Para usar explicações baseadas em exemplos, é necessário configurar as explicações especificando uma
explanationSpec
ao importar ou fazer upload do Model
no Modelo de registro.
Em seguida, ao solicitar explicações on-line, é possível modificar alguns desses valores de configuração especificando um ExplanationSpecOverride na solicitação. Não é possível solicitar explicações em lote. Eles não são compatíveis.
Esta página descreve como configurar e atualizar essas opções.
Configurar explicações ao importar ou fazer upload do modelo
Antes de começar, verifique se você tem o seguinte:
Um local do Cloud Storage que contém os artefatos do modelo. O modelo precisa ser um modelo de rede neural profunda (DNN, na sigla em inglês) em que você fornece o nome de uma camada ou assinatura, cuja saída pode ser usada como espaço latente ou você pode fornecer um modelo que gera diretamente embeddings (representação de espaço atrasado). Esse espaço latente captura as representações de exemplo usadas para gerar explicações.
Um local do Cloud Storage que contém as instâncias a serem indexadas para a pesquisa do vizinho mais próximo. Para mais informações, consulte Requisitos de dados de entrada.
Console
Siga o guia para importar um modelo usando o console Google Cloud .
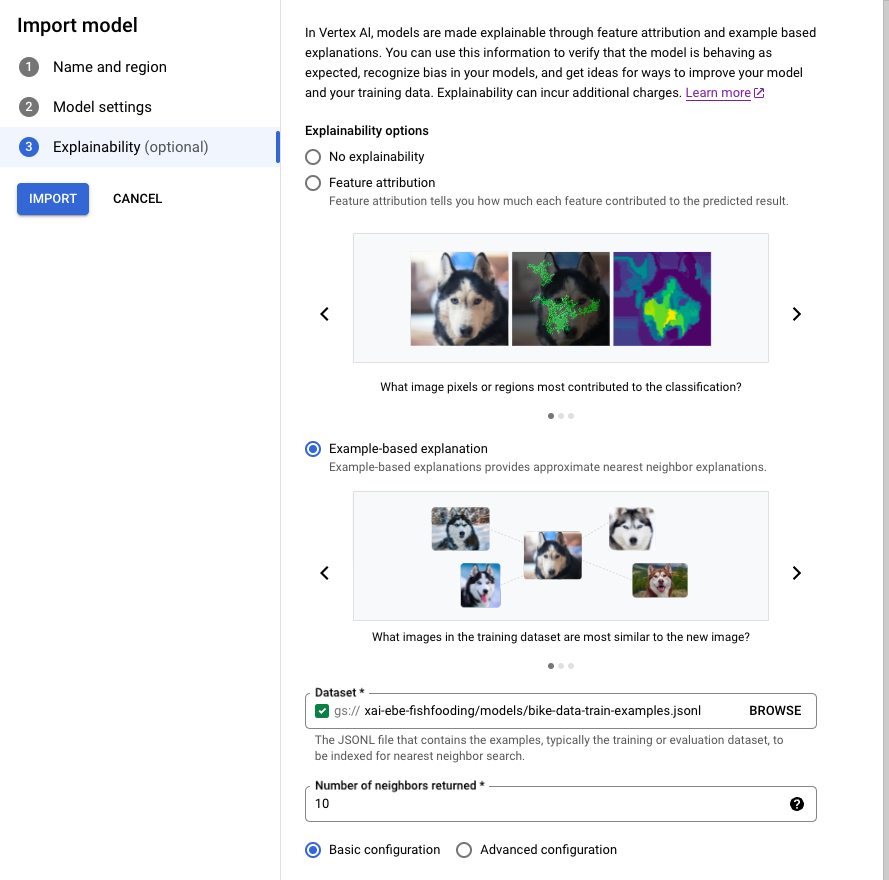
Na guia Explicabilidade, selecione Explicação baseada em exemplos e preencha os campos.
Para informações sobre cada campo, consulte as dicas no console Google Cloud
(mostradas abaixo), bem como a documentação de referência para Example e ExplanationMetadata.
CLI da gcloud
- Grave o seguinte
ExplanationMetadataem um arquivo JSON no seu ambiente local. O nome de arquivo não importa, mas, neste exemplo, chame o arquivoexplanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (Opcional) Se você estiver especificando o
NearestNeighborSearchConfigcompleto, grave o seguinte em um arquivo JSON no seu ambiente local. O nome de arquivo não importa, mas, neste exemplo, chame o arquivosearch_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- Execute o seguinte comando para fazer upload do
Model.
Se você estiver usando uma configuração de pesquisa Preset, remova a flag --explanation-nearest-neighbor-search-config-file. Se você estiver especificando NearestNeighborSearchConfig, remova as sinalizações --explanation-modality e --explanation-query.
As flags mais pertinentes às explicações baseadas em exemplos ficam em negrito.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
Para mais informações, consulte gcloud ai models upload.
-
A ação de upload retorna um
OPERATION_IDque pode ser usado para verificar quando a operação foi concluída. Pesquise o status da operação até que a resposta inclua"done": true. Use o comando gcloud ai operations describe para pesquisar o status, por exemplo:gcloud ai operations describe <operation-id>Não é possível solicitar explicações até que a operação seja concluída. Dependendo do tamanho do conjunto de dados e da arquitetura de modelo, essa etapa pode levar várias horas para criar o índice usado para consultar exemplos.
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT
- LOCATION
Para saber mais sobre os outros marcadores, consulte Model, explanationSpec e Examples.
Para saber mais sobre como fazer upload de modelos, consulte o método upload e Como importar modelos.
O corpo da solicitação JSON abaixo especifica uma configuração de pesquisa Preset. Como alternativa, você pode especificar o NearestNeighborSearchConfig completo.
Método HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
Corpo JSON da solicitação:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
A ação de upload retorna um OPERATION_ID que pode ser usado para verificar quando a
operação foi concluída. Pesquise o status da operação até que a resposta inclua "done": true. Use o comando gcloud ai operations describe para pesquisar o status, por exemplo:
gcloud ai operations describe <operation-id>
Não é possível solicitar explicações até que a operação seja concluída. Dependendo do tamanho do conjunto de dados e da arquitetura de modelo, essa etapa pode levar várias horas para criar o índice usado para consultar exemplos.
Python
Consulte a seção Fazer upload do modelo no notebook com explicações baseadas em exemplos de classificação de imagens.
NearestNeighborSearchConfig
O corpo da solicitação JSON a seguir demonstra como especificar o NearestNeighborSearchConfig completo (em vez de predefinições) em uma solicitação upload.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
Essas tabelas listam os campos para NearestNeighborSearchConfig.
| Campos | |
|---|---|
dimensions |
Obrigatório. O número de dimensões dos vetores de entrada. Usado apenas para embeddings densos. |
approximateNeighborsCount |
Obrigatório se o algoritmo tree-AH for usado. O número padrão de vizinhos que será encontrado por meio da pesquisa de aproximação antes da reordenação exata ser realizada. A reordenação exata é um procedimento em que os resultados retornados por um algoritmo de pesquisa aproximada são reordenados usando um cálculo de distância mais caro. |
ShardSize |
ShardSize
O tamanho de cada fragmento. Quando um índice é grande, ele é fragmentado com base no tamanho do fragmento especificado. Durante a disponibilização, cada fragmento é exibido em um nó separado e é escalonado de maneira independente. |
distanceMeasureType |
A medida de distância usada na pesquisa de vizinho mais próxima. |
featureNormType |
Tipo de normalização a ser realizada em cada vetor. |
algorithmConfig |
oneOf:
A configuração dos algoritmos usados pelo Vector Search para uma pesquisa eficiente. Usado apenas para embeddings densos.
|
DistanceMeasureType
| Enums | |
|---|---|
SQUARED_L2_DISTANCE |
Distância euclidiana (L2) |
L1_DISTANCE |
Distância de Manhattan (L1) |
DOT_PRODUCT_DISTANCE |
Valor padrão. Definido como um negativo do produto de ponto. |
COSINE_DISTANCE |
Distância do cosseno. Sugerimos usar DOT_PRODUCT_DISTANCE + UNIT_L2_NORM em vez da distância COSINE. Nossos algoritmos foram mais otimizados para a distância DOT_PRODUCT e, quando combinado com UNIT_L2_NORM, oferece a mesma classificação e equivalência matemática que a distância COSINE. |
FeatureNormType
| Enums | |
|---|---|
UNIT_L2_NORM |
Tipo de normalização da unidade L2. |
NONE |
Valor padrão. Nenhum tipo de normalização foi especificado. |
TreeAhConfig
Esses são os campos a serem selecionados para o algoritmo árvore-AH (árvore superficial + hash assimétrica).
| Campos | |
|---|---|
fractionLeafNodesToSearch |
double |
| A porcentagem padrão de nós de folha em que qualquer consulta pode ser pesquisada. Precisa estar entre 0,0 e 1,0, exclusivamente. Se não for definido, o valor padrão será 0.05. | |
leafNodeEmbeddingCount |
int32 |
| Número de embeddings em cada nó de folha. Se não for definido, o valor padrão será 1.000. | |
leafNodesToSearchPercent |
int32 |
fractionLeafNodesToSearchObsoleto: use .A porcentagem padrão de nós de folha em que qualquer consulta pode ser pesquisada. Precisa estar no intervalo 1-100, inclusive. Se não for definido, o valor padrão será 10 (significa 10%). |
|
BruteForceConfig
Essa opção implementa a pesquisa linear padrão no banco de dados para cada
consulta. Não há campos para configurar para uma pesquisa de força bruta. Para selecionar esse
algoritmo, transmita um objeto vazio de BruteForceConfig para algorithmConfig.
Requisitos de dados de entrada
Faça upload do conjunto de dados para um local do Cloud Storage. Verifique se os arquivos estão no formato de linhas JSON.
Os arquivos precisam estar no formato Linhas JSON. A amostra a seguir é do notebook com base em exemplos de classificação de imagens:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
Atualizar o índice ou a configuração
A Vertex AI permite atualizar o índice vizinho mais próximo ou a configuração Example de um modelo. Isso é útil se você quiser atualizar o modelo sem reindexar o conjunto de dados. Por exemplo, se o índice do modelo contiver 1.000 instâncias e você quiser adicionar mais 500 instâncias, chame UpdateExplanationDataset para adicionar ao índice. sem reprocessar as 1.000 instâncias originais.
Para atualizar o conjunto de dados de explicação:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
Observações sobre o uso:
O
model_idpermanece inalterado após a operaçãoUpdateExplanationDataset.A operação
UpdateExplanationDatasetafeta apenas o recursoModel. Ela não atualizaDeployedModels associados. Isso significa que o índice dedeployedModelcontém o conjunto de dados no momento da implantação. Para atualizar o índice de umdeployedModel, implante novamente o modelo atualizado em um endpoint.
Substituir a configuração ao receber explicações on-line
Ao solicitar uma explicação, é possível substituir alguns dos parâmetros em tempo real. Basta especificar o campo ExplanationSpecOverride.
Dependendo do aplicativo, algumas restrições podem ser desejáveis no tipo de explicações retornadas. Por exemplo, para garantir a diversidade de explicações, o usuário pode especificar um parâmetro de recolhimento que determina que nenhum tipo único de exemplos é muito representado nas explicações. Conceitualmente, se um usuário está tentando entender por que um pássaro foi rotulado como um plano pelo modelo, ele pode não ter interesse em ver muitos exemplos de pássaros, como explicações, para investigar melhor a causa raiz.
A tabela a seguir resume os parâmetros que podem ser substituídos para uma solicitação de explicação baseada em exemplo:
| Nome da propriedade | Valor da propriedade | Descrição |
|---|---|---|
| neighborCount | int32 |
O número de exemplos a serem retornados como explicação |
| crowdingCount | int32 |
Número máximo de exemplos para retornar com a mesma tag de recolhimento |
| allow | String Array |
As tags que podem conter Explicações |
| deny | String Array |
As tags que não têm permissão para que as Explicações tenham |
A Filtragem de pesquisa de vetor descreve esses parâmetros em mais detalhes.
Veja um exemplo de um corpo de solicitação JSON com substituições:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
A seguir
Veja um exemplo de resposta de uma solicitação explain baseada em exemplo:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
Preços
Consulte a seção com explicações baseadas em exemplos na página de preços.