GCP(Google Cloud Platform)에서 Windows Server를 이용해 장애 조치 클러스터를 만들 수 있습니다. 서버 그룹이 함께 작동하여 Windows 애플리케이션에 고가용성(HA)을 제공합니다. 클러스터 노드 하나가 실패하면 다른 노드가 소프트웨어를 이어서 실행합니다. 장애 조치가 자동으로 수행되도록 구성하거나(일반적인 구성) 수동으로 장애 조치를 트리거할 수도 있습니다.
이 튜토리얼은 사용자가 장애 조치 클러스터링, Active Directory(AD), Windows Server 관리에 익숙하다고 가정합니다.
GCP의 네트워킹에 대한 간략한 개요는 GCP가 데이터 센터에 제공하는 장점: 네트워킹을 참조하세요.
아키텍처
이 튜토리얼에서는 Compute Engine에서 예시 장애 조치 클러스터를 만드는 방법을 설명합니다. 예시 시스템에는 다음과 같은 서버 두 개가 있습니다.
- 영역
a에서 Windows Server 2016을 실행하는 기본 Compute Engine VM 인스턴스 - 기본 인스턴스와 일치하도록 영역
b에서 구성된 두 번째 인스턴스
또한 이 튜토리얼에서는 다음 용도로 제공하는 AD 도메인 컨트롤러를 배포합니다.
- Windows 도메인을 제공합니다.
- 호스트 이름을 IP 주소로 확인합니다.
- 클러스터에 필요한 쿼럼을 확보할 때 세 번째 '투표' 역할을 하는 파일 공유 감시를 호스팅합니다.
모든 영역에서 도메인 컨트롤러를 만들 수 있습니다. 이 가이드에서는 c 영역을 사용합니다.
프로덕션 시스템에서는 파일 공유 감시를 다른 곳에서 호스팅할 수 있으며 장애 조치 클러스터만 지원하는 별도의 AD 시스템은 필요 없습니다. GCP에서 AD 사용에 대한 문서 링크는 다음 단계를 참조하세요.
장애 조치 클러스터 배포에 사용할 두 개의 서버는 서로 다른 영역에 위치합니다. 각 서버가 서로 다른 물리적 머신에 있도록 하고 드물게 발생하는 영역 장애로부터 보호하기 위해서입니다.
다음 다이어그램에서는 이 튜토리얼에서 배포하는 아키텍처를 설명합니다.

공유 스토리지 옵션
이 튜토리얼에서는 고가용성 공유 스토리지용 파일 서버 설정을 다루지 않습니다.
Google Cloud 는 다음을 포함하여 Windows Server 장애 조치 클러스터링과 함께 사용할 수 있는 여러 공유 스토리지 솔루션을 지원합니다.
가능한 다른 공유 스토리지 솔루션에 대한 자세한 내용은 다음을 참조하세요.
네트워크 라우팅 이해하기
클러스터를 장애 조치할 때 요청은 새 활성 노드로 이동해야 합니다. 클러스터링 기술은 일반적으로 IP 주소를 MAC 주소와 연결하는 주소 확인 프로토콜(ARP)을 이용해 라우팅을 처리합니다. GCP에서 Virtual Private Cloud(VPC) 시스템은 MAC 주소를 활용하지 않는 소프트웨어 정의 네트워킹을 사용합니다. 따라서 ARP가 브로드캐스트하는 변경사항은 라우팅에 영향을 주지 않습니다. 라우팅을 작동하게 하려면 클러스터에 내부 부하 분산기의 소프트웨어 수준 도움이 필요합니다.
일반적으로 내부 부하 분산은 들어오는 네트워크 트래픽을 VPC 내부의 여러 백엔드 인스턴스로 분산해 부하를 공유합니다. 장애 조치 클러스터링의 경우에는 내부 부하 분산을 사용하여 모든 트래픽을 현재 활성 클러스터 노드인 한 인스턴스로 라우팅합니다. 내부 부하 분산은 다음과 같은 방법으로 올바른 노드를 감지합니다.
- 각 VM 인스턴스는 Windows 장애 조치 클러스터링에 대한 지원을 제공하는 Compute Engine 에이전트 인스턴스를 실행합니다. 에이전트는 VM 인스턴스의 IP 주소를 계속 추적합니다.
- 부하 분산기의 프런트엔드는 들어오는 트래픽의 IP 주소를 애플리케이션에 제공합니다.
- 부하 분산기의 백엔드는 상태 점검을 제공합니다. 상태 점검 프로세스는 특정 포트를 통해 VM 인스턴스의 고정 IP 주소를 사용하여 각 클러스터 노드에서 주기적으로 에이전트를 핑합니다. 기본 포트는 59998입니다.
- 상태 점검은 애플리케이션의 IP 주소를 요청의 페이로드로 포함합니다.
- 에이전트는 요청의 IP 주소를 호스트 VM의 IP 주소 목록과 비교합니다 에이전트가 일치하는 항목을 찾으면 값 1로 응답합니다. 찾지 못하면 0으로 응답합니다.
- 부하 분산기는 상태 점검 결과 정상이라고 판정된 VM을 표시합니다. VM 하나만 워크로드의 IP 주소를 가지므로 언제나 하나의 VM만 상태 점검을 통과하게 됩니다.
장애 조치 중 발생 사항
클러스터에서 장애 조치가 발생하면 다음과 같은 변경 사항이 적용됩니다.
- Windows 장애 조치 클러스터링은 활성 노드의 상태를 변경해 장애가 있음을 표시합니다.
- 장애 조치 클러스터링은 쿼럼에 정의된 대로 장애가 발생한 노드의 클러스터 리소스와 역할 일체를 가장 좋은 노드로 옮깁니다. 이 작업에는 연결된 IP 주소 이전도 포함됩니다.
- 장애 조치 클러스터링 ARP 패킷을 브로드캐스트해 하드웨어 기반 네트워크 라우터에 IP 주소 이전을 알립니다. 이 시나리오에서는 GCP 네트워킹이 이러한 패킷을 무시합니다.
- 이전이 끝나면 장애가 발생한 노드의 VM에 있는 Compute Engine 에이전트가 상태 점검에 대한 응답을 1에서 0으로 변경합니다. VM이 요청에 지정된 IP 주소를 더 이상 호스팅하지 않기 때문입니다.
- 새 활성 노드에 대한 VM의 Compute Engine 에이전트도 상태 점검에 대한 응답을 0에서 1로 변경합니다.
- 내부 부하 분산기는 장애가 발생한 노드로의 트래픽 라우팅을 중지하고 새 활성 노드로 트래픽을 라우팅합니다.
종합
지금까지 몇 가지 기본 개념을 살펴봤습니다. 다음은 아키텍처 다이어그램에서 주목해야 하는 세부정보입니다.
wsfc-2라는 VM의 Compute Engine 에이전트는 활성 클러스터 노드임을 나타내는 값 1로 상태 점검에 응답합니다.wsfc-1의 경우 응답은 0입니다.- 부하 분산기는 화살표로 표시된 것처럼 요청을
wsfc-2로 라우팅합니다. - 부하 분산기와
wsfc-2의 IP 주소는 모두10.0.0.9입니다. 부하 분산기의 경우 이 주소는 지정된 프런트엔드 IP 주소입니다. VM의 경우에는 애플리케이션의 IP 주소입니다. 장애 조치 클러스터는 현재 활성 노드에서 이 IP 주소를 설정합니다. - 장애 조치 클러스터와
wsfc-2의 IP 주소는 모두10.0.0.8입니다. VM은 현재 클러스터 리소스를 호스팅하므로 이 IP 주소를 가집니다.
가이드 진행에 관한 조언
이 튜토리얼은 수많은 단계로 구성되어 있습니다. Microsoft 문서 같은 외부 문서의 단계를 수행해야 할 수도 있습니다. 외부 문서의 단계 수행에 대한 구체적인 정보를 제공하는 이 문서의 참고사항을 꼭 확인하세요.
이 튜토리얼에서는 Google Cloud 콘솔의 Cloud Shell을 사용합니다. Google Cloud 콘솔 사용자 인터페이스 또는 gcloud CLI를 사용하여 장애 조치 클러스터링을 설정할 수도 있지만 이 튜토리얼에서는 사용자 편의를 위해 주로 Cloud Shell이 사용됩니다. 이 방법을 사용하면 가이드를 더 빨리 완료할 수 있습니다. 적절한 경우 일부 단계에서는 대신 Google Cloud 콘솔을 사용합니다.
단계를 진행하는 동안 Compute Engine 영구 디스크 스냅샷을 만드는 것이 좋습니다. 문제 발생 시 스냅샷을 사용하면 처음부터 다시 시작하지 않아도 됩니다. 이 튜토리얼은 스냅샷을 만들기에 적절한 시기를 알려드립니다.
작업이 예상대로 진행되지 않는다면 읽고 있는 섹션에 안내가 있을 것입니다. 그렇지 않다면 문제 해결 섹션을 참조하세요.
목표
- 네트워크를 만듭니다.
- Compute Engine VM 2개에 Windows Server 2016을 설치합니다.
- Windows Server의 세 번째 인스턴스에 Active Directory를 설치하고 구성합니다.
- 쿼럼의 파일 공유 감시와 워크로드의 역할을 포함하는 장애 조치 클러스터를 설정합니다.
- 내부 부하 분산기를 설정합니다.
- 장애 조치 작업을 테스트해 클러스터가 작동하는지 확인합니다.
기본 요건
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Cloud Shell의 인스턴스를 시작합니다.
Cloud Shell로 이동
네트워크 만들기
클러스터에 커스텀 네트워크가 필요합니다. VPC로 Cloud Shell에서 gcloud 명령어를 실행하여 커스텀 네트워크와 서브네트워크 한 개를 만듭니다.
네트워크를 만듭니다.
gcloud compute networks create wsfcnet --subnet-mode custom만든 네트워크의 이름은
wsfcnet입니다.서브네트워크를 만듭니다.
[YOUR_REGION]을 가까운 GCP 리전으로 바꿉니다.gcloud compute networks subnets create wsfcnetsub1 --network wsfcnet --region [YOUR_REGION] --range 10.0.0.0/16만든 서브네트워크의 이름은
wsfcnetsub1입니다.
이 서브네트워크 IP 주소의 CIDR 범위는 10.0.0.0/16이며, 이 가이드에서 사용하는 예시 범위입니다. 프로덕션 시스템에서는 네트워크 관리자와 협력하여 시스템의 IP 주소에 적절한 범위를 할당하세요.
방화벽 규칙 만들기
기본적으로 네트워크는 외부 트래픽을 차단합니다. 서버의 원격 연결을 사용 설정하려면 방화벽에서 포트를 열어야 합니다. Cloud Shell에서 gcloud 명령어를 사용하여 규칙을 만듭니다.
이 튜토리얼에서는 기본 네트워크에서 포트 3389를 열어 RDP 연결을 사용 설정합니다. 다음 명령어에서
[YOUR_IPv4_ADDRESS]를 VM 인스턴스 연결에 사용할 컴퓨터의 IP 주소로 바꿉니다. 프로덕션 시스템에서는 IP 주소 범위 또는 일련의 주소를 제공할 수 있습니다.gcloud compute firewall-rules create allow-rdp --network wsfcnet --allow tcp:3389 --source-ranges [YOUR_IPv4_ADDRESS]서브네트워크에서 모든 포트의 모든 프로토콜을 허용해 서버가 서로 통신할 수 있게 합니다. 프로덕션 시스템에서는 필요에 따라 특정 포트만 여는 것이 좋습니다.
gcloud compute firewall-rules create allow-all-subnet --network wsfcnet --allow all --source-ranges 10.0.0.0/16source-ranges값은 서브네트워크를 만들 때 사용한 CIDR 범위와 일치합니다.방화벽 규칙을 확인합니다.
gcloud compute firewall-rules list다음과 비슷한 출력이 표시됩니다.
NAME NETWORK DIRECTION PRIORITY ALLOW DENY DISABLED allow-all-subnet wsfcnet INGRESS 1000 all False allow-rdp wsfcnet INGRESS 1000 tcp:3389 False
Compute Engine에서 장애 조치 클러스터링 사용 설정
Compute Engine 에이전트에서 장애 조치 클러스터링을 사용 설정하려면 Compute Engine 문서의 설명처럼 VM의 커스텀 메타데이터로 enable-wsfc=true 플래그를 지정하거나 각 VM에 구성 파일을 만들어 VM 정의에 플래그를 추가해야 합니다.
이 튜토리얼에서는 다음 섹션의 설명처럼 VM이 생성될 때 이 플래그를 커스텀 메타데이터로 정의합니다. 또한 이 가이드에서는 wsfc-addrs 및 wsfc-agent-port 기본 동작을 사용하므로 이러한 값을 설정할 필요가 없습니다.
서버 만들기
다음 단계에서는 서버 3개를 만듭니다. Cloud Shell에서 gcloud 명령어를 사용합니다.
첫 번째 클러스터 노드 서버 만들기
새 Compute Engine 인스턴스를 만드세요. 다음과 같이 인스턴스를 구성합니다.
- 인스턴스 이름을
wsfc-1로 지정합니다. --zone플래그를 개발자와 가까운 영역으로 설정합니다. 예를 들면us-central1-a입니다.--machine-type플래그를n1-standard-2.로 설정합니다.--image-project플래그를windows-cloud로 설정합니다.--image-family플래그를windows-2016으로 설정합니다.--scopes플래그를https://www.googleapis.com/auth/compute로 설정합니다.--can-ip-forward플래그를 설정하여 IP 전달을 사용 설정합니다.--private-network-ip플래그를10.0.0.4로 설정합니다.- 네트워크를
wsfcnet으로 설정하고 서브네트워크를wsfcnetsub1로 설정합니다. --metadata매개변수를 사용하여enable-wsfc=true를 설정합니다.
다음 명령어를 실행합니다. 이 때 [YOUR_ZONE_1]을 첫 번째 영역의 이름으로 바꿉니다.
gcloud compute instances create wsfc-1 --zone [YOUR_ZONE_1] --machine-type n1-standard-2 --image-project windows-cloud --image-family windows-2016 --scopes https://www.googleapis.com/auth/compute --can-ip-forward --private-network-ip 10.0.0.4 --network wsfcnet --subnet wsfcnetsub1 --metadata enable-wsfc=true
두 번째 클러스터 노드 서버 만들기
두 번째 서버에서도 같은 단계를 반복합니다. 하지만 다음 예외를 적용합니다.
- 인스턴스 이름을
wsfc-2로 설정합니다. --zone플래그를 첫 번째 서버에 사용한 영역과 다른 영역으로 설정합니다. 예를 들면us-central1-b입니다.--private-network-ip플래그를10.0.0.5로 설정합니다.
[YOUR_ZONE_2]를 두 번째 영역 이름으로 바꿉니다.
gcloud compute instances create wsfc-2 --zone [YOUR_ZONE_2] --machine-type n1-standard-2 --image-project windows-cloud --image-family windows-2016 --scopes https://www.googleapis.com/auth/compute --can-ip-forward --private-network-ip 10.0.0.5 --network wsfcnet --subnet wsfcnetsub1 --metadata enable-wsfc=true
Active Directory용 세 번째 서버 만들기
도메인 컨트롤러의 경우에는 동일한 단계를 수행합니다. 하지만 다음 예외를 적용합니다.
- 인스턴스 이름을
wsfc-dc로 설정합니다. --zone플래그를 다른 서버에 사용한 영역과 다른 영역으로 설정합니다. 예를 들면us-central1-c입니다.--private-network-ip플래그를10.0.0.6으로 설정합니다.--metadata enable-wsfc=true를 생략합니다.
[YOUR_ZONE_3]을 개발자 영역 이름으로 바꿉니다.
gcloud compute instances create wsfc-dc --zone [YOUR_ZONE_3] --machine-type n1-standard-2 --image-project windows-cloud --image-family windows-2016 --scopes https://www.googleapis.com/auth/compute --can-ip-forward --private-network-ip 10.0.0.6 --network wsfcnet --subnet wsfcnetsub1
인스턴스 보기
생성한 인스턴스의 세부정보를 확인할 수 있습니다.
gcloud compute instances list
다음과 비슷한 출력이 표시됩니다.
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS wsfc-1 us-central1-a n1-standard-2 10.0.0.4 35.203.131.133 RUNNING wsfc-2 us-central1-b n1-standard-2 10.0.0.5 35.203.130.194 RUNNING wsfc-dc us-central1-c n1-standard-2 10.0.0.6 35.197.27.2 RUNNING
VM에 연결
Windows 기반 VM에 연결하려면 먼저 VM의 비밀번호를 생성해야 합니다. 그런 다음 RDP를 사용하여 VM에 연결할 수 있습니다.
비밀번호 생성
Google Cloud 콘솔에서 VM 인스턴스 페이지로 이동합니다.
새 비밀번호가 필요한 VM 인스턴스의 이름을 클릭합니다.
인스턴스 세부정보 페이지에서 Windows 비밀번호 설정 버튼을 클릭합니다. 비밀번호가 자동으로 생성됩니다. 비밀번호를 복사하여 안전한 곳에 보관합니다.
RDP를 통한 연결
Compute Engine 문서에서 RDP를 사용하여 Windows VM 인스턴스에 연결하는 방법을 확인할 수 있습니다. 다음 방법 중 하나를 이용하세요.
- 기존 클라이언트를 사용합니다.
- 브라우저에 Chrome RDP 플러그인을 추가한 후Google Cloud 콘솔을 통해 연결합니다.
이 가이드에서 Windows 인스턴스에 연결하라고 할 때마다 기본 RDP 연결을 사용합니다.
Windows 네트워킹 구성
VM을 만들 때 할당한 내부 IP 주소는 고정 IP 주소입니다. Windows에서 이 IP 주소가 고정 주소로 취급되게 하려면 기본 게이트웨이 및 DNS 서버의 IP 주소와 함께 이 주소를 Windows Server 네트워킹 구성에 추가해야 합니다.
RDP를 사용하여 wsfc-1, wsfc-2, wsfc-dc에 연결하고 각 인스턴스에 다음 단계를 반복해서 수행합니다.
- 서버 관리자의 왼쪽 창에서 로컬 서버를 선택합니다.
- 속성 창의 이더넷 항목에서 DHCP에 의해 할당된 IPv4 주소, IPv6 사용 가능을 클릭합니다.
- 이더넷을 마우스 오른쪽 버튼으로 클릭하고 속성을 선택합니다.
- 인터넷 프로토콜 버전 4(TCP/IPv4)를 더블클릭합니다.
- 다음 IP 주소 사용을 선택합니다.
VM을 만들 때 VM에 할당한 내부 IP 주소를 입력합니다.
wsfc-1에 '10.0.0.4'를 입력합니다.wsfc-2에 '10.0.0.5'를 입력합니다.wsfc-dc에 '10.0.0.6'을 입력합니다.
서브넷 마스크에 '255.255.0.0'을 입력합니다.
기본 게이트웨이에
10.0.0.1을 입력합니다. 이 IP 주소는 서브넷wsfcnetsub1을 만들 때 기본 게이트웨이용으로 자동 예약된 주소입니다.기본 게이트웨이의 IP 주소는 항상 서브넷의 기본 IP 범위에서 두 번째 주소입니다. IPv4 서브넷 범위의 사용할 수 없는 주소를 참조하세요.
wsfc-1과wsfc-2에 한해 다음을 수행합니다.다음 DNS 서버 주소 사용을 클릭합니다.
기본 설정 DNS 서버에 '10.0.0.6'을 입력합니다.
모든 대화상자를 닫습니다.
이 변경사항은 VM 인스턴스의 가상 네트워크 어댑터를 재설정하기 때문에 RDP 연결이 끊어집니다.
RDP 세션을 닫고 인스턴스에 다시 연결합니다. 이전 단계의 대화상자가 아직 열려 있으면 닫습니다.
로컬 서버의 속성 섹션에서 이더넷 설정에 로컬 서버 IP 주소(
10.0.0.4,10.0.0.5,또는10.0.0.6)가 반영되었는지 확인합니다. 반영되지 않았으면 인터넷 프로토콜 버전 4(TCP/IPv4) 대화상자를 다시 열고 설정을 업데이트합니다.
이제 wsfc-1과 wsfc-2의 스냅샷을 만들면 됩니다.
Active Directory 설정
이제 도메인 컨트롤러를 설정합니다.
- RDP를 사용하여
wsfc-dc라는 서버에 연결합니다. - Windows 컴퓨터 관리 데스크톱 앱을 사용하여 로컬 관리자 계정의 비밀번호를 설정합니다.
- 로컬 관리자 계정을 사용 설정합니다.
아래의 Microsoft 안내에 나온 단계와 이 추가 참고사항을 따라 도메인 컨트롤러를 설정합니다. 대부분의 설정에는 기본값을 사용하면 됩니다.
- DNS 서버 역할 체크박스를 선택합니다. 이 단계는 안내에서 따로 설명하지 않습니다.
- 필요한 경우 자동으로 대상 서버 다시 시작 체크박스를 선택합니다.
- 파일 서버를 도메인 컨트롤러로 승격합니다.
- 새 포리스트 추가 단계에서 도메인 이름을 'WSFC.TEST'로 지정합니다.
- NetBIOS 도메인 이름을 'WSFC'(기본값)로 설정합니다.
이제 wsfc-dc의 스냅샷을 만들면 됩니다.
도메인 사용자 계정 만들기
wsfc-dc를 다시 시작하는 데 시간이 걸릴 수 있습니다. 서버를 도메인에 조인하기 전에 RDP로 wsfc-dc에 로그인하여 도메인 컨트롤러가 실행 중인지 확인합니다.
클러스터 서버의 관리자 권한이 있는 도메인 사용자가 필요합니다. 방법은 다음과 같습니다.
- 도메인 컨트롤러(
wsfc-dc)에서 시작을 클릭하고 dsa를 입력한 후 Active Directory 사용자 및 컴퓨터 앱을 찾아 엽니다. - WSFC.TEST를 마우스 오른쪽 버튼으로 클릭하고 신규를 가리킨 후 사용자를 클릭합니다.
- 전체 이름과 사용자 로그온 이름에
cluster-admin을 입력합니다. - 다음을 클릭합니다.
- 사용자 비밀번호를 입력하고 확인합니다. 대화상자에서 비밀번호 옵션을 선택합니다. 예를 들어 비밀번호가 만료되지 않도록 설정할 수도 있습니다.
- 설정을 확인한 후 완료를 클릭합니다.
cluster-admin을wsfc-dc의 관리자로 지정합니다.cluster-admin을 마우스 오른쪽 버튼으로 클릭하고 그룹에 추가를 선택합니다.- Administrators를 입력하고 확인을 클릭합니다.
이 튜토리얼에서는 관리자 계정이 필요할 때마다 WSFC.TEST\cluster-admin 계정을 관리자 계정으로 사용합니다. 프로덕션 시스템에서는 계정 및 권한 할당에 대한 일반적인 보안 관행을 따릅니다. 자세한 내용은 장애 조치 클러스터에 필요한 Active Directory 계정 개요를 참조하세요.
서버를 도메인에 조인
클러스터 노드 서버 두 개를 WSFC.TEST 도메인에 추가합니다. 각 클러스터 노드 서버(wsfc-1 및 wsfc-2)에서 다음 단계를 수행합니다.
- 서버 관리자 > 로컬 서버의 속성 창에서 작업 그룹을 클릭합니다.
- 변경을 클릭합니다.
- 도메인을 선택하고 'WSFC.TEST'를 입력합니다.
- 확인을 클릭합니다.
WSFC.TEST\cluster-admin의 사용자 인증 정보를 입력하여 도메인에 조인합니다.- 확인을 클릭합니다.
- 대화상자를 닫고 표시되는 메시지를 따라 서버를 다시 시작합니다.
서버 관리자에서
cluster-admin을wsfc-1과wsfc-2의 관리자로 지정합니다. 또는 그룹 정책을 사용하여 관리자 권한을 관리할 수 있습니다.- 도구 메뉴에서 컴퓨터 관리 > 로컬 사용자 및 그룹 > 그룹 > 관리자를 선택하고 추가를 클릭합니다.
- 'cluster-admin'을 입력하고 이름 확인을 클릭합니다.
- 확인을 클릭합니다.
이제 세 VM의 스냅샷을 만들면 됩니다.
장애 조치 클러스터링 설정
Compute Engine에서 클러스터의 IP 주소 예약
장애 조치 클러스터를 만들 때 관리 액세스 포인트를 만들 IP 주소를 할당합니다. 프로덕션 환경에서는 별도 서브넷의 IP 주소를 사용할 수 있습니다. 하지만 이 튜토리얼에서는 이미 만든 서브넷의 IP 주소를 예약합니다. IP 주소를 예약하면 다른 IP 할당과의 충돌이 방지됩니다.
호스트 VM에서 터미널을 열거나 Cloud Shell을 엽니다.
IP 주소를 예약합니다. 이 튜토리얼에서는
10.0.0.8을 사용합니다.gcloud compute addresses create cluster-access-point --region [YOUR_REGION] --subnet wsfcnetsub1 --addresses 10.0.0.8
IP 주소 예약을 확인하려면 다음 명령어를 실행합니다.
gcloud compute addresses list
클러스터 만들기
장애 조치 클러스터 만들고 구성하려면 다음 안내를 따르세요.
- RDP를 사용하여
wsfc-1과wsfc-2를 연결합니다. 아래의 Microsoft 안내에 나온 단계와 이 추가 참고사항을 따릅니다.
wsfc-1과wsfc-2에 장애 조치 클러스터링 기능을 설치합니다.wsfc-dc에는 장애 조치 클러스터링 기능을 설치하지 마세요.- 도메인 사용자
WSFC.TEST\cluster-admin으로 장애 조치 클러스터 관리자 앱을 실행합니다. 그렇지 않으면 권한 문제가 발생할 수 있습니다. 필요한 권한을 갖도록 항상 이러한 방법으로 장애 조치 클러스터 관리자를 실행하거나cluster-admin으로 서버에 연결하는 것이 좋습니다. wsfc-1과wsfc-2를 클러스터에 노드로 추가합니다.구성 유효성을 검사할 때 다음을 수행합니다.
- 테스트 옵션 페이지에서 선택한 테스트만 실행을 선택하고 다음을 클릭합니다.
테스트 선택 페이지에서 저장소를 지워야 합니다. (별도의 독립형 물리적 서버에서처럼) Compute Engine에서 실행하면 저장소 옵션이 실패하기 때문입니다.
클러스터 유효성 검사 중에 발생하는 일반적인 문제는 다음과 같습니다.
- 복제본 간의 네트워크 인터페이스가 하나뿐입니다. 클라우드 기반 설치에는 적용되지 않으므로 이 문제는 무시해도 됩니다.
- Windows 업데이트가 두 복제본에서 동일하지 않습니다. 업데이트를 자동으로 적용하도록 Windows 인스턴스를 구성했다면 한 노드가 다운로드하지 못한 업데이트를 다른 노드는 이미 적용했을 수도 있습니다. 모든 서버는 구성이 동일해야 합니다.
- 재부팅이 대기 중입니다. 서버 변경사항은 재부팅해야 적용됩니다. 이 문제는 무시해선 안 됩니다.
- 서버의 도메인 역할이 동일하지 않습니다. 이 문제는 무시해도 됩니다.
- 모든 서버가 동일한 조직 단위(OU)에 있지 않습니다. 이 튜토리얼에서는 OU를 전혀 사용하지 않지만 프로덕션 시스템에서는 클러스터를 자체 OU에 넣는 것이 좋습니다. 이 권장사항은 Microsoft 안내에 설명되어 있습니다.
- 서명되지 않은 드라이버가 발견되었습니다. 이 문제는 무시해도 됩니다.
요약 페이지에서 마법사를 닫고 다시 여는 대신 검증된 노드를 사용하여 지금 클러스터 만들기를 선택해 클러스터를 계속 생성할 수 있습니다.
클러스터 만들기 마법사의 액세스 포인트 페이지에서 다음을 수행합니다.
- 클러스터 이름을 'testcluster'로 지정합니다.
- 이전에 예약한 IP 주소
10.0.0.8을 주소 필드에 입력합니다.
클러스터 관리자 추가
도메인 계정을 클러스터의 관리자로 추가하면 Windows PowerShell과 같은 도구에서 클러스터 관련 작업을 수행할 수 있습니다. cluster-admin 도메인 계정을 클러스터 관리자로 추가합니다.
- 클러스터 리소스를 호스팅하는 클러스터 노드의 장애 조치 클러스터 관리자에서, 왼쪽 창에서는 클러스터를 선택하고 오른쪽 창에서는 속성을 클릭합니다.
- 클러스터 사용 권한 탭을 선택합니다.
- 추가를 클릭한 후
cluster-admin을 추가합니다. - 그룹 또는 사용자 이름 목록에서
cluster-admin을 선택한 상태에서 권한 창의 모든 권한을 선택합니다. - 적용과 확인을 클릭합니다.
이제 스냅샷을 만들면 됩니다.
파일 공유 감시 만들기
노드가 2개인 장애 조치 클러스터가 있지만 클러스터는 투표 메커니즘을 이용해 활성화할 노드를 결정합니다. 쿼럼 확보를 위해 파일 공유 감시를 추가할 수 있습니다.
이 튜토리얼은 공유 폴더만 도메인 컨트롤러 서버에 추가합니다. 클러스터 노드 중 하나가 재시작할 때 서버가 오프라인이 되면 나머지 서버는 자체적으로 투표할 수 없기 때문에 전체 클러스터가 중단되기도 합니다. 이 튜토리얼에서는 라이브 마이그레이션이나 자동으로 다시 시작과 같은 GCP 인프라 기능이 공유 폴더를 유지하는 데 충분한 안정성을 제공한다고 가정합니다.
한층 더 가용성이 높은 파일 공유 감시를 만들고 싶다면 다음과 같은 방법이 있습니다.
- Storage Spaces Direct를 사용하여 Windows Server의 클러스터로 공유를 제공하세요. 이 Windows Server 2016 기능은 쿼럼 감시에 가용성이 높은 공유를 제공할 수 있습니다. 예를 들어 Active Directory 도메인 컨트롤러용 클러스터를 만들면 가용성이 높은 도메인 서비스와 파일 공유 감시를 동시에 제공할 수 있습니다.
- 동기 또는 비동기 복제에 Windows 장애 조치 서버 클러스터링과 함께 SIOS Datakeeper와 같은 데이터 복제 소프트웨어를 사용합니다.
다음 단계를 따라 감시를 위한 파일 공유를 만듭니다.
wsfc-dc에 연결합니다. 이 서버는 파일 공유를 호스팅합니다.- 탐색기에서
C드라이브를 찾습니다. - 제목 표시줄에서 새 폴더 버튼을 클릭합니다.
- 새 폴더 이름을
shares로 지정합니다. shares폴더를 더블클릭하여 엽니다.- 새 폴더를 추가하고 이름을
clusterwitness-testcluster로 지정합니다.
파일 공유 감시를 위한 공유 구성
클러스터가 사용할 수 있도록 파일 공유 감시 폴더에 대한 권한을 설정해야 합니다.
- 탐색기에서
clusterwitness-testcluster폴더를 마우스 오른쪽 버튼으로 클릭하고 속성을 선택합니다. - 공유 탭에서 고급 공유를 클릭합니다.
- 이 폴더 공유를 선택합니다.
- 권한을 클릭한 다음 추가를 클릭합니다.
- 객체 유형에서 컴퓨터를 선택한 후 확인을 클릭합니다.
- 머신 계정
testcluster$를 추가합니다. testcluster$에 모든 권한을 부여합니다.- 적용을 클릭한 후 모든 대화상자를 닫습니다.
장애 조치 클러스터에 파일 공유 감시 추가
이제 파일 공유 감시를 쿼럼 투표로 사용하도록 장애 조치 클러스터를 구성합니다.
- 클러스터 리소스(
wsfc-1)를 호스팅하는 컴퓨터에서 장애 조치 클러스터 관리자를 엽니다. - 왼쪽 창에서 클러스터 이름(testcluster.WSFC.TEST)을 마우스 오른쪽 버튼으로 클릭하고 추가 작업을 가리킨 후 클러스터 쿼럼 설정 구성을 클릭합니다.
- 쿼럼 구성 옵션 선택 패널에서 쿼럼 감시 선택을 선택합니다.
- 쿼럼 감시 선택 패널에서 파일 공유 감시 구성을 선택합니다.
- 파일 공유 경로에 공유 폴더 경로를 입력합니다(예:
\\wsfc-dc\clusterwitness-testcluster). - 설정을 확인한 후 완료를 클릭합니다.
장애 조치 클러스터 테스트
이제 Windows Server 장애 조치 클러스터가 작동할 것입니다. 인스턴스 간의 클러스터 리소스 이동을 수동으로 테스트할 수 있습니다. 아직 작업이 완료되지 않았지만 이 시점에서 지금까지 한 모든 작업이 정상적으로 작동하는지 확인합니다.
wsfc-1의 장애 조치 클러스터 관리자에서 현재 호스트 서버 이름을 확인합니다.cluster-admin으로 Windows PowerShell을 실행합니다.PowerShell에서 다음 명령어를 실행하여 현재 호스트 서버를 변경합니다.
Move-ClusterGroup -Name "Cluster Group"
현재 호스트 서버의 이름이 다른 VM으로 변경되어야 합니다.
문제가 해결되지 않으면 이전 단계를 검토하여 놓친 부분이 있는지 확인하세요. 가장 흔한 문제는 네트워크 액세스를 차단하는 방화벽 규칙이 없는 것입니다. 다른 문제를 확인하고 싶다면 문제 해결 섹션을 참조하세요.
클러스터의 현재 호스트 서버로 네트워크 트래픽을 라우팅하는 데 필요한 내부 부하 분산기 설정으로 이동할 수도 있습니다.
이제 스냅샷을 만들면 됩니다.
장애 조치 클러스터에 역할 추가
Windows 장애 조치 클러스터링에서 역할은 클러스터링된 워크로드를 호스팅합니다. 역할을 이용해 애플리케이션이 사용하는 IP 주소를 클러스터에 지정할 수 있습니다. 이 튜토리얼에서는 인터넷 정보 서비스(IIS) 웹 서버인 테스트 워크로드를 위한 역할을 추가하고 이 역할에 IP 주소를 할당합니다.
Compute Engine에서 역할의 IP 주소 예약
Compute Engine의 서브넷 내에서 IP 주소 충돌을 방지하려면 역할의 IP 주소를 예약하세요.
호스트 VM에서 터미널을 열거나 Cloud Shell을 엽니다.
IP 주소를 예약합니다. 이 튜토리얼에서는
10.0.0.9을 사용합니다.gcloud compute addresses create load-balancer-ip --region [YOUR_REGION] --subnet wsfcnetsub1 --addresses 10.0.0.9
IP 주소 예약을 확인하려면 다음 명령어를 실행합니다.
gcloud compute addresses list
역할 추가
방법은 다음과 같습니다.
- 장애 조치 클러스터 관리자의 작업 창에서 역할 구성을 선택합니다.
- 역할 선택 페이지에서 다른 서버를 선택합니다.
- 클라이언트 액세스 포인트 페이지에서 이름을
IIS로 입력합니다. - 주소를
10.0.0.9로 설정합니다. - 스토리지 선택 및 리소스 종류 선택을 건너뜁니다.
- 설정을 확인한 후 완료를 클릭합니다.
내부 부하 분산기 만들기
네트워크 트래픽을 활성 클러스터 호스트 노드로 라우팅하는 데 필요한 내부 부하 분산기를 만들고 구성합니다. 사용자 인터페이스를 통해 내부 부하 분산이 어떻게 구성되는지 쉽게 확인할 수 있기 때문에Google Cloud 콘솔을 사용합니다.
또한 부하 분산기가 클러스터 노드 관리에 사용하는 Compute Engine 인스턴스 그룹을 클러스터의 각 영역에 만듭니다.
인스턴스 그룹 만들기
클러스터 노드가 포함된 각 영역에 인스턴스 그룹을 만든 후 각 노드를 영역의 인스턴스 그룹에 추가합니다.
인스턴스 그룹에 도메인 컨트롤러 wsfc-dc를 추가하지 마세요.
클러스터의 각 영역에 인스턴스 그룹을 만들고
[ZONE_1]을 첫 번째 영역의 이름으로,[ZONE_2]를 두 번째 영역의 이름으로 바꿉니다.gcloud compute instance-groups unmanaged create wsfc-group-1 --zone=[ZONE_1]
gcloud compute instance-groups unmanaged create wsfc-group-2 --zone=[ZONE_2]
각 영역의 서버를 해당 영역의 인스턴스 그룹에 추가합니다.
gcloud compute instance-groups unmanaged add-instances wsfc-group-1 --instances wsfc-1 --zone [ZONE_1]
gcloud compute instance-groups unmanaged add-instances wsfc-group-2 --instances wsfc-2 --zone [ZONE_2]
인스턴스 그룹이 만들어졌고 각 그룹에 하나의 인스턴스가 포함되어 있는지 확인합니다.
gcloud compute instance-groups unmanaged list
NAME ZONE NETWORK NETWORK_PROJECT MANAGED INSTANCES wsfc-group-1 us-central1-a wsfcnet exampleproject No 1 wsfc-group-2 us-central1-b wsfcnet exampleproject No 1
부하 분산기 만들기
구성 시작
Google Cloud 콘솔에서 부하 분산 페이지로 이동합니다.
- 부하 분산기 만들기를 클릭합니다.
- 부하 분산기 유형에 네트워크 부하 분산기(TCP/UDP/SSL)를 선택하고 다음을 클릭합니다.
- 프록시 또는 패스 스루에서 패스 스루 부하 분산기를 선택하고 다음을 클릭합니다.
- 공개 또는 내부에서 내부를 선택하고 다음을 클릭합니다.
- 구성을 클릭합니다.
기본 구성
- 이름에는 'wsfc-lb'를 입력합니다.
- 현재 리전을 선택합니다.
wsfcnet을 네트워크로 선택합니다.
백엔드 구성
기억하시겠지만 GCP 내부 부하 분산기는 정기적인 상태 점검으로 활성 노드를 결정합니다. 상태 점검은 활성 클러스터 노드에서 실행 중인 Compute Engine 클러스터 호스트 에이전트를 핑합니다. 상태 점검 페이로드는 클러스터링된 역할로 표시되는 애플리케이션의 IP 주소입니다. 에이전트는 노드가 활성 상태이면 값 1로, 활성 상태가 아니라면 0으로 응답합니다.
- 백엔드 구성을 클릭합니다.
- 백엔드에서 만든 각 인스턴스 그룹의 이름을 선택하고 완료를 클릭하여 인스턴스 그룹을 추가합니다.
상태 점검을 만듭니다.
- 이름에는 'wsfc-hc'를 입력합니다.
- TCP의 기본 프로토콜 설정을 수락하고 클러스터 호스트 에이전트 응답 포트를 '59998'로 변경합니다.
- 요청에는 '10.0.0.9'를 입력합니다.
- 응답에는 '1'을 입력합니다.
- 확인 간격에는 '2'를 입력합니다.
- 제한 시간에는 '1'을 입력합니다.
- 저장 후 계속을 클릭합니다.
프런트엔드 구성
프런트엔드 구성은 부하 분산기가 들어오는 요청을 처리하는 방법을 정의하는 전달 규칙을 만듭니다. 이 튜토리얼에서는 쉽게 설명하기 위해 하위 네트워크의 VM 간에 요청을 전송해 시스템을 테스트합니다.
프로덕션 시스템에서는 시스템을 인터넷 트래픽 같은 외부 트래픽에 개방할 수도 있습니다. 이렇게 하려면 외부 트래픽을 수락하고 내부 네트워크로 전달하는 배스천 호스트를 만들어야 합니다. 배스천 호스트 사용 방법은 이 가이드에서 다루지 않습니다.
- 가운데 창에서 프런트엔드 구성을 클릭합니다.
- 이름에 'wsfc-lb-fe'를 입력합니다.
- 서브네트워크(
wsfcnetsub1)를 선택합니다. - 내부 IP에 load-balancer-ip(10.0.0.9)를 선택합니다. 이것은 역할에 설정한 것과 동일한 IP 주소입니다
- 포트에는 '80'을 입력합니다.
- 완료를 클릭합니다.
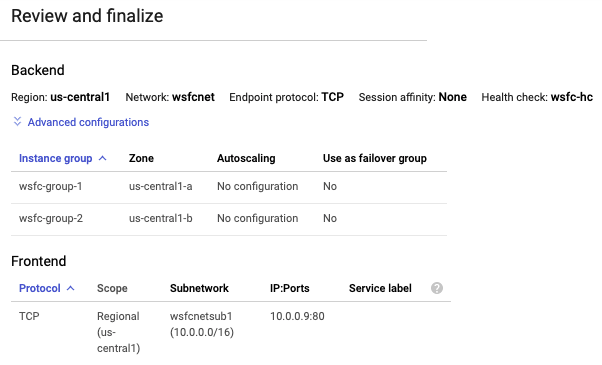
검토 및 완료
- 내부 부하 분산기 설정 요약을 보려면 가운데 창에서 검토 및 완료를 클릭합니다. 요약은 오른쪽 창에 표시됩니다.
만들기를 클릭합니다. 부하 분산기를 만드는 데는 시간이 다소 걸립니다.
상태 확인용 방화벽 규칙 만들기
상태 점검 시스템이 해당 대상에 상태 점검을 수행할 수 있도록 방화벽 규칙이 필요하다는 알림이 Google Cloud 콘솔에 표시되었을 수 있습니다. 이 섹션에서는 방화벽 규칙을 설정합니다.
Google Cloud 콘솔에서 Cloud Shell로 이동합니다.
다음 명령어를 실행해 방화벽 규칙을 만듭니다.
gcloud compute firewall-rules create allow-health-check --network wsfcnet --source-ranges 130.211.0.0/22,35.191.0.0/16 --allow tcp:59998
Windows 방화벽 열기
클러스터 노드 wsfc-1과 wsfc-2에서 각각 부하 분산기의 Windows 시스템 액세스를 허용하는 방화벽 규칙을 Windows 방화벽에 만듭니다.
고급 보안 앱으로 Windows 방화벽을 엽니다.
왼쪽 탐색창에서 인바운드 규칙을 선택합니다.
오른쪽 탐색창에서 새 규칙을 선택합니다.
규칙 종류 패널에서 커스텀을 규칙 유형으로 선택하고 다음을 클릭합니다.
프로그램 패널에서 기본값을 그대로 사용하고 다음을 클릭합니다.
프로토콜 및 포트 패널에서 다음을 수행합니다.
- 프로토콜 종류: 필드에서 TCP를 선택합니다.
- 로컬 포트: 필드에서 특정 포트를 선택하고
59998을 입력합니다.
범위 패널의 이 규칙이 적용되는 원격 IP 주소에서 다음을 수행합니다.
- 다음 IP 주소:를 선택합니다.
추가를 클릭하여 다음 IP 주소 각각을 다음 IP 주소 또는 서브넷에 추가합니다.
130.211.0.0/2235.191.0.0/16
다음을 클릭합니다.
작업 패널에서 연결 허용을 수락하고 다음을 클릭합니다.
프로필 패널에서 기본값을 그대로 사용하고 다음을 클릭합니다.
방화벽 규칙 이름을 지정하고 완료를 클릭합니다.
부하 분산기 유효성 검사
내부 부하 분산기를 실행하면 상태를 검사해 정상 인스턴스를 찾을 수 있는지 확인한 후 장애 조치를 다시 테스트할 수 있습니다.
Google Cloud 콘솔에서 부하 분산 페이지로 이동합니다.
부하 분산기 이름(
wsfc-lb)을 클릭합니다.요약의 백엔드 섹션에 인스턴스 그룹 목록이 나열되어야 합니다.
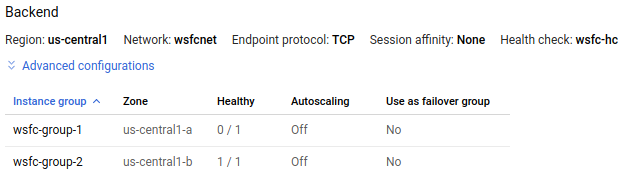
wsfc-lb부하 분산기 세부정보 페이지의 다음 이미지에 있는 인스턴스 그룹wsfc-group-1의 정상 열에 1 / 1로 표시된 활성 노드가 포함되어 있습니다. 인스턴스 그룹wsfc-group-2에는 0 / 1로 표시된 비활성 노드가 포함되어 있습니다.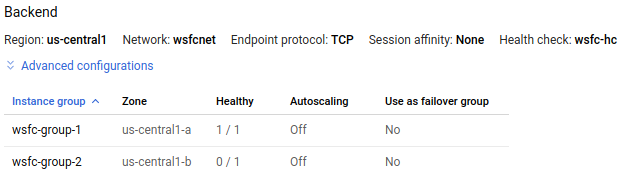
두 인스턴스 그룹 모두 0 / 1이 표시되는 경우 부하 분산기가 아직 노드와 동기화 중일 수 있습니다. 부하 분산기가 IP 주소를 찾도록 하려면 장애 조치 작업을 한 번 이상 수행해야 할 수도 있습니다.
장애 조치 클러스터 관리자에서 클러스터 이름을 확장하고 역할을 클릭합니다. 소유자 노드 열에서 IIS 역할의 서버 이름을 확인합니다.
IIS 역할을 마우스 오른쪽 버튼으로 클릭하고 이동 > 가장 적합한 노드를 선택하여 장애 조치를 시작합니다. 이 작업은 소유자 노드 열과 같이 역할을 다른 노드로 이동합니다.
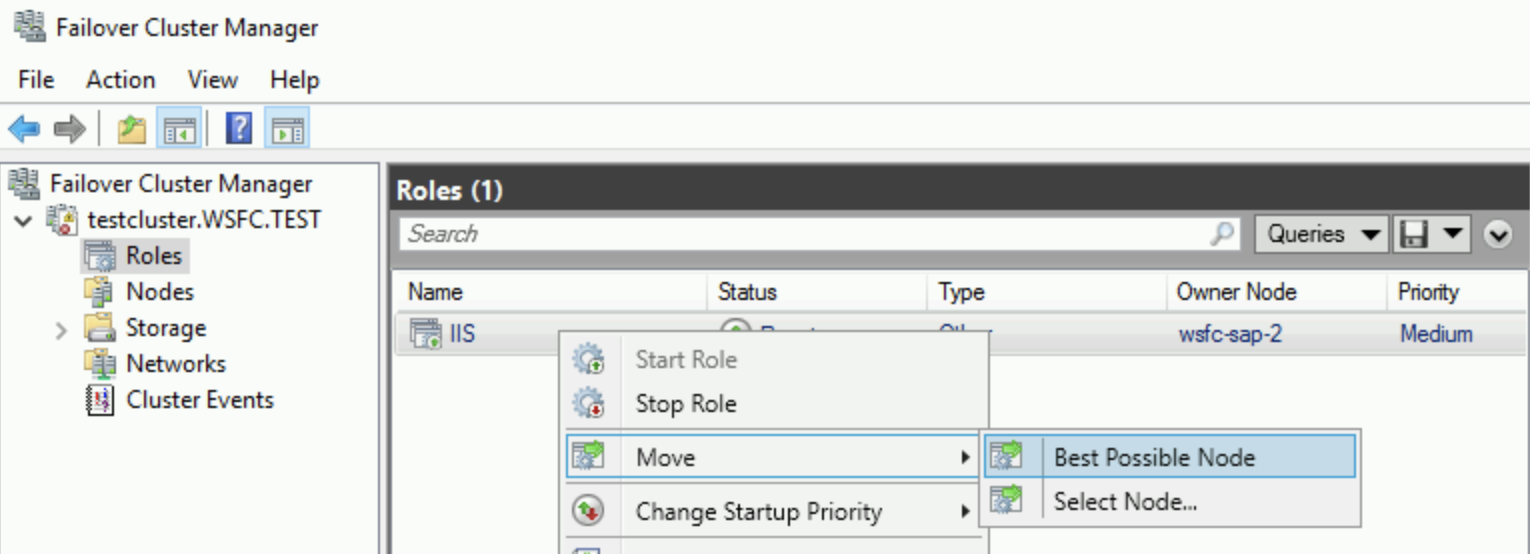
상태가 실행 중으로 표시될 때까지 기다립니다.
부하 분산기 세부정보 페이지로 돌아와 새로고침을 클릭하고 정상 열의 1 / 1 및 0 / 1 값이 인스턴스 그룹을 전환했는지 확인합니다.
gcloud compute backend-services get-health wsfc-lb --region=[REGION]
출력은 다음과 같이 표시됩니다.
backend: https://compute.googleapis.com/compute/v1/projects/exampleproject/zones/us-central1-a/instanceGroups/wsfc-group-1
status:
healthStatus:
- healthState: HEALTHY
instance: https://compute.googleapis.com/compute/v1/projects/exampleproject/zones/us-central1-a/instances/wsfc-1
ipAddress: 10.0.0.4
port: 80
kind: compute#backendServiceGroupHealth
---
backend: https://compute.googleapis.com/compute/v1/projects/exampleproject/zones/us-central1-b/instanceGroups/wsfc-group-2
status:
healthStatus:
- healthState: UNHEALTHY
instance: https://compute.googleapis.com/compute/v1/projects/exampleproject/zones/us-central1-b/instances/wsfc-2
ipAddress: 10.0.0.5
port: 80
kind: compute#backendServiceGroupHealth애플리케이션 설치
이제 클러스터가 있으므로 각 노드에서 애플리케이션을 설정하고 클러스터링된 환경에서 실행되도록 구성할 수 있습니다.
이 튜토리얼에서는 클러스터가 내부 부하 분산기와 실제로 작업 중임을 보여주는 항목을 설정해야 합니다. 각 VM에 IIS를 설정해 간단한 웹페이지를 제공하세요.
클러스터의 HA용 IIS는 설정하지 않습니다. 각각 다른 웹페이지를 제공하는 별도의 IIS 인스턴스를 만들게 됩니다. 장애 조치가 끝나면 웹 서버는 공유 콘텐츠가 아닌 자체 콘텐츠를 제공합니다.
HA용 애플리케이션 또는 IIS 설정은 이 튜토리얼에서 다루지 않습니다.
IIS 설정
각 클러스터 노드에 IIS를 설치합니다.
- 역할 서비스 선택 페이지의 일반 HTTP 기능에서 기본 문서가 선택되어 있는지 확인합니다.
- 확인 페이지에서 대상 서버 자동 다시 시작을 사용 설정하는 체크박스를 선택합니다.
각 웹 서버가 작동하는지 확인합니다.
- RDP를 사용하여
wsfc-dc라는 VM에 연결합니다. - 서버 관리자에서 창 왼쪽의 탐색창에서 로컬 서버를 클릭합니다.
- 상단의 속성 섹션에서 IE 보안 강화 구성을 사용 중지합니다.
- Internet Explorer를 엽니다.
각 서버의 IP 주소를 탐색합니다.
http://10.0.0.4/
http://10.0.0.5/
- RDP를 사용하여
둘 다 기본 IIS 웹페이지인 환영 페이지가 표시됩니다.
기본 웹페이지 수정
현재 페이지를 제공하는 서버를 쉽게 확인할 수 있도록 각각의 기본 웹페이지를 변경합니다.
- RDP를 사용하여
wsfc-1이라는 VM에 연결합니다. - 관리자 권한으로 메모장을 실행합니다.
- 메모장에서
C:\inetpub\wwwroot\iisstart.htm을 엽니다. 텍스트 파일을 포함한 모든 파일을 찾아야 합니다. <title>요소에서 텍스트를 현재 서버 이름으로 변경합니다. 예를 들면 다음과 같습니다.<title>wsfc-1</title>HTML 파일을 저장합니다.
wsfc-2에도 같은 단계를 반복하고<title>요소를wsfc-2로 설정합니다.
이제 이러한 서버 중 하나에서 제공하는 웹페이지를 보면 서버 이름이 Internet Explorer 탭의 제목으로 표시됩니다.
장애 조치 테스트
- RDP를 사용하여
wsfc-dc라는 VM에 연결합니다. - Internet Explorer를 엽니다.
부하 분산기 역할의 IP 주소를 탐색합니다.
http://10.0.0.9/탭 제목에 현재 서버 이름이 표시되는 시작 페이지가 나타납니다.
현재 서버를 중지하여 실패를 시뮬레이션합니다. Cloud Shell에서 다음 명령어를 실행하여
[INSTANCE_NAME]을 이전 단계에서 확인한 현재 서버 이름(예:wsfc-1)으로 바꿉니다.gcloud compute instances stop [INSTANCE_NAME] --zone=[ACTIVE_ZONE]RDP 연결을
wsfc-dc로 전환합니다.부하 분산기가 이동을 감지하여 트래픽을 다시 라우팅하기까지 몇 분이 걸릴 수 있습니다.
30초 정도 지나면 Internet Explorer에서 페이지를 새로고침합니다.
이제 탭 제목에 새 활성 노드 이름이 표시됩니다. 예를 들어 처음에는
wsfc-1이 활성화되었다면 지금은 제목에wsfc-2가 표시됩니다. 변경사항이 바로 표시되지 않거나 '페이지를 찾을 수 없음' 오류가 표시되면 브라우저를 다시 새로 고칩니다.
수고하셨습니다. 이제 GCP에서 Windows Server 2016 장애 조치 클러스터가 실행됩니다.
문제 해결
다음은 정상적으로 작동하지 않을 때 확인해야 할 일반적인 문제입니다.
GCP 방화벽 규칙에서 상태 확인 차단
상태 점검이 작동하지 않으면 상태 점검 시스템이 사용하는 IP 주소(130.211.0.0/22 및 35.191.0.0/16)에서 들어오는 트래픽을 허용하는 방화벽 규칙이 있는지 다시 확인하세요.
Windows 방화벽에서 상태 확인 차단
각 클러스터 노드의 Windows 방화벽에서 포트 59998이 열려 있는지 확인하세요. Windows 방화벽 열기를 참조하세요.
DHCP를 사용하는 클러스터 노드
클러스터의 각 VM에는 고정 IP 주소가 있어야 합니다. Windows에서 VM이 DHCP를 사용하도록 구성된 경우, Google Cloud 콘솔에 표시된 것처럼 IPv4 주소가 VM의 IP 주소와 일치하도록 Windows에서 네트워킹 설정을 변경합니다. 또한 게이트웨이 IP 주소를 GCP VPC의 서브네트워크 게이트웨이 주소와 일치하도록 설정합니다.
방화벽 규칙의 GCP 네트워크 태그
방화벽 규칙에서 네트워크 태그를 사용한다면 모든 VM 인스턴스에 올바른 태그가 설정되어 있는지 확인하세요. 이 가이드에서는 태그를 사용하지 않지만 다른 이유로 태그를 설정했다면 일관되게 사용해야 합니다.