In dieser Anleitung wird beschrieben, wie Sie von Amazon DynamoDB zu Spanner migrieren. Das Dokument richtet sich in erster Linie an Inhaber von Anwendungen, die von einem NoSQL-System zu Spanner wechseln möchten. Spanner ist ein vollständig relationales, fehlertolerantes, hoch skalierbares SQL-Datenbanksystem, das Unterstützung für Transaktionen bietet. Wenn Ihre Amazon DynamoDB-Tabellen in Bezug auf Typen und Layout einheitlich sind, ist die Zuordnung zu Spanner unkompliziert. Enthalten Ihre Amazon DynamoDB-Tabellen jedoch beliebige Datentypen und Werte, ist es möglicherweise einfacher, auf andere NoSQL-Dienste wie Datastore oder Firestore umzusteigen.
In dieser Anleitung wird davon ausgegangen, dass Sie mit Datenbankschemas, Datentypen, den Grundlagen von NoSQL und mit relationalen Datenbanksystemen vertraut sind. Es werden vordefinierte Aufgaben ausgeführt, um eine Beispielmigration vorzunehmen. Wenn Sie die Anleitung abgeschlossen haben, können Sie den Code und die Schritte an Ihre Umgebung anpassen.
Das folgende Architekturdiagramm enthält eine Übersicht der Komponenten, die in dieser Anleitung zur Datenmigration verwendet werden:

Ziele
- Daten von Amazon DynamoDB zu Spanner migrieren
- Spanner-Datenbank und -Migrationstabelle erstellen
- NoSQL-Schema einem relationalen Schema zuordnen
- Beispiel-Dataset, das Amazon DynamoDB verwendet, erstellen und exportieren
- Daten zwischen Amazon S3 und Cloud Storage übertragen
- Mit Dataflow Daten in Spanner laden
Kosten
In dieser Anleitung werden die folgenden kostenpflichtigen Komponenten von Google Cloudverwendet:
Die Gebühren für Spanner beruhen auf der Rechenkapazität in Ihrer Instanz und der Menge an Daten, die während des monatlichen Abrechnungszyklus gespeichert werden. Im Rahmen der Anleitung verwenden Sie eine minimale Konfiguration dieser Ressourcen, die am Ende bereinigt werden. In der Praxis müssen Sie Ihre Durchsatz- und Speicheranforderungen abschätzen und dann mithilfe der Dokumentation zu Spanner-Instanzen bestimmen, wie viel Rechenkapazität Sie benötigen.
Neben Google Cloud -Ressourcen werden in dieser Anleitung die folgenden Amazon Web Services-Ressourcen (AWS) verwendet:
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
Diese Dienste werden nur während der Migration benötigt. Am Ende der Anleitung können Sie die Schritte zum Bereinigen aller Ressourcen ausführen, um unnötige Gebühren zu vermeiden. Mit dem AWS-Preisrechner können Sie die Kosten für diese Dienste kalkulieren.
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Legen Sie die Standardzone für Compute Engine fest, Beispiel:
us-central1-b. gcloud config set compute/zone us-central1-b - Klonen Sie das GitHub-Repository mit dem Beispielcode. git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- Rufen Sie das geklonte Verzeichnis auf. cd dynamodb-spanner-migration
- Erstellen Sie eine virtuelle Python-Umgebung. pip3 install virtualenv virtualenv env
- Virtuelle Umgebung aktivieren: source env/bin/activate
- Installieren Sie die erforderlichen Python-Module. pip3 install -r requirements.txt
- Rufen Sie in der AWS-Konsole den Bereich IAM auf, klicken Sie auf Roles und wählen Sie Create Role aus.
- Prüfen Sie, ob unter Art der vertrauenswürdigen Entität die Option AWS-Dienst ausgewählt ist.
- Wählen Sie unter Anwendungsfall die Option Lambda aus und klicken Sie dann auf Weiter.
- Geben Sie im Filterfeld Berechtigungsrichtlinien
AWSLambdaDynamoDBExecutionRoleein und drücken SieReturn, um die Suche zu starten. - Klicken Sie auf das Kästchen AWSLambdaDynamoDBExecutionRole und dann auf Weiter.
- Geben Sie im Feld Role name den Wert
dynamodb-spanner-lambda-roleein und klicken Sie dann auf Create role. - Klicken Sie im Bereich IAM der AWS-Konsole auf Nutzer und wählen Sie Nutzer hinzufügen aus.
- Geben Sie im Feld User name den Wert
dynamodb-spanner-migrationein. Klicken Sie unter Zugriffstyp das Kästchen links neben Zugriffsschlüssel – programmatischer Zugriff an.
Klicken Sie auf Next: Permissions.
Klicken Sie auf Bestehende Richtlinien direkt anhängen, nutzen Sie das Feld Suchen zum Filtern und wählen Sie das Kästchen neben jeder der folgenden Richtlinien aus:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
Klicken Sie auf Weiter: Tags, Weiter: Prüfen und dann auf Nutzer erstellen.
Klicken Sie auf Show, um die Anmeldedaten aufzurufen. Die Zugriffsschlüssel-ID und der geheime Zugriffsschlüssel für den neu erstellten Nutzer werden angezeigt. Lassen Sie dieses Fenster vorerst geöffnet, da Sie die Anmeldedaten im nächsten Abschnitt benötigen. Sie sollten diese Anmeldedaten an einem sicheren Ort aufbewahren, da Sie damit Änderungen an Ihrem Konto vornehmen können, die sich ggf. auf die Umgebung auswirken. Am Ende dieser Anleitung können Sie den IAM-Nutzer löschen.
Konfigurieren Sie die AWS-Befehlszeilenschnittstelle in Cloud Shell.
aws configure
Die Ausgabe sieht so aus:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- Geben Sie die
ACCESS KEY IDund denSECRET ACCESS KEYdes AWS IAM-Kontos ein, das Sie erstellt haben. - Geben Sie im Feld Default region name den Wert
us-west-2ein. Übernehmen Sie die Standardwerte der restlichen Felder.
- Geben Sie die
Schließen Sie das Fenster der AWS IAM-Konsole.
Erstellen Sie in Cloud Shell eine Amazon DynamoDB-Tabelle mit den Attributen der Beispieltabelle.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75Prüfen Sie, ob der Tabellenstatus
ACTIVElautet.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'Füllen Sie die Tabelle mit Beispieldaten.
python3 make-fake-data.py --table Migration --items 25000
Erstellen Sie eine Spanner-Instanz in derselben Region, in der Sie die Compute Engine-Standardzone festgelegt haben. z. B.
us-central1gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Erstellen Sie zusammen mit der Beispieltabelle eine Datenbank in der Spanner-Instanz.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"Aktivieren Sie Amazon DynamoDB-Streams für Ihre Quelltabelle in Cloud Shell.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGESRichten Sie ein Pub/Sub-Thema ein, das die Änderungen empfangen soll.
gcloud pubsub topics create spanner-migration
Die Ausgabe sieht so aus:
Created topic [projects/your-project/topics/spanner-migration].
Erstellen Sie ein IAM-Dienstkonto, um Tabellenaktualisierungen an das Pub/Sub-Thema per Push zu übertragen.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"Die Ausgabe sieht so aus:
Created service account [spanner-migration].
Erstellen Sie eine IAM-Richtlinienbindung, damit das Dienstkonto die Berechtigung zum Veröffentlichen in Pub/Sub hat. Ersetzen Sie
GOOGLE_CLOUD_PROJECTdurch den Namen Ihres Google Cloud Projekts.gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comDie Ausgabe sieht so aus:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
Erstellen Sie Anmeldedaten für das Dienstkonto.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comDie Ausgabe sieht so aus:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
Bereiten Sie die AWS Lambda-Funktion vor und verpacken Sie sie, um Änderungen in Amazon DynamoDB-Tabellen an Pub/Sub-Thema zu übertragen.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
Erstellen Sie eine Variable, um den Amazon Resource Name (ARN) der zuvor erstellten Lambda-Ausführungsrolle zu erfassen.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)Verwenden Sie das Paket
pubsub-lambda.zip, um die AWS Lambda-Funktion zu erstellen.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"Die Ausgabe sieht so aus:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Create a variable to capture the ARN of the Amazon DynamoDB stream for your table.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Verknüpfen Sie die Lambda-Funktion mit der Amazon DynamoDB-Tabelle.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONZum Optimieren der Reaktionszeit beim Testen fügen Sie am Ende des vorherigen Befehls
--batch-size 1hinzu. Dadurch wird die Funktion jedes Mal ausgelöst, wenn Sie ein Element erstellen, aktualisieren oder löschen.Es wird eine Ausgabe wie diese angezeigt:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...Erstellen Sie in Cloud Shell eine Variable für einen Bucket-Namen, den Sie in den folgenden Abschnitten verwenden.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportErstellen Sie einen Amazon S3-Bucket, in den der DynamoDB-Export kopiert werden soll.
aws s3 mb s3://${BUCKET}Wechseln Sie in der AWS Management Console zu DynamoDB und klicken Sie auf Tabellen.
Klicken Sie auf die Tabelle
Migration.Klicken Sie auf dem Tab Exporte und Stream auf Nach S3 exportieren.
Aktivieren Sie
point-in-time-recovery(PITR), wenn Sie dazu aufgefordert werden.Klicken Sie auf S3 durchsuchen, um den zuvor erstellten S3-Bucket auszuwählen.
Klicken Sie auf Exportieren.
Klicken Sie auf das Symbol Aktualisieren, um den Status des Exportjobs zu aktualisieren. Der Export kann mehrere Minuten dauern.
Wenn der Prozess beendet wurde, sehen Sie sich den Ausgabe-Bucket an.
aws s3 ls --recursive s3://${BUCKET}Dieser Schritt dauert ca. fünf Minuten. Nach Abschluss des Vorgangs wird in etwa folgende Ausgabe angezeigt:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket, in den die exportierten Dateien von Amazon S3 kopiert werden sollen.
gcloud storage buckets create gs://${BUCKET}Synchronisieren Sie die Dateien von Amazon S3 nach Cloud Storage. Für die meisten Kopiervorgänge können Sie den Befehl
rsyncverwenden. Wenn die Exportdateien groß sind (mehrere GB oder mehr), können Sie die Übertragung mit dem Cloud Storage Transfer Service im Hintergrund durchführen.gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objectsFühren Sie einen Cloud Dataflow-Job mit Apache Beam-Beispielcode aus, um die Daten aus den exportierten Dateien in die Spanner-Tabelle zu schreiben.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Gehen Sie in der Google Cloud Console zu Dataflow, um den Fortschritt des Importjobs zu beobachten.
Während der Job ausgeführt wird, können Sie sich das Ausführungsdiagramm ansehen, um die Logs zu prüfen. Klicken Sie auf den Job mit dem Status "Wird ausgeführt".
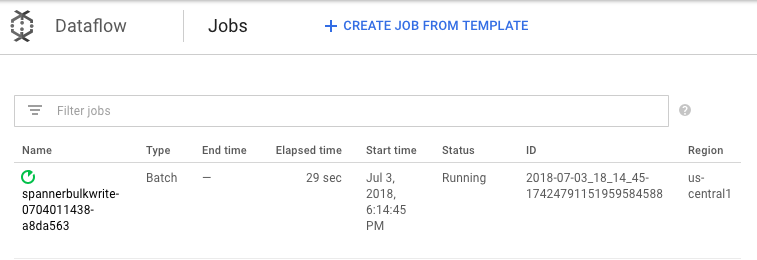
Klicken Sie auf die einzelnen Phasen, um zu sehen, wie viele Elemente schon verarbeitet wurden. Der Import ist abgeschlossen, wenn für alle Phasen der Status Erfolgreich angezeigt wird. In jeder Phase wird die gleiche Anzahl von Elementen angezeigt, die in Ihrer Amazon DynamoDB-Tabelle erstellt wurden.
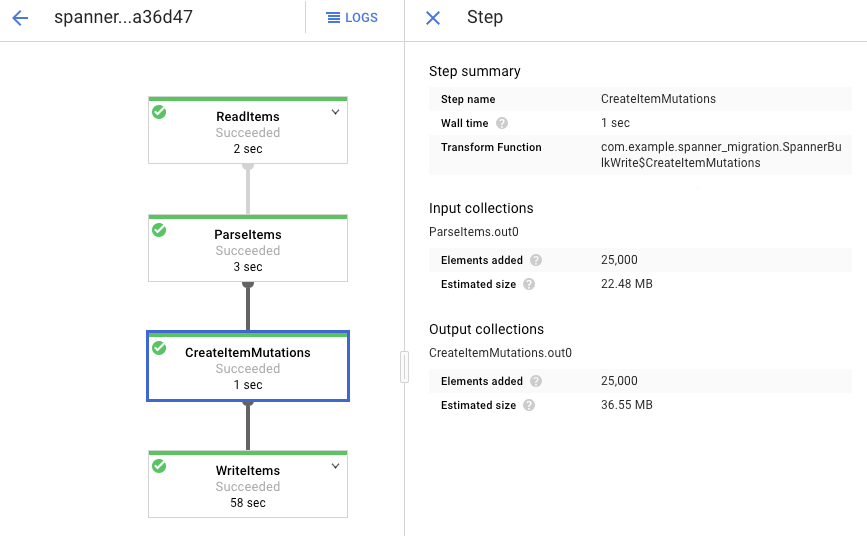
Die Anzahl der Einträge in der Spanner-Zieltabelle muss der Anzahl der Elemente in der Amazon DynamoDB-Tabelle entsprechen.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
Die Ausgabe sieht so aus:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
Überprüfen Sie zufällig ausgewählte Einträge in jeder Tabelle auf Konsistenz.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"Die Ausgabe sieht so aus:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
Fragen Sie die Amazon DynamoDB-Tabelle mit demselben
Usernameab, der im vorherigen Schritt von der Spanner-Abfrage zurückgegeben wurde. Beispiel:aallen2538Der Wert bezieht sich auf die Beispieldaten in Ihrer Datenbank.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'Die Werte der anderen Felder sollten den Werten der Spanner-Ausgabe entsprechen. Die Ausgabe sieht so aus:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }Erstellen Sie ein Abo für das Pub/Sub-Thema, an das AWS Lambda Ereignisse sendet.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migrationDie Ausgabe sieht so aus:
Created subscription [projects/your-project/subscriptions/spanner-migration].
Führen Sie den Dataflow-Job in Cloud Shell aus, um die an Pub/Sub gesendeten Änderungen in die Spanner-Tabelle zu schreiben.
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"Wie beim Laden im Batchverfahren gehen Sie in der Google Cloud -Konsole zu Dataflow, um den Fortschritt des Jobs zu beobachten.
Klicken Sie auf den Job mit dem Status Wird ausgeführt.
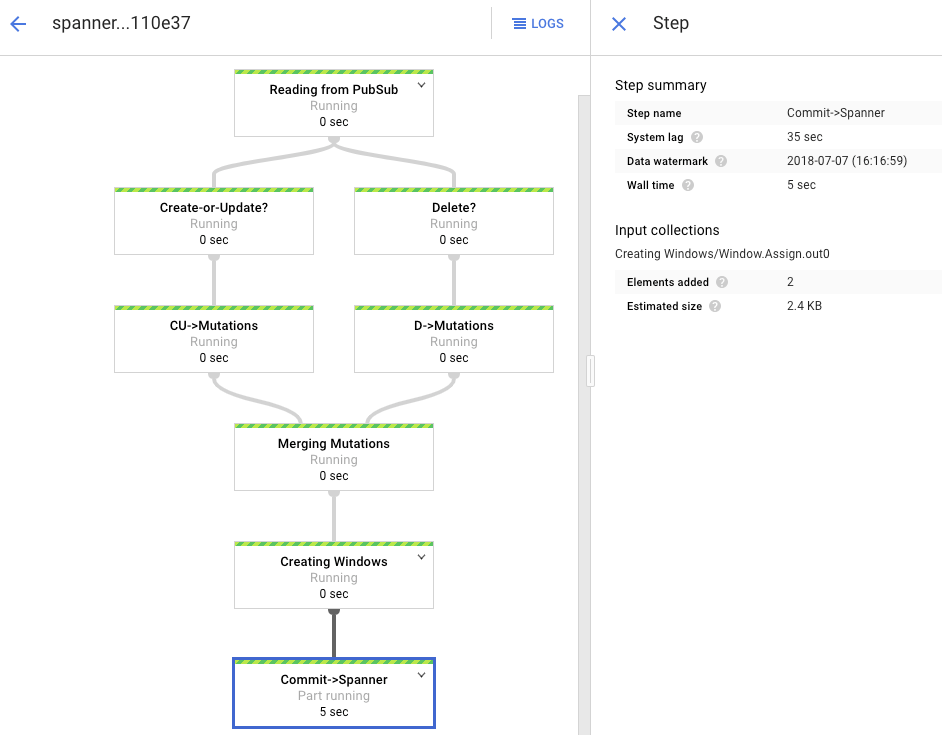
Im Verarbeitungsdiagramm wird eine ähnliche Ausgabe wie vorher angezeigt, aber jedes verarbeitete Element wird im Statusfenster gezählt. Die Systemverzögerungszeit ist eine grobe Schätzung der voraussichtlichen Verzögerung, bis Änderungen in der Spanner-Tabelle angezeigt werden.
Führen Sie eine Abfrage für eine nicht vorhandene Zeile in Spanner durch.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Der Vorgang gibt keine Ergebnisse zurück.
Erstellen Sie in Amazon DynamoDB einen Eintrag mit demselben Schlüssel, den Sie in der Spanner-Abfrage verwendet haben. Wenn der Befehl erfolgreich ausgeführt wird, erfolgt keine Ausgabe.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'Führen Sie dieselbe Abfrage noch einmal aus, um zu prüfen, ob sich die Zeile jetzt in Spanner befindet.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"In der Ausgabe wird die eingefügte Zeile angezeigt:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
Ändern Sie ein paar Attribute im ursprünglichen Element und aktualisieren Sie die Amazon DynamoDB-Tabelle.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEWEs wird eine Ausgabe wie diese angezeigt:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }Prüfen Sie, ob die Änderungen in die Spanner-Tabelle übernommen wurden.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Die Ausgabe sieht so aus:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Löschen Sie das Testelement aus der Amazon DynamoDB-Quelltabelle.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'Prüfen Sie, ob die entsprechende Zeile aus der Spanner-Tabelle gelöscht wurde. Wenn die Änderung übernommen wurde, gibt der folgende Befehl keine Zeilen zurück:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Rufen Sie Spanner auf.
Klicken Sie auf Spanner Studio.
Geben Sie in das Feld Abfrage den folgenden Wert ein und klicken Sie auf Abfrage ausführen.
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
Nachdem die Abfrage ausgeführt wurde, klicken Sie auf Erklärung und vergleichen Gescannte Zeilen mit Zurückgegebene Zeilen. Ohne Index scannt Spanner die gesamte Tabelle, um eine kleine Teilmenge von Daten zurückzugeben, die der Abfrage entsprechen.
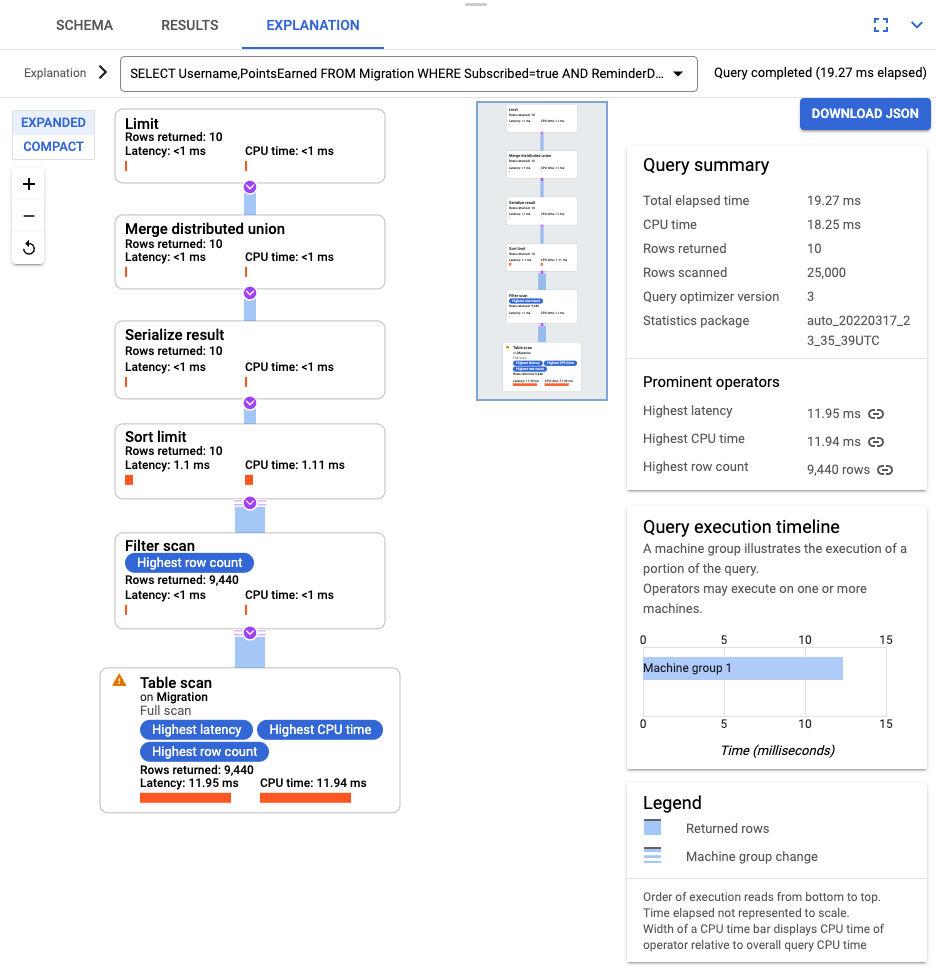
Wenn diese Abfrage regelmäßig ausgeführt wird, sollten Sie einen zusammengesetzten Index für die Spalten "Subscribed" und "ReminderDate" erstellen. Wählen Sie in der Spanner-Konsole im linken Navigationsbereich Indexe aus und klicken Sie auf Index erstellen.
Geben Sie in das Textfeld die Indexdefinition ein.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
Klicken Sie auf Erstellen, um den Erstellvorgang der Datenbank im Hintergrund zu starten.
Nachdem der Index erstellt wurde, führen Sie die Abfrage noch einmal aus und fügen den Index hinzu.
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10Untersuchen Sie noch einmal die Erklärung der Abfrage. Die Anzahl der gescannten Zeilen (Rows scanned) ist weniger geworden. Die Anzahl der in jedem Schritt zurückgegebenen Zeilen (Rows returned) entspricht dem von der Abfrage zurückgegebenen Wert.

Verwenden Sie GSON, um eingehende JSON-Dateien zu parsen und Mutationen zu erstellen. Passen Sie die JSON-Definition an Ihre Daten an.
Passen Sie die entsprechende JSON-Zuordnung an.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Löschen Sie die DynamoDB-Tabelle mit dem Namen Migration.
- Löschen Sie den Amazon S3-Bucket und die Lambda-Funktion, die Sie bei den Migrationsschritten erstellt haben.
- Löschen Sie zuletzt den für diese Anleitung erstellten AWS IAM-Nutzer.
- Spanner-Schema optimieren
- Dataflow für komplexere Situationen nutzen
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Umgebung vorbereiten
In dieser Anleitung führen Sie Befehle in Cloud Shell aus. Cloud Shell bietet Zugriff auf die Befehlszeile in Google Cloudund umfasst die Google Cloud CLI und andere Tools, die Sie für die Google Cloud -Entwicklung benötigen. Die Initialisierung von Cloud Shell kann mehrere Minuten dauern.
AWS-Zugriff konfigurieren
In dieser Anleitung erstellen und löschen Sie Amazon DynamoDB-Tabellen, Amazon S3-Buckets und andere Ressourcen. Damit Sie auf diese Ressourcen zugreifen können, müssen Sie die erforderlichen AWS IAM-Berechtigungen (Identity and Access Management) erstellen. Sie können ein Test- oder Sandbox-AWS-Konto verwenden, um eine Beeinträchtigung der Produktionsressourcen im selben Konto zu vermeiden.
AWS IAM-Rolle für AWS Lambda erstellen
In diesem Abschnitt erstellen Sie eine AWS IAM-Rolle, die in einem späteren Anleitungsschritt in AWS Lambda verwendet wird.
AWS IAM-Nutzer erstellen
In den folgenden Schritten erstellen Sie einen AWS IAM-Nutzer mit programmatischem Zugriff auf AWS-Ressourcen, die in der Anleitung verwendet werden.
AWS-Befehlszeilenschnittstelle konfigurieren
Informationen zum Datenmodell
Im folgenden Abschnitt sind die Ähnlichkeiten und Unterschiede zwischen Datentypen, Schlüsseln und Indexen für Amazon DynamoDB und Spanner beschrieben.
Datentypen
Spanner verwendet GoogleSQL-Datentypen. In der folgenden Tabelle ist die Zuordnung von Datentypen in Amazon DynamoDB zu Datentypen in Spanner beschrieben.
| Amazon DynamoDB | Spanner |
|---|---|
| Number | Je nach Genauigkeit oder beabsichtigter Verwendung kann dieser Datentyp den Typen INT64, FLOAT64, TIMESTAMP oder DATE zugeordnet werden. |
| String | String |
| Boolean | BOOL |
| Null | Kein expliziter Typ. Spalten können Nullwerte enthalten. |
| Binary | Byte |
| Sets | Array |
| Map und List | Struct, wenn die Struktur konsistent ist und mithilfe der Tabellen-DDL-Syntax beschrieben werden kann. |
Primärschlüssel
Ein Amazon DynamoDB-Primärschlüssel sorgt für Eindeutigkeit und kann entweder ein Hash-Schlüssel oder eine Kombination aus Hash-Schlüssel und Bereichsschlüssel sein. In dieser Anleitung wird zuerst die Migration einer Amazon DynamoDB-Tabelle demonstriert, deren Primärschlüssel ein Hash-Schlüssel ist. Dieser Hash-Schlüssel wird zum Primärschlüssel Ihrer Spanner-Tabelle. Im Abschnitt zu verschränkten Tabellen modellieren Sie später eine Situation, in der eine Amazon DynamoDB-Tabelle einen Primärschlüssel verwendet, der sich aus einem Hash-Schlüssel und einem Bereichsschlüssel zusammensetzt.
Sekundäre Indexe
Sowohl Amazon DynamoDB als auch Spanner unterstützen die Erstellung eines Index für ein Attribut, das kein Primärschlüssel ist. Notieren Sie sich alle sekundären Indexe in Ihrer Amazon DynamoDB-Tabelle, damit Sie sie in der Spanner-Tabelle erstellen können. Dies wird in einem späteren Abschnitt dieser Anleitung behandelt.
Beispieltabelle
Zur Vereinfachung dieser Anleitung migrieren Sie die folgende Beispieltabelle von Amazon DynamoDB zu Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| Tabellenname |
Migration
|
Migration
|
| Primärschlüssel |
"Username" : String
|
"Username" : STRING(1024)
|
| Schlüsseltyp | Hash | – |
| Sonstige Felder |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Amazon DynamoDB-Tabelle vorbereiten
Im folgenden Abschnitt erstellen Sie eine Amazon DynamoDB-Quelltabelle und füllen diese mit Daten.
Spanner-Datenbank erstellen
Sie erstellen eine Spanner-Instanz mit der kleinstmöglichen Rechenkapazität: 100 Verarbeitungseinheiten. Diese Rechenkapazität ist für den Umfang dieser Anleitung ausreichend. In einer Produktionsbereitstellung werden weitere Knoten benötigt. Informationen zur Ermittlung der geeigneten Rechenkapazität, die den Leistungsanforderungen Ihrer Datenbank entspricht, finden Sie in der Dokumentation zu Spanner-Instanzen.
In diesem Beispiel erstellen Sie gleichzeitig mit der Datenbank ein Tabellenschema. Außerdem ist es möglich und üblich, Schemaaktualisierungen durchzuführen, nachdem Sie die Datenbank erstellt haben.
Migration vorbereiten
In den nächsten Abschnitten erfahren Sie, wie Sie die Amazon DynamoDB-Quelltabelle exportieren und die Pub/Sub-Replikation so einstellen, dass während des Exports auftretende Änderungen an der Datenbank erfasst werden.
Änderungen an Pub/Sub streamen
Zum Streamen von Datenbankänderungen an Pub/Sub verwenden Sie eine AWS Lambda-Funktion.
Amazon DynamoDB-Tabelle nach Amazon S3 exportieren
Migration ausführen
Die Pub/Sub-Bereitstellung wurde eingerichtet und Sie können alle nach dem Export vorgenommenen Tabellenänderungen verarbeiten.
Exportierte Tabelle in Cloud Storage kopieren
Batch-Import der Daten
Neue Änderungen replizieren
Wenn der Batch-Importjob abgeschlossen ist, richten Sie einen Streamingjob ein, um aktive Aktualisierungen aus der Quelltabelle in Spanner zu schreiben. Sie abonnieren die Ereignisse über Pub/Sub und schreiben sie in Spanner.
Die von Ihnen erstellte Lambda-Funktion ist dazu konfiguriert, Änderungen in der Amazon DynamoDB-Quelltabelle zu erfassen und in Pub/Sub zu veröffentlichen.
Der Dataflow-Job, den Sie in der Batch-Ladephase ausgeführt haben, bestand aus einem endlichen Eingabe-Dataset. Dies wird auch als begrenztes Dataset bezeichnet. Dieser Dataflow-Job verwendet Pub/Sub als Streamingquelle und gilt als unbegrenzt. Weitere Informationen zu diesen beiden Quelltypen finden Sie im Programmierleitfaden für Apache Beam im Abschnitt zu PCollections. Der Dataflow-Job in diesem Schritt soll aktiv bleiben, damit er beim Abschluss nicht beendet wird. Der Dataflow-Streamingjob behält den Status Wird ausgeführt bei, statt zu Erfolgreich zu wechseln.
Replikation prüfen
Wenn Sie ein paar Änderungen an der Quelltabelle vornehmen, können Sie verifizieren, ob die Änderungen in die Spanner-Tabelle repliziert werden.
Verschränkte Tabellen verwenden
Spanner unterstützt das Konzept der verschränkten Tabellen. Dies ist ein Entwurfsmodell, bei dem ein Element der obersten Ebene mehrere verschachtelte Elemente enthält, die sich auf das Element der obersten Ebene beziehen. Beispiel: Ein Kunde und seine Bestellungen oder ein Spieler und seine Spielergebnisse. Wenn Ihre Amazon DynamoDB-Quelltabelle einen Primärschlüssel verwendet, der sich aus einem Hash-Schlüssel und einem Bereichsschlüssel zusammensetzt, können Sie ein verschränktes Tabellenschema modellieren, wie im folgenden Diagramm dargestellt. Mit dieser Struktur können Sie für die verschränkte Tabelle effiziente Abfragen durchführen, während Sie Felder in der übergeordneten Tabelle zusammenführen.

Sekundäre Indexe anwenden
Als Best Practice wird empfohlen, sekundäre Indexe auf Spanner-Tabellen anzuwenden, nachdem die Daten geladen wurden. Da die Replikation jetzt funktioniert, können Sie einen sekundären Index einrichten, um Abfragen zu beschleunigen. Wie Spanner-Tabellen sind sekundäre Spanner-Indexe vollständig konsistent. Sie sind nicht letztendlich konsistent, wie es in vielen NoSQL-Datenbanken üblich ist. Diese Funktion kann die Entwicklung Ihrer Anwendung vereinfachen.
Führen Sie eine Abfrage aus, die keine Indexe verwendet. Dabei suchen Sie nach den obersten n Treffern für einen bestimmten Spaltenwert. Dies ist eine gängige Abfrage zur Verbesserung der Datenbankeffizienz in Amazon DynamoDB.
Verschränkte Indexe
Sie können in Spanner verschränkte Indexe einrichten. Die im vorherigen Abschnitt beschriebenen sekundären Indexe befinden sich auf der Stammebene der Datenbankhierarchie und nutzen Indexe genauso wie eine herkömmliche Datenbank. Ein verschränkter Index befindet sich im Kontext seiner verschränkten Zeile. Weitere Informationen dazu, wo Sie verschränkte Indexe anwenden können, finden Sie unter Indexoptionen.
An Ihr Datenmodell anpassen
Wenn Sie den Migrationsteil dieser Anleitung auf Ihre eigene Situation anwenden möchten, müssen Sie die Apache Beam-Quelldateien anpassen. Das Quellschema sollte jedoch nicht während des eigentlichen Migrationsfensters geändert werden, da sonst möglicherweise Daten verloren gehen.
In den vorherigen Schritten haben Sie den Apache Beam-Quellcode für den Bulk-Import geändert. Der Quellcode für den Streamingteil der Pipeline muss auf ähnliche Weise geändert werden. Abschließend müssen Sie die Tabellenerstellungsskripts, -schemas und -indexe Ihrer Spanner-Zieldatenbank anpassen.
Bereinigen
Damit Ihrem Google Cloud -Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
Projekt löschen
AWS-Ressourcen löschen
Wenn das AWS-Konto nicht nur für diese Anleitung verwendet wird, sollten Sie beim Löschen der folgenden Ressourcen vorsichtig vorgehen: