Dokumen ini menjelaskan tentang strategi pemulihan dari bencana (DR) untuk Microsoft SQL Server yang ditujukan untuk arsitek dan pimpinan teknis yang bertanggung jawab dalam merancang dan menerapkan pemulihan dari bencana di Google Cloud.
Database kadang tidak tersedia karena berbagai alasan, misalnya, disebabkan oleh kegagalan hardware atau jaringan. Untuk menyediakan akses database secara berkelanjutan selama kegagalan berlangsung, database sekunder yang merupakan replika dari database utama akan tetap dikelola. Menempatkan database sekunder di lokasi yang berbeda dapat meningkatkan peluang tersedianya database tersebut saat database utama tidak tersedia.
Jika database utama tidak tersedia, aplikasi penting akan terhubung ke database sekunder. Database ini melanjutkan status data konsisten yang terakhir diketahui untuk menyediakan layanan tanpa periode nonaktif minimal atau tanpa periode nonaktif.
Proses menyediakan database sekunder setelah terjadi kegagalan database utama disebut pemulihan bencana database (DR). Database sekunder memulihkan ketidaktersediaan database utama. Database sekunder idealnya memiliki status konsisten yang sama persis dengan database utama saat tidak tersedia, atau database sekunder hanya melewatkan serangkaian transaksi minimal terbaru dari database utama.
DR database adalah fitur penting untuk pelanggan perusahaan. Faktor utamanya adalah keberlangsungan bisnis untuk aplikasi penting. Misalnya, aplikasi penting untuk penghasilan pendapatan (e-commerce), layanan yang dapat diandalkan secara berkelanjutan (pengelolaan penerbangan atau pembangkit listrik), atau fungsi yang berkaitan dengan nyawa (pemantauan pasien). Dari contoh ini, bisa dipahami bahwa aplikasi tersebut harus terus tersedia karena dianggap sangat penting.
Sebagian besar sistem pengelolaan database menyediakan fungsi pemulihan dari bencana, termasuk Microsoft SQL Server. Dokumen arsitektur ini membahas cara fitur DR yang disediakan oleh SQL Server diimplementasikan dalam konteks Google Cloud.
Terminologi
Bagian berikut menjelaskan beberapa istilah yang digunakan di seluruh dokumen ini.
Arsitektur DR Umum
Diagram berikut mengilustrasikan topologi dari arsitektur DR umum.
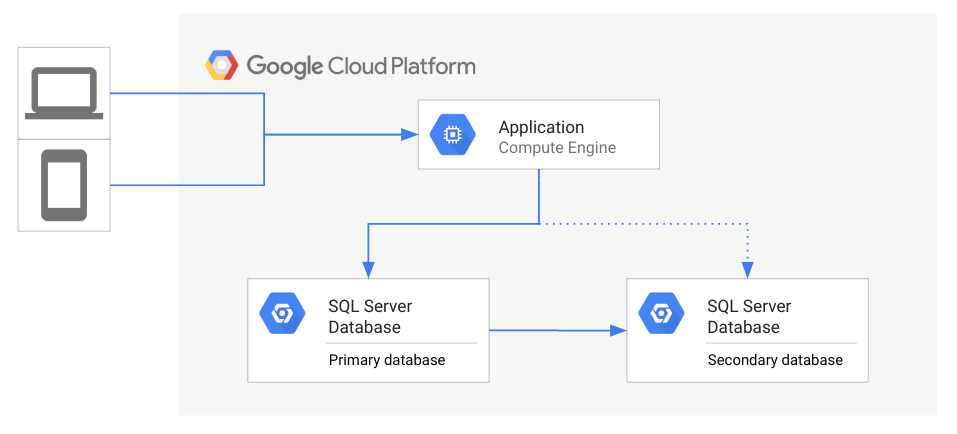
Di diagram sebelumnya, aplikasi mengakses database utama saat database sekunder dalam mode standby dan mencerminkan status database utama. Klien mengakses aplikasi yang berjalan di Google Cloud.
Jika database utama tidak tersedia, admin database atau tim operasi harus memutuskan untuk memulai proses pemulihan dari bencana. Saat pemulihan dari bencana database dimulai, aplikasi akan melakukan sambungan ulang ke database sekunder. Setelah terhubung, aplikasi dapat melayani kebutuhan klien kembali. Di situasi yang ideal, aplikasi dapat terhubung ke database sekunder secepat mungkin, sehingga klien mungkin tidak perlu mengalami pemadaman layanan. Salah satu alternatifnya adalah menunggu database utama dapat diakses kembali, dan tidak memulai pemulihan dari bencana. Misalnya, jika bencana terjadi secara bergantian, mungkin akan lebih cepat untuk menyelesaikan masalahnya, dari pada melakukan failover.
Database primer dan sekunder
Database utama dapat diakses oleh satu atau beberapa aplikasi untuk menyediakan layanan persistensi di dalam pengelolaan status aplikasi. Database sekunder berkaitan dengan database primer dan berisi replika database utama. Idealnya, konten database sekunder sama persis dengan konten database utama pada waktu tertentu. Di banyak kasus, database sekunder tertinggal dari database utama karena penundaan dalam menerapkan perubahan transaksi yang dilakukan pada database utama. Anda dapat mengaitkan lebih dari satu database sekunder dengan database utama, bergantung pada teknologi yang dipakai database. SQL Server mendukung pengaitan lebih dari satu database sekunder dengan database utama.
Pemulihan dari bencana
Jika database utama tidak tersedia, DR akan mengubah peran database sekunder menjadi database utama. Jika ada lebih dari satu database sekunder, salah satu database akan dipilih secara manual atau berdasarkan daftar failover yang diinginkan. Aplikasi harus terhubung kembali ke database utama yang baru agar statusnya dapat terus diakses. Jika database utama yang baru tidak disinkronkan dengan status terakhir yang diketahui dari database primer sebelumnya, aplikasi akan dimulai dari status lama (disebut juga dengan istilah flashback).
Penting untuk memiliki setidaknya satu database sekunder setiap saat untuk setiap database utama. Setelah pemulihan dari bencana, pastikan database sekunder baru disiapkan untuk menangani skenario pemulihan dari bencana di masa mendatang.
Failover, switchover, dan fallback
Ada beberapa skenario untuk mengubah peran antara database primer dan sekunder:
- Failover: proses mengubah peran database sekunder menjadi database utama baru dan menghubungkan semua aplikasi ke database tersebut. Failover terjadi tanpa disengaja karena dipicu oleh database utama yang tidak tersedia. Failover dapat dikonfigurasi untuk dipicu secara otomatis atau manual.
- Switchover: berbeda dengan failover, switchover dari database utama ke database sekunder (database primer baru) sengaja dipicu untuk pengujian awal dan pemeliharaan terjadwal. Uji sistem DR Anda dengan switchover berkala untuk memastikan keandalan berkelanjutan pada pemulihan dari bencana (disaster recovery).
- Fallback: fallback membalikkan proses di mana database utama yang baru menjadi database sekunder, setelah database utama diperbaiki. Fallback sengaja dipicu untuk menetapkan kembali status sebelum failover atau switchover dimulai. Tindakan ini tidak mutlak diperlukan, tetapi dapat dilakukan berdasarkan persyaratan pemulihan dari bencana, seperti lokalitas atau sumber daya yang tersedia.
Google Cloud zona dan region
Resource seperti database terletak di zona dan regionGoogle Cloud , dengan setiap zona merupakan bagian dari satu region. Zona adalah titik tunggal domain kegagalan. Sebaiknya deploy resource yang sangat tersedia dan fault-tolerant di beberapa zona dalam satu region.
Untuk menghindari pemadaman layanan di seluruh region, buat strategi multi-region untuk pemulihan dari bencana (disaster recovery). Misalnya, database utama terletak di satu region dan database sekunder yang sesuai terletak di region lain.
Mode aktif: aktif-pasif dan aktif-aktif
Database utama adalah database yang terbuka untuk operasi baca dan tulis (operasi DML) sehingga aplikasi yang mengakses database dapat mengelola statusnya. Database utama disebut database aktif. Database sekunder yang terkait bersifat pasif karena mereplikasi database utama, tetapi tidak menyediakan operasi perubahan status untuk aplikasi apa pun. Setelah failover atau switchover, database sekunder menjadi database primer baru dan menjadi database aktif.
Database utama dan database sekunder dapat berupa database aktif jika teknologi database mendukung fitur ini, disebut mode aktif-aktif. Di kasus ini, aplikasi dapat terhubung ke salah satunya karena kedua database tersedia untuk pengelolaan status. Pemulihan dari bencana (disaster recovery) dengan mode aktif-aktif tidak memerlukan failover jika hanya salah satu database aktif yang tidak tersedia. Jika satu database aktif tidak tersedia, database aktif lainnya akan tetap tersedia. Mode aktif-aktif dibahas di luar cakupan artikel ini karena SQL Server tidak mendukung mode tersebut.
Mode standby: mode hot, warm, cold, dan no standby
Agar database utama menjadi database aktif, database harus berjalan dan dapat menjalankan pernyataan DML. Database sekunder tidak perlu berjalan; dan dapat dimatikan. Jika database tidak berjalan, waktu yang diperlukan untuk memulihkan dari bencana akan meningkat karena database utama yang baru harus dibawa ke status berjalan terlebih dahulu, sebelum mengasumsikan peran database utama yang baru.
Beberapa variasi cara menyiapkan database sekunder:
- Mode hot standby: database sekunder aktif dan berjalan serta siap dihubungkan oleh klien. Perubahan terbaru yang tersedia dari database utama selalu diterapkan segera setelah terdapat perubahan.
- Mode warm standby: database sekunder aktif dan berjalan, tetapi tidak semua perubahan dari database utama diterapkan.
- Mode cold standby: database sekunder tidak berjalan. Pertama, database sekunder perlu dimulai, lalu disinkronkan ke status terbaru yang tersedia.
- Mode no standby: software database harus diinstal terlebih dahulu dan dimulai sebelum semua perubahan dari database utama diterapkan. Mode ini adalah mode yang paling murah karena tidak menghabiskan resource saat tidak diperlukan, tetapi dibandingkan dengan mode lain, mode ini memerlukan waktu paling lama untuk menjadi database utama yang baru.
Strategi DR
Bagian ini menjelaskan strategi DR yang didukung oleh Microsoft SQL Server.
Dimensi strategi pemulihan
Ada beberapa dimensi utama yang perlu dipertimbangkan ketika memilih atau menerapkan strategi pemulihan dari bencana (disaster recovery) database. Setiap dimensi memiliki spektrum dan perilaku, serta ekspektasi dari strategi pemulihan dari bencana (disaster recovery) bergantung pada pemilihan titik pada spektrum. Dimensi kuncinya adalah sebagai berikut:
- Recovery Point Objective (RPO): Durasi waktu maksimum yang dapat diterima, yang mungkin hilang dari data di aplikasi karena adanya insiden serius. Dimensi ini bervariasi berdasarkan cara penggunaan datanya. RPO dapat dinyatakan dalam durasi (detik, menit, atau jam) dari waktu tidak tersedianya database utama atau dapat dinyatakan sebagai status pemrosesan yang dapat diidentifikasi (pencadangan penuh terakhir atau pencadangan inkremental terakhir). Terlepas dari cara penentuan RPO, strategi pemulihan dari bencana (disaster recovery) harus menerapkan tindakan tertentu sehingga persyaratan RPO dapat terpenuhi. Kasus dengan tuntutan tinggi adalah transaksi yang terakhir di-commit, yang berarti tidak ada kerugian dari database utama ke database sekunder yang harus terjadi.
- Batas Waktu Pemulihan (RTO). Durasi offline maksimum pada aplikasi yang dapat diterima. Nilai ini biasanya ditentukan sebagai bagian dari Perjanjian tingkat layanan yang lebih besar. RTO biasanya dinyatakan dalam durasi dari saat tidak tersedianya database utama, misalnya, aplikasi harus beroperasi sepenuhnya dalam waktu 5 menit. Kasus dengan tuntutan tinggi harus disegerakan agar pengguna aplikasi tidak menyadari bahwa pemulihan dari bencana (disaster recovery) sedang berlangsung.
- Domain titik tunggal kegagalan. Region spesifik dapat ditentukan secara opsional sebagai domain titik tunggal kegagalan untuk persyaratan pemulihan dari bencana (disaster recovery). Jika region sebagai domain titik tunggal kegagalan sudah ditentukan, pemulihan dari bencana (disaster recovery) harus disiapkan agar dua region atau lebih dapat terlibat dalam penyiapan yang sebenarnya. Jika region yang berisi database utama gagal, database sekunder di region yang berbeda menjadi database primer baru. Jika domain titik tunggal kegagalan dianggap sebagai zona, pemulihan dari bencana (disaster recovery) dapat disiapkan di seluruh zona dalam satu region. Jika zona gagal, pemulihan dari bencana (disaster recovery) akan menggunakan zona kedua dan menyediakan database utama baru di dalamnya.
Membuat keputusan dengan pertimbangan biaya dan kualitas merupakan penentuan dimensi kunci. Semakin rendah RTO dan RPO, semakin mahal solusi pemulihan dari bencana (disaster recovery) karena semakin banyak resource aktif yang akan digunakan. Bagian ini menjelaskan beberapa strategi DR alternatif yang mewakili titik-titik pada dimensi dalam konteks database Microsoft SQL Server.
Strategi DR untuk SQL Server
Kelangsungan bisnis dan pemulihan database - SQL Server menjelaskan fitur ketersediaan yang dapat digunakan untuk menerapkan strategi pemulihan dari bencana (disaster recovery).
Persiapan
SQL Server beroperasi di Windows dan Linux. Namun, tidak semua fitur ketersediaan tersedia di Linux. SQL Server memiliki beberapa edisi, tetapi tidak semua fitur ketersediaan tersedia di setiap edisi.
SQL Server membedakan instance dari database. Instance adalah software yang menjalankan SQL Server, sedangkan database adalah kumpulan data yang dikelola oleh instance SQL Server.
Grup ketersediaan Always On
Grup ketersediaan Always On memberikan perlindungan tingkat database. Grup ketersediaan memiliki dua replika atau lebih. Satu replika adalah replika utama dengan akses baca dan tulis, dan replika satunya adalah replika sekunder yang dapat memberikan akses baca. Setiap replika database dikelola oleh instance SQL Server mandiri. Grup ketersediaan dapat berisi satu atau beberapa database. Jumlah database yang dapat disertakan ke dalam grup ketersediaan dan jumlah replika sekunder yang didukung bergantung pada edisi SQL Server. Semua database di dalam grup ketersediaan mengalami perubahan siklus proses yang sama secara bersamaan. Grup ketersediaan menerapkan mode aktif-pasif karena hanya database utama yang mendukung akses tulis.
Saat terjadi failover, replika sekunder akan menjadi replika utama yang baru. Karena grup ketersediaan mencakup instance SQL Server mandiri, semua operasi yang direkam di dalam log transaksi akan tersedia di replika. Setiap perubahan yang tidak terekam di dalam log transaksi perlu disinkronkan secara manual, misalnya, login tingkat instance SQL Server atau tugas Agen SQL Server. Untuk memberikan perlindungan tingkat database dan perlindungan instance SQL Server, Failover Cluster Instance (FCI) perlu dipersiapkan. Arsitektur deployment ini akan dibahas di bagian Failover Cluster Instance Always On.
Aplikasi dapat dilindungi dari perubahan peran dengan menggunakan pemroses. Pemroses mendukung aplikasi yang terhubung ke grup ketersediaan. Aplikasi tidak mengetahui instance SQL Server mana yang mengelola database utama atau replika sekunder di titik waktu tertentu. Pemroses mengharuskan klien menggunakan versi .NET minimum 3.5 dengan update atau 4.0 dan yang lebih tinggi seperti yang diuraikan dalam Kelangsungan bisnis dan pemulihan database - SQL Server.
Grup ketersediaan mengandalkan lapisan abstraksi dasar untuk menyediakan fungsinya. Grup ketersediaan beroperasi di Windows Server Failover Cluster (WSFC) seperti yang diuraikan dalam Windows Server Failover Clustering dengan SQL Server. Semua node yang mengoperasikan instance SQL Server harus menjadi bagian dari WSFC yang sama.
Transaksi akan dikirim dari database utama ke semua replika sekunder. Dua mode pengiriman untuk mengirim transaksi: sinkron dan asinkron. Setiap replika dapat dikonfigurasi secara terpisah untuk menggunakan salah satu mode atau mode lainnya. Di mode pengiriman sinkron, transaksi pada database utama hanya akan berhasil jika transaksi berhasil di semua replika sekunder yang ditautkan secara sinkron. Di mode asinkron, transaksi di database utama dapat berhasil meskipun tidak semua replika sekunder menerapkan transaksinya.
Pilihan mode pengiriman akan mempengaruhi kemungkinan RTO, RPO, dan mode standby. Misalnya, jika transaksi dikirim ke semua replika dengan mode sinkron, semua replika akan berada dalam status yang sama persis. RPO dengan tuntutan tinggi (transaksi terbaru) dapat terpenuhi karena semua replika sepenuhnya disinkronkan. Replika sekunder menggunakan mode hot standby sehingga setiap replika tersebut dapat langsung digunakan sebagai database utama.
Failover dapat bersifat otomatis atau manual. Failover otomatis dapat dilakukan jika semua replikanya disinkronkan. Di contoh sebelumnya, hal ini dapat terjadi karena semua replika selalu disinkronkan sepenuhnya.
Gambar berikut menampilkan grup ketersediaan Always On di satu region.
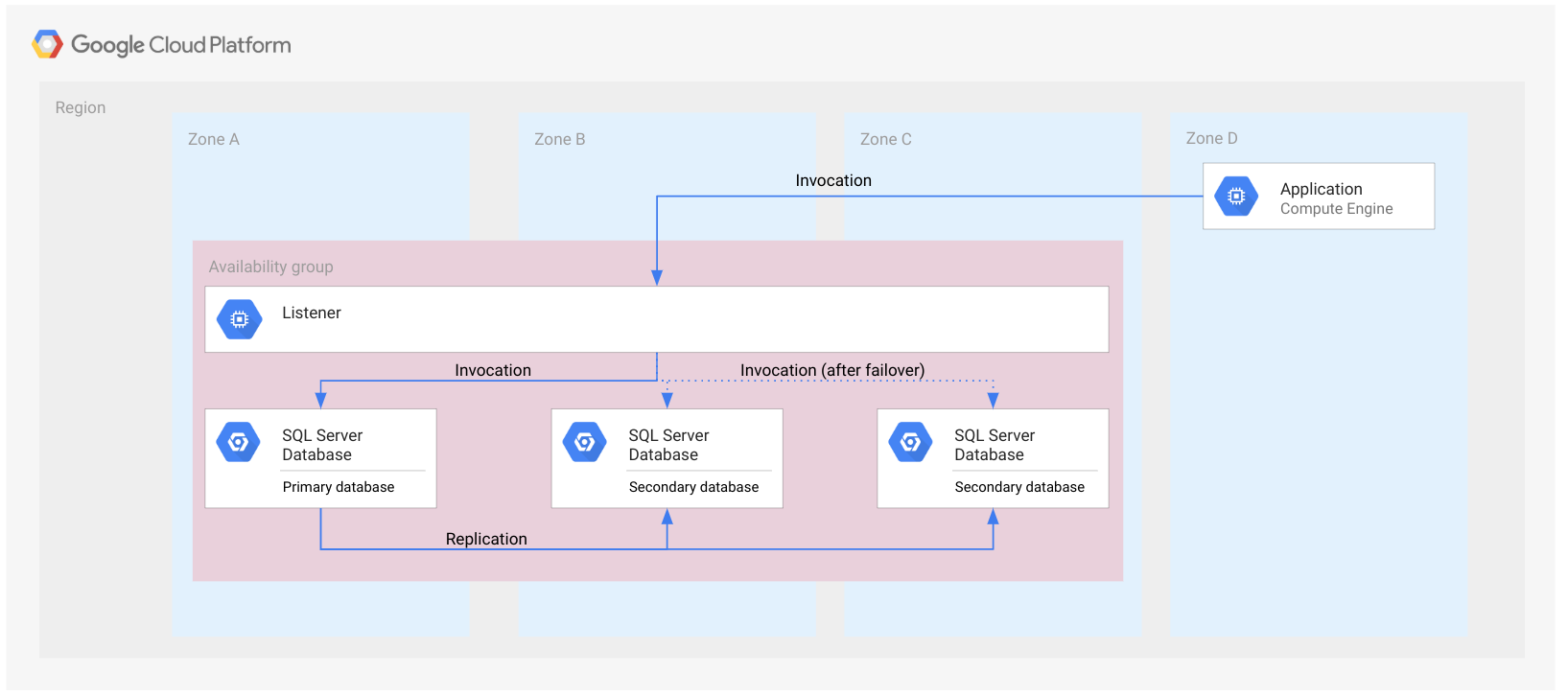
Grup ketersediaan direpresentasikan sebagai zona persegi panjang yang membentang. Ilustrasi ini bertujuan untuk menunjukkan bahwa semua database termasuk ke dalam grup ketersediaan yang sama. Grup ketersediaan bukanlah resource cloud, sehingga tidak dapat diterapkan ke node atau jenis resource lainnya.
Failover Cluster Instance Always On
Untuk menghindari kegagalan node, gunakan Failover Cluster Instance (FCI), bukan instance SQL Server mandiri. Ada dua atau lebih node yang mengoperasikan instance SQL Server untuk mengelola database (utama atau sekunder). Node yang mengelola database membentuk Failover Cluster. Satu node di cluster aktif mengoperasikan instance SQL Server, sementara node yang lain tidak mengoperasikan instance SQL Server. Jika node yang menjalankan instance SQL Server gagal, node lain di cluster akan memulai instance SQL Server, dan mengambil alih pengelolaan database (failover node). Proses memulai instance SQL Server secara otomatis ini menyediakan fungsionalitas ketersediaan yang tinggi.
Cluster FCI muncul sebagai unit tunggal dan klien yang mengakses cluster tidak mengalami failover antar-node, kecuali mungkin untuk periode ketidaktersediaan yang singkat. Data tidak hilang saat terjadi failover node. Semua yang beroperasi di dalam instance SQL Server yang gagal akan dipindahkan ke instance SQL Server lain di cluster yang sama. Misalnya, tugas Agen Server SQL atau server tertaut dipindahkan ke instance lain.
Node cluster FCI dapat disiapkan di berbagai zona Google Cloud . Arsitektur ini tidak hanya menyediakan ketersediaan tinggi untuk kegagalan node, tetapi juga untuk kegagalan zona. Contoh deployment strategi ini dibahas di bagian alternatif deployment DR.
Meskipun node yang berbeda mengelola database yang sama dan berbagi database, penyimpanan umum di antara node cluster FCI tidak diperlukan. SQL Server menggunakan fungsi Storage Spaces Direct (S2D) untuk mengelola database pada disk node khusus. Untuk informasi selengkapnya, lihat Mengonfigurasi Failover Cluster Instance SQL Server.
Contoh bagian sebelumnya Grup ketersediaan Always On dengan FCI, bukan instance SQL Server mandiri, ditampilkan lewat gambar berikut. Setiap FCI memiliki satu instance SQL Server aktif yang mengelola database.
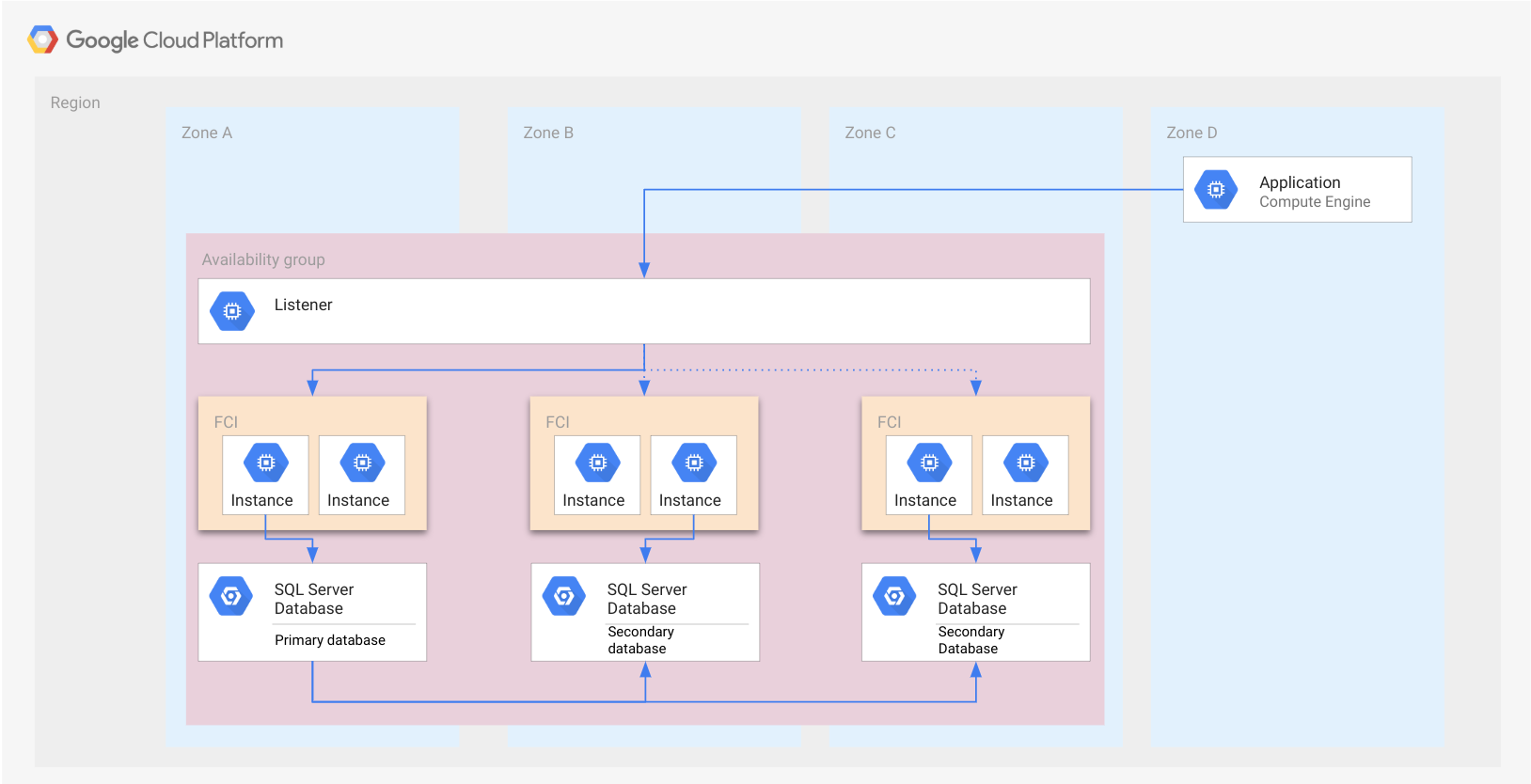
Seperti pada kasus grup ketersediaan, FCI direpresentasikan dengan persegi panjang. Ilustrasi ini hanya bertujuan untuk menunjukkan bahwa semua node termasuk ke dalam FCI yang sama. FCI bukanlah resource cloud, sehingga tidak diimplementasikan di node atau jenis resource lainnya.
Untuk pembahasan lebih detail, lihat Failover Cluster Instance Always On (SQL Server).
Grup ketersediaan terdistribusi
Grup ketersediaan terdistribusi adalah jenis grup ketersediaan yang khusus. Grup ketersediaan terdistribusi mencakup dua grup ketersediaan, satu grup berperan sebagai grup ketersediaan utama dan grup satu lagi berperan sebagai grup ketersediaan sekunder. Grup ketersediaan terdistribusi dapat meneruskan transaksi dalam mode sinkron maupun asinkron dari grup ketersediaan utama ke grup ketersediaan sekunder.
Meskipun setiap grup ketersediaan memiliki database utama sendiri, grup ini bukan deployment aktif-aktif. Hanya database utama grup ketersediaan utama yang dapat menerima operasi tulis. Database utama dari grup ketersediaan sekunder disebut forwarder. Forwarder menerima transaksi dari grup ketersediaan utama dan meneruskannya ke database sekunder dari grup ketersediaan sekunder. Failover dari grup ketersediaan utama ke grup ketersediaan sekunder akan membuat database utama grup ketersediaan utama yang baru dapat diakses untuk operasi tulis.
Grup ketersediaan utama dan sekunder tidak harus berada di lokasi yang sama dan tidak harus berada di sistem operasi yang sama. Namun, setiap grup ketersediaan harus memiliki pemroses yang terinstal. Grup ketersediaan terdistribusi sebenarnya tidak memiliki pemroses. Grup ketersediaan terdistribusi tidak mengharuskan kedua grup ketersediaan berada di WSFC yang sama. Semua fungsi yang diperlukan untuk membuat grup ketersediaan terdistribusi bekerja tercakup di dalam fungsi SQL Server dan tidak memerlukan penginstalan komponen tambahan yang mendasarinya.
Grup ketersediaan terdistribusi mencakup dua grup ketersediaan. Grup ketersediaan dapat menjadi bagian dari dua grup ketersediaan terdistribusi. Kemungkinan ini mendukung topologi yang berbeda. Salah satunya adalah topologi daisy-chain dari grup ketersediaan hingga grup ketersediaan di beberapa lokasi. Topologi lainnya adalah topologi seperti pohon, dengan grup ketersediaan utama adalah bagian dari dua grup ketersediaan terdistribusi yang berbeda dan terpisah.
Grup ketersediaan terdistribusi adalah alat utama untuk menerapkan pemulihan dari bencana (disaster recovery) di seluruh sistem operasi. Misalnya, grup ketersediaan utama dapat disetel di Windows, dan grup ketersediaan kedua yang sesuai di Linux, dengan kedua grup ketersediaan membentuk grup ketersediaan terdistribusi.
Diagram berikut menunjukkan dua grup ketersediaan yang merupakan bagian dari grup ketersediaan terdistribusi.
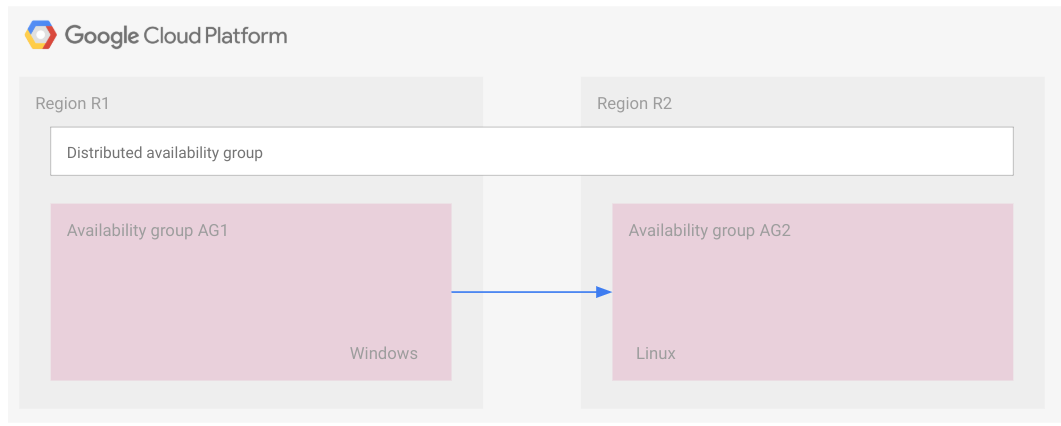
Grup ketersediaan 1 adalah grup ketersediaan utama dan grup ketersediaan 2 adalah grup ketersediaan sekunder.
Seperti dalam kasus FCI, grup ketersediaan terdistribusi direpresentasikan dengan persegi panjang. Ilustrasi ini hanya bertujuan untuk menunjukkan bahwa semua grup ketersediaan termasuk dalam grup ketersediaan terdistribusi yang sama. Grup ketersediaan terdistribusi, seperti grup ketersediaan, bukan resource cloud sehingga tidak diterapkan pada node atau jenis resource lainnya.
Untuk informasi selengkapnya, lihat Grup ketersediaan terdistribusi.
Pengiriman log
Pengiriman log transaksi adalah fitur ketersediaan SQL Server jika RTO dan RPO tidak ketat (RTO rendah dan/atau RPO terbaru) karena perbedaan status antara database primer dan database sekundernya secara signifikan lebih besar. Perbedaannya lebih besar dalam hal status karena file log transaksi berisi banyak perubahan status. Perbedaannya juga lebih besar dari segi waktu keterlambatan karena file log transaksi dipindahkan secara asinkron dan harus diterapkan secara keseluruhan ke database sekunder.
File log transaksi dibuat oleh database utama dan dicadangkan, misalnya, ke Cloud Storage. Setiap file log transaksi disalin ke setiap database sekunder dan diterapkan ke database tersebut. Karena database sekunder tertinggal dari database utama, database tersebut berada dalam mode warm standby. Objek dan perubahan yang tidak terekam oleh log transaksi harus diterapkan secara manual ke database sekunder untuk melakukan sinkronisasi penuh tanpa kehilangan.
Agen SQL Server mengotomatiskan keseluruhan proses pembuatan, penyalinan, dan penerapan log transaksi. Pengiriman log harus disiapkan untuk setiap masing-masing database. Jika grup ketersediaan mengelola lebih dari satu database, sejumlah proses pengiriman log harus disiapkan.
Jika terjadi kegagalan, proses pemulihan dari bencana (disaster recovery) harus dimulai secara manual karena tidak ada dukungan otomatis. Selain itu, akses klien tidak dipisahkan dari database primer dan database sekunder oleh pemroses. Jika terjadi failover, klien harus dapat menangani perubahan peran database dari peran sekunder menjadi peran utama yang baru dengan cara menghubungkan ke peran utama yang baru setelah pemulihan dari bencana (disaster recovery). Abstraksi dapat dibuat secara terpisah dari instance SQL Server, misalnya alamat IP floating seperti yang dijelaskan dalam Praktik terbaik untuk alamat IP floating.
Karena pengiriman log adalah bagian dari proses manual, penerapan file log yang disalin ke database sekunder dengan sengaja (berbeda dengan grup ketersediaan dan grup ketersediaan terdistribusi yang perubahannya langsung diterapkan) dapat ditunda. Kasus penggunaan yang mungkin terjadi mencegah error modifikasi data pada database utama untuk diterapkan ke database sekunder sampai error modifikasi data ditangani. Dalam hal ini, database sekunder yang belum menerapkan error modifikasi data dapat menjadi database utama hingga error modifikasi data selesai ditangani. Setelah itu, pemrosesan normal dapat dilanjutkan kembali.
Seperti halnya grup ketersediaan terdistribusi, pengiriman log dapat digunakan untuk solusi lintas platform ketika database utama beroperasi di Linux, sedangkan database sekunder ada di Linux dan Windows.
Diagram berikut mengilustrasikan deployment lintas platform dengan pengiriman log. Perlu diperhatikan bahwa tidak ada konfigurasi umum di seluruh region seperti grup ketersediaan terdistribusi di dalam topologi ini.
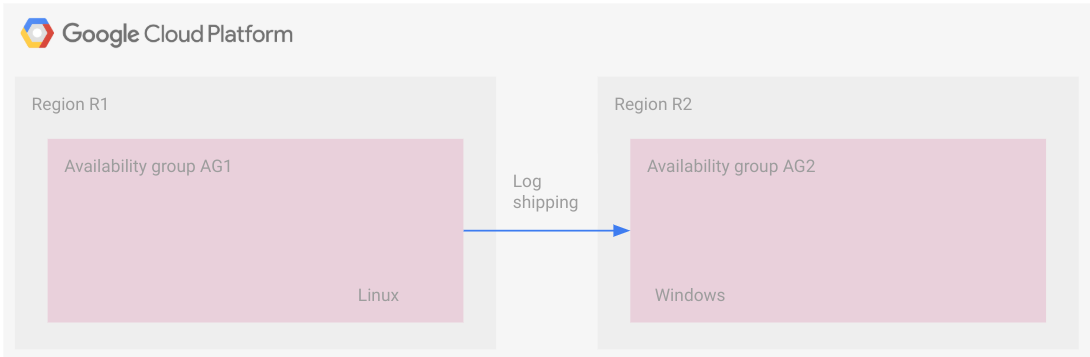
Grup ketersediaan berada di wilayah terpisah, di mana satu grup beroperasi di Linux dan grup satu lagi beroperasi di Windows.
Untuk informasi selengkapnya tentang pengiriman log SQL Server, baca Tentang Pengiriman Log (SQL Server).
Menggabungkan fitur ketersediaan SQL Server
Anda dapat men-deploy fitur ketersediaan SQL Server dengan berbagai kombinasi. Misalnya, di kasus penggunaan sebelumnya, pengiriman log digunakan dengan grup ketersediaan berbeda yang diinstal pada sistem operasi yang berbeda.
Berikut adalah daftar kemungkinan kombinasi fitur ketersediaan server SQL:
- Gunakan pengiriman log antara grup ketersediaan yang diinstal pada sistem operasi yang sama.
- Buat grup ketersediaan utama yang menggunakan FCI dengan grup ketersediaan sekunder yang hanya menggunakan instance mandiri SQL Server.
- Gunakan grup ketersediaan terdistribusi antara wilayah terdekat, dan pengiriman log ke berbagai region yang berlokasi di benua berbeda.
Hanya terdapat beberapa kemungkinan kombinasi fitur ketersediaan SQL Server.
Fleksibilitas yang diberikan fitur ketersediaan SQL Server mendukung penyesuaian strategi pemulihan dari bencana (disaster recovery) sesuai dengan persyaratan yang dinyatakan.
Replikasi SQL Server
Replikasi SQL Server umumnya tidak dianggap sebagai fitur ketersediaan, tetapi bagian ini menjelaskan secara singkat mengenai kegunaan fitur ini untuk pemulihan dari bencana (disaster recovery).
Fitur replikasi mendukung pembuatan dan pemeliharaan replika database. Berbagai jenis agen SQL Server berkolaborasi untuk merekam perubahan, mengirimkan perubahan yang direkam, dan menerapkan perubahan tersebut ke replika. Proses ini bersifat asinkron dan replika biasanya tertinggal dari replikasi database hingga beberapa derajat.
Misalnya, Anda dapat memiliki replika database produksi. Dalam hal pemulihan dari bencana (disaster recovery), database produksi adalah database utama dan replikanya adalah database sekunder. Fitur replikasi SQL Server tidak mengetahui bahwa database memiliki peran yang berbeda dalam konteks pemulihan dari bencana (disaster recovery). Oleh sebab itu, replikasi tidak memiliki operasi yang mendukung proses pemulihan dari bencana (disaster recovery), misalnya, perubahan peran. Proses pemulihan dari bencana (disaster recovery) harus diterapkan secara terpisah dari fungsi SQL Server dan dijalankan oleh organisasi yang mengimplementasikan karena tidak ada penggabungan akses klien.
Pengiriman file cadangan
Pengiriman file cadangan adalah strategi lain dalam penerapan pemulihan dari bencana (disaster recovery). Pendekatan standar untuk menyiapkan dan memperbarui database sekunder secara berkelanjutan adalah mengambil pencadangan penuh awal dari database utama dan pencadangan inkremental setelahnya. Semua pencadangan inkremental diterapkan ke database sekunder dengan urutan yang benar. Ada banyak variasi untuk pendekatan ini, bergantung pada frekuensi pencadangan inkremental dan lokasi penyimpanan file pencadangan (lokasi global atau disalin antarlokasi).
Strategi ini tidak melibatkan fitur ketersediaan SQL Server apa pun saat mereplikasi perubahan status dari database utama ke database sekunder. Strategi ini tidak menggunakan Agen SQL Server yang digunakan di dalam kasus pengiriman log.
Untuk informasi selengkapnya, lihat bagian tentang Contoh: strategi DR pencadangan dan pemulihan.
Dibandingkan dengan pendekatan replikasi yang dibahas di bagian sebelumnya, pengiriman file replikasi dan cadangan memiliki kesamaan, yaitu proses pemulihan dari bencana (disaster recovery) diimplementasikan di luar dan terpisah dari set fitur SQL Server. Dari perspektif pengiriman perubahan yang terekam, replikasi SQL Server lebih mudah karena dilakukan secara otomatis melalui Agen SQL Server.
Catatan tentang interaksi antara siklus proses database dan siklus proses aplikasi
Failover database tidak sepenuhnya terpisah dan independen dari aplikasi yang mengakses database. Pada prinsipnya, ada dua skenario kegagalan.
Pertama, aplikasi akan tetap beroperasi saat database mengalami kegagalan. Mulai dari tidak tersedianya database utama hingga database utama yang baru beroperasi, aplikasi tersebut tidak dapat mengakses database sama sekali. Koneksi yang ada akan gagal dan tidak ada koneksi baru yang akan dibuat. Selama ini berlangsung, aplikasi tidak dapat melayani kliennya, setidaknya sejauh fungsi tersebut memerlukan akses database. Aplikasi perlu mengetahui kapan database utama yang baru tersedia sehingga aplikasi dapat melanjutkan pemrosesan normal.
Aplikasi mungkin memiliki status di luar database, misalnya, dalam cache memori utama. Aplikasi memastikan cache tetap konsisten (disinkronkan) dengan database utama yang baru. Jika tidak terjadi kehilangan transaksi sama sekali selama failover, cache mungkin konsisten tanpa pemeliharaan lebih lanjut. Namun, jika hilangnya transaksi (data) terjadi selama failover, cache mungkin tidak konsisten dalam kaitannya dengan database utama yang baru. Diskusi analog akan berlaku untuk status bersama, jika misalnya, beberapa data dalam database juga merupakan bagian dari pesan dalam antrean, atau file dalam sistem file. Aspek konsistensi data ini dibahas di luar cakupan dokumen ini karena tidak terkait langsung dengan pemulihan dari bencana (disaster recovery) database.
Kedua, satu atau beberapa aplikasi mungkin tidak tersedia pada saat yang sama ketika database utama tidak tersedia. Misalnya, jika suatu region menjadi offline, sistem aplikasi yang dieksekusi di region tersebut tidak akan tersedia lagi seperti database utama di region yang sama. Dalam hal ini, aplikasi juga harus dipulihkan, bukan hanya sistem database utama. Bersama dengan proses pemulihan dari bencana (disaster recovery) database, Anda perlu memulai proses pemulihan aplikasi yang serupa. Aplikasi yang dipulihkan harus terhubung ke database utama baru dan dikonfigurasi ulang (misalnya, alamat IP floating). Pemulihan aplikasi tidak termasuk ke dalam cakupan dokumen ini.
Hubungan antara pencadangan dan pemulihan dengan pemulihan dari bencana (disaster recovery)
Mencadangkan database bersifat independen dan ortogonal terhadap pemulihan dari bencana (disaster recovery) database. Tujuan pencadangan database adalah untuk dapat memulihkan status yang konsisten, misalnya, jika database hilang atau rusak, atau status sebelumnya harus dipulihkan karena kegagalan aplikasi atau adanya bug.
Bagian ini membahas cara menggunakan pencadangan sebagai salah satu mekanisme untuk menerapkan pemulihan dari bencana (disaster recovery) database. Di skenario ini, salin file cadangan ke lokasi database sekunder sehingga database sekunder dapat dipulihkan. Namun, file cadangan bukan merupakan prasyarat untuk pemulihan dari bencana (disaster recovery); diskusi sebelumnya tentang fitur ketersediaan menampilkan beberapa alternatif.
Ketersediaan tinggi dan pemulihan dari bencana (disaster recovery)
Ketersediaan tinggi dan pemulihan dari bencana (disaster recovery) sama-sama memberikan solusi untuk ketidaktersediaan database. Jika database utama tidak tersedia, database sekunder akan menjadi database utama baru yang konsisten dan tersedia.
Perbedaan antara ketersediaan tinggi dan pemulihan dari bencana (disaster recovery) terletak pada titik tunggal domain kegagalan. Ketersediaan tinggi mengatasi pemadaman layanan dalam suatu region, misalnya, saat satu zona gagal atau satu node gagal. Solusi ketersediaan tinggi menyediakan database utama baru di zona lain di region yang sama. Selain itu, ketersediaan tinggi mengatasi kegagalan node, bukan hanya kegagalan database. Jika node yang menjalankan instance SQL Server gagal, node baru akan tersedia dan mengoperasikan instance SQL Server baru (lihat diskusi di bagian Failover Cluster Instance Always On).
Pemulihan dari bencana (disaster recovery) melibatkan setidaknya dua region. Pemulihan ini menangani kasus ketika seluruh region menjadi tidak tersedia. Pemulihan dari bencana (disaster recovery) dapat menyediakan database utama baru di region yang berbeda.
Fitur ketersediaan tinggi SQL Server mendukung solusi untuk ketersediaan tinggi dan pemulihan dari bencana (disaster recovery) secara bersamaan. Satu grup ketersediaan dapat mencakup zona dalam satu region serta region itu sendiri. Grup ketersediaan dapat berisi Failover Cluster Instance untuk menangani ketersediaan tinggi.
SQL Server dapat membuat grup ketersediaan dalam satu region untuk kegagalan zona dan ketersediaan tinggi, serta menggabungkannya dengan pengiriman log di seluruh region untuk mengatasi pemulihan dari bencana (disaster recovery).
Alternatif deployment DR
Bagian berikut menampilkan beberapa kemungkinan topologi pemulihan dari bencana (disaster recovery) selain yang sudah dibahas sejauh ini. Topologi ini memenuhi persyaratan RPO dan RTO yang berbeda. Daftar ini tidak lengkap.
DR dan HA antarregion
Deployment ini adalah variasi dari grup ketersediaan yang berisi FCI, di dalam region yang terdiri dari tiga zona. Di skenario ini, zona dianggap sebagai domain titik tunggal kegagalan.
Dibandingkan dengan deployment yang ditunjukkan sebelumnya, setiap FCI terdiri dari tiga node, dengan setiap node berjalan di zona yang berbeda. Manfaat dari penyiapan ini adalah bahwa satu atau dua zona dapat gagal tanpa memerlukan proses pemulihan dari bencana (disaster recovery).
Diagram berikut menunjukkan penyiapan ini.
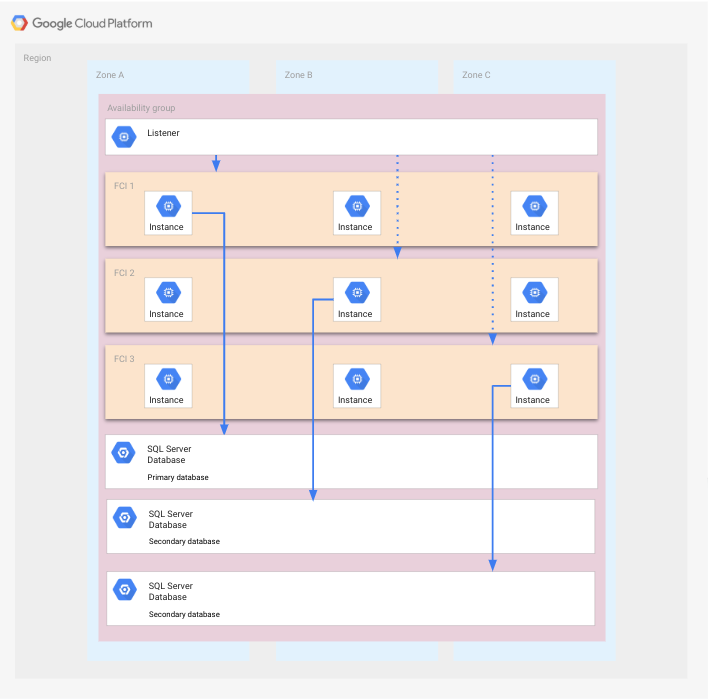
FCI mencakup semua zona, dan setiap FCI memiliki satu instance SQL Server yang beroperasi dan mengakses database terkait. Ada dua instance SQL Server tambahan yang tidak beroperasi di setiap FCI yang dapat dimulai saat zona mengalami kegagalan. Database ditampilkan di seluruh zona karena setiap database menggunakan disk dari semua node dalam FCI tertentu. Aplikasi tidak ditampilkan untuk alasan kejelasan.
DR antarregion: grup ketersediaan yang mencakup beberapa wilayah
Di skenario ini, grup ketersediaan berjalan di Windows Server Failover Cluster dan mencakup dua region. Region dianggap sebagai domain titik tunggal kegagalan.
Diagram berikut mengilustrasikan penyiapan ini.

Untuk mengatasi potensi masalah latensi, Anda dapat mengonfigurasi replika di region R1 untuk menggunakan propagasi transaksi sinkron, sedangkan replika di region R2 dikonfigurasi untuk menggunakan propagasi transaksi asinkron.
DR antarregion: transfer file cadangan
Skenario ini menggunakan transfer file cadangan. Dua grup ketersediaan di dua region ditautkan. Setiap grup ketersediaan memiliki replika yang menerima transaksi secara sinkron sehingga replika sekunder setiap region berada dalam konfigurasi mode hot standby.
Diagram berikut mengilustrasikan penyiapan ini.
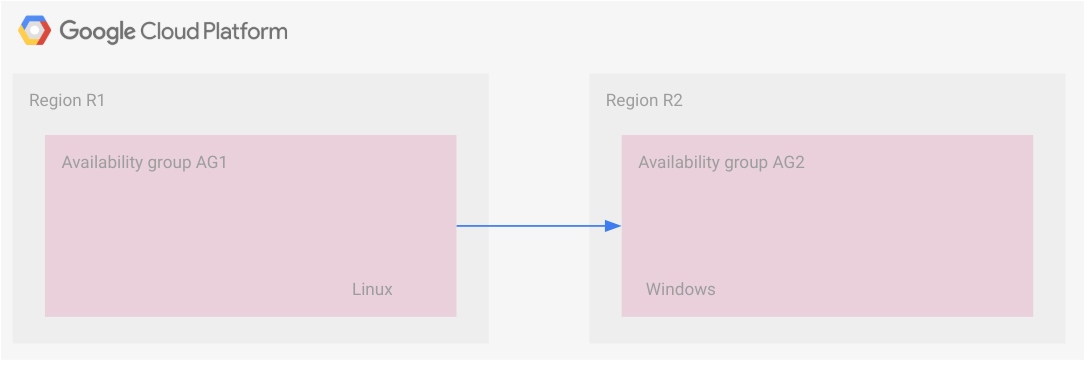
Namun, kedua grup ketersediaan tersebut terhubung melalui transfer file cadangan. Grup ketersediaan AG1 adalah grup ketersediaan utama dan grup ketersediaan AG2 adalah grup ketersediaan sekunder. Saat file cadangan tersedia untuk grup ketersediaan sekunder, file tersebut akan diterapkan di sana. Skenario ini dibahas dengan lebih detail di bagian berikut, Contoh: strategi DR pencadangan dan pemulihan.
Topologi lokasi ganda dan lokasi tersier
Jika hanya ada dua database, yaitu database utama dan database sekunder masing-masing di region terpisah, akan ada durasi yang tidak dilindungi setelah failover, yaitu sejak database primer baru beroperasi sampai dengan database sekunder baru sudah siap. Jika database primer baru tidak tersedia saat database sekunder belum beroperasi, periode nonaktif yang berat akan terjadi dan hanya dapat dipulihkan dari saat database primer baru dibuat. Hal yang sama berlaku untuk grup ketersediaan.
Lokasi ketiga yang mengoperasikan database sekunder atau grup ketersediaan lainnya dapat menghilangkan durasi tidak dilindungi setelah failover. Penyiapan ini perlu memastikan bahwa salah satu dari dua database sekunder tetap merupakan database sekunder dan ditetapkan ulang ke database primer baru agar tidak ada data yang hilang. Seperti sebelumnya, hal yang sama berlaku untuk grup ketersediaan.
Siklus proses DR
Terlepas dari solusi pemulihan dari bencana yang dipilih, terdapat langkah-langkah siklus proses umum yang berlaku.
Di situasi pemulihan dari bencana (disaster recovery) yang sebenarnya, semua pemangku kepentingan (pemilik aplikasi, grup operasi, dan admin database) harus hadir dan berpartisipasi aktif dalam mengelola pemulihan dari bencana (disaster recovery). Para pemangku kepentingan harus memutuskan otoritas keputusan (terkadang disebut master of ceremony) dan proses keputusan yang dipilih. Terlebih lagi, para pemangku kepentingan harus menyetujui terminologi dan metode komunikasinya.
Menentukan untuk memulai proses failover
Pemangku kepentingan harus membuat keputusan untuk memulai failover, kecuali jika failover dimulai secara otomatis Berbagai pemangku kepentingan perlu berkoordinasi secara kompak tentang keputusan waktu untuk memulai failover.
Memulai proses failover bergantung pada beberapa faktor, terutama pada akar masalah database utama yang menjadi tidak tersedia.
Jika proses pemulihan dari bencana (disaster recovery) memerlukan waktu lebih lama dari waktu yang diperkirakan untuk mengatasi ketidaktersediaan database utama, failover akan memperburuk masalah. Pertama, Anda harus mempertimbangkan apakah pemulihan database utama adalah opsi yang memungkinkan.
Semakin baik strategi pemulihan dari bencana yang diuji, dan semakin cepat diimplementasikan, semakin mudah untuk memulai proses failover karena lebih sedikit ketidakpastian akan dipertimbangkan dalam keputusan tersebut.
Eksekusi proses failover
Proses failover idealnya diuji secara rutin, sehingga dapat diketahui oleh berbagai pemangku kepentingan.
Otoritas keputusan harus mengetahui semua langkah yang sedang dijalankan dan semua masalah tak terduga yang mungkin akan terjadi. Otoritas keputusan mendorong proses failover dan pemangku kepentingan bertanggung jawab untuk mendukung otoritas keputusan.
Anda harus menyimpan statistik untuk analisis postmortem dan peningkatan proses failover; termasuk durasi aktivitas, masalah yang muncul, dan kebingungan mengenai langkah-langkah proses failover.
Perlindungan tidak ada
Jika Anda hanya memiliki satu database sekunder, dimulai sejak database primer baru tersedia dan beroperasi hingga database sekunder baru disiapkan, tidak ada perlindungan DR tersedia. Ketidaktersediaan selama waktu ini dapat menyebabkan periode nonaktif yang berat karena tidak ada failover ke database lain yang dapat dimungkinkan. Jika situasi tersebut terjadi, database utama yang lain harus disiapkan dan RPA adalah titik terakhir yang dapat direkonstruksi berdasarkan cadangan yang tersedia.
Kecuali jika strategi pemulihan dari bencana (disaster recovery) disiapkan sehingga selalu ada perlindungan, setiap pemangku kepentingan harus mengetahui durasi hilangnya perlindungan ini untuk melakukan tindakan pencegahan tambahan selama penyiapan atau perubahan konfigurasi lingkungan.
Anda dapat menghindari waktu yang tidak dilindungi ini jika akses aplikasi ke database primer baru tertunda hingga database sekunder baru aktif dan beroperasi. Segera setelah perubahan dari database utama diterapkan, database utama akan tersedia untuk aplikasi. Meskipun pendekatan ini menghindari setiap aplikasi yang tidak dilindungi dari DR, pendekatan ini menunda penyelesaian proses pemulihan dari bencana (disaster recovery).
Hindari situasi split brain
Penting bagi aplikasi untuk tidak dapat mengakses database utama dan database sekunder secara bersamaan, yang mengeluarkan operasi DML. Di situasi ini, inkonsistensi data akan terjadi saat database utama dan database sekunder tidak setuju terhadap nilai data pada item data yang sama (Split brain). Arsitektur ini sangat penting jika database utama tidak tersedia saat sedang beroperasi dan dapat menerima operasi tulis. Jika ketidaktersediaan disebabkan oleh partisi jaringan yang terputus-putus, partisi tersebut dapat berhenti kapan saja, dan aplikasi mungkin dapat memiliki akses lagi. Jika proses failover terjadi pada saat itu, perubahan pada database utama yang lama mungkin akan hilang, atau beberapa aplikasi mulai beroperasi di database utama yang baru, sementara aplikasi yang lain masih mengakses database primer lama.
Semua akses aplikasi dinonaktifkan ke database mana pun selama proses failover sehingga tidak ada perubahan status yang dapat terjadi di database mana pun. Setelah failover, hanya satu database yang tersedia untuk operasi tulis, yaitu database utama yang baru.
Pernyataan penyelesaian
Setelah proses failover selesai, semua pemangku kepentingan harus diberi tahu secara eksplisit oleh otoritas keputusan bahwa proses tersebut selesai dilakukan. Setiap masalah yang muncul setelah proses selesai harus diperlakukan sebagai insiden terpisah yang bukan lagi bagian dari proses failover tetapi bagian dari pemrosesan reguler. Masalah ini mungkin merupakan konsekuensi dari masalah pada proses failover, atau masalah independen. Namun, pendekatan untuk mengatasi masalah setelah proses failover selesai mungkin berbeda dari cara penanganan selama proses failover dijalankan.
Analisis dan laporan post-mortem
Sebagai referensi di masa mendatang dan untuk meningkatkan proses failover, segera lakukan analisis post-mortem untuk mencatat aspek, temuan, dan item tindakan yang penting.
Tulis laporan yang merangkum peristiwa pemulihan dari bencana (disaster recovery), penyebab utama, dan semua tindakan yang diambil. Laporan ini mungkin bersifat wajib jika Anda menerapkan persyaratan peraturan.
Pengujian dan verifikasi DR
Karena pemulihan dari bencana (disaster recovery) bukan bagian dari operasi sehari-hari yang normal, solusi DR harus diuji secara teratur untuk memastikan DR berfungsi dengan baik saat benar-benar diperlukan.
Frekuensi pengujian bergantung pada persyaratan operasional dan bervariasi menurut database, aplikasi, dan perusahaan. Selain itu, perubahan lingkungan, seperti perubahan konfigurasi jaringan dan update komponen infrastruktur harus memicu pengujian pemulihan dari bencana (disaster recovery) jika perubahan dilakukan pada sistem yang diandalkan oleh solusi pemulihan dari bencana (disaster recovery) yang dipilih. Setiap perubahan dapat menyebabkan solusi pemulihan dari bencana (disaster recovery) gagal, atau mungkin memerlukan penyesuaian proses pemulihan dari bencana (disaster recovery).
Anda dapat mengujinya secara manual dengan memulai proses pengalihan, atau secara otomatis dengan mengikuti pendekatan rekayasa kekacauan seperti yang dijelaskan dalam Rekayasa kekacauan. Dengan pengujian manual, Anda dapat meminimalkan dampak bisnis jika periode nonaktif yang signifikan terjadi.
Aspek penting untuk pengujian adalah mengumpulkan statistik yang terdefinisi dengan baik. Beberapa statistik penting yang perlu dipertimbangkan adalah sebagai berikut:
- Waktu pemulihan aktual: mengukur waktu pemulihan aktual dan membandingkannya dengan RTO.
- Titik pemulihan aktual: mengamati titik pemulihan aktual dan membandingkannya dengan RPO.
- Waktu untuk mendeteksi kegagalan: waktu yang diperlukan DBA atau tim operasi untuk menyadari perlunya failover.
- Waktu untuk inisiasi pemulihan: waktu yang diperlukan untuk memulai proses failover setelah kegagalan terdeteksi.
- Keandalan: seberapa dekat proses failover dijalankan atau apakah nilai deviasi diperlukan? Apakah muncul masalah tak terduga yang perlu diselidiki, dan mungkin mengakibatkan perubahan strategi pemulihan?
Berdasarkan statistik yang dikumpulkan, proses failover mungkin harus disesuaikan atau ditingkatkan agar lebih cocok dengan ekspektasi RPO dan RTO.
Contoh: strategi DR pencadangan dan pemulihan
Bagian ini menguraikan contoh strategi pemulihan dari bencana (disaster recovery) pencadangan dan pemulihan. Skenario ini meminimalkan penggunaan fitur ketersediaan SQL Server untuk menunjukkan upaya yang diperlukan dalam menentukan strategi pencadangan dan pemulihan DR serta membahas aspek yang tidak terlihat dalam penyiapan yang lebih otomatis.
Kasus penggunaan
Grup ketersediaan Always-On utama terletak dan beroperasi di region R1. Grup ketersediaan Always-On sekunder ditambahkan di region R2 untuk perlindungan lintas regional tambahan dan tersedia sebagai target failover atau peralihan.
Strategi
Strategi pemulihan dari bencana (disaster recovery) didasarkan pada pencadangan database. Pencadangan penuh awal diambil dan dilanjutkan dengan pencadangan diferensial berikutnya. Cadangan diterapkan ke grup ketersediaan Always On sekunder saat diambil. Semua cadangan disimpan di bucket Cloud Storage.
Di contoh ini, setelah penyelesaian failover, wajar jika grup ketersediaan Always-On utama yang baru di R2 aktif dan tidak dilindungi untuk waktu yang terbatas hingga grup ketersediaan Always-On sekunder yang baru di R1 bersifat operasional.
Tidak ada penggantian yang harus dilakukan karena grup ketersediaan Always-On di setiap region memenuhi syarat untuk berfungsi sebagai grup ketersediaan Always On produksi.
RTO dan RPO
Di contoh ini, RPO ditentukan dengan batas maksimum 60 menit, sehingga cadangan diferensial akan diambil setiap 60 menit.
RTO tidak disetel secara eksplisit ke durasi waktu, tetapi harus seminimal mungkin— kasus terbaiknya adalah secepat mungkin. Grup ketersediaan sekunder harus disiapkan sebagai mode hot standby. Di kasus mode hot standby, semua pencadangan segera diterapkan sehingga failover tidak tertunda dalam menerapkan pencadangan.
Strategi DR tingkat tinggi
Bagian berikut menguraikan tentang strategi DR. Penjelasan ini difokuskan pada langkah-langkah yang penting.
Penyiapan awal
- Buat grup ketersediaan Always-On sekunder di region R2.
- Cegah akses aplikasi ke grup ketersediaan sekunder sehingga tidak ada situasi split brain yang dapat terjadi secara tidak sengaja.
- Buat bucket file cadangan B1 di Cloud Storage untuk menampung cadangan penuh awal dari grup ketersediaan Always On di R1 dan pencadangan diferensial per jam berikutnya dari grup ketersediaan Always On di R1. Urutan cadangan diferensial yang benar harus ditetapkan agar proses yang menerapkan cadangan ke grup ketersediaan sekunder dapat menyimpulkan urutan yang benar. Salah satu pendekatannya mungkin adalah konvensi penamaan yang memungkinkan pembuatan urutan kronologis yang benar berdasarkan tanggal dan waktu yang menjadi bagian dari berbagai nama file.
Strategi peluncuran
- Terapkan cadangan penuh ke grup ketersediaan Always On sekunder di region R2.
- Saat cadangan diferensial tersedia, segera terapkan ke grup ketersediaan Always On sekunder di R2. Penerapan langsung diperlukan untuk menangani RTO.
- Setelah pencadangan penuh awal dan semua pencadangan inkremental diterapkan, grup ketersediaan Always On sekunder sudah siap.
- Uji strategi DR dengan melakukan switchover dari grup ketersediaan utama ke grup ketersediaan sekunder. Setidaknya satu cadangan inkremental harus tersedia selama pengujian.
Kasus failover atau switchover
Di R2, langkah-langkah pentingnya adalah sebagai berikut:
- Pastikan cadangan diferensial terbaru diterapkan ke grup ketersediaan Always On sekunder di R2.
- Tetapkan R2 sebagai grup ketersediaan Always On utama yang baru.
- Buat bucket B2 baru, ambil pencadangan penuh sebagai dasar pengukuran, dan buka grup ketersediaan utama yang baru untuk akses aplikasi.
- Mulai lakukan pencadangan diferensial.
Di R1, langkah-langkah pentingnya adalah sebagai berikut:
- Hapus bucket B1 karena tidak diperlukan lagi.
- Saat grup ketersediaan Always On di R1 kembali tersedia (sebagai grup ketersediaan Always On sekunder baru), cegah akses aplikasi, dan hapus semua data dari database atau reset data ke status awal (kosong) (kecuali jika harus dibuat baru).
- Terapkan cadangan penuh dari grup ketersediaan Always On utama yang baru di R2, dan terus terapkan pencadangan diferensial segera setelah pencadangan tersedia (disimpan di bucket B2).
Kemungkinan peningkatan
Salah satu kemungkinan peningkatan pada strategi DR adalah menghindari pencadangan penuh setelah failover atau switchover, sambil tetap dapat menyiapkan grup ketersediaan sekunder baru dengan cepat. Daripada membuat cadangan penuh dan cadangan diferensial berikutnya, cadangkan sepenuhnya setiap minggu dan buat bucket mingguan yang berisi cadangan penuh untuk minggu tersebut dan semua cadangan diferensial berikutnya untuk minggu tersebut. Grup ketersediaan utama yang baru harus membuat cadangan diferensial hanya setelah failover (dan bukan cadangan penuh) dan menambahkannya ke bucket. Grup ketersediaan sekunder baru hanya menerapkan semua cadangan di bucket minggu ini. Jika pendekatan mingguan ini digunakan, Anda harus menerapkan strategi pembersihan atau penghapusan permanen untuk menghapus cadangan yang sudah tidak digunakan.
Peningkatan lainnya didasarkan pada fakta bahwa grup ketersediaan sekunder baru adalah grup ketersediaan utama sebelumnya. Jika database ada dan beroperasi setelah tersedia lagi, pemulihan point-in-time hingga cadangan diferensial terakhir akan menghindari keharusan memulihkannya dari pencadangan penuh terakhir seperti yang dijelaskan dalam Memulihkan Database SQL Server ke Titik Waktu (Model Pemulihan Penuh). Skenario ini mengurangi upaya dan durasi waktu grup ketersediaan utama yang baru tidak dilindungi.
Praktik terbaik produksi
Solusi ini tidak menentukan apakah instance SQL Server dalam grup ketersediaan Always On adalah instance FCI atau mandiri. Jenis instance yang digunakan harus diputuskan sebelum implementasi.
Hingga grup ketersediaan Always-On sekunder baru beroperasi setelah failover, terkadang DR tidak dilindungi. Anda harus menyiapkan grup ketersediaan Always On ketiga di region ketiga.
Selain itu, Anda juga harus mengimplementasikan pemantauan untuk memastikan bahwa kegagalan atau error dapat terdeteksi. Pemantauan berada di luar cakupan dokumen ini, tetapi sangat penting untuk solusi pemulihan dari bencana (disaster recovery) yang berfungsi.
Langkah berikutnya
- Mengonfigurasi Grup Ketersediaan SQL Server Always On.
- Men-deploy grup ketersediaan SQL Server 2016 Always On multi-subnet di Compute Engine.
- Mengonfigurasi Instance Cluster Failover SQL Server.
- Menjalankan failover clustering server Windows.
- Cara mengaktifkan Cloud Logging, Cloud Monitoring, dan Error Reporting untuk aplikasi .NET
- Menginstal agen Cloud Monitoring.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.