Ce tutoriel explique comment intégrer une nouvelle application, développer une fonctionnalité pour elle et la déployer en production à l'aide de techniques modernes d'intégration continue/de livraison continue (CI/CD) avec Google Kubernetes Engine (GKE).
Ce document fait partie d'une série :
- CI/CD moderne avec GKE : un framework de livraison de logiciels
- CI/CD moderne avec GKE: créer un système CI/CD (architecture de référence)
- CI/CD moderne avec GKE: appliquez le workflow de développeur (ce document)
Dans ce tutoriel, vous utilisez des outils tels que :Skaffold, kustomize, Artifact Registry, Config Sync, Cloud Build etCloud Deploy pour développer, compiler et déployer votre application.
Ce document est destiné aux architectes d'entreprise et aux développeurs d'applications, ainsi qu'aux équipes chargées de la sécurité informatique, des DevOps et de l'ingénierie en fiabilité des sites (SRE). Une certaine expérience des outils et des processus de déploiement automatisés est utile pour comprendre les concepts présentés dans ce document.
Architecture
Dans ce tutoriel, vous allez intégrer une nouvelle application. Vous développez ensuite une nouvelle fonctionnalité et déployez l'application dans des environnements de développement, de préproduction et de production. L'architecture de référence contient l'infrastructure et les outils nécessaires pour intégrer et publier une nouvelle application avec le workflow présenté dans le schéma suivant:

À partir du dépôt de code pour CI, le workflow comprend les étapes suivantes :
Vous partagez le code source de votre application via vos dépôts d'applications.
Lorsque vous procédez au commit et au transfert du code dans le dépôt d'application, cela déclenche automatiquement un pipeline CI dans Cloud Build. Le processus CI crée une image de conteneur et la transfère vers Artifact Registry.
Le processus CI crée également une version CD pour l'application dans Cloud Deploy.
La version CD génère des fichiers manifestes Kubernetes entièrement rendus pour le développement à l'aide de
skaffoldet les déploie dans le cluster GKE de développement.La version CD est ensuite promue depuis le développement en cible de préproduction, qui génère des fichiers manifestes de préproduction entièrement rendus et les déploie dans le cluster de préproduction GKE.
La version CD est ensuite promue de la préproduction à la production, qui génère des fichiers manifestes de production entièrement rendus et les déploie dans les clusters GKE de production.
Pour en savoir plus sur les outils et l'infrastructure utilisés dans ce workflow, consultez la page CI/CD moderne avec GKE: créer un système CI/CD.
Objectifs
Intégrer une nouvelle application.
Déployez l'application dans l'environnement de développement.
Développez une nouvelle fonctionnalité et déployez-la dans l'environnement de développement.
Promouvoir la nouvelle fonctionnalité en préproduction, puis la mettre en production.
Testez la résilience de l'application.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- Google Kubernetes Engine
- Google Kubernetes Engine (GKE) Enterprise edition for Config Sync
- Artifact Registry
- Cloud Build
- Cloud Deploy
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Pour ce tutoriel, déployez l'architecture de référence de cette série.
Préparer votre environnement
Si vous continuez directement depuis CI/CD moderne avec GKE: créez un système CI/CD, passez à la section suivante. Toutefois, si vous avez ouvert une nouvelle session ou si votre session a expiré, ouvrez Cloud Shell et définissez le projet dans lequel vous avez installé l'infrastructure d'architecture de référence:
gcloud config set core/project PROJECT_ID
Remplacez
PROJECT_IDpar l'ID de votre projet Google Cloud.
Intégrer une nouvelle application
L'architecture de référence contient une fabrique d'applications. Cette fabrique est une collection d'un dépôt Git nommé application-factory-repo et des déclencheurs Cloud Build suivants:
create-apptf-plantf-applycreate-team
Vous utilisez la fabrique d'applications pour intégrer une nouvelle application à partir de dépôts de démarrage. L'intégration d'une application comprend les étapes suivantes:
Créer la définition de l'application: vous créez la définition de l'application dans un fichier Terraform et vous la stockez dans
application-factory-repo, qui sert de catalogue d'applications.Créer l'infrastructure de l'application: vous exécutez Terraform sur le fichier de définition d'application pour créer l'infrastructure d'application. L'infrastructure des applications comprend les éléments suivants:
Une zone de destination pour la nouvelle application inclut la définition de l'espace de noms, du compte de service et des règles de base dans le dépôt
acm-gke-infrastructure-repo. La zone de destination n'est créée que dans un cluster de développement GKE lors de l'intégration d'une nouvelle application. Cette opération permet de débloquer les développeurs pour qu'ils puissent utiliser l'environnement de développement et commencer à effectuer des itérations. La zone de destination des clusters de préproduction et de production est créée avec l'approche GitOps. Cette approche est présentée plus loin dans ce document lorsque vous êtes prêt à promouvoir la version dans ces clusters.Dépôt d'infrastructure du dépôt de démarrage de l'infrastructure qui héberge le code permettant de créer le pipeline de CI dans Cloud Build, le pipeline CD dans Cloud Deploy et le dépôt Artifact Registry pour stocker les artefacts.
Déclencheur Cloud Build d'infrastructure qui prend le code dans le dépôt d'infrastructure et crée les ressources en fonction de leur définition.
Un dépôt d'application à partir du dépôt de démarrage de l'application qui héberge le code source de l'application.
Créer les ressources CI/CD d'une application: l'infrastructure de l'application vous permet de créer des ressources CI/CD pour l'application.
Créez une définition d'application:
Exécutez le déclencheur create-app pour générer un fichier de définition d'application dans application-factory-repo. Le fichier de définition contient la définition déclarative des ressources requises pour créer une application.
Dans la console Google Cloud, accédez à la page Cloud Build :
Cliquez sur Déclencheur
create-app.Cliquez sur AFFICHER L'APERÇU D'URL pour afficher l'URL requise pour appeler le webhook.
Dans Cloud Shell, appelez le déclencheur en effectuant une requête curl sur l'URL obtenue à l'étape précédente, puis en lui transmettant les paramètres en tant que charge utile.
curl "WEBHOOK_URL" -d '{"message": {"app": "sample","runtime": "python","trigger_type": "webhook","github_team": ""}}'Dans l'exemple de code précédent:
Remplacez
WEBHOOK_URLpar l'URL obtenue à partir du déclencheur."app": "sample": spécifie le nom de l'application."runtime": "python"indique à la fabrique d'applications d'utiliser le modèle Python pour créer des dépôts d'applications."trigger_type": "webhook"spécifie le type de pipelines CI/CD pour l'application."github_team": ""est une équipe dans GitHub qui sera associée aux dépôts créés pour l'application. Comme vous n'avez pas encore créé d'équipe GitHub, transmettez-la en tant que chaîne vide.
Vérifiez le pipeline pour le déclencheur
create-app:Accéder à la page Historique de Cloud Build
Il existe un nouveau pipeline pour le déclencheur
create-app. Une fois cette opération terminée, la définition de l'application est créée dansapplication-factory-repo.Examinez le fichier de définition d'application:
Dans un navigateur Web, accédez à GitHub et connectez-vous à votre compte.
Cliquez sur l'icône représentant une photo, puis sur
Your organizations. Choisissez votre organisation.Cliquez sur le dépôt
application-factory-repo, accédez au dossierapps/pythonet ouvrez le nouveau fichier nommésample.tfcréé par le déclencheurcreate-app. Inspectez le fichier. Ce fichier contient du code Terraform pour créer une application.
Créez l'infrastructure de l'application:
Maintenant que vous avez créé la définition de l'application, vous allez exécuter le déclencheur tf-apply pour créer l'infrastructure de l'application.
Dans la console Google Cloud :
Accéder à la page Cloud Build.
Cliquez sur le déclencheur
tf-apply.Cliquez sur "AFFICHER L'APERÇU DE L'URL" pour afficher l'URL requise pour appeler le webhook.
Appelez le déclencheur:
curl "WEBHOOK_URL" -d '{}'Dans l'exemple de code précédent:
- Remplacez
WEBHOOK_URLpar l'URL obtenue à partir du déclencheur.
- Remplacez
Vérifiez le pipeline pour le déclencheur
tf-apply:Accéder à la page Historique de Cloud Build
Il existe un nouveau pipeline pour le déclencheur
tf-apply. Attendez la fin de l'opération.
Ce déclencheur crée l'infrastructure de l'application.
Examinez l'infrastructure de l'application:
Examiner les différents composants de l'infrastructure de l'application
Zone de destination
Accédez à Cloud Shell et définissez le projet.
gcloud config set core/project PROJECT_ID
Remplacez
PROJECT_IDpar l'ID de votre projet Google Cloud.Obtenez les identifiants du cluster GKE de développement.
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-aVérifiez l'espace de noms de l'application. L'espace de noms porte le nom de l'application, sample (exemple).
kubectl get namespaces sampleLe résultat se présente comme suit :
NAME STATUS AGE sample Active 15m
Vérifiez le compte de service dans l'espace de noms.
kubectl get serviceaccounts -n sampleIl existe un compte de service en plus du compte par défaut. Le résultat se présente comme suit :
NAME SECRETS AGE default 0 15m sample-ksa 0 15m
Dépôt d'infrastructure
Dans un navigateur Web, accédez à GitHub et connectez-vous à votre compte. Cliquez sur l'icône d'image. Ensuite, cliquez sur Your organizations. Choisissez votre organisation et cliquez sur le dépôt sample-infra.
Ce dépôt comporte quatre branches: cicd-trigger, dev, staging et prod. Il contient également quatre dossiers cicd-trigger, dev, staging et prod. La branche par défaut est cicd-trigger. Vous pouvez y transférer le code, tandis que d'autres branches ont des règles de protection. Vous ne pouvez donc pas transférer du code directement à ces branches. Pour transférer le code vers ces branches, vous devez créer une demande d'extraction. Le dossier cicd-trigger contient le code permettant de créer des ressources CI/CD pour l'application, tandis que les dossiers dev, staging et prod contiennent du code permettant de créer une infrastructure pour différents environnements de l'application.
Déclencheur d'infrastructure
Dans la console Google Cloud :
Il existe un nouveau déclencheur nommé
deploy-infra-sample.Ce déclencheur est connecté au dépôt
sample-infra. Ainsi, lorsqu'un transfert de code est effectué vers ce dépôt, le déclencheur est appelé et il identifie la branche où le déploiement s'est produit. Il est ensuite déplacé vers le dossier correspondant sur cette branche et y exécute Terraform. Par exemple, si le code est transféré vers la branchecicd-trigger, le déclencheur exécute Terraform dans le dossier cicd-trigger de la branche cicd-trigger. De même, lorsqu'une opération push est effectuée sur la branchedev, le déclencheur exécute Terraform dans le dossier dev (de développement) de la branche dev, et ainsi de suite.
Dépôt de l'application
- Accédez à GitHub et récupérez les dépôts de votre organisation. Il existe un nouveau dépôt nommé
sample. Ce dépôt héberge le code source et les étapes permettant de créer des conteneurs dans les configurationsDockerfile,kustomizedécrivant les configurations nécessaires de l'application etskaffold.yamldéfinissant les étapes de déploiement que Cloud Deploy doit utiliser pour la livraison continue.
Créer des ressources CI/CD pour l'application
Maintenant que vous avez créé le squelette de l'application, exécutez le déclencheur deploy-infra-sample pour créer ses ressources CI/CD. Vous pouvez appeler le déclencheur manuellement à l'aide de son URL de webhook ou en effectuant un commit dans le dépôt Git sample-infra.
Pour appeler le déclencheur Cloud Build, ajoutez une ligne dans un fichier dans le dépôt. Transmettez ensuite les modifications:
Si vous n'avez jamais utilisé Git dans Cloud Shell, configurez Git avec votre nom et votre adresse e-mail. Git utilise ces informations pour vous identifier en tant qu'auteur des commits que vous créez dans Cloud Shell :
git config --global user.email "GITHUB_EMAIL_ADDRESS" git config --global user.name "GITHUB_USERNAME"
Remplacez les éléments suivants :
GITHUB_EMAIL_ADDRESS: adresse e-mail associée à votre compte GitHub.GITHUB_USERNAME: le nom d'utilisateur associé à votre compte Git.
Cloner le dépôt Git
sample-infra:git clone https://github.com/GITHUB_ORG/sample-infra cd sample-infra
Remplacez les éléments suivants :
GITHUB_ORGpar votre organisation GitHub.
La branche cicd-trigger par défaut est extraite.
Ajoutez une ligne au fichier env/cicd-trigger/main.tf, validez la modification et transférez-la.
echo "" >> env/cicd-trigger/main.tfValidez et appliquez les modifications :
git add . git commit -m "A dummy commit to invoke the infrastrucutre trigger" git push cd ..Dès que les modifications sont transmises, le déclencheur Cloud Deploy
deploy-infra-sampleest démarré.
Surveillez l'état du déclencheur:
Accédez à la page "Historique Cloud Build" pour afficher le pipeline et attendez qu'il soit terminé.
Examiner les ressources CICD de l'application
Examinez les différentes ressources de CI/CD créées pour l'application.
Dans la console Google Cloud :
Accédez à la page Cloud Build et affichez le déclencheur
deploy-app-sample.Il s'agit du déclencheur de pipeline CI. Il est connecté au dépôt de code d'application
sample. Le déclencheur est appelé lorsqu'une opération push est effectuée sur le dépôt de l'application et effectue les étapes de compilation telles que définies dans la configuration du déclencheur. Pour afficher les étapes effectuées par le déclencheur lorsqu'il est appelé, cliquez sur son nom, puis sur le bouton OUVRIR L'ÉDITEUR.Accédez à la page Artifact Registry et affichez le nouveau dépôt nommé
sample.Ce dépôt d'artefacts stocke les artefacts de l'application.
Accédez à la page du pipeline Cloud Deploy et affichez le pipeline nommé
sample. Il s'agit du pipeline de déploiement continu qui déploie l'application sur les clusters GKE.
Déployer l'application dans l'environnement de développement
Le déclencheur deploy-app-sample est connecté au dépôt d'applications nommé sample. Vous pouvez appeler le déclencheur manuellement, à l'aide de l'URL du webhook, ou via un transfert vers le dépôt d'application.
Ajoutez une ligne dans un fichier dans le dépôt
sample, puis déployez les modifications pour appeler le déclencheur Cloud Build:Cloner le dépôt Git
sample:Dans Cloud Shell :
git clone https://github.com/GITHUB_ORG/sample cd sample
Remplacez
GITHUB_ORGpar votre organisation GitHub.Ajoutez une ligne au fichier
skaffold.yaml.echo "" >> skaffold.yamlValidez et appliquez les modifications :
git add . git commit -m "A dummy commit to invoke CI/CD trigger" git pushDès que les modifications sont transmises, le déclencheur Cloud Deploy
deploy-app-sampleest démarré.
Surveillez l'état du déclencheur:
Accédez à la page "Historique Cloud Build" pour afficher le pipeline et attendez qu'il soit terminé.
Le déclencheur exécute les étapes définies dans sa configuration. La première étape consiste à créer une image Docker à partir du code d'application dans le dépôt
sample. La dernière étape consiste à lancer le pipeline Cloud Deploy qui déploie l'application sur le cluster de développement GKE.Vérifiez le déploiement dans le cluster de développement:
Accéder à la page du pipeline Cloud Deploy
Cliquez sur le pipeline
samplepour lancer le déploiement sur le cluster GKE de développement. Attendez la fin de l'opération.
Vérifiez que l'application a bien été déployée :
Obtenez les identifiants du cluster de développement.
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-aCréez un tunnel vers un cluster GKE.
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-a && kubectl port-forward --namespace sample $(kubectl get pod --namespace sample --selector="deploy.cloud.google.com/delivery-pipeline-id=sample" --output jsonpath='{.items[0].metadata.name}') 8080:8080Dans la barre d'outils Cloud Shell, cliquez sur
Aperçu sur le Web, puis cliquez sur Preview on port 8080 (Prévisualiser sur le port 8080) :
Le résultat est le suivant :
Hello World!
Dans Cloud Shell, appuyez sur
CTRL+Cpour mettre fin au transfert de port.
Ajouter une nouvelle fonctionnalité à l'application
Lorsque vous développez une nouvelle fonctionnalité, vous devez déployer rapidement vos modifications dans l'environnement de développement afin de les tester et de les appliquer. Dans ce tutoriel, vous allez modifier le dépôt du code d'application et le déployer dans l'environnement de développement.
Dans Cloud Shell, remplacez le répertoire par le dépôt
sampledéjà cloné:Mettez à jour l'application pour générer un message différent :
sed -i "s/Hello World/My new feature/g" main.pyValidez et appliquez les modifications :
git add . git commit -m "Changed the message" git pushDès que le code est transféré vers le dépôt GitHub, le déclencheur de webhook
deploy-app-sampleest lancé.Surveillez l'état du déclencheur sur la page Historique Cloud Build et attendez qu'il soit terminé.
Accéder à la page du pipeline Cloud Deploy
Cliquez sur le pipeline
samplepour lancer le déploiement sur le cluster GKE de développement. Attendez la fin de l'opération.
Vérifiez que l'application a bien été déployée :
Obtenez des identifiants pour le cluster de développement si vous avez ouvert une nouvelle session Cloud Shell:
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-aCréez un tunnel vers le cluster GKE:
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-a && kubectl port-forward --namespace sample $(kubectl get pod --namespace sample --selector="deploy.cloud.google.com/delivery-pipeline-id=sample" --output jsonpath='{.items[0].metadata.name}') 8080:8080Dans la barre d'outils Cloud Shell, cliquez sur
Aperçu sur le Web, puis cliquez sur Preview on port 8080 (Prévisualiser sur le port 8080) :
Le résultat est le suivant :
My new feature!
Dans Cloud Shell, appuyez sur
CTRL+Cpour mettre fin au transfert de port.
Promouvoir votre modification dans les clusters de préproduction et de production
Avant de promouvoir l'application dans des environnements de préproduction et de production, vous devez créer la zone de destination de l'application dans les clusters GKE de ces environnements. Lorsque vous avez intégré l'application, la zone de destination du développement a été automatiquement créée dans le cluster GKE de développement en ajoutant du code à acm-gke-infrastructure-repo dans la branche de développement.
Créer une zone de destination dans des clusters GKE de préproduction et de production
Créer une zone de destination dans un cluster GKE de préproduction: vous devez créer une demande d'extraction du développement vers la branche de préproduction dans
acm-gke-infrastructure-repo, puis la fusionner.Accédez à GitHub et accédez au dépôt
acm-gke-infrastructure-repo. Cliquez sur le boutonPull requests, puis sur le boutonNew pull request. Dans le menu Base, sélectionnez staging (préproduction) et, dans le menu Comparer, dev. Cliquez sur le boutonCreate pull request.Généralement, une personne ayant accès au dépôt examine les modifications, puis fusionne les demandes d'extraction pour s'assurer que seules les modifications prévues sont promues dans l'environnement de préproduction. Pour permettre aux utilisateurs de tester l'architecture de référence, les règles de protection des branches ont été assouplies afin que l'administrateur du dépôt puisse contourner l'examen et fusionner la demande d'extraction. Si vous êtes administrateur du dépôt, fusionnez la demande d'extraction. Sinon, demandez à l'administrateur de la fusionner.
Config Sync synchronise les modifications qui arrivent sur la branche de préproduction du dépôt
acm-gke-infrastructure-repoavec le cluster GKE de préproduction, ce qui entraîne la création d'une zone de destination pour l'application sur le cluster GKE de préproduction.Créez une zone de destination dans les clusters de production GKE: vous devez créer une demande d'extraction depuis la branche de préproduction vers la branche prod, puis la fusionner.
Cliquez sur le bouton
Pull requests, puis sur le boutonNew pull request. Dans le menu Base, sélectionnez prod et dans le menu Comparer, choisissez staging (préproduction). Cliquez sur le boutonCreate pull request.Si vous êtes administrateur du dépôt, fusionnez la demande d'extraction. Sinon, demandez à l'administrateur de la fusionner.
Config Sync synchronise les modifications apportées à la branche de production du dépôt
acm-gke-infrastructure-repoavec les clusters GKE de production, ce qui entraîne la création d'une zone de destination pour l'application sur des clusters GKE de production.
Faites passer les modifications du développement à la préproduction
Maintenant que vous avez créé la zone de destination de l'application dans des clusters GKE de préproduction et de production, faites passer l'application de l'environnement de développement à celui de préproduction.
Recherchez le dernier nom de version et enregistrez-le en tant que variable d'environnement:
export RELEASE=$(gcloud deploy targets describe dev --region=us-central1 --format="json" | jq -r '."Active Pipeline"[0]."projects/PROJECT_ID/locations/us-central1/deliveryPipelines/sample"."Latest release"' | awk -F '/' '{print $NF}')Remplacez
PROJECT_IDpar l'ID de votre projet Google Cloud.Vérifiez que la variable d'environnement a été définie:
echo $RELEASE
Dans Cloud Shell, exécutez la commande suivante pour déclencher la promotion de la version d'environnement de développement vers celle de préproduction:
gcloud deploy releases promote --release=$RELEASE --delivery-pipeline=sample --region=us-central1 --to-target=staging --quiet
Vérifiez le déploiement en préproduction:
Accéder à la page du pipeline Cloud Deploy
Cliquez sur le pipeline
sampleet le déploiement sur le cluster de préproduction GKE a démarré. Attendez la fin de l'opération.Vérifiez que le déploiement en préproduction a bien été effectué:
Obtenez les identifiants du cluster de préproduction:
gcloud container clusters get-credentials gke-staging-us-central1 --zone us-central1-aCréez un tunnel vers le cluster GKE:
gcloud container clusters get-credentials gke-staging-us-central1 --zone us-central1-a && kubectl port-forward --namespace sample $(kubectl get pod --namespace sample --selector="deploy.cloud.google.com/delivery-pipeline-id=sample" --output jsonpath='{.items[0].metadata.name}') 8080:8080Dans la barre d'outils Cloud Shell, cliquez sur
Aperçu sur le Web, puis cliquez sur Preview on port 8080 (Prévisualiser sur le port 8080) :
Le résultat est le suivant :
My new feature!
Dans Cloud Shell, appuyez sur
CTRL+Cpour mettre fin au transfert de port.
Promouvoir les changements de la préproduction à la production
Maintenant, vous pouvez promouvoir la version de préproduction en production. Vous disposez de deux clusters de production. Cloud Deploy possède une cible pour chacun d'eux, respectivement nommés prod1 et prod2.
Dans Cloud Shell, exécutez la commande suivante pour déclencher la promotion de la version depuis le cluster de préproduction vers le cluster de production (prod1):
gcloud deploy releases promote --release=$RELEASE --delivery-pipeline=sample --region=us-central1 --to-target=prod1 --quiet
La publication sur des clusters de production nécessite une approbation. Le déploiement attend donc que vous l'approuviez. Pour l'afficher:
Accéder à la page du pipeline Cloud Deploy
Cliquez sur le pipeline
sample. Le déploiement sur prod1 nécessite l'approbation. Le rôle clouddeploy.approver est nécessaire pour approuver le déploiement. Comme vous êtes le propriétaire du projet, vous disposez d'un accès pour approuver la version.Approuvez la version dans prod1:
Exécutez la commande suivante pour récupérer le nom du déploiement en attente d'approbation et l'enregistrer dans une variable d'environnement:
export ROLLOUT=$(gcloud deploy targets describe prod1 --region=us-central1 --format="json" | jq -r '."Pending Approvals"[]' | awk -F '/' '{print $NF}')Approuvez la version:
gcloud deploy rollouts approve $ROLLOUT --delivery-pipeline=sample --region=us-central1 --release=$RELEASE --quiet
Une fois l'approbation accordée, la version de prod1 démarre. Surveillez la progression sur la page Pipeline Cloud Deploy.
Une fois le déploiement prod1 terminé, lancez la version prod2.
gcloud deploy releases promote --release=$RELEASE --delivery-pipeline=sample --region=us-central1 --to-target=prod2 --quiet
La publication sur prod2 nécessite également une approbation. Approuvez la version du cluster prod2:
Exécutez la commande suivante pour récupérer le nom du déploiement en attente d'approbation et l'enregistrer dans une variable d'environnement:
export ROLLOUT=$(gcloud deploy targets describe prod2 --region=us-central1 --format="json" | jq -r '."Pending Approvals"[]' | awk -F '/' '{print $NF}')Approuvez la version:
gcloud deploy rollouts approve $ROLLOUT --delivery-pipeline=sample --region=us-central1 --release=$RELEASE --quiet
Une fois l'approbation accordée, la version de prod2 démarre. Surveillez la progression sur la page Pipeline Cloud Deploy.
Vérifiez que le déploiement dans le cluster de production a réussi après la fin des pipelines Cloud Deploy dans prod1 et prod2.
Un objet Ingress multicluster est créé dans les clusters de production, et vous utilisez un équilibreur de charge pour accéder à l'application de production. Ces configurations d'entrée multicluster sont créées à l'aide des fichiers YAML k8s/prod/mci.yaml et k8s/prod/mcs.yaml dans le dépôt
sample. Lorsque vous envoyez une requête à l'adresse IP de l'équilibreur de charge, Multi Cluster Ingress transmet la requête à l'une des deux instances de l'application exécutée dans deux clusters GKE différents.Répertoriez la règle de transfert associée à l'équilibreur de charge pour trouver l'adresse IP.
gcloud compute forwarding-rules list
Le résultat se présente comme suit :
NAME: mci-qqxs9x-fw-sample-sample-ingress REGION: IP_ADDRESS: 34.36.123.118 IP_PROTOCOL: TCP TARGET: mci-qqxs9x-sample-sample-ingress
Ouvrez un navigateur Web et saisissez l'URL suivante:
http://IP_ADDRESS:80
Remplacez
IP_ADDRESSpar l'adresse IP de l'équilibreur de charge.Le résultat est le suivant :
My new feature!
Cela confirme que l'application est déployée comme prévu dans les clusters de production.
Tester la résilience de l'application
Dans cette section, vous allez tester la résilience de l'application exécutée en production en redémarrant l'un des deux nœuds de cluster GKE de production sans affecter l'application.
L'application en production utilise une entrée multicluster et est accessible via une adresse IP d'équilibreur de charge. Lorsque l'application est accessible via cette adresse IP, l'entrée multicluster l'achemine vers l'une des deux instances de l'application exécutée sur deux clusters GKE différents. Lorsqu'un des clusters GKE n'est pas opérationnel et que l'instance d'application exécutée sur celui-ci n'est pas accessible, l'entrée multicluster continue d'envoyer le trafic vers l'instance opérationnelle de l'application exécutée sur l'autre cluster GKE. Cela rend l'interruption du cluster invisible pour l'utilisateur final, et l'application diffuse en continu les requêtes.
Pour tester la résilience, procédez comme suit:
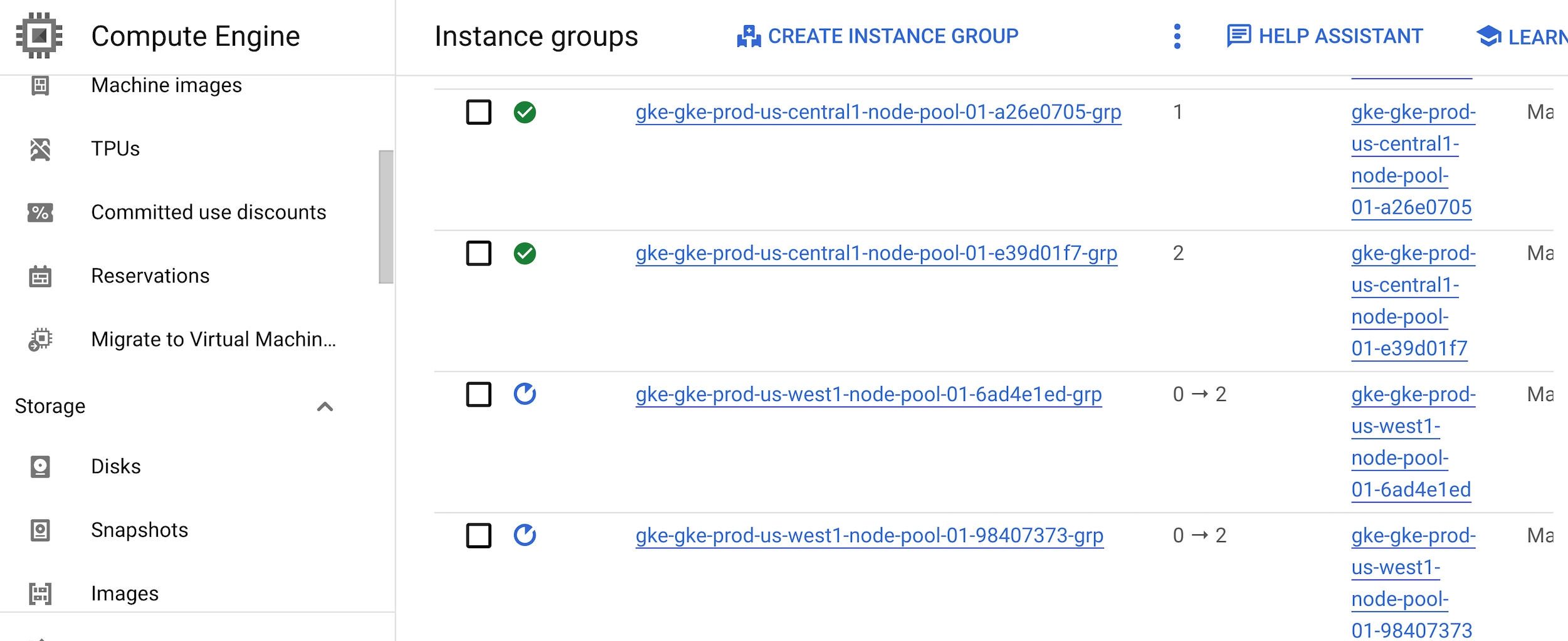
Recherchez le pool de nœuds des clusters GKE de production exécutés dans la région us-west1.
gcloud container clusters describe gke-prod-us-west1 --zone=us-west1-a --format=json | jq ".nodePools[0].instanceGroupUrls[]" | tr '"' ' ' | awk -F '/' '{for(i=NF-2; i<=NF; i=i+2) printf ("%s ",$i); print ""}'Le résultat se présente comme suit :
us-west1-b gke-gke-prod-us-west1-node-pool-01-6ad4e1ed-grp us-west1-c gke-gke-prod-us-west1-node-pool-01-98407373-grp
Le résultat comporte deux colonnes : la première correspond à la zone et la deuxième au nom du groupe d'instances associé au pool de nœuds du cluster GKE de production dans la région us-west1.
Redémarrez le groupe d'instances correspondant aux pools de nœuds:
gcloud compute instance-groups managed rolling-action restart INSTANCE_GROUP_1 --zone=ZONE_1 --max-unavailable=100% gcloud compute instance-groups managed rolling-action restart INSTANCE_GROUP_2 --zone=ZONE_2 --max-unavailable=100%
Remplacez
INSTANCE_GROUP_1par le nom du premier groupe d'instances.Remplacez
ZONE_1par la zone du premier groupe d'instances.Remplacez
INSTANCE_GROUP_2par le nom du deuxième groupe d'instances.Remplacez
ZONE_2par la zone du deuxième groupe d'instances.Vérifiez l'état du groupe d'instances.
Accéder à la page "Groupes d'instances"
Les deux groupes d'instances sont en cours de redémarrage, tandis que les autres groupes sont signalés par une coche verte.
Ouvrez un navigateur Web et saisissez l'URL suivante:
http://IP_ADDRESS:80
Remplacez
IP_ADDRESSpar l'adresse IP de l'équilibreur de charge.Même lorsque l'un des deux clusters GKE est en panne, l'application est disponible et le résultat est le suivant:
My new feature!
Cela montre que votre application est résiliente et hautement disponible.
Gérer l'application
Lorsque vous avez créé cette application à partir de la fabrique d'applications, vous avez obtenu des dépôts Git et des pipelines CI/CD distincts ainsi qu'une infrastructure distincte pour l'application. Vous avez utilisé ces ressources pour déployer l'application et ajouter une nouvelle fonctionnalité. Pour gérer davantage l'application, il vous suffit d'interagir avec ces dépôts Git et le pipeline sans avoir à mettre à jour la fabrique d'applications. Vous pouvez personnaliser les pipelines et les dépôts Git de l'application en fonction de vos besoins. En tant que propriétaire d'application, vous pouvez définir qui a accès aux pipelines et aux dépôts Git de votre application pour la gérer.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel soient facturées sur votre compte Google Cloud, procédez comme suit :
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étape suivante
- Découvrez les bonnes pratiques de configuration de la fédération d'identités.
- Consultez Kubernetes et les défis liés au déploiement continu de logiciels.
- Découvrez les modèles de surveillance et de journalisation hybrides et multicloud.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.