在 JupyterLab 內查詢 BigQuery 中的資料
本頁說明如何透過 Vertex AI Workbench 執行個體的 JupyterLab 介面,查詢儲存在 BigQuery 中的資料。
在筆記本 (IPYNB) 檔案中查詢 BigQuery 資料的方法
如要從 JupyterLab 筆記本檔案內查詢 BigQuery 資料,可以使用 %%bigquery magic 指令,以及 Python 專用的 BigQuery 用戶端程式庫。
Vertex AI Workbench 執行個體也包含 BigQuery 整合功能,可讓您在 JupyterLab 介面中瀏覽及查詢資料。
本頁面說明如何使用這些方法。
事前準備
如果還沒有,請建立 Vertex AI Workbench 執行個體。
必要的角色
為確保執行個體的服務帳戶具備在 BigQuery 中查詢資料的必要權限,請要求管理員授予執行個體的服務帳戶專案的「服務使用情形個人使用者」(roles/serviceusage.serviceUsageConsumer) IAM 角色。
管理員或許也能透過自訂角色或其他預先定義的角色,將必要權限授予執行個體的服務帳戶。
開啟 JupyterLab
前往 Google Cloud 控制台的「Instances」(執行個體) 頁面。
按一下 Vertex AI Workbench 執行個體名稱旁的「Open JupyterLab」(開啟 JupyterLab)。
Vertex AI Workbench 執行個體會開啟 JupyterLab。
瀏覽 BigQuery 資源
BigQuery 整合功能提供窗格,可供您瀏覽有權存取的 BigQuery 資源。
在 JupyterLab 導覽選單中,點選「Notebooks 中的 BigQuery」
 。
。「BigQuery」BigQuery窗格會列出可用的專案和資料集,您可以在其中執行下列工作:
- 如要查看資料集說明,請按兩下資料集名稱。
- 如要顯示資料集的資料表、檢視區塊和模型,請展開該資料集。
- 如要在 JupyterLab 中以分頁形式開啟摘要說明,請按兩下表格、檢視畫面或模型。
注意:在資料表的摘要說明中,按一下「預覽」分頁標籤,即可預覽資料表資料。下圖顯示
bigquery-public-data專案中google_trends資料集的international_top_terms資料表預覽畫面: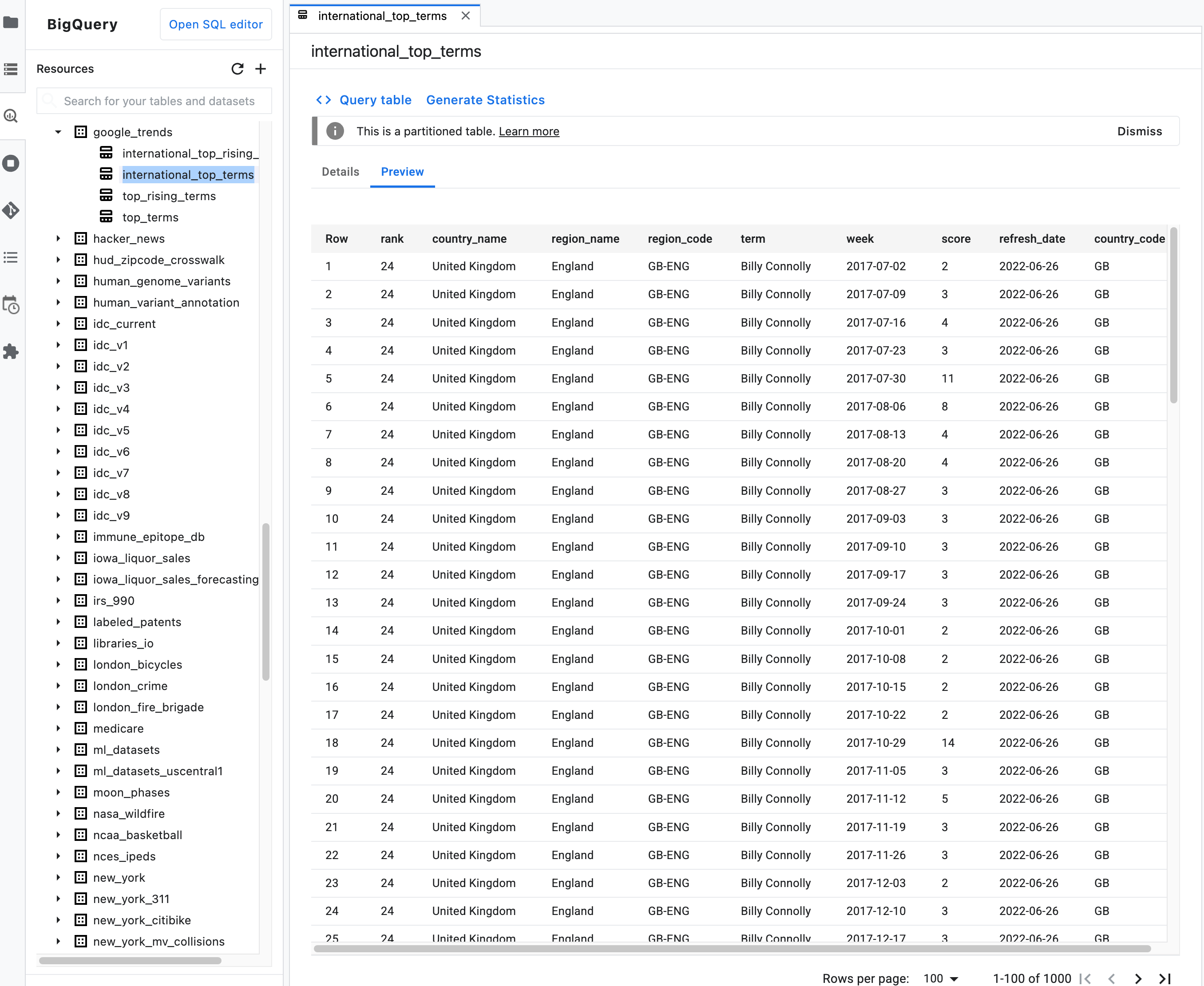
使用 %%bigquery magic 指令查詢資料
在本節中,您會在筆記本儲存格中直接撰寫 SQL,並將資料從 BigQuery 讀取至 Python 筆記本。
使用單一或雙百分比字元 (% 或 %%) 的神奇指令,可讓您在筆記本中使用最少的語法與 BigQuery 互動。Vertex AI Workbench 執行個體會自動安裝 Python 專用的 BigQuery 用戶端程式庫。在幕後,%%bigquery 神奇指令會使用 Python 專用的 BigQuery 用戶端程式庫執行指定查詢、將結果轉換為 pandas DataFrame、選擇是否要將結果儲存到變數,然後顯示結果。
注意:從 google-cloud-bigquery Python 套件 1.26.0 版開始,系統預設會使用 BigQuery Storage API 從 %%bigquery magics 下載結果。
如要開啟筆記本檔案,請依序選取「File」>「New」>「Notebook」。
在「Select Kernel」對話方塊中,選取「Python 3」,然後按一下「Select」。
系統會開啟新的 IPYNB 檔案。
如要在資料集中取得各國家/地區的區域數量,請輸入下列陳述式:
international_top_terms%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
按一下「Run cell」(執行儲存格) 。
輸出結果會與下列內容相似:
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
在下一個儲存格 (前一個儲存格的輸出內容下方) 中,輸入下列指令來執行相同的查詢,但這次會將結果儲存至名為
regions_by_country的新 pandas DataFrame。您可以使用%%bigqueryMagic 指令的引數提供該名稱。%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
注意:如要進一步瞭解
%%bigquery指令的可用引數,請參閱用戶端程式庫魔法說明文件。按一下「Run cell」(執行儲存格) 。
在下一個儲存格中輸入下列指令,查看您剛讀取的前幾列查詢結果:
regions_by_country.head()按一下「Run cell」(執行儲存格) 。
pandas DataFrame
regions_by_country已可繪製圖表。
直接使用 BigQuery 用戶端程式庫查詢資料
在本節中,您會直接使用 Python 專用的 BigQuery 用戶端程式庫,將資料讀取至 Python 筆記本。
用戶端程式庫可讓您進一步掌控查詢,並為查詢和工作使用更複雜的設定。程式庫與 pandas 之間的整合可以讓您將宣告式 SQL 與命令式程式碼 (Python) 的功能結合在一起,以分析、視覺化及轉換資料。
注意:您可以使用多種 Python 資料分析、資料疊加及視覺化程式庫,例如 numpy、pandas、matplotlib 等。其中有數種程式庫會以 DataFrame 物件為建構基礎。
在下一個儲存格中輸入下列 Python 程式碼,匯入 Python 專用的 BigQuery 用戶端程式庫並初始化用戶端:
from google.cloud import bigquery client = bigquery.Client()BigQuery 用戶端是用來與 BigQuery API 收發訊息。
按一下「Run cell」(執行儲存格) 。
在下一個儲存格中,輸入下列程式碼,以擷取美國每日熱門搜尋字詞的百分比
top_terms,這些字詞會依間隔天數重疊。這裡的概念是查看每天的熱門字詞,並瞭解這些字詞與前一天、前 2 天、前 3 天等熱門字詞的重疊百分比 (約一個月內的所有日期配對)。sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
使用的 SQL 會封裝在 Python 字串中,然後傳遞至
query()方法,以執行查詢。to_dataframe方法會等待查詢完成,並使用 BigQuery Storage API 將結果下載至 pandas DataFrame。按一下 「執行儲存格」。
查詢結果的前幾列會顯示在程式碼儲存格下方。
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
如要進一步瞭解如何使用 BigQuery 用戶端程式庫,請參閱快速入門導覽課程「使用用戶端程式庫」。
使用 Vertex AI Workbench 中的 BigQuery 整合功能查詢資料
整合 BigQuery 後,您還能透過兩種方法查詢資料。這些方法與使用 %%bigquery 魔法指令不同。
儲存格內查詢編輯器是一種儲存格類型,可在筆記本檔案中使用。
獨立查詢編輯器會在 JupyterLab 中以獨立分頁開啟。
內嵌式
如要使用儲存格內查詢編輯器查詢 BigQuery 資料表中的資料,請完成下列步驟:
在 JupyterLab 中開啟筆記本 (IPYNB) 檔案,或建立新的檔案。
如要建立儲存格內查詢編輯器,請按一下儲存格,然後點選儲存格右側的「BigQuery 整合」按鈕。或者,在 Markdown 儲存格中輸入
#@BigQuery。BigQuery 整合功能會將儲存格轉換為儲存格內查詢編輯器。
在
#@BigQuery下方的新行中,使用 BigQuery 支援的陳述式和 SQL 方言編寫查詢。如果系統在查詢中偵測到錯誤,查詢編輯器的右上角會顯示錯誤訊息。如果查詢有效,系統會顯示預估處理的位元組數。按一下「提交查詢」。查詢結果會隨即顯示在畫面上。 根據預設,查詢結果會以每頁 100 列的方式分頁,總共最多 1,000 列,但您可以在結果表格底部變更這些設定。在查詢編輯器中,請將查詢限制為僅包含驗證查詢所需的資料。您會在筆記本儲存格中再次執行這項查詢,並視需要調整限制,以擷取完整結果集。
您可以按一下「查詢並載入為 DataFrame」,自動新增含有程式碼片段的儲存格,其中會匯入 Python 專用的 BigQuery 用戶端程式庫、在筆記本儲存格中執行查詢,並將結果儲存在名為
df的 pandas DataFrame 中。
獨立式
如要使用獨立查詢編輯器查詢 BigQuery 資料表中的資料,請完成下列步驟:
在 JupyterLab 的「BigQuery in Notebooks」窗格中,按一下滑鼠右鍵選取資料表,然後選取「Query table」,或按兩下資料表,在另一個分頁中開啟說明,然後按一下「Query table」連結。
使用 BigQuery 支援的陳述式和 SQL 方言編寫查詢。如果系統在查詢中偵測到錯誤,查詢編輯器的右上角會顯示錯誤訊息。如果查詢有效,系統會顯示預估處理的位元組數。
按一下「提交查詢」。查詢結果會隨即顯示在畫面上。 根據預設,查詢結果會以每頁 100 列的方式分頁,總共最多 1,000 列,但您可以在結果表格底部變更這些設定。在查詢編輯器中,請將查詢限制為僅包含驗證查詢所需的資料。您會在筆記本儲存格中再次執行這項查詢,並視需要調整限制,以擷取完整結果集。
您可以按一下「Copy code for DataFrame」(複製 DataFrame 的程式碼),複製程式碼片段,匯入 Python 專用的 BigQuery 用戶端程式庫、在筆記本儲存格中執行查詢,並將結果儲存在名為
df的 pandas DataFrame 中。將這段程式碼貼到要執行的筆記本儲存格中。
查看查詢記錄及重複使用查詢
如要在 JupyterLab 中以分頁的形式查看查詢記錄,請按照下列步驟操作:
在 JupyterLab 導覽選單中,按一下「
筆記本中的 BigQuery」,開啟「BigQuery」窗格。在「BigQuery」窗格中向下捲動,然後按一下「查詢記錄」。
系統會在新的分頁中開啟查詢清單,您可以在這裡執行下列工作:
- 如要查看查詢的詳細資料,例如工作 ID、查詢執行時間和執行時間長度,請按一下查詢。
- 如要修改查詢、再次執行查詢,或將查詢複製到筆記本以供日後使用,請按一下「在編輯器中開啟查詢」。
後續步驟
如要查看如何以視覺化方式呈現 BigQuery 資料表中的資料,請參閱在 JupyterLab 中探索 BigQuery 資料並以視覺化方式呈現。
如要進一步瞭解如何撰寫 BigQuery 查詢,請參閱「執行互動式和批次查詢工作」一文。
瞭解如何控管 BigQuery 資料集的存取權。