Membangun layanan ketersediaan tinggi dengan disk regional
Bagian ini menjelaskan cara membuat layanan HA dengan Persistent Disk regional atau disk Hyperdisk Balanced High Availability.
Pertimbangan desain
Sebelum mulai mendesain layanan dengan ketersediaan tinggi (HA), pahami karakteristik aplikasi, sistem file, dan sistem operasi. Karakteristik ini adalah dasar desain dan dapat mengesampingkan berbagai pendekatan. Misalnya, jika aplikasi tidak mendukung replikasi tingkat aplikasi, beberapa opsi desain yang terkait tidak akan berlaku.
Demikian pula, jika aplikasi, sistem file, atau sistem operasi tidak toleran terhadap error, penggunaanPersistent Disk regional ataudisk Hyperdisk Balanced High Availability, atau bahkan snapshot disk zonal, mungkin tidak dapat dilakukan. Toleransi error didefinisikan sebagai kemampuan untuk pulih dari penghentian tiba-tiba tanpa kehilangan atau merusak data yang sudah di-commit ke disk sebelum error.
Pertimbangkan hal-hal berikut saat mendesain untuk ketersediaan tinggi:
- Pengaruh penggunaan Hyperdisk Balanced High Availability, Persistent Disk regional, atau solusi lain terhadap aplikasi.
- Performa penulisan disk.
- Batas waktu pemulihan layanan - seberapa cepat layanan Anda harus pulih dari pemadaman layanan di zona tertentu dan persyaratan SLA.
- Biaya untuk membangun arsitektur layanan yang tangguh dan andal.
- Untuk mengetahui informasi selengkapnya tentang pertimbangan khusus wilayah, lihat Geografi dan wilayah.
Dari segi biaya, gunakan opsi berikut untuk replikasi aplikasi sinkron dan asinkron:
Gunakan dua instance database dan VM. Dalam hal ini, item berikut menentukan total biaya:
- Biaya instance VM
- Biaya Persistent Disk atau Hyperdisk
- Biaya mempertahankan replikasi aplikasi
Gunakan VM tunggal dengan disk yang direplikasi secara sinkron. Untuk mencapai ketersediaan tinggi dengan Persistent Disk regional atau disk Hyperdisk Balanced High Availability, gunakan instance VM dan komponen disk yang sama seperti opsi sebelumnya, tetapi sertakan juga disk yang direplikasi secara sinkron. Persistent Disk Regional dan Hyperdisk Balanced High Availability memiliki biaya per byte dua kali lipat dibandingkan disk zona karena direplikasi dalam dua zona.
Namun, penggunaan disk yang direplikasi secara sinkron dapat mengurangi biaya pemeliharaan karena data secara otomatis ditulis ke dua replika tanpa perlu mempertahankan replikasi aplikasi.
Jangan memulai VM sekunder hingga failover diperlukan. Anda dapat mengurangi biaya host lebih besar lagi dengan memulai VM sekunder hanya sesuai permintaan selama failover, bukan mempertahankan VM sebagai VM standby aktif.
Bandingkan biaya, performa, dan ketahanan
Tabel berikut menyoroti kompromi dalam biaya, performa, dan ketahanan untuk berbagai arsitektur layanan.
| Arsitektur layanan dengan ketersediaan tinggi (HA) |
Snapshot disk zona |
Tingkat aplikasi sinkron |
Tingkat aplikasi asinkron |
Disk regional |
|---|---|---|---|---|
| Melindungi dari aplikasi, VM, kegagalan zona* | ||||
| Mitigasi terhadap kerusakan aplikasi (Contoh: intoleransi error aplikasi) | † | † | ||
| Biaya | $ |
$$
|
$$
|
$1,5x - $$
|
| Performa Aplikasi |
|
|
|
|
| Cocok untuk aplikasi dengan persyaratan RPO rendah (Toleransi sangat rendah terhadap kehilangan data) |
|
|
|
|
| Waktu pemulihan penyimpanan sejak bencana# |
|
|
|
|
* Penggunaan disk atau snapshot regional tidaklah cukup untuk melindungi dari dan mengurangi kegagalan serta kerusakan. Aplikasi, sistem file, dan mungkin komponen software lainnya harus konsisten dengan error atau menggunakan semacam quiescing.
† Replikasi beberapa aplikasi memberikan mitigasi terhadap beberapa kerusakan aplikasi. Misalnya, kerusakan aplikasi utama MySQL tidak menyebabkan instance VM replikanya juga rusak. Tinjau dokumentasi aplikasi untuk mengetahui detailnya.
‡ Kehilangan data berarti hilangnya data yang tidak dapat dipulihkan yang dikirim ke penyimpanan persisten. Semua data yang tidak di-commit akan tetap hilang.
# Performa failover tidak mencakup pemeriksaan sistem file serta pemulihan dan pemuatan aplikasi setelah failover.
Membuat layanan database dengan ketersediaan tinggi (HA) menggunakan disk regional
Bagian ini membahas konsep tingkat tinggi dalam membangun solusi HA untuk layanan database stateful (MySQL, Postgres, dll.) menggunakan Compute Engine denganPersistent Disk Regional dan disk Hyperdisk Balanced High Availability.
Jika ada pemadaman layanan secara luas di Google Cloud, misalnya, jika seluruh region menjadi tidak tersedia, aplikasi Anda mungkin tidak akan tersedia. Bergantung pada kebutuhan Anda, pertimbangkan teknik replikasi lintas-regional atau Replikasi Asinkron untuk ketersediaan yang lebih tinggi.
Konfigurasi HA database biasanya memiliki setidaknya dua instance VM. Sebaiknya instance VM ini adalah bagian dari satu atau beberapa grup instance terkelola:
- Instance VM utama di zona utama
- Instance VM standby di zona sekunder
Instance VM utama memiliki setidaknya dua disk: boot disk dan disk regional. Disk regional berisi data database dan data lain yang dapat berubah dan harus dipertahankan di zona lain jika terjadi pemadaman.
Instance VM standby memerlukan boot disk terpisah agar dapat dipulihkan dari pemadaman terkait konfigurasi, yang dapat disebabkan oleh upgrade sistem operasi, misalnya. Selain itu, Anda tidak dapat memaksa pemasangan boot disk ke VM lain selama failover.
Instance VM utama dan standby dikonfigurasi untuk menggunakan load balancer dengan traffic yang diarahkan ke VM utama berdasarkan sinyal health check. Skenario pemulihan dari bencana untuk data menguraikan konfigurasi failover lainnya, yang mungkin lebih sesuai untuk skenario Anda.
Tantangan dengan replikasi database
Tabel berikut mencantumkan beberapa tantangan umum dalam menyiapkan dan mengelola replikasi sinkron atau semi-sinkron aplikasi (seperti MySQL) dan perbandingannya dengan replikasi disk sinkron dengan disk Ketersediaan Tinggi yang SeimbangPersistent Disk Regional dan Hyperdisk.
| Tantangan | Replikasi sinkron atau semi-sinkron aplikasi |
Replikasi disk sinkron |
|---|---|---|
| Mempertahankan replikasi stabil antara replika utama dan failover. | Ada sejumlah hal yang bisa terjadi dan menyebabkan instance VM keluar dari mode HA:
|
Kegagalan penyimpanan ditangani oleh Persistent Disk Regional dan disk Hyperdisk Balanced High Availability. Hal ini terjadi secara transparan pada aplikasi, kecuali kemungkinan fluktuasi performa disk. Harus ada health check yang ditentukan pengguna untuk menemukan masalah aplikasi atau VM dan memicu failover. |
| Waktu failover menyeluruh lebih lama dari yang diperkirakan. | Waktu yang dibutuhkan untuk operasi failover tidak memiliki batas atas. Menunggu semua transaksi untuk di-replay (langkah 2 di atas) dapat memakan waktu yang lama, bergantung pada skema dan beban pada database. | Persistent Disk Regional dan disk Hyperdisk Balanced High Availability menyediakan replikasi sinkron, sehingga waktu failover dibatasi oleh jumlah latensi berikut:
|
| Split-brain | Untuk menghindari split-brain, kedua pendekatan ini memerlukan ketentuan untuk memastikan bahwa hanya ada satu pendekatan utama dalam satu waktu. | |
Urutan operasi baca dan tulis ke disk
Dalam menentukan urutan baca dan tulis, atau urutan pembacaan dan penulisan data ke disk, sebagian besar pekerjaan dilakukan oleh driver disk di VM Anda. Sebagai pengguna, Anda tidak perlu berurusan dengan semantik replikasi, dan dapat berinteraksi dengan sistem file seperti biasa. Driver yang mendasarinya menangani urutan untuk membaca dan menulis.
Secara default, VM Compute Engine dengan Persistent Disk Regional atau Hyperdisk Balanced High Availability beroperasi dalam mode replikasi penuh, dengan permintaan untuk membaca atau menulis dari disk akan dikirim ke kedua replika.
Dalam mode replikasi penuh, hal berikut akan terjadi:
- Saat menulis, permintaan tulis mencoba menulis ke kedua replika dan mengonfirmasi saat kedua penulisan berhasil.
- Saat membaca, VM akan mengirimkan permintaan baca ke kedua replika, dan menampilkan hasil dari replika yang berhasil. Jika waktu permintaan baca habis, permintaan baca lainnya akan dikirim.
Jika replika tertinggal atau gagal mengonfirmasi bahwa permintaan baca atau tulis telah selesai, maka status replika akan diperbarui.
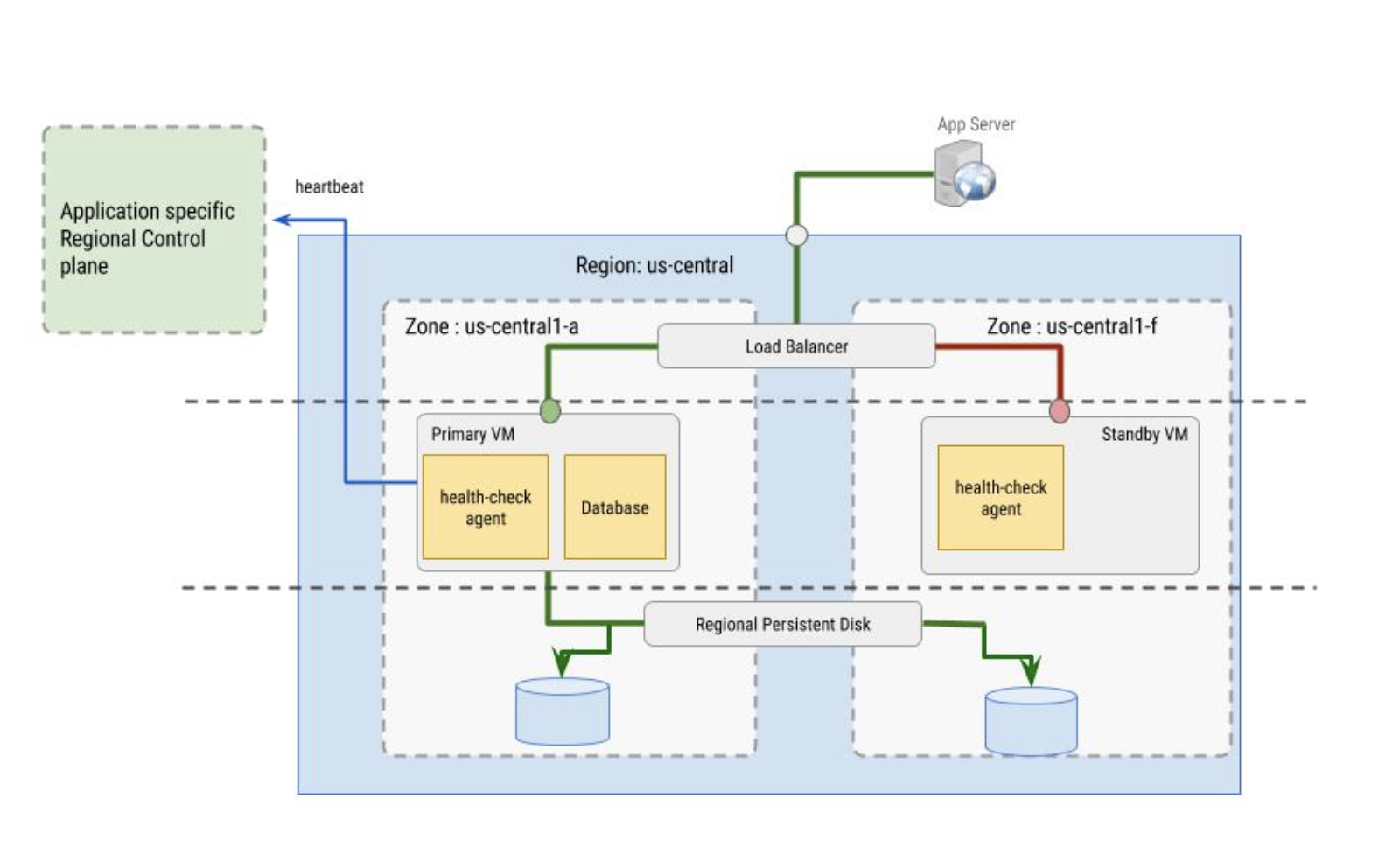
Health check
Health check yang digunakan oleh load balancer diterapkan oleh agen health check. Agen health check memiliki dua tujuan:
- Agen health check berada di dalam VM utama dan sekunder untuk memantau instance VM dan berkomunikasi dengan load balancer untuk mengarahkan traffic. Fungsi ini berfungsi paling optimal jika dikonfigurasi dengan grup instance.
- Agen health check menyinkronkan dengan bidang kontrol regional khusus aplikasi dan membuat keputusan failover berdasarkan perilaku bidang kontrol. Bidang kontrol harus berada di zona yang berbeda dari instance VM yang kondisinya dipantau.
Agen health check itu sendiri harus bersifat fault tolerant. Misalnya, perhatikan bahwa,
pada gambar berikutnya, bidang kontrol dipisahkan dari instance VM
utama yang berada di zona us-central1-a, sedangkan VM standby berada
di zona us-central1-f.
Langkah berikutnya
- Pelajari cara membuat dan mengelola disk regional.
- Pelajari Replikasi Asinkron.
- Pelajari cara mengonfigurasi instance cluster failover SQL Server untuk disk dalam mode multi-writer.
- Pelajari cara membangun aplikasi web yang skalabel dan tangguh di Google Cloud.
- Tinjau panduan perencanaan pemulihan dari bencana.