このガイドでは、VM ランタイムを使用して、ベアメタル上の Google Distributed Cloud(GDC)エアギャップ クラスタに仮想マシン(VM)ベースのワークロードをデプロイするために必要な概念的なコンテキストについて説明します。このガイドのワークロードは、オンプレミス ハードウェアで使用可能なサンプル チケット発行システム プラットフォームです。
アーキテクチャ
リソース階層
GDC では、チケット発行システムを構成するコンポーネントを、オペレーション チーム専用のテナント組織にデプロイします。これは、他の顧客組織と同じです。組織は、まとめて管理されるクラスタ、インフラストラクチャ リソース、アプリケーション ワークロードの集合です。GDC インスタンス内の各組織は専用のサーバーセットを使用するため、テナント間の分離が強化されます。インフラストラクチャの詳細については、アクセス境界を設計するをご覧ください。
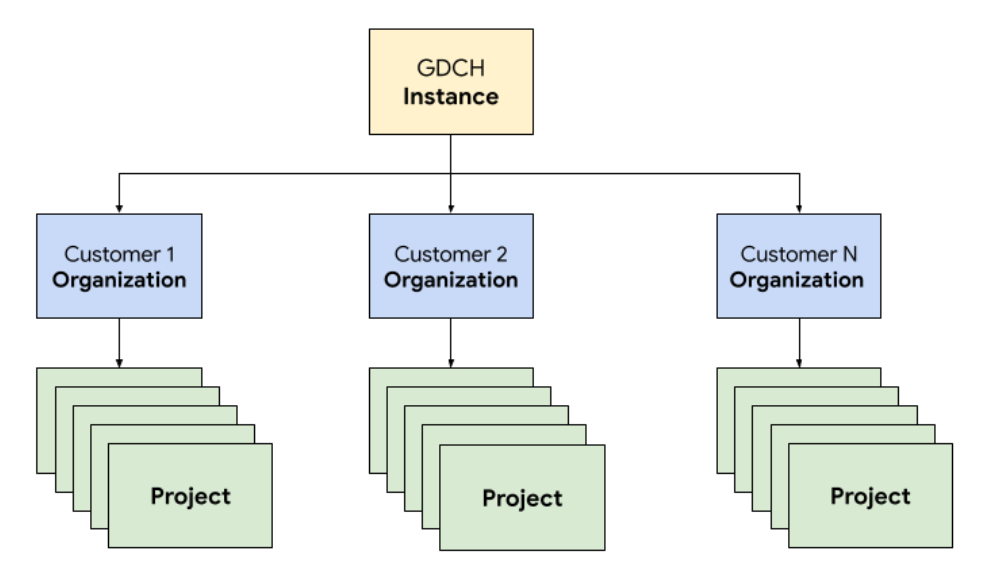
また、チケット発行システムのリソースをプロジェクトに一緒にデプロイして管理します。これにより、ソフトウェア ポリシーと適用を使用して、組織内で論理的な分離が実現します。プロジェクト内のリソースは、ライフサイクルを通じて一緒に維持する必要があるコンポーネントを結合することを目的としています。
チケット発行システムは、ロードバランサを使用して、永続データを保存するデータベース サーバーに接続するアプリケーション サーバー間でトラフィックを転送する 3 階層アーキテクチャに従います。
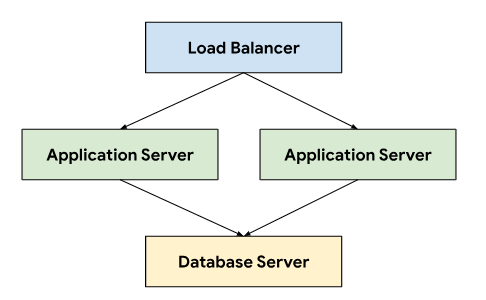
このアーキテクチャでは、各階層を個別に開発して維持できるため、スケーラビリティと保守性が向上します。また、関心の分離が明確になるため、デバッグやトラブルシューティングが簡素化されます。これらの階層を GDC プロジェクト内にカプセル化すると、アプリケーション サーバーやデータベース サーバーなどのコンポーネントをまとめてデプロイして管理できます。
ネットワーキング
本番環境でチケット発行システムを実行するには、ノード障害が発生した場合に高可用性を実現するために、2 つ以上のアプリケーション サーバーをデプロイする必要があります。このトポロジでは、ロードバランサと組み合わせて、複数のマシンに負荷を分散してアプリケーションを水平方向にスケーリングすることもできます。GDC の Kubernetes ネイティブ プラットフォームは、Cloud Service Mesh を使用して、発券システムを構成するアプリケーション サーバーにトラフィックを安全にルーティングします。
Cloud Service Mesh は、サービスの管理、監視、保護を行うオープンソース プロジェクトに基づく Google の実装です。Cloud Service Mesh の次の機能を利用して、GDC でチケット販売システムをホストします。
- ロード バランシング: Cloud Service Mesh は、トラフィック フローとインフラストラクチャのスケーリングを分離し、動的リクエスト ルーティングなどのさまざまなトラフィック管理機能を利用できるようにします。チケット発行システムには永続的なクライアント接続が必要なため、
DestinationRulesを使用してスティッキー セッションを有効にし、トラフィック ルーティングの動作を構成します。
TLS 終端: Cloud Service Mesh は、TLS 証明書を使用して上り(内向き)ゲートウェイを公開し、アプリケーション コードを変更することなく、mTLS(Mutual Transport Layer Security)を介してクラスタ内のトランスポート認証を提供します。
障害復旧: Cloud Service Mesh には、タイムアウト、サーキット ブレーカー、アクティブ ヘルスチェック、制限付き再試行など、重要な障害復旧機能が多数用意されています。
Kubernetes クラスタ内では、標準の Service オブジェクトを使用して、アプリケーション サーバーとデータベース サーバーをネットワークに公開します。Service は、セレクタを使用してインスタンスをターゲットにする便利な方法を提供し、クラスタ対応 DNS サーバーを使用してクラスタ内で名前解決を提供します。
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
コンピューティング
チケット発行システムでは、オンプレミス インストールをホストするためにベアメタルまたは仮想マシンのいずれかを使用することが推奨されています。そこで、GDC 仮想マシン(VM)管理を使用して、アプリケーション サーバーとデータベース サーバーの両方を VM ワークロードとしてデプロイしました。Kubernetes リソースを定義することで、VirtualMachine と VirtualMachineDisk の両方を指定して、さまざまなタイプのサーバーのニーズに合わせてリソースを調整できました。VirtualMachineExternalAccess を使用すると、VM のデータ転送(イン)とデータ転送(アウト)を構成できます。
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
ゲスト OS イメージについては、コンプライアンスとセキュリティの要件を満たすカスタム イメージを作成しました。実行中の VM インスタンスには、VirtualMachineAccessRequest を使用して SSH 経由で接続できます。これにより、Kubernetes RBAC を介して VM への接続機能を制限し、カスタム イメージでローカル ユーザー アカウントを作成する必要がなくなります。アクセス リクエストでは、有効期間(TTL)も定義します。これにより、時間ベースのアクセス リクエストで、自動的に期限切れになる VM を管理できます。
自動化
このプロジェクトの重要な成果物として、広範な自動化をサポートし、デプロイ間の構成のずれを減らすことができる、チケット発行システムのインスタンスを繰り返しインストールするアプローチを設計しました。
リリース パイプライン
アプリケーション サーバー イメージとデータベース サーバー イメージのカスタマイズは、ベース オペレーティング システム イメージから始まり、各サーバー イメージに必要な依存関係をインストールするために必要に応じてベースイメージを変更します。ベース OS イメージは、オンプレミス インストールでチケット発行システムをホストするために広く採用されているため、選択しました。このベース OS イメージは、NIST-800-53 制御を満たす準拠イメージの提供に必要なセキュリティ技術実装ガイド(STIG)を満たすために必要なセキュリティ強化機能も提供します。
継続的インテグレーション(CI)パイプラインでは、次のワークフローを使用してアプリケーション サーバー イメージとデータベース サーバー イメージをカスタマイズしました。
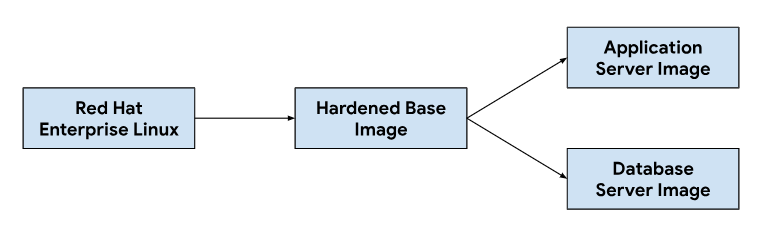
デベロッパーがカスタマイズ スクリプトまたはイメージの依存関係を変更すると、CI ツールで自動ワークフローがトリガーされ、GDC リリースにバンドルされる新しいイメージのセットが生成されます。イメージのビルドの一環として、OS の依存関係を更新(yum update)し、圧縮でイメージをスパース化して、イメージを顧客環境に転送するために必要なイメージサイズを縮小します。
ソフトウェア開発ライフサイクル
ソフトウェア開発ライフサイクル(SDLC)は、組織がソフトウェアの計画、作成、テスト、デプロイを行うのに役立つプロセスです。明確に定義された SDLC に従うことで、組織はソフトウェアが一貫性のある再現可能な方法で開発されることを保証し、潜在的な問題を早期に特定できます。継続的インテグレーション(CI)パイプラインでのイメージのビルドに加えて、テストと品質保証のために、チケット発行システムのプレリリース バージョンを開発してステージングする環境も定義しました。
GDC プロジェクトごとにチケット発行システムの個別のインスタンスをデプロイすることで、同じ GDC インスタンス上の既存のインスタンスに影響を与えることなく、変更を個別にテストできました。ResourceManager API を使用して、Kubernetes リソースを使用してプロジェクトを宣言的に作成および削除しました。
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
チャートのパッケージ化と、仮想マシンなどのインフラストラクチャをコードとして管理することを組み合わせることで、デベロッパーは本番環境インスタンスと並行して、変更の反復処理や新機能のテストを迅速に行うことができます。宣言型 API を使用すると、自動テスト実行フレームワークで定期的な回帰テストを実行し、既存の機能を確認することもできます。
操作性
運用性とは、システムを運用および保守する際の容易さです。これは、ソフトウェア アプリケーションの設計において重要な考慮事項です。効果的なモニタリングは、システムに大きな影響を与える前に問題を特定して対処できるため、運用性に貢献します。モニタリングは、改善の機会を特定し、サービスレベル目標(SLO)のベースラインを確立するためにも使用できます。
モニタリング
チケット発行システムを、ロギングや指標などの既存の GDC オブザーバビリティ インフラストラクチャと統合しました。指標については、各 VM から HTTP エンドポイントを公開し、アプリケーションがアプリケーション サーバーとデータベース サーバーによって生成されたデータポイントをスクレイピングできるようにします。これらのエンドポイントには、アプリケーション ノード エクスポータを使用して収集されたシステム指標とアプリケーション固有の指標が含まれます。
各 VM で公開されたエンドポイントを使用して、MonitoringTarget カスタム リソースを使用してアプリケーションのポーリング動作を構成し、スクレイピング間隔を定義して指標にアノテーションを付けました。
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
ロギングについては、各 VM にロギングと指標のプロセッサをインストールして構成し、関連するログを追跡してログデータをロギング ツールに送信しました。このツールでは、データがインデックス登録され、モニタリング インスタンスを介してクエリされます。監査ログは、コンプライアンスのために保持期間が延長された特別なエンドポイントに転送されます。コンテナベースのアプリケーションは、LoggingTarget カスタム リソースと AuditLoggingTarget カスタム リソースを使用して、ロギング パイプラインにプロジェクト内の特定のサービスからログを収集するように指示できます。
ロギング プロセッサとモニタリング プロセッサで使用可能なデータに基づいて、MonitoringRule カスタム リソースを使用してアラートを作成しました。これにより、この構成をチャート パッケージのコードとして管理できます。宣言型 API を使用してアラートとダッシュボードを定義すると、この構成をコード リポジトリに保存し、他のコード変更と同じコードレビューと継続的インテグレーションのプロセスに従うことができます。
障害モード
早期のテストで、リソース関連の障害モードがいくつか発見されました。これにより、どの指標とアラートを最初に追加するかを優先順位付けできました。データベースの構成ミスにより、バッファ テーブルが使用可能なメモリをすべて消費し、過剰なロギングによってアタッチされた永続ボリューム ディスクが満杯になったため、まずメモリとディスクの使用率が高い状態をモニタリングすることから始めました。ストレージ バッファサイズを調整し、ログローテーション戦略を実装した後、VM のメモリまたはディスク使用率が高くなると実行されるアラートを導入しました。
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
システムの安定性を確認した後、チケット発行システム内のアプリケーション障害モードに焦点を当てました。アプリケーション内の問題のデバッグでは、各アプリケーション サーバー VM にセキュア シェル(SSH)を使用してチケット発行システムのログを確認する必要があることが多いため、これらのログをロギングツールに転送するようにアプリケーションを構成し、GDC のオブザーバビリティ スタックを構築して、モニタリング インスタンス内のチケット発行システムのすべての運用ログをクエリできるようにしました。
一元化されたロギングにより、複数の VM から同時にログをクエリできるようになり、システム内の各コンポーネントのビューを統合できました。
バックアップ
バックアップは、障害が発生した場合にシステムを復元できるため、ソフトウェア システムの運用性にとって重要です。GDC は、Kubernetes リソースを介して VM のバックアップと復元を提供します。VirtualMachineBackupPlanTemplate カスタム リソースを使用して VirtualMachineBackupRequest カスタム リソースを作成すると、各 VM にアタッチされた永続ボリュームをオブジェクト ストレージにバックアップできます。バックアップは、設定された保持ポリシーに従って保持されます。
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
同様に、バックアップから VM の状態を復元するには、VirtualMachineRestoreRequest カスタム リソースを作成して、アプリケーション サーバーとデータベース サーバーの両方を復元します。このとき、どちらのサービスのコードや構成も変更しません。
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
アップグレード
チケット発行システムとその依存関係のソフトウェア ライフサイクルをサポートするために、3 種類のソフトウェア アップグレードを特定しました。ダウンタイムとサービスの中断を最小限に抑えるため、それぞれ個別に処理されます。
- OS のアップグレード。
- パッチ バージョンやメジャー バージョンなどのプラットフォーム アップグレード。
- 構成の更新。
OS のアップグレードでは、アプリケーション サーバーとデータベース サーバーの両方に対して新しい VM イメージを継続的にビルドしてリリースします。これらのイメージは、各 GDC リリースで配布されます。これらのイメージには、セキュリティの脆弱性の修正と基盤となるオペレーティング システムのアップデートが含まれています。
チケット発行システム プラットフォームのアップグレードでは、既存の VM イメージに更新を適用する必要があるため、不変インフラストラクチャに依存してパッチ適用とメジャー リリース バージョンの更新を行うことはできません。プラットフォームのアップグレードでは、パッチまたはメジャー リリース バージョンを開発環境とステージング環境でテストして検証してから、GDC リリースとともにスタンドアロン アップグレード パッケージをリリースします。
最後に、更新セットやその他のユーザーデータのチケット発行システム API を介して、ダウンタイムなしで構成の更新が適用されます。構成の更新は、開発環境とステージング環境で開発およびテストしてから、GDC リリース プロセスで複数の更新セットをまとめてパッケージ化します。
統合
ID プロバイダ
お客様にシームレスなジャーニーを提供し、組織がユーザーをオンボーディングできるように、チケット発行システムを GDC で利用可能な複数の ID プロバイダと統合します。通常、企業や公共部門のお客様は、従業員に利用資格を付与したり取り消したりするための、適切に管理された独自の ID プロバイダを持っています。コンプライアンス要件と ID およびアクセス ガバナンスの容易さから、これらのユーザーは既存の ID プロバイダを信頼できる情報源として使用し、従業員のチケット発行システムへのアクセスを管理したいと考えています。
このチケット発行システムは、マルチ ID プロバイダ モジュールを介して SAML 2.0 プロバイダと OIDC プロバイダの両方をサポートしています。このモジュールは、アプリケーション サーバー VM イメージで事前に有効になっています。お客様は組織の ID プロバイダを通じて認証を行い、チケット発行システム内でユーザーが自動的に作成され、ロールが割り当てられます。
ID プロバイダ サーバーへの下り(外向き)は ProjectNetworkPolicy カスタム リソースで許可されます。これにより、GDC の組織から外部サービスにアクセスできるかどうかが制限されます。これらのポリシーを使用すると、ネットワーク上でチケット発行システムがアクセスできるエンドポイントを宣言的に制御できます。
アラートの取り込み
ユーザーがログインしてサポートケースを手動で作成できるようにするだけでなく、システム アラートに応じてチケット発行システムのインシデントも作成します。
この統合を実現するために、オープンソースの Kubernetes Webhook をカスタマイズして、アプリケーションからアラートを受信し、Cloud Service Mesh を介して公開されたチケット発行システム API エンドポイントを使用してインシデントのライフサイクルを管理しました。
API キーは、ロールベース アクセス制御(RBAC)で制御される Kubernetes シークレットによってバックアップされた GDC シークレット ストアを使用して保存されます。API エンドポイントやインシデントのカスタマイズ フィールドなどの他の構成は、Kubernetes ConfigMap の Key-Value ストレージで管理されます。
メール
チケット発行システムには、メールサーバー統合機能が用意されており、お客様はメールベースのサポートを受けることができます。自動化されたワークフローにより、お客様からのメールがサポートケースに変換され、ケースリンクを含む自動返信がお客様に送信されます。これにより、サポートチームは受信トレイをより適切に管理し、メール リクエストを体系的に追跡して解決し、より優れたカスタマー サービスを提供できます。
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
メールを Kubernetes Service として公開すると、サービス ディスカバリとドメイン名解決も提供され、メールサーバー バックエンドとチケット発行システムなどのクライアントがさらに分離されます。
コンプライアンス
監査ロギング
監査ログは、ソフトウェアの使用状況を追跡してモニタリングし、システム アクティビティの記録を提供することで、コンプライアンス体制に貢献します。監査ログは、権限のないユーザーによるアクセス試行を記録し、API の使用状況を追跡し、潜在的なセキュリティ リスクを特定します。監査ログは、医療保険の相互運用性と説明責任に関する法律(HIPAA)、ペイメント・カード情報に関するセキュリティ基準(PCI DSS)、サーベンス オクスリー法(SOX)などのコンプライアンス要件を満たしています。
GDC は、プラットフォーム内の管理アクティビティとアクセスを記録し、これらのログを構成可能な期間保持するシステムを提供します。AuditLoggingTarget カスタム リソースをデプロイすると、アプリケーションから監査ログを収集するようにロギング パイプラインが構成されます。
チケット発行システムでは、収集されたシステム監査イベントと、チケット発行システムのセキュリティ監査ログによって生成されたアプリケーション固有のイベントの両方に対して、監査ロギング ターゲットを構成しました。両方のタイプのログは、一元化された Loki インスタンスに送信されます。ここで、クエリを作成し、モニタリング インスタンスでダッシュボードを表示できます。
アクセス制御
アクセス制御とは、アクセスをリクエストするユーザーまたはプロセスの ID に基づいて、リソースへのアクセスを許可または拒否するプロセスです。これにより、データが不正アクセスから保護され、承認されたユーザーのみがシステムを変更できるようになります。GDC では、Kubernetes RBAC を使用してポリシーを宣言し、チケット発行システム アプリケーションで構成されるシステム リソースに対する認可を適用します。
GDC で ProjectRole を定義すると、プリセットの認可ロールを使用して Kubernetes リソースへのきめ細かいアクセス権を付与できます。
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
障害復旧
データベース レプリケーション
障害復旧(DR)の要件を満たすため、複数の GDC インスタンスにわたってプライマリ / セカンダリ構成でチケット発行システムをデプロイします。このモードでは、通常、チケット発行システムへのリクエストはプライマリ サイトに転送され、セカンダリ サイトはデータベースのバイナリログを継続的に複製します。フェイルオーバー イベントが発生すると、セカンダリ サイトが新しいプライマリ サイトに昇格し、リクエストが新しいプライマリに転送されます。
データベース レプリケーション機能に基づいて、設定されたパラメータに基づいて GDC インスタンスごとにプライマリ データベース サーバーとレプリカ データベース サーバーの両方を構成します。
バイナリログの保持期間よりも長く実行されている既存のインスタンスでレプリケーションを有効にするには、データベース バックアップを使用してレプリカ データベースを復元し、プライマリ データベースからレプリケーションを開始します。
プライマリ モードでは、アプリケーション サーバーとデータベースは現在と同じように動作しますが、レプリケーションを有効にするようにプライマリ データベースが構成されます。次に例を示します。
バイナリログを有効にします。
サーバー ID を設定します。
レプリケーション ユーザー アカウントを作成します。
バックアップの作成。
レプリカ モードでは、アプリケーション サーバーはレプリカ データベースに直接接続しないように、チケット発行ウェブサービスを無効にします。レプリカ データベースは、プライマリ データベースからのレプリケーションを開始するように構成する必要があります。例:
サーバー ID を設定します。
レプリケーション ユーザーの認証情報と、ホストやポートなどのプライマリ接続の詳細情報を構成します。
バックアップから復元し、バイナリログの位置を再開します。
データベース レプリケーションでは、レプリカがプライマリ データベースに接続してレプリケーションを開始するために、ネットワーク接続が必要です。レプリケーション用にプライマリ データベース エンドポイントを公開するために、Cloud Service Mesh を使用して、サービス メッシュで TLS 終端をサポートする Ingress サービス メッシュを作成します。これは、チケット発行システムのウェブ アプリケーションで HTTPS データ転送を処理する方法と同様です。