Pour extraire les données de caractéristiques pour l'entraînement de modèle, utilisez la livraison par lots. Si vous devez exporter des valeurs de caractéristiques pour l'archivage ou une analyse ad hoc, exportez plutôt les valeurs de caractéristiques.
Récupérer les valeurs de caractéristiques pour l'entraînement de modèle
Pour l'entraînement d'un modèle, vous avez besoin d'un ensemble de données d'entraînement contenant des exemples de votre tâche de prédiction. Ces exemples sont constitués d'instances qui incluent leurs caractéristiques et leurs étiquettes. L'instance est l'élément sur lequel vous souhaitez effectuer une prédiction. Par exemple, une instance peut être une maison et vous souhaitez déterminer sa valeur de marché. Ses caractéristiques peuvent inclure son emplacement, son âge et le prix moyen des maisons voisines qui ont été vendues récemment. Une étiquette est une réponse à la tâche de prédiction, telle que la vente d'une maison s'est finalement faite à 100 000 $.
Étant donné que chaque étiquette est une observation à un moment spécifique, vous devez extraire des valeurs de caractéristiques correspondant à ce moment où l'observation a été effectuée, telles que les prix des maisons à proximité au moment où une maison particulière a été vendue. Les étiquettes et valeurs de caractéristiques changent au fil de leur collecte. Vertex AI Feature Store (ancienne version) peut effectuer une recherche à un moment précis afin de pouvoir récupérer les valeurs des caractéristiques à un moment donné.
Exemple de recherche à un moment précis
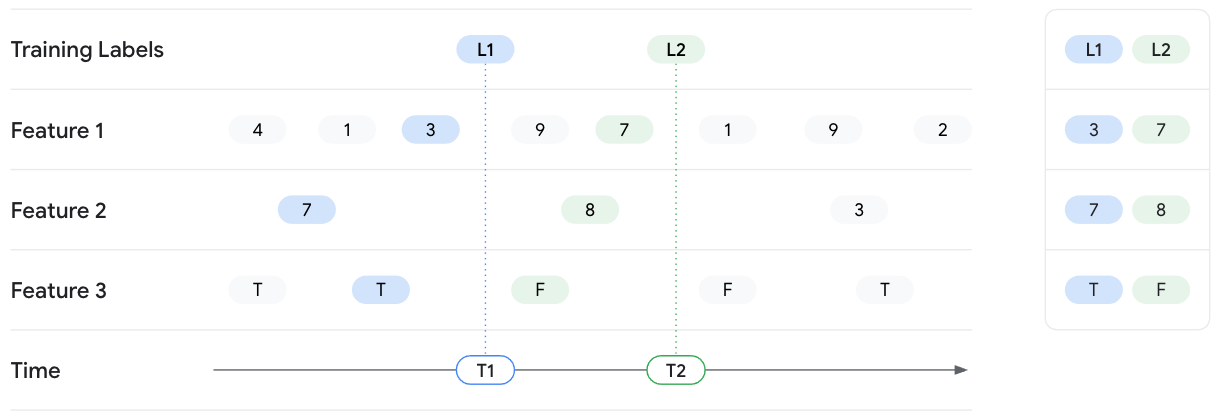
L'exemple suivant implique la récupération des valeurs de caractéristiques pour deux instances d'entraînement avec les étiquettes L1 et L2. Les deux étiquettes sont observées respectivement à T1 et T2. Imaginez que l'état des valeurs de caractéristiques est gelé au niveau de ces horodatages. Par conséquent, pour la recherche à un moment précis T1, Vertex AI Feature Store (ancienne version) renvoie les dernières valeurs de caractéristiques jusqu'à l'instant T1 pour Feature 1, Feature 2 et Feature 3, et ne fuite aucune valeur au-delà de T1. À mesure que le temps évolue, les valeurs de caractéristiques changent tout comme l'étiquette. Ainsi, à T2, Feature Store renvoie différentes valeurs de caractéristiques pour ce moment spécifique.
Entrées pour la livraison par lots
Dans une requête de livraison par lots, les informations suivantes sont requises :
- Liste des caractéristiques pour lesquelles obtenir des valeurs.
- Une liste d'instances en lecture avec des données pour chaque exemple d'entraînement.
Elle comprend les observations à un moment précis. Il peut s'agir d'un fichier CSV ou d'une table BigQuery. Cette liste doit inclure les informations suivantes :
- Codes temporels : moments auxquels les étiquettes ont été observées ou mesurées. Les codes temporels sont obligatoires pour que Vertex AI Feature Store (ancienne version) puisse effectuer une recherche à un moment précis.
- ID d'entité : un ou plusieurs ID des entités qui correspondent à l'étiquette.
- URI de destination et format dans lequel la sortie est écrite. Dans la sortie, Vertex AI Feature Store (ancienne version) joint essentiellement la table à partir de la liste des instances en lecture et les valeurs de caractéristiques à partir du magasin de caractéristiques. Spécifiez l'un des formats et emplacements suivants pour la sortie :
- Table BigQuery dans un ensemble de données régional ou multirégional.
- Fichier CSV dans un bucket Cloud Storage régional ou multirégional. Toutefois, si les valeurs de vos caractéristiques incluent des tableaux, vous devez choisir un autre format.
- Fichier TFRecord dans un bucket Cloud Storage.
Conditions requises pour la région
Pour les instances en lecture et la destination, l'ensemble de données ou le bucket source doit se trouver dans la même région ou dans le même emplacement multirégional que votre magasin de caractéristiques. Par exemple, un magasin de caractéristiques situé dans us-central1 ne peut lire ou livrer des données que depuis ou vers des buckets Cloud Storage ou des ensembles de données BigQuery qui se trouvent dans us-central1 ou dans l'emplacement multirégional "US". Vous ne pouvez pas utiliser de données de, par exemple, us-east1. En outre, il est impossible de lire ou de livrer des données à l'aide de buckets birégionaux.
Liste des instances en lecture
La liste d'instances en lecture spécifie les entités et les codes temporels des valeurs de caractéristiques que vous souhaitez récupérer. Le fichier CSV ou la table BigQuery doivent contenir les colonnes suivantes, dans n'importe quel ordre. Chaque colonne nécessite un en-tête de colonne.
- Vous devez inclure une colonne de code temporel, dont le nom d'en-tête est
timestampet les valeurs de la colonne sont des codes temporels au format RFC 3339. - Vous devez inclure une ou plusieurs colonnes de type d'entité, dont l'en-tête est l'ID du type d'entité et les valeurs de colonne sont les ID d'entité.
- Facultatif : vous pouvez inclure des valeurs répercutées (colonnes supplémentaires), qui sont transmises telles quelles à la sortie. Cela s'avère utile si vous avez des données qui ne se trouvent pas dans Vertex AI Feature Store (ancienne version), mais que vous souhaitez les inclure dans le résultat.
Exemple (fichier CSV)
Imaginons un magasin de caractéristiques contenant les types d'entités users et movies ainsi que leurs caractéristiques. Par exemple, les caractéristiques de users peuvent inclure age et gender, tandis que les caractéristiques de movies peuvent inclure ratings et genre.
Dans cet exemple, vous souhaitez collecter des données d'entraînement concernant les films préférés des utilisateurs. Vous récupérez les valeurs des caractéristiques des deux entités utilisateur alice et bob, ainsi que celles des films qu'elles ont visionnés. Dans un ensemble de données distinct, vous savez que alice a regardé movie_01 et qu'il l'a aimé. bob a regardé movie_02 et n'a pas aimé. Ainsi, la liste des instances en lecture peut ressembler à l'exemple suivant :
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
Vertex AI Feature Store (ancienne version) récupère les valeurs de caractéristiques pour les entités listées aux codes temporels donnés ou avant. Vous spécifiez les caractéristiques spécifiques à exporter lors de la requête de livraison par lots, et non dans la liste des instances en lecture.
Cet exemple inclut également une colonne appelée liked qui indique si un utilisateur a aimé un film. Cette colonne n'est pas incluse dans le magasin de caractéristiques, mais vous pouvez toujours transmettre ces valeurs à la sortie de livraison par lots. Dans le résultat, ces valeurs répercutées sont associées aux valeurs du magasin de caractéristiques.
Valeurs Null
Si, à un code temporel donné, une valeur de caractéristique est "null", Vertex AI Feature Store (ancienne version) renvoie la valeur de caractéristique non nulle précédente. S'il n'existe aucune valeur précédente, Vertex AI Feature Store (ancien) renvoie la valeur "null".
Livrer les valeurs des caractéristiques par lots
Livrez les valeurs de caractéristiques par lots depuis un magasin de caractéristiques pour obtenir des données, comme déterminé par votre fichier de liste d'instances en lecture.
Si vous souhaitez réduire les coûts d'utilisation du stockage hors connexion en lisant les données d'entraînement récentes et en excluant les anciennes données, spécifiez une heure de début. Pour savoir comment réduire le coût d'utilisation du stockage hors connexion en spécifiant une heure de début, consultez Spécifier une heure de début pour optimiser les coûts du stockage hors connexion lors de la livraison et de l'exportation par lots.
UI Web
Utilisez une autre méthode. Vous ne pouvez pas livrer des caractéristiques par lots depuis la consoleGoogle Cloud .
REST
Pour livrer par lots les valeurs des caractéristiques, envoyez une requête POST à l'aide de la méthode featurestores.batchReadFeatureValues.
L'exemple suivant génère une table BigQuery contenant des valeurs de caractéristiques pour les types d'entités users et movies. Notez que chaque destination de sortie peut avoir des conditions préalables avant de vous permettre d'envoyer une requête. Par exemple, si vous spécifiez un nom de table pour le champ bigqueryDestination, vous devez disposer d'un ensemble de données existant. Ces exigences sont décrites dans la documentation de référence de l'API.
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- LOCATION_ID : région dans laquelle le magasin de caractéristiques est créé. Par exemple :
us-central1. - PROJECT_ID : ID de votre projet.
- FEATURESTORE_ID : ID du magasin de caractéristiques.
- DATASET_NAME : nom de l'ensemble de données BigQuery de destination.
- TABLE_NAME : nom de la table BigQuery de destination.
- STORAGE_LOCATION : URI Cloud Storage du fichier CSV des instances en lecture.
Méthode HTTP et URL :
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
Corps JSON de la requête :
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
Un résultat semblable à ce qui suit doit s'afficher. Vous pouvez utiliser OPERATION_ID dans la réponse pour obtenir l'état de l'opération.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
SDK Vertex AI pour Python
Pour savoir comment installer ou mettre à jour le SDK Vertex AI pour Python, consultez Installer le SDK Vertex AI pour Python. Pour en savoir plus, consultez la documentation de référence de l'API SDK Vertex AI pour Python.
Langages supplémentaires
Vous pouvez installer et utiliser les bibliothèques clientes Vertex AI suivantes pour appeler l'API Vertex AI. Les bibliothèques clientes Cloud optimisent l'expérience des développeurs en utilisant les conventions et styles naturels de chaque langage compatible.
Afficher les jobs de livraison par lots
Utilisez la console Google Cloud pour afficher les jobs de livraison par lots dans un projetGoogle Cloud .
UI Web
- Dans la section Vertex AI de la console Google Cloud , accédez à la page Caractéristiques.
- Sélectionnez une région dans la liste déroulante Région.
- Dans la barre d'action, cliquez sur Afficher les jobs de livraison par lots pour lister les jobs de livraison par lots de tous les magasins de caractéristiques.
- Cliquez sur l'ID d'un job de livraison par lots pour en afficher les détails, tels que la source d'instance en lecture utilisée et la destination de sortie.
Étapes suivantes
- Découvrez comment ingérer des valeurs de caractéristiques par lots.
- Apprenez à livrer des caractéristiques avec la livraison en ligne.
- Affichez le quota des jobs par lots simultanés de Vertex AI Feature Store (ancienne version).
- Résolvez les problèmes courants liés à Vertex AI Feature Store (ancienne version).