托管式灾难恢复
本文档简要介绍 BigQuery 托管式灾难恢复,以及如何为数据和工作负载实施此类灾难恢复。
概览
BigQuery 支持在发生全区域服务中断时进行灾难恢复。BigQuery 灾难恢复依靠跨区域数据集复制来管理存储故障切换。在次要区域中创建数据集副本后,您可以控制计算和存储的故障切换行为,以在服务中断期间维护业务连续性。进行故障切换后,您可以在提升的区域中访问计算容量(槽)和复制的数据集。只有企业 Plus 版才支持灾难恢复。
托管式灾难恢复提供两种故障切换选项:硬故障切换和软故障切换。硬故障切换会立即将次要区域的预留和数据集副本提升为主要区域。即使当前主要区域处于离线状态,此操作也会继续进行,并且不会等待复制任何未复制的数据。因此在硬故障切换期间,可能会发生数据丢失。
进行故障切换之后,在副本的 replication_time 值之前在来源区域中提交数据的任何作业都可能需要在目标区域中重新运行。
与硬故障切换不同,软故障切换会等待主要区域中提交的所有预留和数据集更改复制到次要区域,然后才会完成故障切换流程。软故障切换要求主要区域和次要区域都可用。启动软故障切换会为预留设置 softFailoverStartTime。在软故障切换完成后,系统会清除 softFailoverStartTime。
如需启用灾难恢复,您需要在主要区域(即数据集在进行故障切换之前所在的区域)中创建企业 Plus 版预留。配对区域中的备用计算容量包含在企业 Plus 版预留中。您随后可将一个数据集附加到此预留,以便为该数据集启用故障切换。仅当数据集进行回填,并且具有与预留相同的配对主要位置和次要位置时,您才能将数据集附加到预留。将数据集附加到故障切换预留后,只有企业 Plus 版预留才能对这些数据集进行写入,并且您无法对数据集执行跨区域复制提升。您可以从附加到故障切换预留(采用任何容量模型)的数据集读取数据。 如需详细了解预留,请参阅工作负载管理简介。
进行故障切换后,可立即在次要区域中使用主要区域的计算容量。这种可用性适用于预留基准(无论是否使用它)。
在测试或应对实际灾难的过程中,您必须主动选择进行故障切换。您不应在 10 分钟内多次进行故障切换。在数据复制场景中,回填是指使用在副本创建或生效之前存在的历史数据来填充数据集副本的过程。数据集必须先完成其回填,然后您才能故障切换到数据集。
下图展示了托管式灾难恢复的架构:
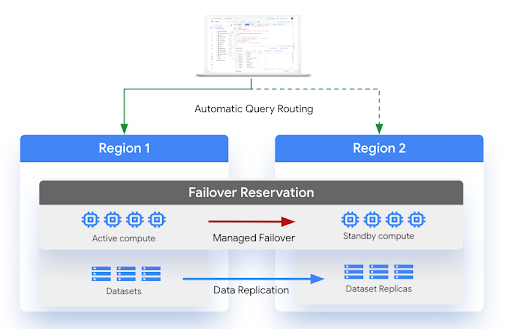
限制
BigQuery 灾难恢复存在以下限制:
BigQuery 灾难恢复受到与跨区域数据集复制相同的限制。
进行故障切换后的自动扩缩取决于次要区域中的计算容量可用性。次要区域中仅提供预留基准。
INFORMATION_SCHEMA.RESERVATIONS视图不包含故障切换详细信息。如果您的同一个管理项目有多个故障切换预留,但这些预留的附加数据集使用不同的次要位置,请不要将一个故障切换预留与附加到不同故障切换预留的数据集搭配使用。
如果您要将现有预留转换为故障切换预留,则现有预留的预留分配不能超过 1,000 个。
故障切换预留附加的数据集数量不能超过 1,000 个。
只有在来源区域和目标区域均可用的情况下,才能触发软故障切换。
如果在预留复制期间出现任何暂时性错误或其他错误,则无法触发软故障切换。例如,如果次要区域中的槽配额不足导致无法更新预留。
在软故障切换处于有效状态期间,无法更新预留和附加的数据集,但仍可从中读取数据。
在软故障切换处于有效状态期间,在故障切换预留上运行的作业可能无法在该预留上运行,这是因为在故障切换操作期间,数据集和预留路由会发生暂时性更改。不过,这些作业会在启动任何软故障切换之前以及完成软故障切换之后使用预留槽。
位置
创建故障切换预留时,可使用以下区域:
| 位置代码 | 区域名称 | 区域说明 |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
台湾 | |
ASIA-SOUTHEAST1 |
新加坡 | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
悉尼 | |
AUSTRALIA-SOUTHEAST2 |
墨尔本 | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
蒙特利尔 | |
NORTHAMERICA-NORTHEAST2 |
多伦多 | |
DE |
||
EUROPE-WEST3 |
法兰克福 | |
EUROPE-WEST10 |
柏林 | |
EU |
||
EU |
欧盟多区域 | |
EUROPE-CENTRAL2 |
华沙 | |
EUROPE-NORTH1 |
芬兰 | |
EUROPE-SOUTHWEST1 |
马德里 | |
EUROPE-WEST1 |
比利时 | |
EUROPE-WEST3 |
法兰克福 | |
EUROPE-WEST4 |
荷兰 | |
EUROPE-WEST8 |
米兰 | |
EUROPE-WEST9 |
巴黎 | |
IN |
||
ASIA-SOUTH1 |
孟买 | |
ASIA-SOUTH2 |
德里 | |
US |
||
US |
美国多区域 | |
US-CENTRAL1 |
艾奥瓦 | |
US-EAST1 |
南卡罗来纳 | |
US-EAST4 |
北弗吉尼亚 | |
US-EAST5 |
哥伦布 | |
US-SOUTH1 |
达拉斯 | |
US-WEST1 |
俄勒冈 | |
US-WEST2 |
洛杉矶 | |
US-WEST3 |
盐湖城 | |
US-WEST4 |
拉斯维加斯 |
必须在 ASIA、AU、CA、DE、EU、IN 或 US 中选择区域对。例如,US 中的区域不能与 EU 中的区域配对。
如果您的 BigQuery 数据集位于多区域位置,则不能使用以下区域对。此限制是必需的,可确保您的故障切换预留和数据在复制后位于不同的地理位置。如需详细了解多区域中包含的区域,请参阅多区域。
us-central1-us多区域us-west1-us多区域eu-west1-eu多区域eu-west4-eu多区域
准备工作
- 验证您是否拥有更新预留的
bigquery.reservations.updateIdentity and Access Management (IAM) 权限。 - 验证您是否已有针对复制进行了配置的数据集。有关详情,请参阅复制数据集。
增强型复制
灾难恢复使用增强型复制,以便更快地跨区域复制数据,从而降低面临数据丢失的风险,最大限度地减少服务停机时间,并在发生区域级服务中断后,有助于支持提供不间断的服务。
增强型复制不适用于初始回填操作。初始回填操作完成后,增强型复制旨在将数据集复制到单个故障切换区域对,并在 15 分钟内完成次要副本复制,前提是未超出带宽配额且不存在用户错误。
恢复时间目标
恢复时间目标 (RTO) 是指在发生灾难时,BigQuery 允许的恢复目标时间。如需详细了解 RTO,请参阅灾难恢复规划基础知识。在您启动故障切换后,托管式灾难恢复的 RTO 为 5 分钟。由于此 RTO,在开始故障切换过程后的 5 分钟内,次要区域就会有可用容量。
恢复点目标
恢复点目标 (RPO) 是指必须能够恢复数据的最近时间点。如需详细了解 RPO,请参阅灾难恢复规划的基础知识。托管式灾难恢复具有针对每个数据集定义的 RPO。RPO 旨在恢复主副本的 15 分钟内保留次要副本。为了达到此 RPO,不得超出带宽配额,并且不得发生任何用户错误。
Quota
您必须先在次要区域中拥有所选的计算容量,然后才能配置故障切换预留。如果次要区域中没有可用的配额,则无法配置或更新预留。 如需了解详情,请参阅配额和限制。
增强型复制带宽存在配额。如需了解详情,请参阅配额和限制。
价格
配置托管式灾难恢复需要以下定价方案:
计算容量:您必须购买企业 Plus 版。
增强型复制:灾难恢复在复制期间依赖于增强型复制。您需要根据物理字节数,按复制的物理 GiB 量付费。如需了解详情,请参阅适用于增强型复制的数据复制数据传输价格。
存储:次要区域中的存储字节数的计费价格与主要区域中的存储字节数相同。如需了解详情,请参阅存储价格。
客户只需要为主要区域中的计算容量付费。次要计算容量(基于预留基准)在次要区域中可用,无需额外付费。除非预留进行了故障切换,否则空闲槽不能使用次要计算容量。
如果您需要在次要区域中执行过时数据读取,则必须购买额外的计算容量。
创建或更改企业 Plus 版预留
在将数据集附加到预留之前,您必须先创建企业 Plus 版预留或更改现有预留,然后对其进行配置以用于灾难恢复。
创建预留
从下列选项中选择一项:
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击容量管理,然后点击创建预留。
在预留名称字段中,输入预留的名称。
在位置列表中,选择相应位置。
在版本列表中,选择企业 Plus 版。
在预留大小上限选择器列表中,选择预留大小上限。
可选:在基准槽数字段中,输入预留的基准槽数。
可用自动扩缩槽的数量为预留大小上限值减去基准槽数值。例如,如果您创建了一个包含 100 个基准槽且预留大小上限为 400 的预留,则该预留包含 300 个自动扩缩槽。如需详细了解基准槽,请参阅将预留与基准槽和自动扩缩槽搭配使用。
在次要位置列表中,选择次要位置。
如需停用空闲槽共享并且仅使用指定的槽容量,请点击忽略空闲槽切换开关。
如需展开高级设置部分,请点击 展开箭头。
可选:如需设置目标作业并发,请点击开启替换自动目标作业并发切换开关,然后为目标作业并发输入值。槽明细显示在费用估算表中。预留摘要显示在容量摘要表中。
点击保存。
新预留会显示在槽预留标签页中。
SQL
如需创建预留,请使用 CREATE RESERVATION 数据定义语言 (DDL) 语句。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
替换以下内容:
ADMIN_PROJECT_ID:拥有预留资源的管理项目的项目 ID。LOCATION:预留的位置。如果您选择 BigQuery Omni 位置,则您的版本选项仅限于企业版。RESERVATION_NAME:预留的名称。该名称必须以小写字母或数字开头和结尾,并且只能包含小写字母、数字和短划线。
NUMBER_OF_BASELINE_SLOTS:要分配给预留的基准槽数。您不能在同一预留中设置slot_capacity选项和edition选项。SECONDARY_LOCATION:预留的次要位置。如果发生服务中断,则附加到此预留的任何数据集都会故障切换到此位置。
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
更改现有预留
从下列选项中选择一项:
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击容量管理。
点击槽预留标签页。
找到您要更新的预留。
点击 预留操作,然后点击修改。
在次要位置字段中,输入次要位置。
点击保存。
SQL
如需对预留添加或更改次要位置,请使用 ALTER RESERVATION SET OPTIONS DDL 语句。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
替换以下内容:
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
将数据集附加到预留
如需为之前创建的预留启用灾难恢复,请完成以下步骤。数据集必须已配置为在与预留相同的主要和次要区域中进行复制。如需了解详情,请参阅跨区域数据集复制。
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击容量管理,然后点击槽预留标签页。
点击要向其附加数据集的预留。
点击灾难恢复标签页。
点击添加故障切换数据集。
输入要与预留关联的数据集的名称。
点击添加。
SQL
如需将数据集附加到预留,请使用 ALTER SCHEMA SET OPTIONS DDL 语句。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
替换以下内容:
DATASET_NAME:数据集的名称。ADMIN_PROJECT_ID.RESERVATION_NAME:您要将数据集关联到的预留的名称。
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
将数据集从预留中分离
如需停止通过预留管理数据集的故障切换行为,请将数据集从预留中分离。这不会更改数据集的当前主副本,也不会移除任何现有的数据集副本。如需详细了解如何在分离数据集后移除数据集副本,请参阅移除数据集副本。
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击容量管理,然后点击槽预留标签页。
点击您要从中分离数据集的预留。
点击灾难恢复标签页。
展开数据集的主副本的 操作选项。
点击移除。
SQL
如需将数据集从预留中分离,请使用 ALTER SCHEMA SET OPTIONS DDL 语句。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
替换以下内容:
DATASET_NAME:数据集的名称。
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
启动故障切换
如果发生区域级服务中断,您必须手动将预留故障切换到副本所使用的位置。对预留进行故障切换还包括所有关联的数据集。如需手动对预留进行故障切换,请执行以下操作:
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击灾难恢复。
点击您要故障切换到的预留的名称。
选择硬故障切换模式(默认)或软故障切换模式。
点击故障切换。
SQL
如需对预留添加或更改次要位置,请使用 ALTER RESERVATION SET OPTIONS DDL 语句并将 is_primary 设置为 TRUE。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
替换以下内容:
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
监控
如需确定副本的状态,请查询 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 视图。例如:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
以下查询返回过去七天内在其数据集为故障切换数据集时会失败的作业:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
请替换以下内容:
PROJECT_ID:项目 ID。DATASET_ID:数据集 ID。LOCATION:位置。