Die Speichertechnologien von Google werden von einigen der weltweit größten Anwendungen verwendet. Mit der Nutzung dieser Systeme geht jedoch nicht immer die Skalierung einher. Designer müssen sich genau überlegen, wie sie ihre Daten so modellieren, dass ihre Anwendungen skalierbar und leistungsfähig sind, wenn sie in verschiedenen Dimensionen anwachsen.
Spanner ist eine verteilte Datenbank, bei der ein anderer Umgang mit Schemadesign und Zugriffsmustern als bei herkömmlichen Datenbanken erforderlich ist. Verteilte Systeme zwingen Designer von Natur aus dazu, sich Gedanken über die Daten- und Verarbeitungslokalität zu machen.
Spanner unterstützt SQL-Abfragen und -Transaktionen, die horizontal skaliert werden können. Eine sorgfältige Planung ist oft erforderlich, um den vollen Nutzen von Spanner zu erzielen. In diesem Artikel werden einige der wichtigsten Konzepte beschrieben, mit denen Sie dafür sorgen können, dass Ihre Anwendung auf beliebige Ebenen skaliert werden und ihre Leistung maximiert werden kann. Insbesondere zwei Tools spielen eine wichtige Rolle bei der Skalierbarkeit: Schlüsselbestimmung und Verschränkung.
Tabellenlayout
Die Zeilen in einer Spanner-Tabelle sind lexikografisch nach PRIMARY
KEY organisiert. Konzeptionell werden Schlüssel nach der Verkettung der Spalten in der Reihenfolge angeordnet, in der sie in der PRIMARY KEY-Klausel deklariert werden. Dies weist alle Standard-Properites der Lokalität auf:
- Es ist effizient, die Tabelle in lexikografischer Reihenfolge zu scannen.
- Ausreichend eng verwandte Zeilen werden in den gleichen Festplattenblöcken gespeichert und werden gemeinsam gelesen und im Cache gespeichert.
Spanner repliziert Ihre Daten in mehreren Zonen, um Verfügbarkeit und Skalierbarkeit zu gewährleisten. Jede Zone enthält ein vollständiges Replikat Ihrer Daten. Wenn Sie einen Spanner-Instanzknoten bereitstellen, geben Sie die Rechenkapazität an. Die Rechenkapazität ist die Menge an Rechenressourcen, die Ihrer Instanz in jeder dieser Zonen zugewiesen ist. Obwohl jedes Replikat eine vollständige Liste aller Ihrer Daten ist, werden Daten innerhalb eines Replikats über die Rechenressourcen dieser Zone partitioniert.
Daten innerhalb der einzelnen Spanner-Replikate sind in zwei Hierarchieebenen organisiert: Datenbank-Splits und Blöcke. Splits enthalten zusammenhängende Zeilenreihen und sind die Einheit, mit der Spanner Ihre Datenbank über Computerressourcen verteilt. Mit der Zeit können Splits in kleinere Teile zerlegt, zusammengeführt oder an andere Knoten in Ihrer Instanz verschoben werden, um die Parallelität zu erhöhen und die Skalierung Ihrer Anwendung zu ermöglichen. Vorgänge, die Splits umfassen, sind aufgrund erhöhter Kommunikation teurer als gleichwertige Vorgänge, die das nicht tun. Dies gilt auch dann, wenn diese Splits zufällig von demselben Knoten bereitgestellt werden.
Es gibt zwei Arten von Tabellen in Spanner: Stammtabellen (manchmal auch als übergeordnete Tabellen bezeichnet) und verschränkte Tabellen. Verschränkte Tabellen werden definiert, indem eine andere Tabelle als ihr übergeordnetes Element angegeben wird. Dies bewirkt, dass Zeilen in der verschränkten Tabelle mit der übergeordneten Zeile gruppiert werden. Stammtabellen haben kein übergeordnetes Element und jede Zeile in einer Stammtabelle definiert eine neue übergeordnete Zeile oder Stammzeile. Zeilen, die mit dieser Stammzeile verschränkt sind, werden untergeordnete Zeilen genannt und eine Stammzeile zusammen mit allen ihren untergeordneten Zeilen wird als Zeilenbaum bezeichnet. Nur wenn eine übergeordnete Zeile existiert, können Sie untergeordnete Zeilen einfügen. Die übergeordnete Zeile kann entweder bereits in der Datenbank vorhanden sein oder vor dem Einfügen der untergeordneten Zeilen in derselben Transaktion eingefügt werden.
Spanner partitioniert Splits automatisch, wenn dies aufgrund der Größe oder der Auslastung für notwendig erachtet wird. Um die Datenlokalität zu erhalten, fügt Spanner Split-Grenzen vorzugsweise so nah wie möglich an den Stammtabellen hinzu, damit ein bestimmter Zeilenbaum in einem einzigen Split aufbewahrt werden kann. Das bedeutet, dass Vorgänge innerhalb eines Zeilenbaums in der Regel effizienter sind, da sie wahrscheinlich keine Kommunikation mit anderen Splits erfordern.
Wenn es jedoch in einer untergeordneten Zeile einen Hotspot gibt, versucht Spanner, Split-Grenzen zu verschränkten Tabellen hinzuzufügen, um diese Hotspot-Zeile zusammen mit allen untergeordneten Zeilen zu isolieren.
Die Bestimmung der Stammtabellen ist eine wichtige Entscheidung bei der Erstellung einer skalierbaren Anwendung. Bei Stammtabellen handelt es sich in der Regel um Nutzer, Konten, Projekte und Ähnliches und die dazugehörigen untergeordneten Tabellen sollten die meisten anderen Daten über das betroffene Element enthalten.
Empfehlungen:
- Verwenden Sie ein gemeinsames Schlüsselpräfix für verwandte Zeilen in derselben Tabelle, um die Lokalität zu verbessern.
- Es ist oft sinnvoll, relationale Daten in einer anderen Tabelle zu verschränken.
Kompromisse bei der Lokalität
Wenn Daten häufig zusammen geschrieben oder gelesen werden, kann es sowohl für die Latenz als auch für den Durchsatz von Vorteil sein, sie in einem Cluster zusammenzufügen, indem Sie Primärschlüssel sorgfältig auswählen und Verschränkung verwenden. Das liegt daran, dass es feste Kosten für die Kommunikation mit einem Server oder einem Festplattenblock gibt. Warum also nicht so viel wie möglich bekommen? Je höher die Anzahl der Server, mit denen Sie kommunizieren, desto höher ist die Wahrscheinlichkeit, dass Sie auf einen temporär belegten Server treffen, wodurch die Latenzzeiten verlängert werden. Schließlich haben Transaktionen, die Splits umfassen, etwas höhere CPU-Kosten und -Latenz aufgrund der Verteilung bei Zwei-Phasen-Commits, obwohl sie in Spanner sowohl automatisch als auch transparent sind.
Wenn Daten relational sind, aber nicht oft zusammen darauf zugegriffen wird, sollten Sie sich bemühen, sie zu trennen. Dies hat den größten Vorteil, wenn die Daten, auf die selten zugegriffen wird, umfangreich sind. Beispielsweise speichern viele Datenbanken umfangreiche binäre Daten "out-of-band" von den Primärzeilendaten, wobei nur Referenzen auf umfangreiche Daten verschränkt sind.
Beachten Sie, dass Zwei-Phasen-Commits und nicht lokale Datenoperationen zu einem gewissen Grad unvermeidbar sind. Sie müssen keine perfekte Lokalitätsgeschichte für jede Operation einrichten. Konzentrieren Sie sich darauf, die gewünschte Lokalität für die wichtigsten Stammelemente und häufigsten Zugangsmuster zu erhalten, und lassen Sie zu, dass weniger häufige oder weniger leistungsorientierte verteilte Operationen bei Bedarf stattfinden. Zwei-Phasen-Commits und verteilte Lesevorgänge dienen dazu, Schemas zu vereinfachen und die Programmierarbeit zu erleichtern. In allen außer den leistungsstärksten Anwendungsfällen ist es besser, sie zuzulassen.
Empfehlungen:
- Organisieren Sie Ihre Daten in Hierarchien, sodass Daten, die zusammen gelesen oder geschrieben werden, in der Regel nahe beieinander liegen.
- Versuchen Sie, große Spalten in nicht verschränkten Tabellen zu speichern, wenn seltener auf sie zugegriffen wird.
Indexoptionen
Mit sekundären Indexen finden Sie Zeilen schnell nach anderen Werten als dem Primärschlüssel. Spanner unterstützt sowohl nicht verschränkte als auch verschränkte Indexe. Nicht verschränkte Indexe sind Standard und analog zu dem, was in der traditionellen RDBMS unterstützt wird. Sie legen keine Beschränkungen der indexierten Spalten fest und sind zwar leistungsstark, aber nicht immer die richtige Wahl. Verschränkte Indexe sollten über Spalten definiert sein, die ein Präfix mit der übergeordneten Tabelle gemeinsam haben und mehr Kontrolle über die Lokalität zulassen.
Spanner speichert Indexdaten auf dieselbe Weise wie Tabellen mit einer Zeile pro Indexeintrag. Viele der Designaspekte für Tabellen gelten auch für Indexe. Nicht verschränkte Indexe speichern Daten in Stammtabellen. Da Stammtabellen in einer beliebigen Stammzeile aufgeteilt werden können, wird dadurch ermöglicht, dass verschränkte Indexe auf beliebige Größe skaliert werden können und Hotspots bei fast jeder Arbeitslast ignoriert werden. Leider bedeutet dies auch, dass die Indexeinträge normalerweise nicht in den gleichen Splits wie die Primärdaten liegen. Das führt zu mehr Arbeit und Latenz für alle Schreibvorgänge und fügt zusätzliche Splits hinzu, die zum Lesezeitpunkt beachtet werden müssen.
Verschränkte Indexe hingegen speichern Daten in verschränkten Tabellen. Sie sind für den Fall geeignet, dass Sie eine Suche innerhalb der Domain einer einzelnen Entität durchführen. Verschränkte Indexe zwingen Daten und Indexeinträge dazu, im selben Zeilenbaum zu bleiben, was Verknüpfungen zwischen ihnen viel effizienter gestaltet. Hier einige Anwendungsbeispiele für einen verschränkten Index:
- Nach verschiedenen Reihenfolgentypen auf Fotos zugreifen, z. B. Erstellungsdatum, Zuletzt geändert, Titel, Album usw.
- Alle Beiträge finden, die einen bestimmten Satz von Tags haben.
- Meine früheren Bestellungen finden, die einen bestimmten Artikel enthielten.
Empfehlungen:
- Verwenden Sie nicht verschränkte Indexe, wenn Sie Zeilen an einem beliebigen Standort Ihrer Datenbank suchen müssen.
- Bevorzugen Sie verschränkte Indexe, wenn Ihre Suchvorgänge auf eine einzelne Entität beschränkt sind.
STORING-Indexklausel
Mit sekundären Indexen können Sie Zeilen mithilfe anderer Attribute als dem Primärschlüssel finden. Wenn sich alle angeforderten Daten im Index selbst befinden, können sie alleine aufgerufen werden, ohne dass der primäre Datensatz gelesen werden muss. Dies kann erhebliche Ressourcen sparen, da keine Verknüpfung erforderlich ist.
Unglücklicherweise sind Indexschlüssel auf 16 in der Anzahl und 8 KiB in der Gesamtgröße beschränkt, was die Menge dessen begrenzt, was darin eingefügt werden kann. Spanner hat die Möglichkeit, zusätzliche Daten über die STORING-Klausel in jedem Index zu speichern, um diese Einschränkungen auszugleichen. Das STORING einer Spalte in einem Index führt dazu, dass ihre Werte dupliziert werden, wobei eine Kopie im Index gespeichert wird. Sie können sich einen Index mit STORING als eine einfache materialisierte Ansicht mit einer einzelnen Tabelle vorstellen (Ansichten werden in Spanner zur Zeit nicht nativ unterstützt).
Eine andere nützliche Anwendung von STORING ist als Teil eines NULL_FILTERED-Index.
So können Sie festlegen, was effektiv eine materialisierte Ansicht einer kleinen Teilmenge einer Tabelle ist, die Sie effizient scannen können. Beispielsweise können Sie einen solchen Index für die Spalte is_unread eines Postfachs erstellen. So können Sie die ungelesenen Nachrichten in einem einzelnen Tabellenscan anzeigen, ohne für eine vollständige Kopie jedes Postfachs zu bezahlen.
Empfehlungen:
- Nutzen Sie
STORINGeffektiv, um einen Kompromiss zwischen Lesezeitleistung und Speichergröße sowie Schreibzeitleistung zu schaffen. - Verwenden Sie
NULL_FILTERED, um die Speicherkosten von Indexen mit geringer Dichte zu steuern.
Anti-Muster
Anti-Muster: Zeitstempel sortieren
Viele Schemadesigner neigen dazu, eine Stammtabelle zu definieren, die nach Zeitstempel sortiert ist und nach jedem Schreibvorgang aktualisiert wird. Dies ist leider eines der am wenigsten skalierbaren Dinge, die Sie tun können. Denn dieses Design führt zu einem riesigen Hotspot am Ende der Tabelle, der nicht so einfach vermieden werden kann. Wenn Schreibraten zunehmen, nehmen auch die RPCs auf einen einzelnen Split sowie Sperrenkonflikte und andere Probleme zu. Oft tauchen diese Probleme nicht in kleinen Belastungstests auf und tauchen stattdessen auf, wenn die Anwendung schon seit einiger Zeit in Betrieb ist. Dann ist es zu spät.
Wenn Ihre Anwendung auf jeden Fall ein Log enthalten muss, das nach Zeitstempel geordnet ist, können Sie das Log lokal machen, indem Sie es in eine Ihrer anderen Stammtabellen verschränken. Dies hat den Vorteil der Verteilung des Hotspots über viele Stammtabellen. Sie müssen jedoch darauf achten, dass jede einzelne Stammtabelle eine ausreichend niedrige Schreibrate hat.
Wenn Sie eine geordnete Zeitstempel-Tabelle für globale (stammübergreifende) Tabellen benötigen und höhere Schreibraten für diese Tabelle als für einen einzelnen Knoten erforderlich sind, verwenden Sie die Fragmentierung auf Anwendungsebene. Beim Fragmentieren (Sharding) einer Tabelle wird sie in eine Zahl N ungefähr gleich großer Teile partitioniert, die als Fragmente (Shards) bezeichnet werden. Dazu wird dem ursprünglichen Primärschlüssel in der Regel eine zusätzliche ShardId-Spalte mit Ganzzahlwerten zwischen [0, N) vorangestellt. Die ShardId für einen bestimmten Schreibvorgang wird normalerweise entweder zufällig oder durch Hashing eines Teils des Basisschlüssels ausgewählt. Hashing wird oft bevorzugt, da es verwendet werden kann, um sicherzustellen, dass alle Datensätze eines bestimmten Typs in dasselbe Fragment übergehen, was die Wiederherstellungsleistung verbessert. In jedem Fall sollten die Schreibvorgänge im Laufe der Zeit gleichmäßig über alle Fragmente verteilt werden.
Dieser Ansatz bedeutet manchmal, dass Lesevorgänge alle Fragmente scannen müssen, um die ursprüngliche Gesamtordnung von Schreibvorgängen zu rekonstruieren.
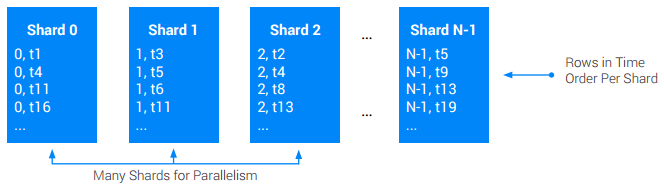
Empfehlungen:
- Vermeiden Sie nach Zeitstempel sortierte Tabellen mit hohen Schreibraten um jeden Preis.
- Verwenden Sie eine Technik, um Hotspots zu vermeiden, sei es durch Verschränken in einer anderen Tabelle oder durch Fragmentierung.
Anti-Muster: Sequenzen
App-Entwickler verwenden gern Datenbanksequenzen (oder automatische Inkrementierung), um Primärschlüssel zu generieren. Leider ist diese Gewohnheit aus den Zeiten von RDBMS (auch "Surrogate-Schlüssel" genannt) fast genauso schädlich wie das Anti-Muster der Zeitstempel-Reihenfolgen, das oben beschrieben wurde. Der Grund dafür ist, dass Datenbanksequenzen dazu neigen, Werte über die Zeit quasi-monoton zu erzeugen, um Werte zu erzeugen, die sich nahe beieinander befinden. Dies erzeugt typischerweise Hotspots, wenn sie als Primärschlüssel verwendet werden, insbesondere für Stammzeilen.
Im Gegensatz zu herkömmlicher RDBMS-Norm empfehlen wir, dass Sie für Primärschlüssel immer echte Attribute verwenden, wenn es sinnvoll ist. Dies ist insbesondere der Fall, wenn das Attribut sich nie ändern wird.
Wenn Sie numerische eindeutige Primärschlüssel generieren möchten, versuchen Sie, die Bits höherer Ordnung nachfolgender Zahlen ungefähr gleichmäßig über den gesamten Zahlenbereich zu verteilen. Eine Methode besteht darin, sequenzielle Zahlen auf konventionelle Weise zu generieren, um dann mit Bit-Umkehrung einen endgültigen Wert zu erhalten. Alternativ können Sie einen UUID-Generator verwenden, aber seien Sie vorsichtig: Nicht alle UUID-Funktionen werden gleich erstellt und einige speichern den Zeitstempel in den Bits höherer Ordnung, wodurch der Nutzen zunichte gemacht wird. Sorgen Sie dafür, dass Ihr UUID-Generator pseudo-zufällig Bits höherer Ordnung auswählt.
Empfehlungen:
- Verwenden Sie möglichst keine inkrementierenden Sequenzwerte als Primärschlüssel. Sie können stattdessen Bit-Umkehrungen mit einem Sequenzwert oder eine sorgfältig ausgewählte UUID verwenden.
- Verwenden Sie reale Werte für Primärschlüssel anstelle von Ersatzschlüsseln.