En esta guía, se muestra cómo automatizar la implementación de SAP HANA en un clúster de alta disponibilidad (HA) de Red Hat Enterprise Linux (RHEL) o SUSE Linux Enterprise Server (SLES) que usa el balanceador de cargas de red de transferencia interno para administrar la dirección IP virtual (VIP).
En la guía, se usa Terraform para implementar dos máquinas virtuales (VMs) de Compute Engine, dos sistemas de escalamiento vertical de SAP HANA, una dirección IP virtual (VIP) con una implementación de balanceador de cargas de red de transferencia interno y un clúster de HA basado en SO, según las prácticas recomendadas de Google Cloud, SAP y el proveedor del SO.
Uno de los sistemas SAP HANA funciona como el sistema activo principal, y el otro funciona como un sistema secundario en espera. Debes implementar ambos sistemas de SAP HANA dentro de la misma región, de forma ideal en diferentes zonas.

El clúster implementado incluye las siguientes funciones y características:
- El administrador de recursos del clúster de alta disponibilidad de Pacemaker
- Un mecanismo de protección Google Cloud
- Una IP virtual (VIP) que usa una implementación de balanceador de cargas TCP de nivel 4, que incluye lo siguiente:
- Una reserva de la dirección IP que selecciones para la VIP.
- Dos grupos de instancias de Compute Engine.
- Un balanceador de cargas TCP interno.
- Una verificación de estado de Compute Engine.
- En clústeres de HA de RHEL:
- El patrón de alta disponibilidad de Red Hat.
- El agente de recursos de Red Hat y los paquetes de protección.
- En clústeres de HA de SLES:
- El patrón de alta disponibilidad de SUSE
- El paquete del agente de recursos de SUSE SAPHanaSR
- Replicación síncrona del sistema
- Carga previa de la memoria
- Reinicio automático de la instancia con errores como la instancia secundaria nueva
Si necesitas un sistema de escalamiento horizontal con hosts en espera para la conmutación por error automática de host de SAP HANA, debes consultar Terraform: guía de implementación del sistema de escalamiento horizontal de SAP HANA con conmutación por error automática de host.
Para implementar un sistema de SAP HANA sin un clúster de alta disponibilidad de Linux o hosts en espera, usa la Terraform: Guía de implementación de SAP HANA.
Esta guía está destinada a usuarios avanzados de SAP HANA que estén familiarizados con la configuración de alta disponibilidad de Linux para SAP HANA.
Requisitos previos
Antes de crear el clúster de alta disponibilidad de SAP HANA, asegúrate de que se cumplan los siguientes requisitos:
- Leíste la Guía de planificación de SAP HANA y la Guía de planificación de alta disponibilidad de SAP HANA.
- Tú o tu organización deben tener una cuenta de Google Cloud y haber creado un proyecto para la implementación de SAP HANA. Para obtener información sobre cómo crear cuentas y proyectos deGoogle Cloud , consulta Configura tu Cuenta de Google.
- Si necesitas que tu carga de trabajo de SAP se ejecute de acuerdo con los requisitos de residencia de datos, control de acceso, personal de asistencia o reglamentario, debes crear la carpeta de cargas de trabajo de Assured Workloads requerida. Para obtener más información, consulta Controles de cumplimiento y soberanía para SAP en Google Cloud.
El medio de instalación de SAP HANA se almacena en un bucket de Cloud Storage que está disponible en tu proyecto y región de implementación. Para obtener información sobre cómo subir medios de instalación de SAP HANA a un bucket de Cloud Storage, consulta Crea un bucket de Cloud Storage para los archivos de instalación de SAP HANA.
Si el Acceso al SO está habilitado en los metadatos del proyecto, debes inhabilitar el Acceso al SO de forma temporal hasta que se complete la implementación. Para fines de implementación, este procedimiento configura las claves SSH en metadatos de instancia. Cuando el acceso al SO está habilitado, la configuración de las claves SSH basada en metadatos se inhabilita y esta implementación falla. Una vez terminada la implementación, puedes volver a habilitar el acceso al SO.
Para obtener más información, consulte:
Si usas un DNS interno de VPC, el valor de la variable
vmDnsSettingen los metadatos del proyecto debe serGlobalOnlyoZonalPreferredpara habilitar la resolución de los nombres del nodo entre zonas. La configuración predeterminada devmDnsSettingesZonalOnly. Para obtener más información, consulta:
Crea una red
Por razones de seguridad, crea una red nueva. Puedes controlar quién tiene acceso con reglas de firewall o a través de otro método de control de acceso.
Si tu proyecto tiene una red de VPC predeterminada, no la uses. En su lugar, crea tu propia red de VPC para que las únicas reglas de firewall vigentes sean aquellas que crees explícitamente.
Durante la implementación, las instancias de Compute Engine suelen requerir acceso a Internet para descargar el agente de Google Cloudpara SAP. Si usas una de las imágenes de Linux certificadas por SAP que están disponibles en Google Cloud, la instancia de procesamiento también requiere acceso a Internet para registrar la licencia y acceder a los repositorios de los proveedores de SO. Una configuración con una puerta de enlace NAT y con etiquetas de red de VM admite este acceso, incluso si las instancias de procesamiento de destino no tienen IP externas.
Para crear una red de VPC para tu proyecto, completa los siguientes pasos:
-
Crea una red de modo personalizado. Para obtener más información, consulta Cómo crear una red de modo personalizado.
-
Crea una subred y especifica la región y el rango de IP a través de el siguiente comando. Para obtener más información, consulta Cómo agregar subredes.
Cómo configurar una puerta de enlace NAT
Si necesitas crear una o más VMs sin direcciones IP públicas, debes usar la traducción de direcciones de red (NAT) para permitir que las VMs accedan a Internet. Usa Cloud NAT, un servicio administrado distribuido y definido por software por Google Cloud que permite que las VMs envíen paquetes salientes a Internet y reciban cualquier paquete de respuesta entrante establecido. Como alternativa, puedes configurar una VM independiente como una puerta de enlace NAT.
Para crear una instancia de Cloud NAT para tu proyecto, consulta Usa Cloud NAT.
Después de configurar Cloud NAT para tu proyecto, tus instancias de VM pueden acceder a Internet de forma segura sin una dirección IP pública.
Cómo agregar reglas de firewall
De forma predeterminada, una regla de firewall implícita bloquea las conexiones entrantes desde fuera de tu red de nube privada virtual (VPC). Para permitir conexiones entrantes, establece una regla de firewall para la VM. Después de establecer una conexión entrante con una VM, se permite el tráfico en ambas direcciones a través de esa conexión.
Los clústeres de alta disponibilidad para SAP HANA requieren al menos dos reglas de firewall, una que permita que la verificación de estado de Compute Engine verifique el estado de los nodos del clúster y otra que permita que los nodos del clúster se comuniquen entre sí.Si no usas una red de VPC compartida, debes crear la regla de firewall para la comunicación entre los nodos, pero no para las verificaciones de estado. El archivo de configuración de Terraform crea la regla de firewall para las verificaciones de estado, que puedes modificar una vez que se completa la implementación, si es necesario.
Si usas una red de VPC compartida, un administrador de red debe crear ambas reglas de firewall en el proyecto host.
También puedes crear una regla de firewall para permitir el acceso externo a puertos especificados o restringir el acceso entre las VM en la misma red. Si se usa el tipo de red de VPC default, también se aplican algunas reglas predeterminadas adicionales, como la regla default-allow-internal, que permite la conectividad entre VM en la misma red en todos los puertos.
En función de la política de TI que se aplique a tu entorno, es posible que debas aislar o restringir la conectividad a tu host de base de datos, lo que puedes hacer a través de la creación de reglas de firewall.
Según la situación en la que te encuentres, puedes crear reglas de firewall para permitir los siguientes accesos:
- Los puertos SAP predeterminados que se enumeran en TCP/IP de todos los productos SAP.
- Conexiones desde tu computadora o tu entorno de red corporativa a tu instancia de VM de Compute Engine. Si no estás seguro de qué dirección IP usar, comunícate con el administrador de red de tu empresa.
- Conexiones SSH a tu instancia de VM, incluido SSH en el navegador.
- Conexión a tu VM a través de una herramienta de terceros en Linux. Crea una regla para permitir el acceso a la herramienta a través de tu firewall.
Para crear las reglas de firewall para tu proyecto, consulta Crea reglas de firewall.
Crea un clúster de Linux de alta disponibilidad con SAP HANA instalado
En las siguientes instrucciones, se usa el archivo de configuración de Terraform para crear un clúster de RHEL o SLES con dos sistemas de SAP HANA: un sistema SAP HANA principal de host único en una instancia de VM y un sistema SAP HANA en espera en otra instancia de VM en la misma región de Compute Engine. Los sistemas SAP HANA usan la replicación síncrona del sistema, y el sistema en espera precarga los datos replicados.
Define opciones de configuración para el clúster de alta disponibilidad de SAP HANA en un archivo de configuración de Terraform.
Confirma que las cuotas actuales de los recursos como discos persistentes y CPU sean suficientes para los sistemas SAP HANA que estás a punto de instalar. Si tus cuotas son insuficientes, entonces tu implementación falla.
Si quieres ver los requisitos de cuota de SAP HANA, consulta las consideraciones de precios y cuotas para SAP HANA.
Abre Cloud Shell.
Descarga el archivo de configuración
sap_hana_ha.tfpara el clúster de alta disponibilidad de SAP HANA en tu directorio de trabajo:$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tfAbre el archivo
sap_hana_ha.tfen el editor de código de Cloud Shell.Para abrir el editor de código de Cloud Shell, haz clic en el ícono de lápiz en la esquina superior derecha de la ventana de la terminal de Cloud Shell.
En el archivo
sap_hana_ha.tf, reemplaza los contenidos dentro de las comillas dobles por los valores de la instalación para actualizar los siguientes valores de argumento. Los argumentos se describen en la siguiente tabla.Argumento Tipo de datos Descripción sourceString Especifica la ubicación y la versión del módulo de Terraform que se usará durante la implementación.
El archivo de configuración
sap_hana_ha.tfincluye dos instancias del argumentosource: una que está activa y otra que se incluye como un comentario. El argumentosourceque está activo de forma predeterminada especificalatestcomo la versión del módulo. La segunda instancia del argumentosource, que de forma predeterminada se desactiva a través de un carácter#inicial, especifica una marca de tiempo que identifica una versión del módulo.Si necesitas que todas tus implementaciones usen la misma versión del módulo, quita el carácter
#inicial del argumentosourceque especifica la marca de tiempo de la versión y agrégala al argumentosourceque especificalatest.project_idString Especifica el ID del proyecto de Google Cloud en el que implementarás este sistema. Por ejemplo, my-project-x.machine_typeString Especifica el tipo de máquina virtual (VM) de Compute Engine en el que quieres ejecutar el sistema SAP. Si necesitas un tipo de VM personalizada, especifica un tipo de VM predefinido con una cantidad de CPU virtuales más cercana al número que necesitas sin dejar de ser más grande. Una vez completada la implementación, modifica la cantidad de CPU virtuales y la cantidad de memoria. Por ejemplo,
n1-highmem-32.sole_tenant_deploymentBooleano Opcional. Si deseas aprovisionar un nodo de solo usuario para tu implementación de SAP HANA, especifica el valor
true.El valor predeterminado es
false.Este argumento está disponible en
sap_hana_haversión1.3.704310921o posterior.sole_tenant_name_prefixString Opcional. Si aprovisionas un nodo de usuario único para tu implementación de SAP HANA, puedes usar este argumento para especificar un prefijo que Terraform establece para los nombres de la plantilla y el grupo de usuario único correspondientes.
El valor predeterminado es
st-SID_LC.Para obtener información sobre la plantilla y el grupo de usuario único, consulta Descripción general del usuario único.
Este argumento está disponible en
sap_hana_haversión1.3.704310921o posterior.sole_tenant_node_typeString Opcional.Si deseas aprovisionar un nodo de solo usuario para tu implementación de SAP HANA, especifica el tipo de nodo que deseas establecer para la plantilla de nodo correspondiente.
Este argumento está disponible en
sap_hana_haversión1.3.704310921o posterior.networkString Especifica el nombre de la red en la que necesitas crear el balanceador de cargas que administra la VIP. Si usas una red de VPC compartida, debes agregar el ID del proyecto host como directorio superior del nombre de la red. Por ejemplo,
HOST_PROJECT_ID/NETWORK_NAME.subnetworkString Especifica el nombre de la subred que creaste en un paso anterior. Si realizas la implementación en una VPC compartida, especifica este valor como SHARED_VPC_PROJECT_ID/SUBNETWORK. Por ejemplo:myproject/network1linux_imageString Especifica el nombre de la imagen del sistema operativo Linux en la que deseas implementar tu sistema SAP. Por ejemplo: rhel-9-2-sap-haosles-15-sp5-sap. Para obtener la lista de imágenes de sistema operativo disponibles, consulta la página Imágenes en la consola de Google Cloud.linux_image_projectString Especifica el proyecto de Google Cloud que contiene la imagen que especificaste para el argumento linux_image. Este proyecto puede ser uno propio o un proyecto de imagen de Google Cloud . En el caso de una imagen de Compute Engine, especificarhel-sap-cloudosuse-sap-cloud. Para encontrar el proyecto de imagen de tu sistema operativo, consulta Detalles de los sistemas operativos.primary_instance_nameString Especifica un nombre de la instancia de VM para el sistema SAP HANA principal. El nombre puede contener letras minúsculas, números o guiones. primary_zoneString Especifica una zona en la que se implemente el sistema SAP HANA principal. Las zonas principal y secundaria deben estar en la misma región. Por ejemplo, us-east1-c.secondary_instance_nameString Especifica un nombre de la instancia de VM para el sistema de SAP HANA secundario. El nombre puede contener letras minúsculas, números o guiones. secondary_zoneString Especifica una zona en la que se implemente el sistema SAP HANA secundario. Las zonas principal y secundaria deben estar en la misma región. Por ejemplo, us-east1-b.sap_hana_deployment_bucketString Para instalar SAP HANA automáticamente en las VMs implementadas, especifica la ruta de acceso del bucket de Cloud Storage que contiene los archivos de instalación de SAP HANA. No incluyas gs://en la ruta de acceso; solo incluye el nombre del bucket y los nombres de las carpetas. Por ejemplo,my-bucket-name/my-folder.El bucket de Cloud Storage debe existir en el proyecto de Google Cloud que especificas para el argumento
project_id.sap_hana_sidString Para instalar SAP HANA automáticamente en las VMs implementadas, especifica el ID del sistema SAP HANA. Debe constar de tres caracteres alfanuméricos y comenzar con una letra. Todas las letras deben estar en mayúsculas. Por ejemplo, ED1.sap_hana_instance_numberEntero Opcional. Especifica el número de instancia, de 0 a 99, del sistema SAP HANA. El valor predeterminado es 0.sap_hana_sidadm_passwordString Para instalar SAP HANA automáticamente en las VMs implementadas, especifica una contraseña temporal SIDadmpara que las secuencias de comandos de instalación se usen durante la implementación. La contraseña debe tener al menos 8 caracteres y debe incluir al menos una letra mayúscula, una letra minúscula y un número.En lugar de especificar la contraseña como texto sin formato, te recomendamos que utilices un Secret. Si deseas obtener más información, consulta Administración de contraseñas.
sap_hana_sidadm_password_secretString Opcional. Si usas Secret Manager para almacenar la contraseña SIDadm, especifica el Nombre del secreto que corresponde a esta contraseña.En Secret Manager, asegúrate de que el valor Secret, que es la contraseña, contenga al menos 8 caracteres e incluya al menos una letra mayúscula, una letra minúscula y un número.
Si deseas obtener más información, consulta Administración de contraseñas.
sap_hana_system_passwordString Para instalar SAP HANA automáticamente en las VMs implementadas, especifica una contraseña de superusuario temporal para la secuencia de comandos de instalación que se usará durante la implementación. La contraseña debe tener al menos 8 caracteres y también incluir al menos una letra mayúscula, una letra minúscula y un número. En lugar de especificar la contraseña como texto sin formato, te recomendamos que utilices un Secret. Si deseas obtener más información, consulta Administración de contraseñas.
sap_hana_system_password_secretString Opcional. Si usas Secret Manager para almacenar la contraseña del superusuario de la base de datos, especifica el Nombre del secreto que corresponde a esta contraseña. En Secret Manager, asegúrate de que el valor Secret, que es la contraseña, contenga al menos 8 caracteres e incluya al menos una letra mayúscula, una letra minúscula y un número.
Si deseas obtener más información, consulta Administración de contraseñas.
sap_hana_double_volume_sizeBooleano Opcional. Para duplicar el tamaño del volumen de HANA, especifica true. Este argumento es útil cuando deseas implementar varias instancias de SAP HANA o una instancia de SAP HANA de recuperación ante desastres en la misma VM. De forma predeterminada, el tamaño del volumen se calcula automáticamente para que sea el tamaño mínimo requerido por la VM, sin dejar de cumplir con los requisitos de certificación y asistencia de SAP. El valor predeterminado esfalse.sap_hana_backup_sizeEntero Opcional. Especifica el tamaño del volumen /hanabackupen GB. Si no especificas este argumento ni lo estableces en0, la secuencia de comandos de instalación aprovisiona la instancia de Compute Engine con un volumen de copia de seguridad de HANA de dos veces la memoria total.sap_hana_sidadm_uidEntero Opcional. Especifica un valor para anular el valor predeterminado del ID de usuario SID_LCadm. El valor predeterminado es 900. Puedes cambiar esto a un valor diferente para mantener la coherencia dentro de tu entorno de SAP.sap_hana_sapsys_gidEntero Opcional. Anula el ID de grupo predeterminado para sapsys. El valor predeterminado es79.sap_vipString Especifica la dirección IP que usarás para tu VIP. La dirección IP debe estar dentro del rango de direcciones IP asignadas a la subred. El archivo de configuración de Terraform reserva esta dirección IP para ti. primary_instance_group_nameString Opcional. Especifica el nombre del grupo de instancias no administrado para el nodo principal. El nombre predeterminado es ig-PRIMARY_INSTANCE_NAME.secondary_instance_group_nameString Opcional. Especifica el nombre del grupo de instancias no administrado para el nodo secundario. El nombre predeterminado es ig-SECONDARY_INSTANCE_NAME.loadbalancer_nameString Opcional. Especifica el nombre del balanceador de cargas de red de transferencia interno. El nombre predeterminado es lb-SAP_HANA_SID-ilb.network_tagsString Opcional. Especifica una o más etiquetas de red separadas por comas que desees asociar con tus instancias de VM para un firewall o enrutamiento. Una etiqueta de red para los componentes del ILB se agrega automáticamente a las etiquetas de red de la VM.
nic_typeString Opcional. Especifica la interfaz de red que se usará con la instancia de VM. Puedes especificar el valor GVNICoVIRTIO_NET. Para usar una NIC virtual de Google (gVNIC), debes especificar una imagen de SO que admita gVNIC como valor del argumentolinux_image. Para obtener la lista de imágenes del SO, consulta Detalles de los sistemas operativos.Si no especificas un valor para este argumento, la interfaz de red se selecciona automáticamente según el tipo de máquina que especifiques para el argumento
Este argumento está disponible en el módulomachine_type.sap_hanaversión202302060649o posterior.disk_typeString Opcional. Especifica el tipo predeterminado de volumen de Persistent Disk o Hyperdisk que deseas implementar para los datos de SAP y los volúmenes de registros en tu implementación. Para obtener información sobre la implementación de disco predeterminada que realiza la configuración de Terraform que proporciona Google Cloud, consulta Implementación de discos mediante Terraform. Los siguientes valores son válidos para este argumento:
pd-ssd,pd-balanced,hyperdisk-extreme,hyperdisk-balancedypd-extreme. En las implementaciones de escalamiento vertical de SAP HANA, también se implementa un disco persistente balanceado independiente para el directorio/hana/shared.Puedes anular este tipo de disco predeterminado y los tamaños predeterminados del disco y las IOPS predeterminadas a través de algunos argumentos avanzados. Para obtener más información, navega al directorio de trabajo, ejecuta el comando
terraform inity, luego, consulta el archivo/.terraform/modules/sap_hana_ha/variables.tf. Antes de usar estos argumentos en producción, asegúrate de probarlos en un entorno de no producción.use_single_shared_data_log_diskBooleano Opcional. El valor predeterminado es false, que le indica a Terraform que implemente un disco persistente o Hyperdisk independiente para cada uno de los siguientes volúmenes de SAP:/hana/data,/hana/log,/hana/sharedy/usr/sap. Para activar estos volúmenes de SAP en el mismo disco persistente o Hyperdisk, especificatrue.enable_data_stripingBooleano Opcional. Este argumento te permite implementar el volumen /hana/dataen dos discos. El valor predeterminado esfalse, que le indica a Terraform que implemente un solo disco para alojar tu volumen/hana/data.Este argumento está disponible en el módulo
sap_hana_haversión1.3.674800406o posterior.include_backup_diskBooleano Opcional. Este argumento se aplica a las implementaciones de escalamiento vertical de SAP HANA. El valor predeterminado es true, que le indica a Terraform implementar un disco separado para alojar el directorio/hanabackup.El tipo de disco se determina mediante el argumento
backup_disk_type. El tamaño de este disco se determina a través del argumentosap_hana_backup_size.Si configuras el valor de
include_backup_diskcomofalse, no se implementa ningún disco para el directorio/hanabackup.backup_disk_typeString Opcional. Para implementaciones de escalamiento vertical, especifica el tipo de Persistent Disk o Hyperdisk que deseas implementar para el volumen /hanabackup. Para obtener información sobre la implementación de disco predeterminada que realiza la configuración de Terraform que proporciona Google Cloud, consulta Implementación de discos mediante Terraform.Los siguientes valores son válidos para este argumento:
pd-ssd,pd-balanced,pd-standard,hyperdisk-extreme,hyperdisk-balancedypd-extreme.Este argumento está disponible en el módulo
sap_hana_haversión202307061058o posterior.enable_fast_restartBooleano Opcional. Este argumento determina si la opción de reinicio rápido de SAP HANA está habilitada para tu implementación. El valor predeterminado es true. Google Cloud recomienda habilitar la opción de reinicio rápido de SAP HANA.Este argumento está disponible en el módulo
sap_hana_haversión202309280828o posterior.public_ipBooleano Opcional. Determina si se agrega o no una dirección IP pública a la instancia de VM. El valor predeterminado es true.service_accountString Opcional. Especifica la dirección de correo electrónico de una cuenta de servicio administrada por el usuario que usarán las VM del host y los programas que se ejecutan en las VM del host. Por ejemplo: svc-acct-name@project-id.iam.gserviceaccount.com.Si especificas este argumento sin un valor o lo omites, la secuencia de comandos de instalación usará la cuenta de servicio predeterminada de Compute Engine. Para obtener más información, consulta la sección sobre administración de identidades y accesos para programas SAP en Google Cloud.
sap_deployment_debugBooleano Opcional. Solo cuando Atención al cliente de Cloud te solicite habilitar la depuración para tu implementación, especifica true, lo que hace que la implementación genere registros de implementación con verbosidad. El valor predeterminado esfalse.primary_reservation_nameString Opcional. Especifica el nombre de la reserva para usar una reserva de VM de Compute Engine específica para aprovisionar la instancia de VM que aloja la instancia principal de SAP HANA de tu clúster de alta disponibilidad. De forma predeterminada, la secuencia de comandos de instalación selecciona cualquier reserva de Compute Engine disponible según las siguientes condiciones. Para que una reserva se pueda usar, sin importar si especificas un nombre o si la secuencia de comandos de instalación lo selecciona automáticamente, la reserva debe configurarse con lo siguiente:
-
La opción
specificReservationRequiredse configura comotrueo, en la consola de Google Cloud, se selecciona la opción Seleccionar reserva específica. -
Algunos tipos de máquinas de Compute Engine son compatibles con las plataformas de CPU que no están cubiertas por la certificación de SAP del tipo de máquina. Si la reserva de destino es para cualquiera de los siguientes tipos de máquina, la reserva debe especificar las plataformas de CPU mínimas como se indica:
n1-highmem-32: Broadwell de Inteln1-highmem-64: Broadwell de Inteln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Las plataformas de CPU mínimas para todos los demás tipos de máquinas certificados por SAP para su uso en Google Cloud cumplen con el requisito mínimo de CPU de SAP.
secondary_reservation_nameString Opcional. Especifica el nombre de la reserva para usar una reserva de VM de Compute Engine específica para aprovisionar la instancia de VM que aloja la instancia secundaria de SAP HANA de tu clúster de alta disponibilidad. De forma predeterminada, la secuencia de comandos de instalación selecciona cualquier reserva de Compute Engine disponible según las siguientes condiciones. Para que una reserva se pueda usar, sin importar si especificas un nombre o si la secuencia de comandos de instalación lo selecciona automáticamente, la reserva debe configurarse con lo siguiente:
-
La opción
specificReservationRequiredse configura comotrueo, en la consola de Google Cloud, se selecciona la opción Seleccionar reserva específica. -
Algunos tipos de máquinas de Compute Engine son compatibles con las plataformas de CPU que no están cubiertas por la certificación de SAP del tipo de máquina. Si la reserva de destino es para cualquiera de los siguientes tipos de máquina, la reserva debe especificar las plataformas de CPU mínimas como se indica:
n1-highmem-32: Broadwell de Inteln1-highmem-64: Broadwell de Inteln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Las plataformas de CPU mínimas para todos los demás tipos de máquinas certificados por SAP para su uso en Google Cloud cumplen con el requisito mínimo de CPU de SAP.
primary_static_ipString Opcional. Especifica una dirección IP estática válida para la instancia de VM principal en tu clúster de alta disponibilidad. Si no especificas una, se generará una dirección IP automáticamente para tu instancia de VM. Por ejemplo, 128.10.10.10.Este argumento está disponible en el módulo
sap_hana_haversión202306120959o posterior.secondary_static_ipString Opcional. Especifica una dirección IP estática válida para la instancia de VM secundaria en tu clúster de alta disponibilidad. Si no especificas una, se generará una dirección IP automáticamente para tu instancia de VM. Por ejemplo, 128.11.11.11.Este argumento está disponible en el módulo
sap_hana_haversión202306120959o posterior.can_ip_forwardBooleano Especifica si se permite el envío y la recepción de paquetes con IP de origen o destino que no coincidan, lo que permite que una VM actúe como un router. El valor predeterminado es
true.Si solo deseas usar los balanceadores de cargas internos de Google para administrar las IP virtuales de las VMs implementadas, establece el valor en
false. Un balanceador de cargas interno se implementa automáticamente como parte de las plantillas de alta disponibilidad.En los siguientes ejemplos, se muestra el archivo de configuración completo que define un clúster de alta disponibilidad para SAP HANA. El clúster usa un balanceador de cargas de red de transferencia interno para administrar la VIP.
Terraform implementa los recursos de Google Cloudque se definen en el archivo de configuración y, luego, las secuencias de comandos toman el control del sistema operativo, instalan SAP HANA, configuran la replicación y configuran el clúster de alta disponibilidad de Linux.
Haz clic en
RHELoSLESpara ver el ejemplo específico de tu sistema operativo. Para mayor claridad, los comentarios en el archivo de configuración se omiten en los ejemplos.RHEL
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "rhel-8-4-sap-ha" linux_image_project = "rhel-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456.iam.gserviceaccount.com" primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }SLES
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp3-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456.iam.gserviceaccount.com" primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }-
La opción
Inicializa tu directorio de trabajo actual y descarga los archivos del módulo y el complemento del proveedor de Terraform para Google Cloud:
terraform init
El comando
terraform initprepara tu directorio de trabajo para otros comandos de Terraform.Para forzar una actualización del complemento de proveedor y los archivos de configuración en tu directorio de trabajo, especifica la marca
--upgrade. Si se omite la marca--upgradey no realizas ningún cambio en tu directorio de trabajo, Terraform usa las copias almacenadas en caché de forma local, incluso silatestse especifica en la URLsource.terraform init --upgrade
De manera opcional, crea el plan de ejecución de Terraform:
terraform plan
El comando
terraform planmuestra los cambios que requiere tu configuración actual. Si omites este paso, el comandoterraform applycrea automáticamente un plan nuevo y te solicita que lo apruebes.Aplica el plan de ejecución:
terraform apply
Cuando se te solicite aprobar las acciones, ingresa
yes.El comando
terraform applyconfigura la infraestructura de Google Cloud y, luego, entrega el control a una secuencia de comandos que configura el clúster de HA y, luego, instala SAP HANA según los argumentos definidos en el archivo de configuración de Terraform.Mientras Terraform tiene control, los mensajes de estado se escriben en Cloud Shell. Una vez que se invocan las secuencias de comandos, los mensajes de estado se escriben en Logging y se pueden ver en la consola de Google Cloud, como se describe en Verifica los registros.
Verifica la implementación de tu sistema HANA de alta disponibilidad
La verificación de un clúster de alta disponibilidad de SAP HANA implica varios procedimientos diferentes:
- Verificar los registros
- Verifica la configuración de la VM y la instalación de SAP HANA
- Verificar la configuración del clúster
- Verificar el balanceador de cargas y el estado de los grupos de instancias
- Comprueba el sistema SAP HANA con SAP HANA Studio
- Realiza una prueba de conmutación por error
Verifica los registros
En la consola de Google Cloud, abre Cloud Logging para supervisar el progreso de la instalación y verificar si hay errores.
Filtra los registros:
Explorador de registros
En la página Explorador de registros, ve al panel Consulta.
En el menú desplegable Recurso, selecciona Global y, luego, haz clic en Agregar.
Si no ves la opción Global, ingresa la siguiente consulta en el editor de consultas:
resource.type="global" "Deployment"Haz clic en Ejecutar consulta.
Visor de registros heredado
- En la página Visor de registros heredado, en el menú del selector básico, selecciona Global como tu recurso de registro.
Analiza los registros filtrados:
- Si se muestra
"--- Finished", el proceso de implementación está completo y puedes continuar con el siguiente paso. Si ves un error de cuota, sigue estos pasos:
En la página Cuotas de IAM y administración, aumenta cualquiera de las cuotas que no cumplan con los requisitos de SAP HANA que se enumeran en la Guía de planificación de SAP HANA.
Abra Cloud Shell.
Ve al directorio de trabajo y borra la implementación para limpiar las VM y los discos persistentes de la instalación fallida:
terraform destroy
Cuando se te solicite aprobar la acción, ingresa
yes.Vuelve a ejecutar tu implementación.
- Si se muestra
Verifica la configuración de la VM y la instalación de SAP HANA
Después de que el sistema SAP HANA se implemente sin errores, conéctate a cada VM a través de una conexión SSH. En la página Instancias de VM de Compute Engine, puedes hacer clic en el botón SSH para cada instancia de VM o usar tu método SSH preferido.

Cambia al usuario raíz.
sudo su -
En el símbolo del sistema, ingresa
df -h. Asegúrate de ver un resultado que incluya los directorios/hana, como/hana/data.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
Verifica el estado del clúster nuevo. Para ello, ingresa el comando de estado específico de tu sistema operativo:
RHEL
pcs statusSLES
crm statusEl resultado es similar al siguiente ejemplo, en el que se inician ambas instancias de VM y
example-ha-vm1es la instancia principal activa:RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES para SAP 15 SP5 o versiones anteriores
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]SLES para SAP 15 SP6 o posterior
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Mon Oct 7 22:57:59 2024 * Last change: Mon Oct 7 22:57:03 2024 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]En el siguiente comando, reemplaza SID_LC por el valor
sap_hana_sidque especificaste en el archivosap_hana_ha.tfpara cambiar al usuario administrador de SAP. El valor SID_LC debe estar en minúsculas.su - SID_LCadmEjecuta el siguiente comando para asegurarte de que los servicios de SAP HANA, como
hdbnameserver,hdbindexservery otros, se ejecuten en la instancia:HDB infoSi usas RHEL para SAP 9.0 o una versión posterior, asegúrate de que los paquetes
chkconfigycompat-openssl11estén instalados en la instancia de VM.Para obtener más información de SAP, consulta la Nota 3108316 de SAP: Red Hat Enterprise Linux 9.x: Instalación y configuración.
Verifica la configuración de tu clúster
Verifica la configuración de parámetros del clúster. Verifica la configuración que muestra el software de tu clúster y la configuración de los parámetros en el archivo de configuración del clúster. Compara tu configuración con la de los ejemplos a continuación, que se crearon a partir de las secuencias de comandos de automatización que se usan en esta guía.
Haz clic en la pestaña de tu sistema operativo.
RHEL
Muestra las opciones de configuración de los recursos de tu clúster:
pcs config show
En el siguiente ejemplo, se muestran las opciones de configuración de recursos que crean las secuencias de comandos de automatización en RHEL 8.1 y versiones posteriores.
Si ejecutas RHEL 7.7 o versiones anteriores, la definición de recurso
Clone: SAPHana_HA1_00-cloneno incluyeMeta Attrs: promotable=true.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=example-project-123456 zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=example-project-123456 zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:Muestra el archivo de configuración del clúster,
corosync.conf:cat /etc/corosync/corosync.conf
En el siguiente ejemplo, se muestran los parámetros que configuran las secuencias de comandos de automatización para RHEL 8.1 y versiones posteriores.
Si usas RHEL 7.7 o una versión anterior, el valor de
transport:esudpuen lugar deknet:totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES para SAP 15 SP5 o versiones anteriores
Muestra las opciones de configuración de los recursos de tu clúster:
crm config show
Las secuencias de comandos de automatización que se usan en esta guía crean las opciones de configuración de los recursos que se muestran en el siguiente ejemplo:
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Muestra el archivo de configuración del clúster,
corosync.conf:cat /etc/corosync/corosync.conf
Las secuencias de comandos de automatización que se usan en esta guía especifican la configuración de los parámetros en el archivo
corosync.conf, como se muestra en el siguiente ejemplo:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
SLES para SAP 15 SP6 o posterior
Muestra las opciones de configuración de los recursos de tu clúster:
crm config show
Las secuencias de comandos de automatización que se usan en esta guía crean las opciones de configuración de los recursos que se muestran en el siguiente ejemplo:
node 1: example-ha-vm1 \ attributes hana_ha1_vhost=example-ha-vm1 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHanaFileSystem_HA1_HDB00 ocf:suse:SAPHanaFilesystem \ operations $id=rsc_sap3_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Promoted timeout=700 \ op monitor interval=61 role=Unpromoted timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 clone mst_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 promotable=true interleave=true clone cln_SAPHanaFileSystem_HA1_HDB00 rsc_SAPHanaFileSystem_HA1_HDB00 \ meta clone-node-max=1 interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started mst_SAPHana_HA1_HDB00:Promoted order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 mst_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Muestra el archivo de configuración del clúster,
corosync.conf:cat /etc/corosync/corosync.conf
Las secuencias de comandos de automatización que se usan en esta guía especifican la configuración de los parámetros en el archivo
corosync.conf, como se muestra en el siguiente ejemplo:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
Verifica el balanceador de cargas y el estado de los grupos de instancias
Para confirmar que el balanceador de cargas y la verificación de estado se configuraron de forma correcta, verifica el balanceador de cargas y los grupos de instancias en la consola de Google Cloud.
Abra la página Balanceo de cargas en la consola de Google Cloud:
En la lista de balanceadores de cargas, confirma que se creó un balanceador de cargas para tu clúster de alta disponibilidad.
En la página Detalles del balanceador de cargas en la columna En buen estado en Grupo de instancias en la sección Backend, confirma que uno de los grupos de instancias muestra “1/1” y el otro muestra “0/1”. Después de una conmutación por error, el indicador en buen estado, “1/1”, cambia al nuevo grupo de instancias activo.
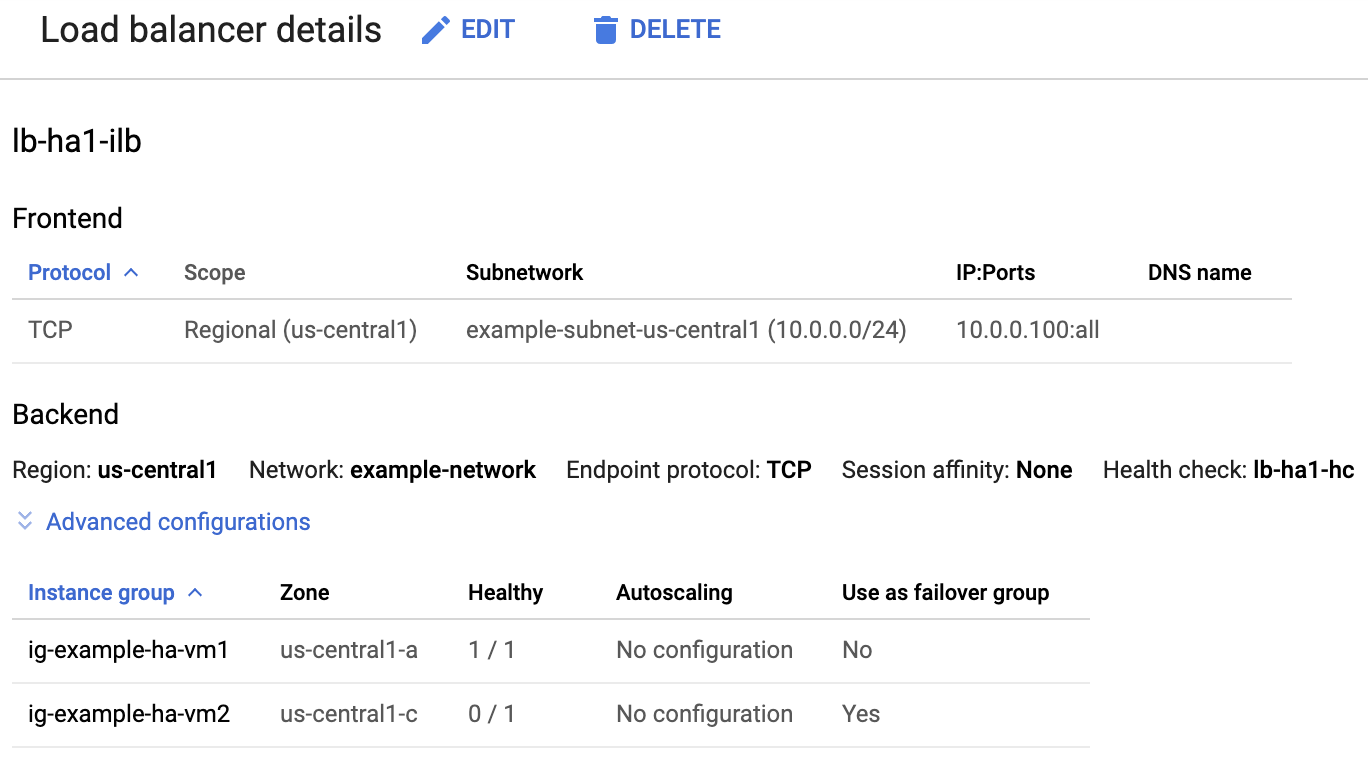
Comprueba el sistema SAP HANA con SAP HANA Studio
Puedes usar SAP HANA Cockpit o SAP HANA Studio para supervisar y administrar tus sistemas SAP HANA en un clúster de alta disponibilidad.
Conéctate al sistema HANA con SAP HANA Studio. Cuando definas la conexión, especifica los siguientes valores:
- En el panel Specify System, proporciona la dirección IP flotante como el nombre de host.
- En el panel Propiedades de conexión, para realizar la autenticación de usuario de la base de datos, especifica el nombre del superusuario de la base de datos y la contraseña que especificaste para el argumento
sap_hana_system_passworden el archivosap_hana_ha.tf.
Para obtener información de SAP sobre la instalación de SAP HANA Studio, consulta SAP HANA Studio Installation and Update Guide (Guía de instalación y actualización de SAP HANA Studio).
Después de que SAP HANA Studio se conecte al sistema de alta disponibilidad de HANA, haz doble clic en el nombre del sistema, en el panel de navegación al lado izquierdo de la ventana, para ver la descripción general del sistema.
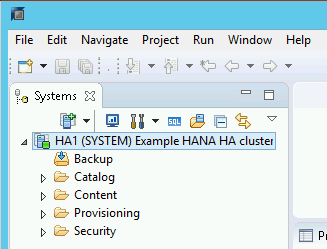
En General Information (Información general), en la pestaña Overview (Descripción general), confirma que suceda lo siguiente:
- Operational Status (Estado operativo) muestre “All services started” (“Todos los servicios iniciados”)
- System Replication Status (Estado de replicación del sistema) muestre “All services are active and in sync” (“Todos los servicios están activos y sincronizados”)
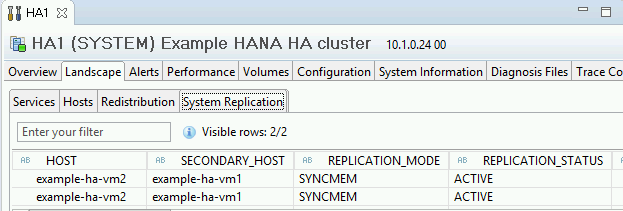
Para confirmar el modo de replicación, haz clic en el vínculo Estado de replicación del sistema (System Replication Status) en Información general (General Information). La replicación síncrona se indica a través de
SYNCMEMen la columna REPLICATION_MODE de la pestaña Replicación del sistema (System Replication).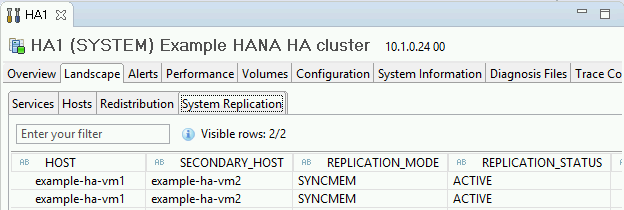
Limpia y vuelve a intentar la implementación
Si alguno de los pasos de verificación de implementación en las secciones anteriores muestra que la instalación no se realizó de forma correcta, debes deshacer la implementación y volver a intentarlo a través de los siguientes pasos:
Resuelve cualquier error para asegurarte de que tu implementación no vuelva a fallar por el mismo motivo. Si deseas obtener más información para verificar los registros o resolver errores relacionados con la cuota, consulta Verifica los registros.
Abre Cloud Shell o, si instalaste Google Cloud CLI en la estación de trabajo local, abre una terminal.
Ve al directorio que contiene el archivo de configuración de Terraform que usaste para esta implementación.
Borra todos los recursos que forman parte de la implementación a través de la ejecución del siguiente comando:
terraform destroy
Cuando se te solicite aprobar la acción, ingresa
yes.Vuelve a intentar la implementación como se indicó antes en esta guía.
Realiza una prueba de conmutación por error
Para realizar una prueba de conmutación por error, sigue estos pasos:
Conéctate a la VM principal mediante SSH. Puedes conectarte desde la página Instancias de VM de Compute Engine si haces clic en el botón SSH para cada instancia de VM o si usas tu método SSH preferido.
En el símbolo del sistema, ingresa el siguiente comando:
sudo ip link set eth0 down
El comando
ip link set eth0 downactiva una conmutación por error dado que divide las comunicaciones con el host principal.Vuelve a conectarte a cualquier host a través de SSH y cambia al usuario raíz.
Confirma que el host principal ahora está activo en la VM que contenía el host secundario. El reinicio automático está habilitado en el clúster, por lo que el host detenido se reiniciará y asumirá la función de host secundario.
RHEL
pcs statusSLES
crm statusEn los siguientes ejemplos, se muestra que cambiaron las funciones de cada host.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES para SAP 15 SP5 o versiones anteriores
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES para SAP 15 SP6 o posterior
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Tue Oct 8 21:47:19 2024 * Last change: Tue Oct 8 21:47:13 2024 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]En la página Detalles del balanceador de cargas, en la consola, confirma que la instancia principal activa nueva muestre “1/1” en la columna En buen estado. Si es necesario, actualiza la página.
Por ejemplo:

En SAP HANA Studio, confirma que aún tienes conexión al sistema; para ello, haz doble clic en la entrada del sistema en el panel de navegación para actualizar la información del sistema.
Haz clic en el vínculo Estado de replicación del sistema (System Replication Status) para confirmar que los hosts principales y secundarios cambiaron de host y están activos.
Valida la instalación del agente de Google Cloudpara SAP
Después de que hayas implementado una VM y le hayas instalado SAP NetWeaver, valida que el agente deGoogle Cloudpara SAP funcione de forma correcta.
Verifica que el agente de Google Cloudpara SAP esté en ejecución
Para verificar que el agente esté en ejecución, sigue estos pasos:
Establece una conexión SSH con tu instancia de Compute Engine.
Ejecuta el siguiente comando:
systemctl status google-cloud-sap-agent
Si el agente funciona de forma correcta, el resultado contendrá
active (running). Por ejemplo:google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Si el agente no está en ejecución, reinicia el agente.
Verifica que SAP Host Agent reciba métricas
Para verificar que el agente deGoogle Cloudpara SAP recopile las métricas de infraestructura y que se envíen de forma correcta al agente de host SAP, sigue estos pasos:
- En el sistema SAP, ingresa la transacción
ST06. En el panel de descripción general, revisa la disponibilidad y el contenido de los siguientes campos para verificar la configuración completa y correcta de la infraestructura de supervisión de SAP y Google:
- Proveedor de servicios en la nube:
Google Cloud Platform - Acceso de supervisión mejorada:
TRUE - Detalles de supervisión mejorada:
ACTIVE
- Proveedor de servicios en la nube:
Configura la supervisión para SAP HANA
De manera opcional, puedes supervisar tus instancias de SAP HANA con el agente para SAP deGoogle Cloud. Desde la versión 2.0, puedes configurar el agente para recopilar las métricas de supervisión de SAP HANA y enviarlas a Cloud Monitoring. Cloud Monitoring te permite crear paneles para visualizar estas métricas, configurar alertas basadas en límites de métricas y mucho más.
Para supervisar un clúster de alta disponibilidad con el agente de Google Cloudpara SAP, asegúrate de seguir las instrucciones que se proporcionan en Configuración de alta disponibilidad para el agente.Si deseas obtener más información sobre la recopilación de métricas de supervisión de SAP HANA a través del agente deGoogle Cloudpara SAP, consulta Recopilación de métricas de supervisión de SAP HANA.
Conéctate a SAP HANA
Ten en cuenta que, como en estas instrucciones no se usa una dirección IP externa para SAP HANA, solo puedes conectarte a las instancias de SAP HANA a través de la instancia de bastión a través de conexiones SSH o a través de Windows Server a través de SAP HANA Studio.
Para conectarte a SAP HANA a través de la instancia de bastión, conéctate al host de bastión y, luego, a las instancias de SAP HANA a través de el cliente SSH que prefieras.
Para conectarte a la base de datos de SAP HANA a través de SAP HANA Studio, usa un cliente de escritorio remoto para conectarte a la instancia de Windows Server. Después de la conexión, instala SAP HANA Studio de forma manual y accede a la base de datos de SAP HANA.
Configurar HANA activo/activo (lectura habilitada)
A partir de SAP HANA 2.0 SPS1, puedes configurar HANA Active/Active (Read Enabled) en un clúster de Pacemaker. Para obtener instrucciones, consulta los siguientes vínculos:
- Configura HANA activo/activo (lectura habilitada) en un clúster de SUSE Pamaker
- Configura HANA activo/activo (lectura habilitada) en un clúster de Red Hat Pamaker
Realiza tareas posteriores a la implementación
Antes de usar la instancia de SAP HANA, te recomendamos que realices los siguientes pasos posteriores a la implementación: Para obtener más información, consulta SAP HANA Installation and Update Guide (Guía de instalación y actualización de SAP HANA).
Cambia las contraseñas temporales para el administrador del sistema de SAP HANA y el superusuario de la base de datos.
Actualiza el software SAP HANA con los últimos parches.
Si tu sistema SAP HANA se implementa en una interfaz de red de VirtIO, te recomendamos que te asegures de que el valor del parámetro de TCP
/proc/sys/net/ipv4/tcp_limit_output_bytesesté configurado como1048576. Esta modificación ayuda a mejorar la capacidad de procesamiento general de la red en la interfaz de red de VirtIO sin afectar la latencia de la red.Instala cualquier componente adicional, como las bibliotecas de funciones de aplicaciones (AFL) o el acceso a datos inteligentes (SDA).
Configura y haz una copia de seguridad de tu base de datos de SAP HANA nueva. Para obtener más información, consulta la Guía de operaciones de SAP HANA.
Evalúa la carga de trabajo de SAP HANA
Para automatizar las verificaciones de validación continua de las cargas de trabajo de alta disponibilidad de SAP HANA que se ejecutan en Google Cloud, puedes usar Workload Manager.
Workload Manager te permite analizar y evaluar automáticamente las cargas de trabajo de alta disponibilidad de SAP HANA con las prácticas recomendadas de SAP, Google Cloudy los proveedores del SO. Esto ayuda a mejorar la calidad, el rendimiento y la confiabilidad de tus cargas de trabajo.
Si deseas obtener información sobre las prácticas recomendadas que admite el administrador de cargas de trabajo para evaluar las cargas de trabajo de alta disponibilidad de SAP HANA que se ejecutan en Google Cloud, consulta Prácticas recomendadas de administrador de cargas de trabajo para SAP. Para obtener información sobre cómo crear y ejecutar una evaluación mediante Workload Manager, consulta Crea y ejecuta una evaluación.
¿Qué sigue?
- Si necesitas usar volúmenes de NetApp de Google Cloud en lugar de discos persistentes o Hyperdisk para alojar directorios de SAP HANA, como
/hana/sharedo/hanabackup, consulta la información de implementación de los volúmenes de NetApp en la guía de planificación de SAP HANA. - Para obtener más información sobre la administración y supervisión de VM, consulta la guía de operaciones de SAP HANA.