Tutorial ini menjelaskan cara mengaktifkan Replikasi Asinkron Hyperdisk Seimbang di dua region Google Cloud sebagai solusi pemulihan dari bencana (DR), dan cara mengaktifkan instance DR jika terjadi bencana.
Instance Cluster Failover (FCI) Microsoft SQL Server adalah satu instance SQL Server yang sangat tersedia dan di-deploy di beberapa node Windows Server Failover Cluster (WSFC). Sewaktu-waktu, salah satu node cluster secara aktif menghosting instance SQL. Jika terjadi gangguan zonal atau masalah VM , WSFC akan mentransfer kepemilikan resource instance ke node lain dalam cluster secara otomatis sehingga klien dapat terhubung kembali. FCI SQL Server mengharuskan data ditempatkan di disk bersama agar dapat diakses di seluruh node WSFC.
Untuk memastikan deployment SQL Server dapat bertahan dari pemadaman listrik regional, replikasi data disk region utama ke region sekunder dengan mengaktifkan Replikasi Asinkron. Tutorial ini menggunakan disk multi-writer Ketersediaan Tinggi yang Seimbang Hyperdisk untuk mengaktifkan Replikasi Asinkron di dua region Google Cloud sebagai solusi pemulihan dari bencana (DR) untuk FCI SQL Server, dan cara mengaktifkan instance DR jika terjadi bencana. Dalam dokumen ini, bencana adalah peristiwa saat cluster database utama gagal atau tidak tersedia karena region cluster tidak tersedia, mungkin karena bencana alam.
Tutorial ini ditujukan untuk arsitek, administrator, dan engineer database.
Pemulihan dari bencana di Google Cloud
DR di Google Cloud melibatkan pemeliharaan akses berkelanjutan ke data saat region gagal atau tidak dapat diakses. Ada beberapa opsi deployment untuk situs DR dan opsi tersebut akan ditentukan oleh persyaratan toleransi jumlah data yang hilang (RPO) dan batas waktu pemulihan (RTO). Tutorial ini membahas salah satu opsi tempat disk yang terpasang ke virtual machine direplikasi dari region utama ke region DR.
Pemulihan dari bencana menggunakan Replikasi Asinkron Hyperdisk
Replikasi Asinkron Hyperdisk adalah opsi penyimpanan yang menyediakan salinan penyimpanan asinkron untuk replikasi disk antara dua region. Jika terjadi pemadaman listrik regional, Replikasi Asinkron Hyperdisk memungkinkan Anda melakukan failover data ke region sekunder dan memulai ulang workload di region tersebut.
Replikasi Asinkron Hyperdisk mereplikasi data dari disk yang terpasang ke workload yang sedang berjalan, yang disebut sebagai disk utama, ke disk terpisah yang terletak di region lain. Disk yang menerima replikasi disebut sebagai disk sekunder. Region tempat disk utama berjalan disebut sebagai region utama, dan region tempat disk sekunder berjalan adalah region sekunder. Untuk memastikan bahwa replika semua disk yang terpasang ke setiap node SQL Server berisi data dari titik waktu yang sama, disk ditambahkan ke grup konsistensi. Dengan grup konsistensi, Anda dapat melakukan DR dan pengujian DR di beberapa disk.
Arsitektur pemulihan dari bencana (disaster recovery)
Untuk Replikasi Asinkron Hyperdisk, diagram berikut menunjukkan arsitektur minimal yang mendukung HA database di region utama, R1, dan replikasi disk dari region utama ke region sekunder, R2.
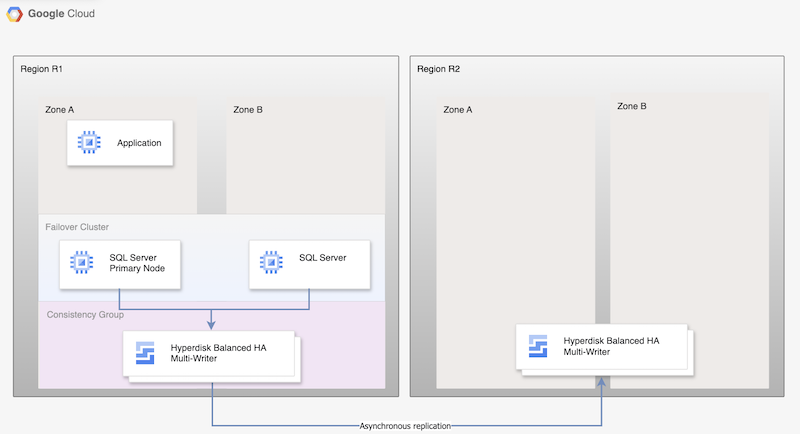
Gambar 1. Arsitektur pemulihan dari bencana dengan Microsoft SQL Server dan Replikasi Asinkron Hyperdisk
Arsitektur ini berfungsi sebagai berikut:
- Dua instance Microsoft SQL Server, instance utama dan instance standby, adalah bagian dari cluster FCI, dan terletak di region utama, (R1) tetapi di zona yang berbeda (zona A dan B). Kedua instance berbagi disk Hyperdisk Balanced High Availability, sehingga memungkinkan akses ke data dari kedua VM. Untuk mengetahui petunjuknya, lihat Mengonfigurasi cluster FCI SQL Server dengan mode multi-writer Ketersediaan Tinggi Seimbang Hyperdisk
- Disk dari kedua node SQL ditambahkan ke grup konsistensi dan direplikasi ke region DR, R2. Compute Engine mereplikasi data secara asinkron dari R1 ke R2.
- Replikasi asinkron hanya mereplikasi data pada disk ke R2 dan tidak mereplikasi metadata VM. Selama DR, VM baru dibuat dan disk yang direplikasi yang ada dipasang ke VM untuk mengaktifkan node.
Proses pemulihan dari bencana
Proses DR menetapkan langkah-langkah operasional yang harus Anda lakukan setelah region menjadi tidak tersedia untuk melanjutkan workload di region lain.
Proses DR database dasar terdiri dari langkah-langkah berikut:
- Region pertama (R1), yang menjalankan instance database utama, menjadi tidak tersedia.
- Tim operasi mengenali dan secara resmi mengonfirmasi bencana, dan memutuskan apakah failover diperlukan.
- Jika failover diperlukan, Anda harus menghentikan replikasi antara disk utama dan sekunder. VM baru dibuat dari replika disk dan diaktifkan.
- Database di region DR, R2, divalidasi dan diaktifkan. Database di R2 menjadi database utama baru yang memungkinkan konektivitas.
- Pengguna melanjutkan pemrosesan di database utama baru dan mengakses instance utama di R2.
Meskipun proses dasar ini menetapkan kembali database utama yang berfungsi, proses ini tidak membuat arsitektur HA yang lengkap, karena database utama yang baru tidak direplikasi.
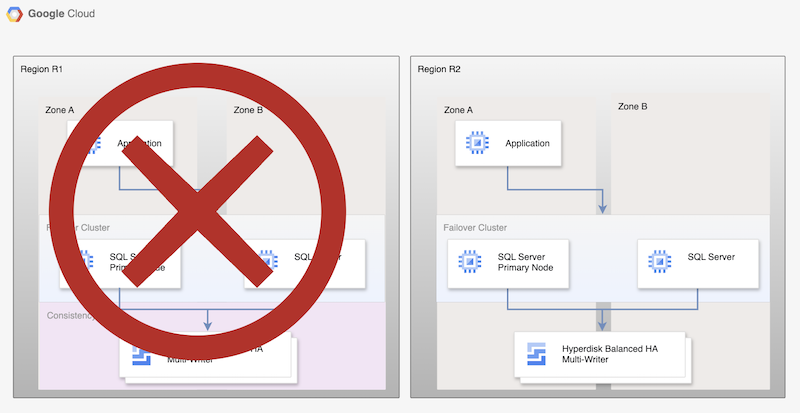
Gambar 2. Deployment SQL Server setelah Pemulihan dari bencana dengan Replikasi Asinkron Persistent Disk
Penggantian ke region yang dipulihkan
Saat region utama (R1) kembali online, Anda dapat merencanakan dan menjalankan proses failback. Proses failback terdiri dari semua langkah yang diuraikan dalam tutorial ini, tetapi dalam hal ini, R2 adalah sumber dan R1 adalah region pemulihan.
Pilih edisi SQL Server
Tutorial ini mendukung versi Microsoft SQL Server berikut:
- SQL Server 2016 Enterprise dan Standard Edition
- SQL Server 2017 Enterprise dan Standard Edition
- SQL Server 2019 Enterprise dan Standard Edition
- SQL Server 2022 Enterprise dan Standard Edition
Tutorial ini menggunakan instance cluster failover SQL Server dengan disk Hyperdisk Balanced High Availability.
Jika Anda tidak memerlukan fitur SQL Server Enterprise, Anda dapat menggunakan SQL Server edisi Standard:
SQL Server versi 2016, 2017, 2019, dan 2022 telah menginstal Microsoft SQL Server Management Studio di image; Anda tidak perlu menginstalnya secara terpisah. Namun, dalam lingkungan produksi, sebaiknya Anda menginstal satu instance Microsoft SQL Server Management Studio di VM terpisah di setiap region. Jika Anda menyiapkan lingkungan HA, Anda harus menginstal Microsoft SQL Server Management Studio satu kali untuk setiap zona guna memastikan ketersediaannya jika zona lain tidak tersedia.
Menyiapkan pemulihan dari bencana untuk Microsoft SQL Server
Tutorial ini menggunakan image sql-ent-2022-win-2022 untuk Microsoft SQL Server
Enterprise.
Untuk daftar lengkap image, lihat Image OS.
Menyiapkan cluster ketersediaan tinggi dengan dua instance
Untuk menyiapkan replikasi disk untuk SQL Server di antara dua region, pertama-tama buat cluster HA dua instance di satu region.
Satu instance berfungsi sebagai instance utama, dan instance lainnya berfungsi sebagai
standby. Untuk menyelesaikan langkah ini, ikuti petunjuk di
Mengonfigurasi cluster FCI SQL Server dengan mode multi-writer Ketersediaan Tinggi Hyperdisk Seimbang.
Tutorial ini menggunakan us-central1 untuk region utama R1.
Jika Anda mengikuti langkah-langkah dalam
Mengonfigurasi cluster FCI SQL Server dengan mode multi-writer Ketersediaan Tinggi yang Seimbang Hyperdisk,
Anda akan membuat dua instance SQL Server di region yang sama (us-central1). Anda akan men-deploy instance SQL Server utama (node-1) di
us-central1-a, dan instance standby (node-2) di us-central1-b.
Mengaktifkan Replikasi Asinkron disk
Setelah membuat dan mengonfigurasi semua VM, aktifkan replikasi disk di antara kedua region dengan menyelesaikan langkah-langkah berikut:
Buat grup konsistensi untuk kedua node SQL Server dan node yang menghosting peran saksi dan pengendali domain. Salah satu batasan untuk grup konsistensi adalah bahwa grup tersebut tidak dapat mencakup zona, jadi Anda harus menambahkan setiap node ke grup konsistensi terpisah.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
Tambahkan disk dari VM utama dan standby ke grup konsistensi yang sesuai.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Buat disk sekunder kosong di region sekunder.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Mulai replikasi disk. Data direplikasi dari disk utama ke disk kosong yang baru dibuat di region DR.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
Data harus direplikasi antar-region pada saat ini.
Status replikasi untuk setiap disk harus menampilkan Active.
Menyimulasikan pemulihan dari bencana
Di bagian ini, Anda akan menguji arsitektur pemulihan dari bencana yang disiapkan dalam tutorial ini.
Menyimulasikan pemadaman layanan dan mengeksekusi failover pemulihan dari bencana
Selama failover, Anda membuat VM baru di region DR dan memasang disk yang direplikasi ke VM tersebut. Untuk menyederhanakan failover, Anda dapat menggunakan Virtual Private Cloud (VPC) yang berbeda di region DR untuk pemulihan, sehingga Anda dapat menggunakan alamat IP yang sama.
Sebelum memulai failover, pastikan bahwa node-1 adalah node utama untuk
grup ketersediaan AlwaysOn yang Anda buat. Aktifkan pengendali domain dan node SQL Server utama untuk menghindari masalah sinkronisasi data, karena kedua node dilindungi oleh dua grup konsistensi terpisah.
Untuk menyimulasikan gangguan, ikuti langkah-langkah berikut:
Buat VPC pemulihan.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Menghentikan replikasi data.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Hentikan VM sumber di region utama.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Ganti nama VM yang ada untuk menghindari nama duplikat dalam project.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
Buat VM di region DR menggunakan disk sekunder. VM ini akan memiliki alamat IP VM sumber.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
Anda telah menyimulasikan pemadaman layanan dan melakukan failover ke region DR. Sekarang Anda dapat menguji apakah instance sekunder berfungsi dengan benar.
Memverifikasi konektivitas SQL Server
Setelah membuat VM, verifikasi bahwa database telah dipulihkan dengan berhasil dan server berfungsi seperti yang diharapkan. Untuk menguji database, jalankan kueri dari database yang dipulihkan.
- Hubungkan ke VM SQL Server menggunakan Desktop Jarak Jauh.
- Buka SQL Server Management Studio.
- Pada dialog Connect to server, pastikan nama server disetel ke
node-1, lalu pilih Connect. Di menu file, pilih File > New > Query dengan koneksi saat ini.
USE [bookshelf]; SELECT * FROM Books;