解析器扩展程序
本文档介绍了如何创建解析器扩展功能,以从原始日志数据中提取字段,并将其映射到 Google Security Operations 平台中的目标 UDM(统一数据模型)字段。
该文档概述了解析器扩展程序的创建流程:
- 创建解析器扩展程序。
- 前提条件和限制。
- 确定原始日志数据中的源字段。
- 选择适当的目标 UDM 字段。
-
定义解析器扩展功能包括设计解析逻辑,以过滤原始日志数据、转换数据并将其映射到目标 UDM 字段。Google SecOps 提供两种创建解析器扩展程序的方法:
- 使用无代码(地图数据字段)方法创建解析器扩展程序。
- 使用代码段方法创建解析器扩展程序。
针对各种日志格式和场景的说明性解析器扩展创建示例。例如,使用 JSON 的无代码示例,以及用于复杂逻辑或非 JSON 格式(CSV、XML、Syslog)的代码段。
创建解析器扩展程序
解析器扩展程序提供了一种灵活的方式来扩展现有默认(和自定义)解析器的功能。解析器扩展功能提供了一种灵活的方式来扩展现有默认(或自定义)解析器的功能,而无需替换它们。借助扩展程序,您可以添加新的解析逻辑、提取和转换字段,以及更新或移除 UDM 字段映射,从而自定义解析器流水线。
解析器扩展与自定义解析器不同。您可以为没有默认解析器的日志类型创建自定义解析器,也可以选择不接收解析器更新。
解析器提取和归一化流程
Google SecOps 会接收原始日志数据作为原始日志。默认(和自定义)解析器会将核心日志字段提取并标准化为 UDM 记录中的结构化 UDM 字段。这仅代表原始原始日志数据的一部分。您可以定义解析器扩展程序,以提取默认解析器无法处理的日志值。解析器扩展程序激活后,会成为 Google SecOps 数据提取和规范化流程的一部分。
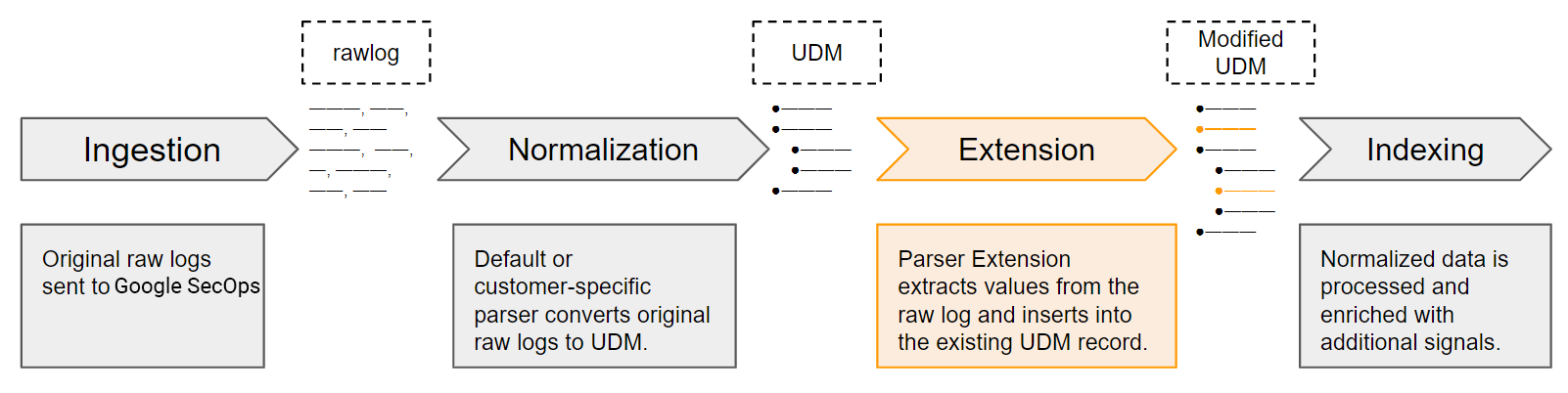
定义新的解析器扩展功能
默认解析器包含预定义的映射指令集,用于指定如何提取、转换和归一化核心安全值。您可以使用无代码(映射数据字段)方法或代码段方法定义映射指令,从而创建新的解析器扩展程序:
无代码方法
无代码方法最适合从原生 JSON、XML 或 CSV 格式的原始日志中进行简单提取。您可以在其中指定原始日志源字段,并映射相应的目标 UDM 字段。
例如,提取最多包含 10 个字段的 JSON 日志数据,使用简单的等值比较。
代码段方法
借助代码段方法,您可以定义指令来从原始日志中提取和转换值,并将这些值分配给 UDM 字段。代码段使用与默认(或自定义)解析器相同的 Logstash 类似语法。
此方法适用于所有受支持的日志格式。它最适合以下情形:
- 复杂的数据提取或复杂的逻辑。
- 需要基于 Grok 的解析器的非结构化数据。
- 非 JSON 格式,例如 CSV 和 XML。
代码段使用函数从原始日志数据中提取特定数据。例如,Grok、JSON、KV 和 XML。
在大多数情况下,最好使用默认(或自定义)解析器中使用的数据映射方法。
将新提取的值合并到 UDM 字段中
激活后,解析器扩展程序会根据预定义的合并原则,将新提取的值合并到相应 UDM 记录中的指定 UDM 字段中。例如:
覆盖现有值:提取的值会覆盖目标 UDM 字段中的现有值。
唯一的例外是重复字段,您可以配置解析器扩展功能,以便在将数据写入 UDM 记录中的重复字段时附加新值。
解析器扩展功能具有优先权:解析器扩展功能中的数据映射说明优先于相应日志类型的默认(或自定义)解析器中的数据映射说明。如果映射指令存在冲突,解析器扩展程序将覆盖默认设置的值。
例如,如果默认解析器将原始日志字段映射到
event.metadata.descriptionUDM 字段,而解析器扩展程序将另一个原始日志字段映射到同一 UDM 字段,则解析器扩展程序会覆盖默认解析器设置的值。
限制
- 每种日志类型只能有一个解析器扩展程序:每种日志类型只能创建一个解析器扩展程序。
- 仅限一种数据映射指令方法:您可以使用无代码方法或代码段方法来构建解析器扩展程序,但不能同时使用这两种方法。
- 用于验证的日志样本:需要提供过去 30 天内的日志样本来验证 UDM 解析器扩展程序。如需了解详情,请参阅确保日志类型有有效的解析器。
- 基本解析器错误:基本解析器错误无法在解析器扩展功能中识别或修复。
- 代码段中的重复字段:在代码段中替换整个重复对象时,请务必谨慎操作,以免意外丢失数据。如需了解详情,请参阅重复字段选择器详解。
- 消除歧义的事件:解析器扩展程序无法处理单个记录中包含多个唯一事件的日志,例如 Google 云端硬盘数组。
XML 和无代码:无代码模式不支持 XML。请改用代码段方法。
无追溯性数据:您无法追溯性地解析原始日志数据。
无代码方法中的预留关键字:如果日志包含以下任何预留关键字,请使用代码段方法,而不是无代码方法:
collectionTimestampcreateTimestampenableCbnForLoopeventfilenamemessagenamespaceoutputonErrorCounttimestamptimezone
移除现有映射:您只能使用代码段方法移除现有的 UDM 字段映射。
移除重复 IP 字段的映射:您无法移除重复 IP 字段的 UDM 字段映射。
解析器概念
以下文档介绍了重要的解析器概念:
前提条件
创建解析器扩展的前提条件:
- 必须为日志类型提供有效的默认(或自定义)解析器。
- Google SecOps 必须能够使用默认(或自定义)解析器注入原始日志并对其进行标准化处理。
- 确保目标日志类型的有效默认(或自定义)解析器已在过去 30 天内提取原始日志数据。此数据应包含您打算提取或用于过滤日志记录的字段的样本。它将用于验证您的新数据映射说明。
开始使用
在创建解析器扩展之前,请执行以下操作:
-
确保日志类型有有效的解析器。如果该格式还没有解析器,请创建自定义解析器。
-
确定要从原始日志中提取的字段。
-
选择相应的 UDM 字段,以映射提取的原始日志字段。
-
选择以下任一扩展方法(数据映射方法)来创建解析器扩展。
验证前提条件
确保您要扩展的日志类型有有效的解析器,如以下部分所述:
确保日志类型有有效的解析器
确保您要扩展的日志类型有有效的默认(或自定义)解析器。
在以下列表中搜索您的日志类型:
-
- 如果日志类型有默认解析器,请确保该解析器处于有效状态。
- 如果日志类型没有默认解析器,请确保日志类型有自定义解析器。
-
- 如果日志类型没有默认解析器,请确保日志类型有自定义解析器。
确保日志类型有自定义解析器
如需确保日志类型有自定义解析器,请执行以下操作:
- 在导航栏中,依次选择 SIEM 设置 > 解析器。
在 Parsers 表中搜索要扩展的日志类型。
- 如果该日志类型尚无默认或自定义解析器,请点击创建解析器,然后按照根据映射说明创建自定义解析器中的步骤操作。
- 如果该日志类型已有自定义解析器,请确保该解析器处于有效状态。
确保解析器已针对相应日志类型处于有效状态
如需检查解析器是否针对特定日志类型处于有效状态,请执行以下步骤:
- 在导航栏中,依次选择 SIEM 设置 > 解析器。
在 Parsers 表中搜索要扩展的日志类型。
如果日志类型的解析器处于非活动状态,请将其激活:
- 如需了解默认解析器,请参阅管理预构建的解析器更新。
- 如需了解自定义解析器,请参阅管理自定义解析器更新。
确定要从原始日志中提取的字段
分析要从中提取数据的原始日志,以确定默认(或自定义)解析器未提取的字段。请注意默认(或自定义)解析器如何提取原始日志字段并将其映射到相应的 UDM 字段。
如需确定要从原始日志中提取的具体字段,您可以使用搜索工具来确定字段:
如需访问搜索工具,请依次前往调查 > SIEM 搜索。在搜索查询前输入 raw=。如需了解详情,请参阅执行原始日志搜索。
如需访问旧版搜索工具,请点击 SIEM 搜索页面顶部的前往旧版搜索。如需了解详情,请参阅使用原始日志扫描功能搜索原始日志。
如需详细了解如何在原始日志中进行搜索,请参阅:
选择合适的 UDM 字段
现在,您已经确定了要提取的具体目标字段,接下来可以将这些字段与相应的目标 UDM 字段进行匹配。在原始日志源字段及其目标 UDM 字段之间建立清晰的映射关系。您可以将数据映射到支持标准数据类型或重复字段的任何 UDM 字段。
选择正确的 UDM 字段
以下资源可帮助您简化此流程:
- 熟悉 UDM 的主要概念
- 了解现有解析器使用的数据映射
- 使用 UDM 查找工具查找与源字段匹配的潜在 UDM 字段。
- 用于解析器数据映射的重要 UDM 字段指南包含对 UDM 架构最常用字段的摘要和说明。
- 统一数据模型字段列表包含所有 UDM 字段及其说明的列表。重复字段在列表中会通过 repeated 标签进行标识。
- 避免出错的重要 UDM 注意事项
熟悉主要的 UDM 概念
-
UDM 架构描述了存储数据的所有可用属性。每个 UDM 记录都描述了一个事件或实体。数据会存储在不同的字段中,具体取决于记录描述的是事件还是实体。
- UDM 事件对象存储有关环境中发生的操作的数据。原始事件日志描述了设备(例如防火墙或 Web 代理)记录的操作。
- UDM 实体对象用于存储与 UDM 事件相关的参与者或实体的数据,例如您环境中的资产、用户或资源。
UDM 名词:名词代表 UDM 事件中的参与者或实体。例如,名词可以是执行事件中所述活动的设备或用户。名词也可以是事件中所述活动的目标设备或用户。
UDM 名词 说明 principal负责发起相应事件中所述操作的实体。 target作为操作的接收者或对象的实体。在防火墙连接中,接收连接的机器是目标。 src主账号所操作的来源实体。例如,如果用户将文件从一台机器复制到另一台机器,则该文件和源机器将表示为 src。 intermediary在事件中充当中间人的任何实体,例如代理服务器。它们可以影响操作,例如阻止或更改请求。 observer一种实体,用于监控和报告事件,但不直接与流量互动。例如,网络入侵检测系统或安全信息和事件管理系统。 about涉及事件但不属于上述类别的任何其他实体。例如,在进程启动期间的电子邮件附件或加载的 DLL。 在实践中,最常使用的正文和目标名词对象是那些。另请务必注意,上述说明构成了对名词的推荐用法。实际使用情况可能会因默认或自定义基本解析器的实现而异。
了解现有解析器使用的数据映射
建议您了解默认(或自定义)解析器使用的现有数据映射,即原始日志源字段与其目标 UDM 字段之间的映射。
如需查看原始日志源字段与现有默认(或自定义)解析器中使用的目标 UDM 字段之间的数据映射,请执行以下操作:
- 在导航栏中,依次选择 SIEM 设置 > 解析器。
- 在 Parsers 表中搜索要扩展的日志类型。
前往相应行,然后依次点击 菜单 > 查看。
解析器代码标签页会显示原始日志源字段与现有默认(或自定义)解析器中使用的目标 UDM 字段之间的数据映射。
使用 UDM 查询工具
使用 UDM 查找工具来帮助确定与原始日志源字段匹配的 UDM 字段。
Google SecOps 提供 UDM 查找工具,可帮助您快速找到目标 UDM 字段。如需访问 UDM 查找工具,请依次前往调查 > SIEM 搜索。
如需详细了解如何使用 UDM 查找工具,请参阅以下主题:
UDM 查询工具示例
例如,如果原始日志中有一个名为“packets”的源字段,请使用 UDM 查找工具查找名称中包含“packets”的潜在目标 UDM 字段:
依次前往调查 > SIEM 搜索。
在 SIEM 搜索页面中,在按值查找 UDM 字段字段中输入“数据包”,然后点击 UDM 查找。
系统随即会打开 UDM Lookup 对话框。搜索工具会按字段名称或字段值匹配 UDM 字段:
- 按字段名称查找 - 将您输入的文本字符串与包含该文本的字段名称进行匹配。
- 按字段值查找 - 将您输入的值与存储的日志数据中包含该值的字段进行匹配。
在 UDM Lookup 对话框中,选择 UDM Fields。
搜索功能将显示一个潜在 UDM 字段列表,其中包含 UDM 字段名称中带有“数据包”字样的字段。
逐个点击各行,查看每个 UDM 字段的说明。
避免出错的重要 UDM 注意事项
- 外观相似的字段:UDM 的层次结构可能会导致出现名称相似的字段。如需指导,请参阅默认解析器。如需了解详情,请参阅了解现有解析器使用的数据映射。
- 任意字段映射:对于无法直接映射到 UDM 字段的数据,请使用
additional对象。如需了解详情,请参阅将任意字段映射到 UDM。 - 重复字段:在代码段中使用重复字段时,请务必谨慎。替换整个对象可能会覆盖原始数据。 使用无代码方法可以更好地控制重复字段。如需了解详情,请参阅重复字段选择器详解。
- UDM 事件类型的强制性 UDM 字段:将 UDM
metadata.event_type字段分配给 UDM 记录时,每个event_type都需要 UDM 记录中存在一组不同的相关字段。如需了解详情,请参阅详细了解如何分配 UDMmetadata.event_type字段。 - 基本解析器问题:解析器扩展程序无法修复基本解析器中的错误。基础解析器是创建 UDM 记录的默认(或自定义)解析器。您可以考虑以下选项:增强解析器扩展程序、修改基本解析器或预过滤日志。
将任意字段映射到 UDM
如果找不到合适的标准 UDM 字段来存储数据,请使用 additional 对象将数据存储为自定义键值对。这样,即使 UDM 记录没有匹配的 UDM 字段,您也可以在其中存储有价值的信息。
选择解析器扩展定义方法
在选择解析器扩展定义方法之前,您必须先完成以下部分:
接下来,您需要打开解析器扩展程序页面,然后选择用于定义解析器扩展程序的扩展程序方法:
打开解析器扩展程序页面
您可以在解析器扩展程序页面中定义新的解析器扩展程序。
您可以通过以下方式打开解析器扩展程序页面:从“设置”菜单中、从原始日志搜索中或从旧版原始日志搜索中打开:
通过“设置”菜单打开
如需从“设置”菜单中打开解析器扩展程序页面,请执行以下操作:
在导航栏中,依次选择 SIEM 设置 > 解析器。
解析器表按日志类型显示默认解析器的列表。
找到要扩展的日志类型,依次点击 菜单 > 创建扩展程序。
系统会打开解析器扩展程序页面。
通过原始日志搜索打开
如需通过原始日志搜索打开解析器扩展功能页面,请执行以下操作:
- 依次前往调查 > SIEM 搜索。
- 在搜索字段中,向搜索实参添加前缀
raw =,然后将搜索字词用英文引号括起来。例如raw = "example.com"。 - 点击运行搜索。 结果会显示在原始日志面板中。
- 在原始日志面板中点击某个日志(行)。 系统随即会显示活动视图面板。
- 点击事件视图面板中的原始日志标签页。 系统会显示原始日志。
依次点击管理解析器 > 创建扩展程序 > 下一步。
系统会打开解析器扩展程序页面。
从旧版原始日志搜索中打开
如需从旧版 原始日志搜索中打开解析器扩展功能页面,请执行以下操作:
- 使用旧版原始日志搜索功能搜索与将要解析的记录类似的记录。
- 从事件 > 时间轴面板中选择一个事件。
- 展开事件数据面板。
依次点击管理解析器 > 创建扩展程序 > 下一步。
系统会打开解析器扩展程序页面。
解析器扩展程序页面
该页面会显示原始日志和扩展程序定义面板:
原始日志面板:
此选项会显示所选日志类型的原始日志数据示例。 如果您是从原始日志搜索打开该页面的,则示例数据是您的搜索结果。您可以使用查看方式菜单(原始、JSON、CSV、XML 等)和自动换行复选框来设置示例的格式。
检查显示的原始日志数据样本是否代表解析器扩展程序将处理的日志。
点击预览 UDM 输出,查看示例原始日志数据的 UDM 输出。
扩展程序定义面板:
这样一来,您就可以使用以下两种映射指令方法之一来定义解析器扩展程序:映射数据字段(无代码)或编写代码段。您无法在同一解析器扩展程序中同时使用这两种方法。
根据您选择的方法,您可以指定要从传入的原始日志中提取的源日志数据字段,并将它们映射到相应的 UDM 字段;也可以编写代码段来执行这些任务以及更多任务。
选择扩展方法
在解析器扩展程序页面的扩展程序定义面板中,在扩展程序方法字段中,选择以下方法之一来创建解析器扩展程序:
映射数据字段(无代码)方法:
此方法可让您指定原始日志中的字段,并将其映射到目标 UDM 字段。
此方法适用于以下原始日志格式:
- 原生 JSON、原生 XML 或 CSV。
- Syslog 标头加上原生 JSON、原生 XML 或 CSV。您可以为以下格式的原始日志创建数据字段类型映射说明:
JSON、XML、CSV、SYSLOG + JSON、SYSLOG + XML和SYSLOG + CSV。
请参阅后续步骤,即创建无代码 (Map 数据字段) 说明。
编写代码段方法:
此方法可让您使用类似 Logstash 的语法来指定指令,以从原始日志中提取和转换值,并将其分配给 UDM 记录中的 UDM 字段。
请参阅后续步骤:创建代码段说明。
创建无代码(映射数据字段)说明
通过无代码方法(也称为映射数据字段方法),您可以指定原始日志字段的路径,并将它们映射到相应的目标 UDM 字段。
在采用无代码方法创建解析器扩展之前,您必须已完成以下部分:
定义解析器扩展程序的后续步骤如下:
设置重复字段选择器
在扩展程序定义面板的重复字段字段中,设置解析器扩展程序应如何将值保存到重复字段(支持值数组的字段,例如 principal.ip):
- 附加值:新提取的值会附加到 UDM 数组字段中存储的现有值集中。
- 替换值:新提取的值会替换 UDM 数组字段中之前由默认解析器存储的现有值集。
重复字段选择器中的设置不会影响非重复字段。
如需了解详情,请参阅详细了解“重复字段”选择器。
为每个字段定义数据映射指令
为您要从原始日志中提取的每个字段定义数据映射指令。该指令应指定原始日志中源字段的路径,并将其映射到目标 UDM 字段。
如果原始日志面板中显示的原始日志样本包含 Syslog 标头,则会显示 Syslog 和目标字段。(某些日志格式不包含 Syslog 标头,例如原生 JSON、原生 XML 或 CSV。)
Google SecOps 需要 Syslog 和 Target 字段来预处理 Syslog 标头,以提取日志的结构化部分。
定义以下字段:
Syslog:这是用户定义的模式,用于对原始日志的结构化部分进行预处理并将其与 Syslog 标头分开。
使用 Grok 和正则表达式指定用于标识 Syslog 标头和原始日志消息的提取模式。如需了解详情,请参阅定义 Syslog 提取器字段。
目标:Syslog 字段中存储日志结构化部分的变量名称。
在提取模式中指定用于存储日志结构化部分的变量名称。
以下分别是 Syslog 和 Target 字段的提取模式和变量名称示例。

在 Syslog 和 Target 字段中输入值后,点击 Validate 按钮。
验证过程会检查语法错误和解析错误,然后返回以下任一结果:
- 成功:系统会显示数据映射字段。定义解析器扩展的其余部分。
- 失败:系统会显示一条错误消息。请先更正错误情况,然后再继续。
(可选)定义前提条件指令。
前提条件指令通过将静态值与原始日志中的字段进行匹配,来标识解析器扩展程序处理的原始日志的子集。如果传入的原始日志满足前提条件,解析器扩展程序会应用映射指令。如果值不匹配,解析器扩展程序不会应用映射指令。
填写以下字段:
- 前提条件字段:原始日志中包含要比较的值的字段标识符。如果日志数据格式为 JSON 或 XML,请输入该字段的完整路径;如果数据格式为 CSV,请输入列位置。
- 前提条件运算符:选择
EQUALS或NOT EQUALS。 - 前提条件值:将与原始日志中的前提条件字段进行比较的静态值。
如需查看前提条件指令的另一个示例,请参阅无代码 - 提取具有前提条件值的字段。
将原始日志数据字段映射到目标 UDM 字段:
原始数据字段:如果日志数据格式为 JSON(例如:
jsonPayload.connection.dest_ip)或 XML(例如:/Event/Reason-Code),请输入该字段的完整路径;如果数据格式为 CSV,请输入列位置(注意:索引位置从 1 开始)。目标字段:输入将存储值的完全限定 UDM 字段名称,例如
udm.metadata.collected_timestamp.seconds。
如需继续添加更多字段,请点击添加,然后输入下一个字段的所有映射指令详细信息。
如需查看字段映射的另一个示例,请参阅无代码 - 提取字段。
提交并激活解析器扩展程序
为要从原始日志中提取的所有字段定义数据映射指令后,提交并激活解析器扩展程序。
点击提交以保存并验证映射指令。
Google SecOps 会验证映射指令:
- 如果验证过程成功,状态会更改为“有效”,并且映射指令开始处理传入的日志数据。
如果验证流程失败,状态会更改为失败,并且“原始日志”字段中会显示错误。
以下是验证错误示例:
ERROR: generic::unknown: pipeline.ParseLogEntry failed: LOG_PARSING_CBN_ERROR: "generic::invalid_argument: pipeline failed: filter mutate (7) failed: copy failure: copy source field \"jsonPayload.dest_instance.region\" must not be empty (try using replace to provide the value before calling copy) "LOG: {"insertId":"14suym9fw9f63r","jsonPayload":{"bytes_sent":"492", "connection":{"dest_ip":"10.12.12.33","dest_port":32768,"protocol":6, "src_ip":"10.142.0.238","src_port":22},"end_time":"2023-02-13T22:38:30.490546349Z", "packets_sent":"15","reporter":"SRC","src_instance":{"project_id":"example-labs", "region":"us-east1","vm_name":"example-us-east1","zone":"us-east1-b"}, "src_vpc":{"project_id":"example-labs","subnetwork_name":"default", "vpc_name":"default"},"start_time":"2023-02-13T22:38:29.024032655Z"}, "logName":"projects/example-labs/logs/compute.googleapis.com%2Fvpc_flows", "receiveTimestamp":"2023-02-13T22:38:37.443315735Z","resource":{"labels": {"location":"us-east1-b","project_id":"example-labs", "subnetwork_id":"00000000000000000000","subnetwork_name":"default"}, "type":"gce_subnetwork"},"timestamp":"2023-02-13T22:38:37.443315735Z"}解析器扩展程序的生命周期状态
解析器扩展程序具有以下生命周期状态:
DRAFT:尚未提交的新创建的解析器扩展程序。VALIDATING:Google SecOps 正在根据现有的原始日志验证映射指令,以确保字段解析无误。LIVE:解析器扩展程序已通过验证,现在处于生产状态。 它从传入的原始日志中提取数据并将其转换为 UDM 记录。FAILED:解析器扩展程序未通过验证。
详细了解“重复字段”选择器
某些 UDM 字段存储着由值组成的数组,例如 principal.ip 字段。借助重复字段选择器,您可以控制解析器扩展程序将如何将新提取的数据存储在重复字段中:
附加值:
解析器扩展程序会将新提取的值附加到 UDM 字段中现有值的数组。
替换值:
解析器扩展程序会将 UDM 字段中的现有值数组替换为新提取的值。
只有当重复字段位于层次结构的最低级别时,解析器扩展程序才能将数据映射到重复字段。例如:
- 支持将值映射到
udm.principal.ip,因为重复的ip字段位于层次结构的最低级别,而principal不是重复字段。 - 不支持将值映射到
udm.intermediary.hostname,因为intermediary是一个重复字段,并且不在层次结构的最低级别。
下表提供了一些示例,说明了重复字段选择器配置如何影响生成的 UDM 记录。
| 选择重复字段 | 日志示例 | 解析器扩展程序配置 | 生成的结果 |
|---|---|---|---|
| 附加值 | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"1.1.1.1, 2.2.2.2"}}} |
前提条件字段:protoPayload.requestMetadata.callerIp
前提条件值: " "
前提条件运算符: NOT_EQUALS
原始数据字段: protoPayload.requestMetadata.callerIp
目标字段: event.idm.read_only_udm.principal.ip
|
metadata:{event_timestamp:{}.....}principal:{Ip:"1.1.1.1, 2.2.2.2"}
}
} |
| 附加值 | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2, 3.3.3.3", "name":"Akamai Ltd"}}} |
前提条件 1:
前提条件字段: protoPayload.requestMetadata.callerIp
前提条件值: " "
前提条件运算符: NOT_EQUALS
原始数据字段: protoPayload.requestMetadata.callerIp
目标字段: event.idm.read_only_udm.principal.ip
前提条件 2:
|
在应用扩展之前,由预建的解析器生成的事件。
metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
应用扩展程序后的输出。
|
| 替换值 | {"protoPayload":{"@type":"type..AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2"}}} |
前提条件字段:protoPayload.authenticationInfo.principalEmail
前提条件值: " "
前提条件运算符: NOT_EQUALS
原始数据字段: protoPayload.authenticationInfo.principalEmail
目标字段: event.idm.read_only_udm.principal.ip
|
应用扩展程序之前由预建的解析器生成的 UDM 事件。timestamp:{} idm:{read_only_udm:{metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
应用扩展后的 UDM 输出
|
详细了解 Syslog 提取器字段
借助 Syslog 提取器字段,您可以通过定义 Grok、正则表达式以及正则表达式模式中的命名令牌来存储输出,从而将 Syslog 标头与结构化日志分开。
定义 Syslog 提取器字段
Syslog 和 Target 字段中的值共同定义了分析器扩展程序如何将原始日志的 Syslog 标头与结构化部分分开。在 Syslog 字段中,您可以使用 Grok 和正则表达式语法的组合来定义表达式。该表达式包含一个变量名称,用于标识原始日志的结构化部分。在目标字段中,您需要指定该变量名称。
以下示例说明了这些字段如何协同工作。
以下是原始日志的示例:
<13>1 2022-09-14T15:03:04+00:00 fieldname fieldname - - - {"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
原始日志包含以下部分:
Syslog 标头:
<13> 2022-09-14T15:03:04+00:00 fieldname fieldname - - -JSON 格式的事件:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
如需将原始日志的 Syslog 标头与 JSON 部分分开,请在 Syslog 字段中使用以下表达式示例:
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg}
- 表达式的这一部分用于标识 Syslog 标头:
%{TIMESTAMP\_ISO8601} %{WORD} %{WORD} ([- ]+)? - 表达式的这一部分用于捕获原始日志的 JSON 段:
%{GREEDYDATA:msg}
此示例包含变量名称 msg。您可以自行选择变量名称。
解析器扩展程序会提取原始日志的 JSON 段,并将其分配给变量 msg。
在目标字段中,输入变量名称 msg。存储在 msg 变量中的值会输入到您在解析器扩展程序中创建的数据字段映射指令中。
使用示例原始日志,以下部分将作为数据映射指令的输入:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
下图显示了已完成的 Syslog 和 Target 字段:
下表提供了更多示例,其中包含示例日志、Syslog 提取模式、目标变量名称和结果。
| 原始日志示例 | Syslog 字段 | 目标字段 | 结果 |
|---|---|---|---|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg} |
msg | field_mappings {
field: "msg"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
}
|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"} |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg1} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | field_mappings {
field: "msg2"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
} |
"<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:message} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | Error - message already exists in state and not overwritable. |
详细了解如何分配 UDM metadata.event_type 字段
将 UDM metadata.event_type 字段分配给 UDM 记录时,系统会进行验证,以确保 UDM 记录中包含所需的相关字段。每个 UDM metadata.event_type 都需要一组不同的相关字段,例如,没有 user 的 USER_LOGIN 事件就没什么用。
如果缺少必需的相关字段,UDM 验证会返回错误:
"error": {
"code": 400,
"message": "Request contains an invalid argument.",
"status": "INVALID_ARGUMENT"
}
Grok 解析器会返回更详细的错误:
generic::unknown:
invalid event 0: LOG_PARSING_GENERATED_INVALID_EVENT:
"generic::invalid_argument: udm validation failed: target field is not set"
如需查找要分配的 UDM event_type 的必需字段,请使用以下资源:
Google SecOps 文档:UDM 使用指南 - 每种事件类型的必填 UDM 字段和选填 UDM 字段
第三方非官方资源:UDM 事件验证
如果 UDM 使用指南不够详细,本文档将通过提供填充给定 UDM
metadata.event_type所需的最低强制性 UDM 字段来补充官方文档。例如,打开文档并搜索
GROUP_CREATION事件类型。您应该会看到以下最低限度的 UDM 字段,以 UDM 对象的形式呈现:
{ "metadata": { "event_timestamp": "2023-07-03T13:01:10.957803Z", "event_type": "GROUP_CREATION" }, "principal": { "user": { "userid": "pinguino" } }, "target": { "group": { "group_display_name": "foobar_users" } } }
创建代码段说明
借助代码段方法,您可以使用类似于 Logstash 的语法来定义如何从原始日志中提取和转换值,并将这些值分配给 UDM 记录中的 UDM 字段。
在采用代码段方法创建解析器扩展程序之前,您必须已完成以下部分:
定义解析器扩展程序的后续步骤如下:
- 如需了解相关提示和最佳实践,请参阅编写代码段说明时的提示和最佳实践。
- 创建代码段指令
- 提交代码段指令
编写代码段说明时的提示和最佳实践
代码段指令可能会因 Grok 模式不正确、重命名或替换操作失败或语法错误等问题而失败。如需提示和最佳实践,请参阅以下内容:
创建代码段指令
代码段指令使用与默认(或自定义)解析器相同的语法和部分:
- 第 1 部分。从原始日志中提取数据。
- 第 2 部分。转换提取的数据。
- 第 3 部分。为 UDM 字段分配一个或多个值。
- 第 4 部分。将 UDM 事件字段绑定到
@output键。
如需使用代码段方法创建解析器扩展程序,请执行以下操作:
- 在解析器扩展程序页面的 CBN 代码段面板中,输入代码段以创建解析器扩展程序。
- 点击验证以验证映射说明。
代码段指令示例
以下示例展示了一个代码段。
以下是原始日志的示例:
{
"insertId": "00000000",
"jsonPayload": {
...section omitted for brevity...
"packets_sent": "4",
...section omitted for brevity...
},
"timestamp": "2022-05-03T01:45:00.150614953Z"
}
以下是一个代码段示例,用于将 jsonPayload.packets_sent 中的值映射到 network.sent_bytes UDM 字段:
filter {
mutate {
replace => {
"jsonPayload.packets_sent" => ""
}
}
# Section 1. extract data from the raw JSON log
json {
source => "message"
array_function => "split_columns"
on_error => "_not_json"
}
if [_not_json] {
drop {
tag => "TAG_UNSUPPORTED"
}
} else {
# Section 2. transform the extracted data
if [jsonPayload][packets_sent] not in ["", 0] {
mutate {
convert => {
"jsonPayload.packets_sent" => "uinteger"
}
on_error => "_exception1"
}
# Section 3. assign the value to a UDM field
mutate {
Replace => {
"event.idm.read_only_udm.network.sent_bytes" => "jsonPayload.packets_sent"
}
on_error => "_exception2"
}
if ![_exception1] and![_exception2] {
# Section 4. Bind the UDM fields to the @output key
mutate {
merge => {
"@output" => "event"
}
}
}
}
}
}
提交代码段指令
点击提交以保存映射说明。
Google SecOps 会验证映射说明。
- 如果验证过程成功,状态会更改为“有效”,并且映射指令开始处理传入的日志数据。
- 如果验证流程失败,状态会更改为失败,并且“原始日志”字段中会显示错误。
管理现有解析器扩展程序
您可以查看、修改、删除现有解析器扩展程序,以及控制对这些扩展程序的访问权限。
查看现有解析器扩展程序
- 在导航栏中,依次选择 SIEM 设置 > 解析器。
- 在解析器列表中,找到要查看的解析器(日志类型)。具有解析器扩展程序的解析器会在其名称旁边显示
EXTENSION文本。 前往相应行,然后依次点击 菜单 > 查看扩展程序。
系统会显示查看自定义/预构建的解析器 > 扩展程序标签页,其中会显示有关解析器扩展程序的详细信息。摘要面板默认显示
LIVE解析器扩展程序。
修改解析器扩展程序
打开查看自定义/预构建的解析器 > 扩展程序标签页,如查看现有解析器扩展程序中所述。
点击修改扩展程序按钮。
系统会显示解析器扩展程序页面。
修改解析器扩展程序。
如需取消编辑并舍弃更改,请点击舍弃草稿。
如需随时删除解析器扩展程序,请点击删除失败的扩展程序。
修改完解析器扩展程序后,点击提交。
系统会运行验证流程来验证新配置。
删除解析器扩展程序
打开查看自定义/预构建的解析器 > 扩展程序标签页,如查看现有解析器扩展程序中所述。
点击删除扩展服务按钮。
控制对解析器扩展服务的访问权限
默认情况下,具有管理员角色的用户可以访问解析器扩展程序。 您可以控制哪些人可以查看和管理解析器扩展服务。如需详细了解如何管理用户和群组或分配角色,请参阅基于角色的访问权限控制。
下表总结了 Google SecOps 中的新角色。
| 功能 | 操作 | 说明 |
|---|---|---|
| 解析器 | 删除 | 删除解析器扩展功能。 |
| 解析器 | 修改 | 创建和修改解析器扩展程序。 |
| 解析器 | 查看 | 查看解析器扩展程序。 |
使用解析器扩展程序移除 UDM 字段映射
您可以使用解析器扩展程序来移除现有的 UDM 字段映射。
- 依次点击 SIEM 设置 > 解析器。
- 您可以使用以下任一方法查看解析器扩展程序页面:
- 对于现有扩展程序,请依次点击 菜单 > 扩展解析器 > 查看扩展程序。
- 对于新的解析器扩展程序,请依次点击 菜单 > 扩展解析器 > 创建扩展程序。
选择 Write code snippet 作为扩展方法,以添加用于移除特定 UDM 字段值的自定义代码段。
对于现有扩展程序,请在解析器扩展程序窗格中点击修改,然后添加代码段。
如需查看代码段示例,请参阅代码段 - 移除现有映射。
按照提交代码段指令中的步骤提交扩展程序。
需要更多帮助?从社区成员和 Google SecOps 专业人士那里获得解答。