Para usar las explicaciones basadas en ejemplos, debe configurar las explicaciones especificando un explanationSpec al importar o subir el recurso Model al registro de modelos.
Después, cuando solicite explicaciones online, podrá anular algunos de esos valores de configuración especificando un ExplanationSpecOverride en la solicitud. No puedes solicitar explicaciones por lotes, ya que no se admiten.
En esta página se describe cómo configurar y actualizar estas opciones.
Configurar explicaciones al importar o subir el modelo
Antes de empezar, asegúrate de que tienes lo siguiente:
Ubicación de Cloud Storage que contiene los artefactos del modelo. Tu modelo debe ser una red neuronal profunda (DNN) en la que proporciones el nombre de una capa o una firma cuya salida se pueda usar como espacio latente. También puedes proporcionar un modelo que genere directamente las inserciones (representación del espacio latente). Este espacio latente captura las representaciones de ejemplo que se usan para generar explicaciones.
Ubicación de Cloud Storage que contiene las instancias que se van a indexar para la búsqueda del vecino más cercano aproximado. Para obtener más información, consulta los requisitos de los datos de entrada.
Consola
Sigue la guía para importar un modelo con la consola Google Cloud .
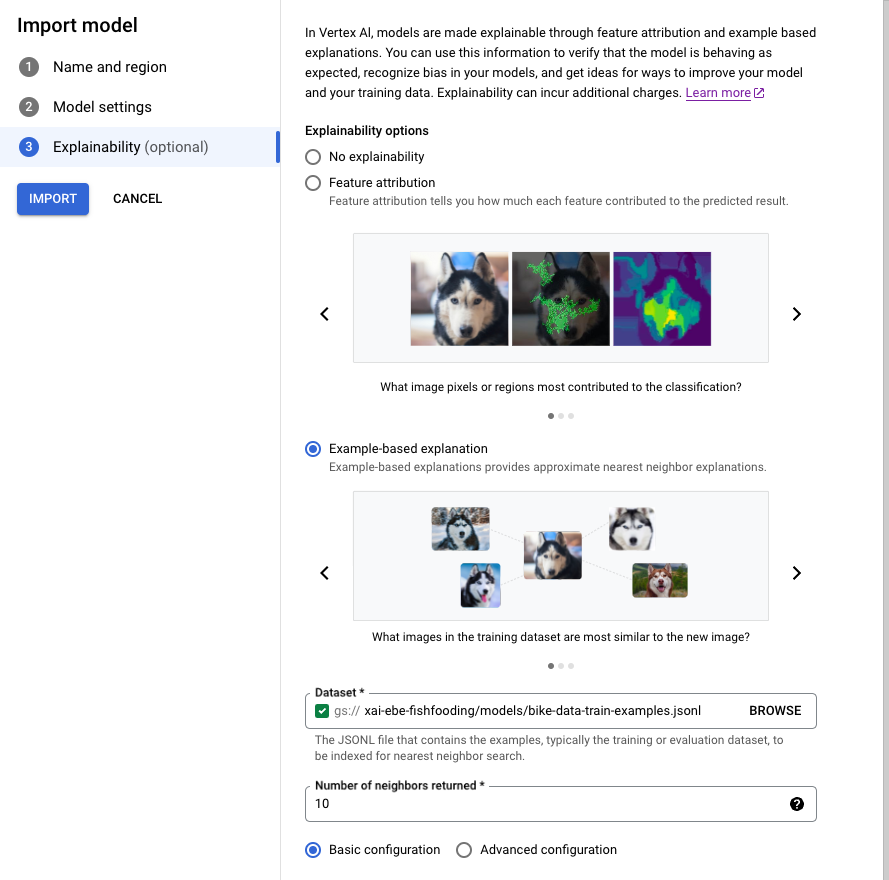
En la pestaña Explicabilidad, selecciona Explicación basada en ejemplos y rellena los campos.
Para obtener información sobre cada campo, consulta los consejos de la Google Cloud consola
(que se muestran a continuación), así como la documentación de referencia de Example y ExplanationMetadata.
CLI de gcloud
- Escribe lo siguiente
ExplanationMetadataen un archivo JSON de tu entorno local. El nombre del archivo no importa, pero, en este ejemplo, llámaloexplanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (Opcional) Si vas a especificar el
NearestNeighborSearchConfigcompleto, escribe lo siguiente en un archivo JSON de tu entorno local. El nombre del archivo no importa, pero en este ejemplo, llámalosearch_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- Ejecuta el siguiente comando para subir tu
Model.
Si usas una configuración de búsqueda Preset, quita la marca --explanation-nearest-neighbor-search-config-file. Si especificas NearestNeighborSearchConfig,
quita las marcas --explanation-modality y --explanation-query.
Las marcas más pertinentes para las explicaciones basadas en ejemplos se muestran en negrita.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
Consulta gcloud ai models upload para obtener más información.
-
La acción de subida devuelve un
OPERATION_IDque se puede usar para comprobar cuándo se ha completado la operación. Puedes sondear el estado de la operación hasta que la respuesta incluya"done": true. Usa el comando gcloud ai operations describe para consultar el estado. Por ejemplo:gcloud ai operations describe <operation-id>No podrás solicitar explicaciones hasta que se haya completado la operación. En función del tamaño del conjunto de datos y de la arquitectura del modelo, este paso puede tardar varias horas en crear el índice que se usa para consultar ejemplos.
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT
- LOCATION
Para obtener información sobre los demás marcadores de posición, consulta Model, explanationSpec y Examples.
Para obtener más información sobre cómo subir modelos, consulta el método upload y el artículo Importar modelos.
El cuerpo de la solicitud JSON que se muestra a continuación especifica una configuración de búsqueda Preset. También puedes especificar el NearestNeighborSearchConfig completo.
Método HTTP y URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
Cuerpo JSON de la solicitud:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
La acción de subida devuelve un OPERATION_ID que se puede usar para comprobar cuándo se ha completado la operación. Puedes sondear el estado de la operación hasta que la respuesta incluya "done": true. Usa el comando gcloud ai operations describe para consultar el estado. Por ejemplo:
gcloud ai operations describe <operation-id>
No podrás solicitar explicaciones hasta que se haya completado la operación. En función del tamaño del conjunto de datos y de la arquitectura del modelo, este paso puede tardar varias horas en crear el índice que se usa para consultar ejemplos.
Python
Consulta la sección Subir el modelo en el cuaderno de explicaciones basadas en ejemplos de clasificación de imágenes.
NearestNeighborSearchConfig
El siguiente cuerpo de solicitud JSON muestra cómo especificar el NearestNeighborSearchConfig completo (en lugar de los preajustes) en una solicitud upload.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
En estas tablas se enumeran los campos de NearestNeighborSearchConfig.
| Campos | |
|---|---|
dimensions |
Obligatorio. Número de dimensiones de los vectores de entrada. Se usa solo para inserciones densas. |
approximateNeighborsCount |
Obligatorio si se usa el algoritmo tree-AH. Número predeterminado de vecinos que se deben encontrar mediante la búsqueda aproximada antes de que se realice la reordenación exacta. El reordenamiento exacto es un procedimiento en el que los resultados devueltos por un algoritmo de búsqueda aproximada se reordenan mediante un cálculo de distancia más costoso. |
ShardSize |
ShardSize
El tamaño de cada fragmento. Cuando un índice es grande, se fragmenta según el tamaño de fragmento especificado. Durante el servicio, cada fragmento se sirve en un nodo independiente y se escala de forma independiente. |
distanceMeasureType |
La medida de distancia utilizada en la búsqueda de vecinos más cercanos. |
featureNormType |
Tipo de normalización que se va a llevar a cabo en cada vector. |
algorithmConfig |
oneOf:
Configuración de los algoritmos que usa la búsqueda de vectores para realizar búsquedas eficientes. Se usa solo para las inserciones densas.
|
DistanceMeasureType
| Enumeraciones | |
|---|---|
SQUARED_L2_DISTANCE |
Distancia euclidiana (L2) |
L1_DISTANCE |
Distancia de Manhattan (L1) |
DOT_PRODUCT_DISTANCE |
Valor predeterminado. Se define como el negativo del producto escalar. |
COSINE_DISTANCE |
Distancia del coseno. Te recomendamos que uses DOT_PRODUCT_DISTANCE + UNIT_L2_NORM en lugar de la distancia COSINE. Nuestros algoritmos se han optimizado más para la distancia DOT_PRODUCT y, cuando se combinan con UNIT_L2_NORM, ofrecen la misma clasificación y equivalencia matemática que la distancia COSINE. |
FeatureNormType
| Enumeraciones | |
|---|---|
UNIT_L2_NORM |
Tipo de normalización de la unidad L2. |
NONE |
Valor predeterminado. No se ha especificado ningún tipo de normalización. |
TreeAhConfig
Estos son los campos que se deben seleccionar para el algoritmo de árbol AH (árbol superficial + hash asimétrico).
| Campos | |
|---|---|
fractionLeafNodesToSearch |
double |
| Fracción predeterminada de nodos hoja que se pueden buscar en cualquier consulta. Debe estar en el intervalo [0,0, 1,0], ambos excluidos. El valor predeterminado es 0,05 si no se define. | |
leafNodeEmbeddingCount |
int32 |
| Número de inserciones en cada nodo hoja. El valor predeterminado es 1000 si no se define. | |
leafNodesToSearchPercent |
int32 |
Obsoleto, usa fractionLeafNodesToSearch.Porcentaje predeterminado de nodos hoja que se pueden buscar en cualquier consulta. Debe estar comprendido entre 1 y 100, ambos incluidos. El valor predeterminado es 10 (es decir, el 10%) si no se define. |
|
BruteForceConfig
Esta opción implementa la búsqueda lineal estándar en la base de datos para cada consulta. No hay campos que configurar para una búsqueda de fuerza bruta. Para seleccionar este algoritmo, pasa un objeto vacío para BruteForceConfig a algorithmConfig.
Requisitos de los datos de entrada
Sube tu conjunto de datos a una ubicación de Cloud Storage. Asegúrate de que los archivos tengan el formato JSON Lines.
Los archivos deben estar en formato JSON Lines. El siguiente ejemplo procede del cuaderno de explicaciones basadas en ejemplos de clasificación de imágenes:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
Actualizar el índice o la configuración
Vertex AI te permite actualizar el índice de vecinos más cercanos de un modelo o la configuración de Example. Esto es útil si quieres actualizar tu modelo sin volver a indexar su conjunto de datos. Por ejemplo, si el índice de tu modelo contiene 1000 instancias y quieres añadir 500 más, puedes llamar a UpdateExplanationDataset para añadirlo al índice sin volver a procesar las 1000 instancias originales.
Para actualizar el conjunto de datos de explicación, sigue estos pasos:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
Notas sobre el uso:
El
model_idno cambia después de la operaciónUpdateExplanationDataset.La operación
UpdateExplanationDatasetsolo afecta al recursoModel; no actualiza ningúnDeployedModelasociado. Esto significa que el índice de undeployedModelcontiene el conjunto de datos en el momento en que se implementó. Para actualizar el índice de undeployedModel, debes volver a desplegar el modelo actualizado en un endpoint.
Anular la configuración al obtener explicaciones online
Cuando solicites una explicación, puedes anular algunos de los parámetros sobre la marcha especificando el campo ExplanationSpecOverride.
En función de la aplicación, puede que sea conveniente aplicar algunas restricciones al tipo de explicaciones que se devuelven. Por ejemplo, para asegurar la diversidad de las explicaciones, un usuario puede especificar un parámetro de saturación que determine que no se represente en exceso ningún tipo de ejemplo en las explicaciones. En concreto, si un usuario intenta averiguar por qué su modelo ha etiquetado un pájaro como un avión, puede que no le interese ver demasiados ejemplos de pájaros como explicaciones para investigar mejor la causa principal.
En la siguiente tabla se resumen los parámetros que se pueden anular en una solicitud de explicación basada en ejemplos:
| Nombre de propiedad | Valor de propiedad | Descripción |
|---|---|---|
| neighborCount | int32 |
Número de ejemplos que se devuelven como explicación. |
| crowdingCount | int32 |
Número máximo de ejemplos que se devolverán con la misma etiqueta de aglomeración |
| Permitir | String Array |
Las etiquetas que se pueden usar en las explicaciones |
| deny | String Array |
Las etiquetas que no se permiten en las explicaciones |
En Filtrado de Vector Search se describen estos parámetros con más detalle.
A continuación se muestra un ejemplo de un cuerpo de solicitud JSON con anulaciones:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
Siguientes pasos
A continuación, se muestra un ejemplo de la respuesta a una solicitud explain basada en ejemplos:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
Precios
Consulta la sección sobre explicaciones basadas en ejemplos de la página de precios.