Model machine learning sering kali merupakan "kotak misteri"; bahkan desainer model tersebut tidak dapat menjelaskan bagaimana atau mengapa model menghasilkan inferensi tertentu. Vertex Explainable AI menawarkan penjelasan berbasis fitur dan berbasis contoh untuk memberikan pemahaman yang lebih baik tentang pengambilan keputusan model.
Dengan mengetahui perilaku model dan bagaimana set data pelatihannya memengaruhi model, siapa saja yang membangun atau menggunakan ML akan memiliki kemampuan baru untuk meningkatkan kualitas model, membangun keyakinan pada inferensinya, serta memahami kapan dan mengapa terjadi hal-hal yang tidak diinginkan.
Penjelasan berbasis contoh
Dengan penjelasan berbasis contoh, Vertex AI menggunakan penelusuran tetangga terdekat untuk menampilkan daftar contoh (biasanya dari set pelatihan) yang paling mirip dengan input. Karena umumnya kita berharap input yang mirip akan menghasilkan inferensi yang mirip pula, kita dapat menggunakan penjelasan ini untuk mengeksplorasi dan menjelaskan perilaku model.
Penjelasan berbasis contoh dapat berguna dalam beberapa skenario:
Meningkatkan kualitas data atau model: Salah satu kasus penggunaan inti untuk penjelasan berbasis contoh adalah membantu Anda memahami alasan model membuat kesalahan tertentu dalam inferensinya, serta menggunakan insight tersebut untuk meningkatkan kualitas data atau model Anda. Untuk melakukannya, pertama-tama pilih data pengujian yang menarik bagi Anda. Pilihan ini bisa didasarkan pada kebutuhan bisnis atau heuristik seperti data di mana model membuat kesalahan parah.
Misalnya, anggaplah kita memiliki model yang mengklasifikasikan gambar sebagai burung atau pesawat dan salah mengklasifikasikan burung berikut sebagai pesawat dengan keyakinan tinggi. Gunakan Penjelasan berbasis contoh untuk mengambil gambar serupa dari set pelatihan guna mencari tahu apa yang terjadi.

Karena semua penjelasannya adalah siluet gelap dari kelas pesawat, hal itu menjadi sinyal untuk mendapatkan lebih banyak siluet burung.
Namun, jika penjelasan itu terutama berasal dari kelas burung, itu adalah sinyal bahwa model kita tidak dapat mempelajari hubungan bahkan ketika datanya lengkap, dan kita harus mempertimbangkan untuk meningkatkan kompleksitas model (misalnya dengan menambahkan lebih banyak lapisan).
Menafsirkan data baru: Anggaplah, untuk saat ini, model Anda telah dilatih untuk mengklasifikasi burung dan pesawat, tetapi di dunia nyata, model tersebut juga menemukan gambar layang-layang, drone, dan helikopter. Jika set data tetangga terdekat Anda menyertakan beberapa gambar berlabel untuk layang-layang, drone, dan helikopter, Anda dapat menggunakan penjelasan berbasis contoh untuk mengklasifikasi gambar baru dengan menerapkan label tetangga terdekat yang paling sering muncul. Hal ini dimungkinkan karena kita mengharapkan representasi laten untuk layang-layang akan berbeda dengan representasi burung atau pesawat, dan lebih mirip dengan layang-layang berlabel dalam set data tetangga terdekat.
Mendeteksi anomali: Secara intuitif, jika sebuah instance jauh dari semua data dalam set pelatihan, kemungkinan itu adalah pencilan. Jaringan neural dikenal terlalu yakin dalam kesalahannya, sehingga menyamarkan error-nya. Memantau model menggunakan penjelasan berbasis contoh membantu mengidentifikasi pencilan yang paling serius.
Pembelajaran aktif: Penjelasan berbasis contoh dapat membantu Anda mengidentifikasi instance yang dapat memperoleh manfaat dari pelabelan manual. Hal ini sangat berguna jika pelabelan lambat atau mahal, sehingga memastikan Anda mendapatkan set data sebanyak mungkin dari resource pelabelan yang terbatas.
Misalnya, anggaplah kita memiliki model yang mengklasifikasi seorang pasien sebagai mengalami demam atau flu. Jika pasien diklasifikasikan sebagai menderita flu, dan semua penjelasan berbasis contoh berasal dari kelas flu, dokter dapat lebih yakin dengan inferensi model tanpa harus melihat lebih dekat. Namun, jika sebagian penjelasan berasal dari kelas flu, dan sebagian lainnya dari kelas demam, pendapat dokter akan diperlukan. Hal ini akan mengarah ke set data di mana instance yang sulit memiliki lebih banyak label, sehingga memudahkan model downstream untuk mempelajari hubungan yang kompleks.
Untuk membuat model yang mendukung penjelasan berbasis contoh, lihat Mengonfigurasi penjelasan berbasis contoh.
Jenis model yang didukung
Semua model TensorFlow yang dapat menyediakan embedding (representasi laten) untuk input didukung. Model berbasis hierarki, seperti pohon keputusan, tidak didukung. Model dari framework lain, seperti PyTorch atau XGBoost, belum didukung.
Untuk jaringan neural dalam, umumnya kita berasumsi bahwa lapisan yang lebih tinggi (lebih dekat dengan lapisan output) telah mempelajari sesuatu yang "bermakna", sehingga lapisan kedua dari atas sering kali dipilih untuk embedding. Lakukan eksperimen dengan beberapa lapisan berbeda, cermati contoh yang Anda peroleh, dan pilih satu lapisan berdasarkan beberapa ukuran kuantitatif (kecocokan kelas) atau kualitatif (terlihat wajar).
Untuk demonstrasi tentang cara mengekstrak embedding dari model TensorFlow dan menjalankan penelusuran tetangga terdekat, lihat notebook penjelasan berbasis contoh.
Penjelasan berbasis fitur
Vertex Explainable AI mengintegrasikan atribusi fitur ke dalam Vertex AI. Bagian ini memberikan ringkasan konseptual singkat tentang metode atribusi fitur yang tersedia dengan Vertex AI.
Atribusi fitur menunjukkan seberapa besar kontribusi setiap fitur dalam model Anda terhadap inferensi untuk setiap instance tertentu. Saat meminta inferensi, Anda mendapatkan nilai yang sesuai untuk model Anda. Saat meminta penjelasan, Anda akan mendapatkan inferensi beserta informasi atribusi fitur.
Atribusi fitur dapat digunakan dengan data tabel, dan mencakup kapabilitas visualisasi bawaan untuk data gambar. Perhatikan contoh berikut:
Sebuah jaringan neural dalam dilatih untuk memprediksi durasi bersepeda berdasarkan data cuaca dan data transportasi online sebelumnya. Jika hanya meminta inferensi dari model ini, Anda akan mendapatkan prediksi durasi bersepeda yang berupa jumlah menit. Jika meminta penjelasan, Anda akan mendapatkan prediksi durasi bersepeda, beserta skor atribusi untuk setiap fitur dalam permintaan penjelasan. Skor atribusi menunjukkan seberapa besar fitur tersebut memengaruhi perubahan nilai inferensi, yang relatif terhadap nilai dasar pengukuran yang Anda tentukan. Pilih dasar pengukuran yang bermakna yang sesuai untuk model Anda, - dalam hal ini, durasi median bersepeda. Anda dapat memetakan skor atribusi fitur untuk melihat fitur mana yang paling berkontribusi terhadap inferensi yang dihasilkan:
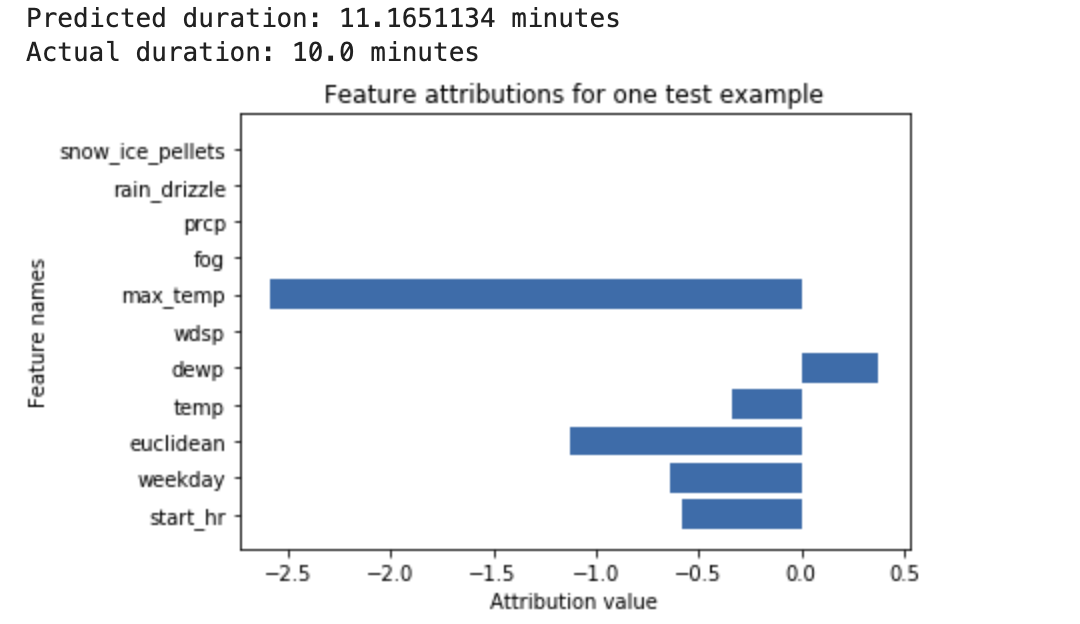
Model klasifikasi gambar dilatih untuk memprediksi apakah gambar tertentu berisi atau kucing. Jika Anda meminta inferensi dari model ini berdasarkan sekumpulan gambar baru, Anda akan menerima inferensi untuk setiap gambar ("" atau "kucing"). Jika meminta penjelasan, Anda akan mendapatkan prediksi kelas beserta overlay untuk gambar itu, yang menunjukkan piksel mana dalam gambar yang paling berkontribusi terhadap inferensi yang dihasilkan:

Foto kucing dengan overlay atribusi fitur 
Foto anjing dengan overlay atribusi fitur Sebuah model klasifikasi gambar dilatih untuk memprediksi spesies bunga dalam gambar. Jika Anda meminta inferensi dari model ini berdasarkan sekumpulan gambar baru, Anda akan menerima inferensi untuk setiap gambar ("daisy" atau "dandelion"). Jika meminta penjelasan, Anda akan mendapatkan prediksi kelas beserta overlay untuk gambar itu, yang menunjukkan area mana dalam gambar yang paling berkontribusi terhadap inferensi yang dihasilkan:

Foto bunga aster dengan overlay atribusi fitur
Jenis model yang didukung
Atribusi fitur didukung untuk semua jenis model (baik AutoML maupun yang dilatih khusus), framework (TensorFlow, scikit, XGBoost), model BigQuery ML, dan modalitas (gambar, teks, tabel).
Untuk menggunakan atribusi fitur, konfigurasi model Anda untuk atribusi fitur saat mengupload atau mendaftarkan model tersebut ke Vertex AI Model Registry.
Selain itu, untuk jenis model AutoML berikut, atribusi fitur terintegrasi ke dalam konsol Google Cloud :
- Model gambar AutoML (khusus model klasifikasi)
- Model tabel AutoML (khusus model klasifikasi dan regresi)
Untuk jenis model AutoML yang terintegrasi, Anda dapat mengaktifkan atribusi fitur di konsol Google Cloud selama pelatihan dan melihat tingkat kepentingan fitur model untuk model tersebut secara keseluruhan, dan tingkat kepentingan fitur lokal baik untuk inferensi online maupun batch.
Untuk jenis model AutoML yang tidak terintegrasi, Anda masih dapat mengaktifkan atribusi fitur dengan mengekspor artefak model dan mengonfigurasi atribusi fitur saat mengupload artefak model ke Vertex AI Model Registry.
Kelebihan
Dengan memeriksa instance tertentu, dan juga menggabungkan atribusi fitur di seluruh set data pelatihan, Anda dapat memperoleh insight lebih dalam tentang cara kerja model. Pertimbangkan kelebihan berikut:
Men-debug model: Atribusi fitur dapat membantu mendeteksi masalah dalam data yang biasanya terlewatkan oleh teknik evaluasi model standar.
Misalnya, model patologi gambar mencapai hasil bagus (meski mencurigakan) pada set data uji gambar Sinar-X dada. Atribusi fitur mengungkapkan bahwa akurasi tinggi model bergantung pada tanda pena ahli radiologi pada gambar. Untuk detail selengkapnya tentang contoh ini, lihat Laporan Resmi AI Explanations.
Mengoptimalkan model: Anda dapat mengidentifikasi dan menghapus fitur yang kurang penting, sehingga menghasilkan model yang lebih efisien.
Metode atribusi fitur
Setiap metode atribusi fitur didasarkan pada nilai Shapley—sebuah algoritma teori game kooperatif yang menetapkan kredit kepada setiap pemain dalam game untuk hasil tertentu. Jika diterapkan pada model machine learning, setiap fitur model diperlakukan sebagai "pemain" dalam game. Vertex Explainable AI menetapkan kredit yang proporsional ke setiap fitur untuk hasil inferensi tertentu.
Metode Sampled Shapley
Metode Sampled Shapley memberikan perkiraan sampling dari nilai pasti Shapley. Model tabel AutoML menggunakan metode Sampled Shapley untuk tingkat kepentingan fitur. Sampled Shapley sangat cocok untuk model ini, yang merupakan meta-ansambel dari pohon dan jaringan neural.
Untuk informasi mendalam tentang cara kerja metode Sampled Shapley, baca makalah Bounding the Estimation Error of Sampling-based Shapley Value Approximation.
Metode Integrated Gradients
Dalam metode Integrated Gradients, gradien output inferensi dihitung dalam kaitannya dengan fitur input, di sepanjang jalur integral.
- Gradien dihitung pada interval parameter penskalaan yang berbeda. Ukuran setiap interval ditentukan menggunakan aturan kuadratur Gauss. (Untuk data gambar, bayangkan parameter penskalaan ini sebagai "penggeser" yang menskalakan semua piksel gambar menjadi hitam.)
- Gradien diintegrasikan sebagai berikut:
- Integral diperkiraan menggunakan rata-rata tertimbang.
- Hasil per elemen dari rata-rata gradien dan input asli akan dihitung.
Untuk penjelasan intuitif mengenai proses ini dalam penerapannya pada gambar, lihat postingan blog "Attributing a deep network's inference to its input features". Penulis makalah asli tentang Integrated Gradients (Axiomatic Attribution for Deep Networks) menunjukkan dalam postingan blog sebelumnya seperti apa tampilan gambar di setiap langkah prosesnya.
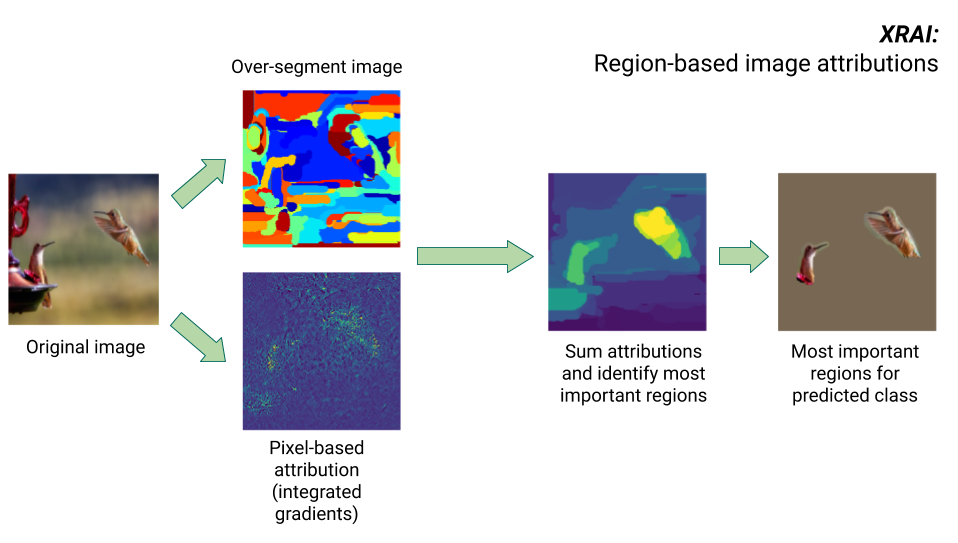
Metode XRAI
Metode XRAI menggabungkan metode Integrated Gradients dengan beberapa langkah tambahan untuk menentukan area gambar yang paling berkontribusi terhadap inferensi kelas tertentu.
- Atribusi tingkat piksel: XRAI menjalankan atribusi tingkat piksel untuk gambar input. Pada langkah ini, XRAI menggunakan metode Integrated Gradients dengan baseline hitam dan baseline putih.
- Oversegmentasi: Terlepas dari atribusi tingkat piksel, XRAI meng-oversegmentasi gambar untuk membuat tambal sulam area-area kecil. XRAI menggunakan metode berbasis grafik Felzenswalb untuk membuat segmen gambar.
- Pemilihan area: XRAI menggabungkan atribusi tingkat piksel dalam setiap segmen untuk menentukan kepadatan atribusinya. Berdasarkan nilai ini, XRAI memeringkatkan setiap segmen, lalu mengurutkan segmen tersebut dari yang paling positif ke paling tidak positif. Pengurutan ini menentukan area mana pada gambar yang paling kentara, atau paling berkontribusi terhadap inferensi kelas tertentu.
Membandingkan metode atribusi fitur
Vertex Explainable AI menawarkan tiga metode yang dapat digunakan untuk atribusi fitur: Sampel Shapley, Integrated Gradients, dan XRAI.
| Metode | Penjelasan dasar | Jenis model yang direkomendasikan | Contoh kasus penggunaan | Resource Model Vertex AI yang kompatibel |
|---|---|---|---|---|
| Sampled Shapley | Menetapkan kredit hasil ke setiap fitur, dan mempertimbangkan berbagai permutasi fitur. Metode ini memberikan perkiraan sampling dari nilai pasti Shapley. | Model tidak terdiferensiasi, seperti ansambel pohon dan jaringan neural |
|
|
| Integrated Gradients | Metode berbasis gradien untuk mengomputasi atribusi fitur secara efisien dengan properti aksiomatik yang sama dengan nilai Shapley. | Model terdiferensiasi, seperti jaringan neural. Direkomendasikan terutama untuk model dengan ruang fitur yang besar. Direkomendasikan untuk gambar berkontras rendah, seperti sinar-X. |
|
|
| XRAI (eXplanation with Ranked Area Integrals) | Berdasarkan metode Integrated Gradients, XRAI menilai area gambar yang tumpang-tindih untuk membuat peta saliency, yang menyoroti area gambar yang relevan, bukan piksel. | Model yang menerima input gambar. Direkomendasikan terutama untuk gambar natural, yaitu suasana dunia nyata yang berisi banyak objek. |
|
|
Untuk perbandingan metode atribusi yang lebih menyeluruh, lihat Laporan Resmi AI Explanations.
Model terdiferensiasi dan tidak terdiferensiasi
Pada model terdiferensiasi, Anda dapat mengkalkulasi turunan dari semua operasi dalam grafik TensorFlow. Dengan properti ini, propagasi mundur dalam model tersebut dapat dibuat. Misalnya, jaringan neural bersifat terdiferensiasi. Untuk mendapatkan atribusi fitur bagi model terdiferensiasi, gunakan metode Integrated Gradients.
Metode Integrated Gradients tidak dapat digunakan dengan model tidak terdiferensiasi. Pelajari lebih lanjut cara mengenkode input yang tidak terdiferensiasi agar dapat digunakan dengan metode Integrated Gradients.
Model tidak terdiferensiasi mencakup operasi yang tidak terdiferensiasi dalam grafik TensorFlow, seperti operasi yang menjalankan tugas decoding dan pembulatan. Misalnya, model yang dibangun sebagai ansambel pohon dan jaringan neural termasuk tidak terdiferensiasi. Untuk mendapatkan atribusi fitur bagi model tidak terdiferensiasi, gunakan metode Sampled Shapley. Sampled Shapley juga dapat digunakan dengan model terdiferensiasi, tetapi dalam hal ini, secara komputasi metode ini lebih mahal daripada yang diperlukan.
Batasan konseptual
Pertimbangkan batasan atribusi fitur berikut:
Atribusi fitur, termasuk nilai penting fitur lokal untuk AutoML, bersifat khusus untuk masing-masing inferensi. Memeriksa atribusi fitur untuk inferensi individual dapat memberikan insight yang baik, meskipun mungkin tidak dapat digeneralisasi ke seluruh kelas untuk instance individual tersebut, atau ke seluruh model.
Untuk mendapatkan insight yang lebih umum untuk model AutoML, lihat nilai penting fitur model. Untuk mendapatkan insight yang dapat digeneralisasi untuk model lain, gabungkan atribusi atas subset dengan set data Anda, atau seluruh set data.
Meskipun dapat membantu proses debug model, atribusi fitur tidak selalu menunjukkan dengan jelas apakah masalah muncul dari model atau dari data yang digunakan untuk melatih model. Gunakan penilaian terbaik Anda, dan diagnosis masalah data yang umum untuk mempersempit kemungkinan penyebabnya.
Atribusi fitur dapat mengalami serangan adversarial yang serupa dengan inferensi dalam model yang kompleks.
Untuk informasi selengkapnya tentang batasan, lihat daftar batasan tingkat tinggi dan Laporan Resmi AI Explanations.
Referensi
Untuk atribusi fitur, penerapan Sampled Shapley, Integrated Gradients, dan XRAI secara berturut-turut didasarkan pada referensi berikut:
- Bounding the Estimation Error of Sampling-based Shapley Value Approximation
- Axiomatic Attribution for Deep Networks
- XRAI: Better Attributions Through Regions
Pelajari lebih lanjut implementasi Vertex Explainable AI dengan membaca Laporan Resmi AI Explanations.
Notebook
Untuk mulai menggunakan Vertex Explainable AI, gunakan notebook berikut:
| Notebook | Metode Explainability | Framework ML | Modalitas | Tugas |
|---|---|---|---|---|
| Link GitHub | Penjelasan berbasis contoh | TensorFlow | gambar | Melatih model klasifikasi yang memprediksi kelas gambar input yang diberikan dan mendapatkan penjelasan online |
| Link GitHub | berbasis fitur | AutoML | tabel | Melatih model klasifikasi biner yang memprediksi apakah nasabah bank membeli deposito berjangka dan mendapatkan penjelasan batch |
| Link GitHub | berbasis fitur | AutoML | tabel | Melatih model klasifikasi yang memprediksi jenis spesies bunga Iris dan mendapatkan penjelasan online |
| Link GitHub | berbasis fitur (Sampled Shapley) | scikit-learn | tabel | Melatih model regresi linier yang memprediksi tarif taksi dan mendapatkan penjelasan online |
| Link GitHub | berbasis fitur (Integrated Gradients) | TensorFlow | gambar | Melatih model klasifikasi yang memprediksi kelas gambar input yang diberikan dan mendapatkan penjelasan batch |
| Link GitHub | berbasis fitur (Integrated Gradients) | TensorFlow | gambar | Melatih model klasifikasi yang memprediksi kelas gambar input yang diberikan dan mendapatkan penjelasan online |
| Link GitHub | berbasis fitur (Integrated Gradients) | TensorFlow | tabel | Melatih model regresi yang memprediksi rerata harga rumah dan mendapatkan penjelasan batch |
| Link GitHub | berbasis fitur (Integrated Gradients) | TensorFlow | tabel | Melatih model regresi yang memprediksi rerata harga rumah dan mendapatkan penjelasan online |
| Link GitHub | berbasis fitur (Sampled Shapley) | TensorFlow | teks | Melatih model LSTM yang mengklasifikasi ulasan film sebagai positif atau negatif menggunakan teks ulasan dan mendapatkan penjelasan online |
Materi edukasi
Referensi berikut memberikan materi edukasi bermanfaat lainnya:
- Explainable AI for Practitioners
- Interpretable Machine Learning: Shapley values
- Repository GitHub Integrated Gradients Ankur Taly.
- Introduction to Shapley values
Langkah berikutnya
- Konfigurasi model untuk penjelasan berbasis fitur
- Konfigurasi model untuk penjelasan berbasis contoh
- Lihat tingkat kepentingan fitur untuk model tabel AutoML.