarela de Cloud NAT. Una pasarela Cloud NAT proporciona conectividad saliente a las instancias de máquina virtual (VM) de Compute Engine sin direcciones IP externas.
Crea la
vertex-networking-vpcred de VPC:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customEn la red
vertex-networking-vpc, crea una subred llamadaworkbench-subnetcon un intervalo IPv4 principal de10.0.1.0/28:gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrea la red de VPC para simular la red local (
onprem-vpc):gcloud compute networks create onprem-vpc \ --subnet-mode customEn la red
onprem-vpc, crea una subred llamadaonprem-vpc-subnet1con un intervalo IPv4 principal de172.16.10.0/29:gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
Verificar que las redes VPC estén configuradas correctamente
En la Google Cloud consola, ve a la pestaña Redes del proyecto actual de la página Redes de VPC.
En la lista de redes de VPC, comprueba que se hayan creado las dos redes:
vertex-networking-vpcyonprem-vpc.Haz clic en la pestaña Subredes del proyecto actual.
En la lista de subredes de VPC, comprueba que se hayan creado las subredes
workbench-subnetyonprem-vpc-subnet1.
Configurar la conectividad híbrida
En esta sección, creará dos pasarelas de VPN de alta disponibilidad que estarán conectadas entre sí. Una de ellas reside en la red de vertex-networking-vpcVPC. La otra se encuentra en la red de VPC onprem-vpc. Cada pasarela contiene un Cloud Router y un par de túneles VPN.
Crear las pasarelas de VPN de alta disponibilidad
En Cloud Shell, crea la pasarela de VPN de alta disponibilidad para la red de VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Crea la pasarela de VPN de alta disponibilidad para la red VPC
onprem-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1En la Google Cloud consola, ve a la pestaña Pasarelas de Cloud VPN de la página VPN.
Verifica que se hayan creado las dos pasarelas (
vertex-networking-vpn-gw1yonprem-vpn-gw1) y que cada una tenga dos direcciones IP de interfaz.
Crear routers de Cloud Router y pasarelas de Cloud NAT
En cada una de las dos redes de VPC, crea dos routers de Cloud Router: uno general y otro regional. En cada uno de los routers de Cloud regionales, crea una pasarela de Cloud NAT. Las pasarelas Cloud NAT proporcionan conectividad saliente a las instancias de máquina virtual (VM) de Compute Engine que no tienen direcciones IP externas.
En Cloud Shell, crea un Cloud Router para la red de VPC
vertex-networking-vpc:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001Crea un Cloud Router para la red de VPC
onprem-vpc:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002Crea un router de Cloud Router regional para la red de VPC
vertex-networking-vpc:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configura una pasarela Cloud NAT en el Cloud Router regional:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Crea un router de Cloud Router regional para la red de VPC
onprem-vpc:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1Configura una pasarela Cloud NAT en el Cloud Router regional:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1En la Google Cloud consola, ve a la página Cloud Routers.
En la lista Cloud Routers (Routers de Cloud), comprueba que se hayan creado los siguientes routers:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
Es posible que tengas que actualizar la pestaña del navegador de la consola para ver los nuevos valores. Google Cloud
En la lista Cloud Routers, haz clic en
cloud-router-us-central1-vertex-nat.En la página Detalles del router, comprueba que se ha creado la pasarela
cloud-nat-us-central1Cloud NAT.Haz clic en la flecha hacia atrás para volver a la página Routers de Cloud.
En la lista de routers, haz clic en
cloud-router-us-central1-onprem-nat.En la página Detalles del router, comprueba que se haya creado la pasarela Cloud NAT
cloud-nat-us-central1-on-prem.
Crear túneles de VPN
En Cloud Shell, en la red
vertex-networking-vpc, crea un túnel VPN llamadovertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0En la red
vertex-networking-vpc, crea un túnel VPN llamadovertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1En la red
onprem-vpc, crea un túnel VPN llamadoonprem-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0En la red
onprem-vpc, crea un túnel VPN llamadoonprem-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1En la Google Cloud consola, ve a la página VPN.
En la lista de túneles VPN, comprueba que se han creado los cuatro túneles VPN.
Establecer sesiones de BGP
Cloud Router usa el protocolo de pasarela fronteriza (BGP) para intercambiar rutas entre tu red de VPC (en este caso, vertex-networking-vpc) y tu red on‐premise (representada por onprem-vpc). En Cloud Router, configura una interfaz y un par BGP para tu router on‐premise.
La interfaz y la configuración del par de BGP forman una sesión de BGP.
En esta sección, creará dos sesiones de BGP para vertex-networking-vpc y dos para onprem-vpc.
Una vez que hayas configurado las interfaces y los peers de BGP entre tus routers, empezarán a intercambiar rutas automáticamente.
Establecer sesiones de BGP para vertex-networking-vpc
En Cloud Shell, en la red
vertex-networking-vpc, crea una interfaz BGP paravertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1En la red
vertex-networking-vpc, crea un peer de BGP parabgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1En la red
vertex-networking-vpc, crea una interfaz de BGP paravertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1En la red
vertex-networking-vpc, crea un peer de BGP parabgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Establecer sesiones de BGP para onprem-vpc
En la red
onprem-vpc, crea una interfaz de BGP paraonprem-vpc-tunnel0:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1En la red
onprem-vpc, crea un peer de BGP parabgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1En la red
onprem-vpc, crea una interfaz de BGP paraonprem-vpc-tunnel1:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1En la red
onprem-vpc, crea un peer de BGP parabgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Validar la creación de la sesión de BGP
En la Google Cloud consola, ve a la página VPN.
En la lista de túneles VPN, comprueba que el valor de la columna Estado de la sesión de BGP de cada túnel haya cambiado de Configurar sesión de BGP a BGP establecido. Puede que tengas que actualizar la pestaña del navegador de la consola para ver los nuevos valores. Google Cloud
Validar las vertex-networking-vpc rutas aprendidas
En la Google Cloud consola, ve a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
vertex-networking-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Intervalo de IP de destino, comprueba que el intervalo de IP de la subred (
172.16.10.0/29) aparece dos veces.onprem-vpc-subnet1
Validar las onprem-vpc rutas aprendidas
Haz clic en la flecha hacia atrás para volver a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
onprem-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Intervalo de IP de destino, comprueba que el
workbench-subnetintervalo de IP de subred (10.0.1.0/28) aparece dos veces.
Crea el endpoint de cliente de Private Service Connect
En Cloud Shell, reserva una dirección IP de endpoint de consumidor que se usará para acceder a las APIs de Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCrea una regla de reenvío para conectar el punto final a las APIs y los servicios de Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Crear rutas anunciadas personalizadas para vertex-networking-vpc
En esta sección, configura el modo de anuncio personalizado de Cloud Router como Anunciar intervalos de IP personalizados para que vertex-networking-vpc-router1 (el Cloud Router de vertex-networking-vpc) anuncie la dirección IP del endpoint de PSC a la red onprem-vpc.
En la Google Cloud consola, ve a la página Cloud Routers.
En la lista de Cloud Routers, haz clic en
vertex-networking-vpc-router1.En la página Detalles del router, haz clic en Editar.
En la sección Rutas anunciadas, en Rutas, seleccione Crear rutas personalizadas.
Marca la casilla Anunciar todas las subredes que pueda ver el router de Cloud Router para seguir anunciando las subredes disponibles para el router de Cloud Router. Si habilita esta opción, se imitará el comportamiento de Cloud Router en el modo de anuncio predeterminado.
Haz clic en Añadir una ruta personalizada.
En Origen, selecciona Intervalo de IP personalizado.
En Intervalo de direcciones IP, introduce la siguiente dirección IP:
192.168.0.1En Descripción, introduce el siguiente texto:
Custom route to advertise Private Service Connect endpoint IP addressHaz clic en Hecho y, a continuación, en Guardar.
Validar que onprem-vpc ha aprendido las rutas anunciadas
En la Google Cloud consola, ve a la página Rutas.
En la pestaña Rutas eficaces, haga lo siguiente:
- En Red, elige
onprem-vpc. - En Región, elige
us-central1 (Iowa). - Haz clic en Ver.
En la lista de rutas, comprueba que haya entradas cuyos nombres empiecen por
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0yonprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1, y que ambas tengan un intervalo de IPs de destino de192.168.0.1.Si estas entradas no aparecen de inmediato, espera unos minutos y, a continuación, actualiza la pestaña del navegador de la consola Google Cloud .
- En Red, elige
Crea una VM en onprem-vpc que use una cuenta de servicio gestionada por el usuario
En esta sección, crearás una instancia de VM que simule una aplicación cliente local que envíe solicitudes de inferencia por lotes. Siguiendo las prácticas recomendadas de Compute Engine e IAM, esta VM usa una cuenta de servicio gestionada por el usuario en lugar de la cuenta de servicio predeterminada de Compute Engine.
Crear una cuenta de servicio gestionada por el usuario
En Cloud Shell, ejecuta los siguientes comandos y sustituye PROJECT_ID por el ID de tu proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea una cuenta de servicio llamada
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"Asigna el rol Usuario de Vertex AI (
roles/aiplatform.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Asigna el rol Lector de objetos de Storage (
storage.objectViewer) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
Crear la instancia de VM de on-prem-client
La instancia de VM que creas no tiene una dirección IP externa y no permite el acceso directo a través de Internet. Para habilitar el acceso administrativo a la VM, utiliza el reenvío de TCP de Identity-Aware Proxy (IAP).
En Cloud Shell, crea la instancia de VM
on-prem-client:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea una regla de cortafuegos para permitir que IAP se conecte a tu instancia de VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Validar el acceso público a la API de Vertex AI
En esta sección, usarás la utilidad dig para realizar una búsqueda de DNS desde la instancia de VM on-prem-client a la API de Vertex AI (us-central1-aiplatform.googleapis.com). El resultado de dig muestra que el acceso predeterminado solo usa VIPs públicos para acceder a la API de Vertex AI.
En la siguiente sección, configurará el acceso privado a la API de Vertex AI.
En Cloud Shell, inicia sesión en la instancia de VM
on-prem-clientcon IAP:gcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iapEn la instancia de VM
on-prem-client, ejecuta el comandodig:dig us-central1-aiplatform.googleapis.comDeberías ver un resultado
digsimilar al siguiente, donde las direcciones IP de la sección de respuesta son direcciones IP públicas:; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
Configurar y validar el acceso privado a la API de Vertex AI
En esta sección, configurarás el acceso privado a la API Vertex AI para que, cuando envíes solicitudes de inferencia por lotes, se redirijan a tu endpoint de PSC. El endpoint de PSC, a su vez, reenvía estas solicitudes privadas a la API REST de inferencia por lotes de Vertex AI.
Actualiza el archivo /etc/hosts para que apunte al endpoint de PSC
En este paso, añade una línea al archivo /etc/hosts que hace que las solicitudes enviadas al endpoint del servicio público (us-central1-aiplatform.googleapis.com) se redirijan al endpoint de PSC (192.168.0.1).
En la instancia de VM
on-prem-client, usa un editor de texto comovimonanopara abrir el archivo/etc/hosts:sudo vim /etc/hostsAñade la siguiente línea al archivo:
192.168.0.1 us-central1-aiplatform.googleapis.comEsta línea asigna la dirección IP del endpoint de PSC (
192.168.0.1) al nombre de dominio completo de la API de Google de Vertex AI (us-central1-aiplatform.googleapis.com).El archivo editado debería tener este aspecto:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleGuarda el archivo de la siguiente manera:
- Si usas
vim, pulsa la teclaEscy, a continuación, escribe:wqpara guardar el archivo y salir. - Si usas
nano, escribeControl+Oy pulsaEnterpara guardar el archivo. A continuación, escribeControl+Xpara salir.
- Si usas
Haga ping al endpoint de Vertex AI de la siguiente manera:
ping us-central1-aiplatform.googleapis.comEl comando
pingdebería devolver el siguiente resultado.192.168.0.1es la dirección IP del endpoint de PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Escribe
Control+Cpara salir deping.Escribe
exitpara salir de la instancia de VMon-prem-client.
Crea una cuenta de servicio gestionada por el usuario para Vertex AI Workbench en la vertex-networking-vpc
En esta sección, para controlar el acceso a tu instancia de Vertex AI Workbench, crea una cuenta de servicio gestionada por el usuario y, a continuación, asigna roles de gestión de identidades y accesos a la cuenta de servicio. Cuando creas la instancia, especificas la cuenta de servicio.
En Cloud Shell, ejecuta los siguientes comandos y sustituye PROJECT_ID por el ID de tu proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea una cuenta de servicio llamada
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Asigna el rol de gestión de identidades y accesos Usuario de Vertex AI (
roles/aiplatform.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Asigna el rol de gestión de identidades y accesos Usuario de BigQuery (
roles/bigquery.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"Asigna el rol de IAM Administrador de Storage (
roles/storage.admin) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Asigna el rol de gestión de identidades y accesos Lector de registros (
roles/logging.viewer) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
Crear la instancia de Vertex AI Workbench
En Cloud Shell, crea una instancia de Vertex AI Workbench y especifica la cuenta de servicio
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.comEn la Google Cloud consola, ve a la pestaña Instancias de la página Vertex AI Workbench.
Junto al nombre de tu instancia de Vertex AI Workbench (
workbench-tutorial), haz clic en Abrir JupyterLab.Tu instancia de Vertex AI Workbench abre JupyterLab.
Selecciona Archivo > Nuevo > Cuaderno.
En el menú Seleccionar kernel, elige Python 3 (Local) y haz clic en Seleccionar.
Cuando se abra el nuevo cuaderno, verás una celda de código predeterminada en la que puedes introducir código. Tiene el aspecto de
[ ]:seguido de un campo de texto. En el campo de texto es donde debes pegar el código.Para instalar el SDK de Vertex AI para Python, pega el siguiente código en la celda y haz clic en Ejecutar las celdas seleccionadas y avanzar:
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2En este paso y en los siguientes, añade una nueva celda de código (si es necesario) haciendo clic en Insertar una celda debajo, pega el código en la celda y, a continuación, haz clic en Ejecutar las celdas seleccionadas y avanzar.
Para usar los paquetes recién instalados en este entorno de ejecución de Jupyter, debes reiniciar el entorno de ejecución:
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)Define las siguientes variables de entorno en tu cuaderno de JupyterLab. Sustituye PROJECT_ID por el ID de tu proyecto.
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"Crea un segmento de Cloud Storage para organizar la tarea de entrenamiento:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gcloud storage buckets create {BUCKET_URI} --location={REGION} --project={PROJECT_ID}
Preparar los datos de entrenamiento
En esta sección, preparará los datos que se usarán para entrenar un modelo de inferencia.
En tu cuaderno de JupyterLab, crea un cliente de BigQuery:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)Obtén datos del
ml_datasetsconjunto de datos públicoml_datasetsde BigQuery:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()Usa la biblioteca
sklearnpara dividir los datos de entrenamiento y prueba:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)Exporta los dataframes de entrenamiento y prueba a archivos CSV en el bucket de almacenamiento provisional:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
Preparar la aplicación de entrenamiento
En esta sección, crearás y compilarás la aplicación de entrenamiento de Python y la guardarás en el bucket de almacenamiento provisional.
En tu cuaderno de JupyterLab, crea una carpeta para los archivos de la aplicación de entrenamiento:
!mkdir -p training_package/trainerAhora deberías ver una carpeta llamada
training_packageen el menú de navegación de JupyterLab.Define las características, el objetivo, la etiqueta y los pasos para entrenar y exportar el modelo a un archivo:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))Crea un archivo
__init__.pyen cada subdirectorio para convertirlo en un paquete:!touch training_package/__init__.py !touch training_package/trainer/__init__.pyCrea una secuencia de comandos de configuración de paquetes de Python:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )Usa el comando
sdistpara crear la distribución de origen de la aplicación de entrenamiento:!cd training_package && python setup.py sdist --formats=gztarCopia el paquete de Python en el bucket de almacenamiento provisional:
!gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/Verifica que el bucket de almacenamiento provisional contenga tres archivos:
!gcloud storage ls $BUCKET_URIEl resultado debería ser similar a este:
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
Preparar el modelo
En esta sección, entrenarás el modelo creando y ejecutando un trabajo de entrenamiento personalizado.
En tu cuaderno de JupyterLab, ejecuta el siguiente comando para crear un trabajo de entrenamiento personalizado:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGIONLa salida debería ser similar a la siguiente. El primer número de cada ruta de trabajo personalizado es el número de proyecto (PROJECT_NUMBER). El segundo número es el ID del trabajo personalizado (CUSTOM_JOB_ID). Anota estos números para poder usarlos en el siguiente paso.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832Ejecuta la tarea de entrenamiento personalizada y muestra el progreso transmitiendo los registros de la tarea mientras se ejecuta:
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_IDSustituye los siguientes valores:
- PROJECT_NUMBER: el número de proyecto de la salida del comando anterior
- CUSTOM_JOB_ID: el ID de trabajo personalizado de la salida del comando anterior
Tu trabajo de entrenamiento personalizado se está ejecutando. Tardará unos 10 minutos en completarse.
Cuando se haya completado la tarea, puedes importar el modelo del bucket de almacenamiento temporal al registro de modelos de Vertex AI.
Importar el modelo
Tu trabajo de entrenamiento personalizado sube el modelo entrenado al bucket de almacenamiento provisional. Cuando se haya completado la tarea, puedes importar el modelo del bucket al registro de modelos de Vertex AI.
En tu cuaderno de JupyterLab, importa el modelo ejecutando el siguiente comando:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGIONLista los modelos de Vertex AI del proyecto de la siguiente manera:
!gcloud ai models list --region=us-central1La salida debería tener el siguiente aspecto. Si se muestran dos o más modelos, el primero de la lista es el que has importado más recientemente.
Anota el valor de la columna MODEL_ID. Lo necesitas para crear la solicitud de inferencia por lotes.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-modelTambién puedes enumerar los modelos de tu proyecto de la siguiente manera:
En la Google Cloud consola, en la sección Vertex AI, ve a la página Registro de modelos de Vertex AI.
Ir a la página Registro de modelos de Vertex AI
Para ver los IDs de modelo y otros detalles de un modelo, haga clic en el nombre del modelo y, a continuación, en la pestaña Detalles de la versión.
Obtener inferencias por lotes del modelo
Ahora puedes solicitar inferencias por lotes del modelo. Las solicitudes de inferencia por lotes se realizan desde la instancia de VM on-prem-client.
Crea la solicitud de inferencia por lotes
En este paso, usará sshpara iniciar sesión en la instancia de VM on-prem-client.
En la instancia de VM, crea un archivo de texto llamado request.json que contenga la carga útil de una solicitud curl de ejemplo que envías a tu modelo para obtener inferencias por lotes.
En Cloud Shell, ejecuta los siguientes comandos y sustituye PROJECT_ID por el ID de tu proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Inicia sesión en la instancia de VM
on-prem-clientconssh:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-aEn la instancia de VM
on-prem-client, usa un editor de texto comovimonanopara crear un archivo llamadorequest.jsonque contenga el siguiente texto:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }Sustituye los siguientes valores:
- PROJECT_ID: tu ID de proyecto
- MODEL_ID: el ID del modelo
- BUCKET_URI: el URI del bucket de almacenamiento en el que has almacenado tu modelo
Ejecuta el siguiente comando para enviar la solicitud de inferencia por lotes:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"Sustituye PROJECT_ID por el ID del proyecto.
Deberías ver la siguiente línea en la respuesta:
"state": "JOB_STATE_PENDING"Tu trabajo de inferencia por lotes ahora se está ejecutando de forma asíncrona. Tarda unos 20 minutos en ejecutarse.
En la Google Cloud consola, en la sección Vertex AI, ve a la página Predicciones por lotes.
Ir a la página Predicciones por lotes
Mientras se ejecuta la tarea de inferencia por lotes, su estado es
Running. Cuando termine, su estado cambiará aFinished.Haga clic en el nombre de su trabajo de inferencia por lotes (
income-classification-batch-job) y, a continuación, en el enlace Ubicación de exportación de la página de detalles para ver los archivos de salida de su trabajo por lotes en Cloud Storage.También puede hacer clic en el icono Ver resultados de la predicción en Cloud Storage (entre la columna Última actualización y el menú Acciones).
Haz clic en el enlace del archivo
prediction.results-00000-of-00002oprediction.results-00001-of-00002y, a continuación, en el enlace URL autenticada para abrir el archivo.La salida del trabajo de inferencia por lotes debería tener un aspecto similar al de este ejemplo:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}