Consultar datos de BigQuery desde JupyterLab
En esta página se explica cómo consultar datos almacenados en BigQuery desde la interfaz de JupyterLab de tu instancia de Vertex AI Workbench.
Métodos para consultar datos de BigQuery en archivos de cuaderno (IPYNB)
Para consultar datos de BigQuery desde un archivo de cuaderno de JupyterLab, puedes usar el comando mágico %%bigquery y la biblioteca de cliente de BigQuery para Python.
Las instancias de Vertex AI Workbench también incluyen una integración con BigQuery que te permite consultar datos desde la interfaz de JupyterLab.
En esta página se describe cómo usar cada uno de estos métodos.
Antes de empezar
Si aún no lo has hecho, crea una instancia de Vertex AI Workbench.
Roles obligatorios
Para asegurarte de que la cuenta de servicio de tu instancia tiene los permisos necesarios para consultar datos en BigQuery, pide a tu administrador que le conceda el rol de gestión de identidades y accesos de consumidor de uso de servicios (roles/serviceusage.serviceUsageConsumer) en el proyecto.
Es posible que tu administrador también pueda conceder a la cuenta de servicio de tu instancia los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Abrir JupyterLab
En la consola, ve a la página Instancias. Google Cloud
Junto al nombre de tu instancia de Vertex AI Workbench, haz clic en Abrir JupyterLab.
Tu instancia de Vertex AI Workbench abre JupyterLab.
Consultar recursos de BigQuery
La integración de BigQuery proporciona un panel para consultar los recursos de BigQuery a los que tiene acceso.
En el menú de navegación de JupyterLab, haz clic en
 BigQuery in Notebooks.
BigQuery in Notebooks.En el panel BigQuery se muestran los proyectos y conjuntos de datos disponibles, donde puedes realizar las siguientes tareas:
- Para ver la descripción de un conjunto de datos, haz doble clic en su nombre.
- Para mostrar las tablas, las vistas y los modelos de un conjunto de datos, despliega el conjunto de datos.
- Para abrir una descripción de resumen como pestaña en JupyterLab, haz doble clic en una tabla, una vista o un modelo.
Nota: En la descripción de resumen de una tabla, haga clic en la pestaña Vista previa para ver los datos de la tabla. En la siguiente imagen se muestra una vista previa de la tabla
international_top_termsdel conjunto de datosgoogle_trendsdel proyectobigquery-public-data: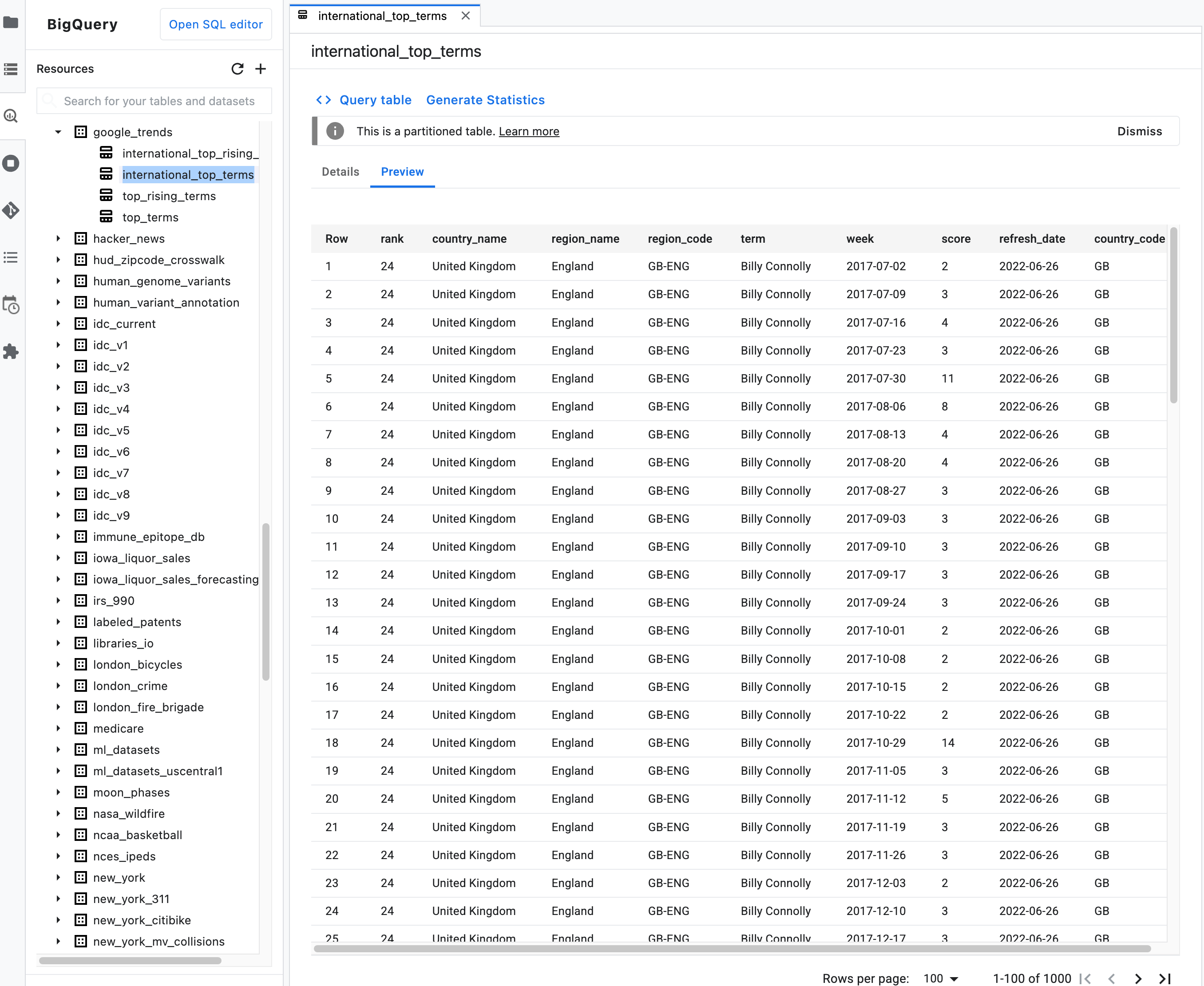
Consultar datos con el comando mágico %%bigquery
En esta sección, escribirás código SQL directamente en celdas de un cuaderno y leerás datos de BigQuery en el cuaderno de Python.
Los comandos mágicos que usan un carácter de porcentaje simple o doble (% o %%) te permiten usar una sintaxis mínima para interactuar con BigQuery en el cuaderno. La biblioteca de cliente de BigQuery para Python se instala automáticamente en una instancia de Vertex AI Workbench. En segundo plano, el comando mágico %%bigquery usa la biblioteca de cliente de BigQuery para Python con el fin de ejecutar la consulta proporcionada, convertir los resultados en un DataFrame de pandas, guardar los resultados en una variable (opcional) y, a continuación, mostrarlos.
Nota: Desde la versión 1.26.0 del paquete de google-cloud-bigquery Python, las %%bigquery mágicas usan de forma predeterminada la API Storage de BigQuery para descargar los resultados.
Para abrir un archivo de cuaderno, selecciona Archivo > Nuevo > Cuaderno.
En el cuadro de diálogo Seleccionar kernel, elige Python 3 y, a continuación, haz clic en Seleccionar.
Se abrirá el nuevo archivo IPYNB.
Para obtener el número de regiones por país en el
international_top_termsconjunto de datos, introduce la siguiente instrucción:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
En la siguiente celda (debajo de la salida de la celda anterior), introduce el siguiente comando para ejecutar la misma consulta, pero esta vez guarda los resultados en un nuevo DataFrame de pandas llamado
regions_by_country. Para proporcionar ese nombre, usa un argumento con el comando mágico%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Nota: Para obtener más información sobre los argumentos disponibles para el comando
%%bigquery, consulta la documentación de los comandos mágicos de la biblioteca de cliente.Haz clic en Ejecutar celda.
En la siguiente celda, introduce el siguiente comando para ver las primeras filas de los resultados de la consulta que acabas de leer:
regions_by_country.head()Haz clic en Ejecutar celda.
El DataFrame de pandas
regions_by_countryestá listo para representarse.
Consultar datos directamente con la biblioteca cliente de BigQuery
En esta sección, usarás la biblioteca de cliente de BigQuery para Python directamente para leer datos en el cuaderno de Python.
La biblioteca de cliente te ofrece más control sobre tus consultas y te permite usar configuraciones más complejas para consultas y trabajos. Las integraciones de la biblioteca con pandas te permiten combinar la potencia de SQL declarativo con código imperativo (Python) para analizar, visualizar y transformar tus datos.
Nota: Puedes usar varias bibliotecas de Python para analizar, organizar y visualizar datos, como numpy, pandas, matplotlib y muchas otras. Varias de estas bibliotecas se basan en un objeto DataFrame.
En la siguiente celda, introduce el siguiente código de Python para importar la biblioteca de cliente de BigQuery para Python e inicializar un cliente:
from google.cloud import bigquery client = bigquery.Client()El cliente de BigQuery se usa para enviar y recibir mensajes de la API de BigQuery.
Haz clic en Ejecutar celda.
En la siguiente celda, introduce el siguiente código para obtener el porcentaje de los términos principales diarios de EE. UU.
top_termsque se solapan a lo largo del tiempo según el número de días de diferencia. La idea es analizar los términos principales de cada día y ver qué porcentaje de ellos se solapan con los términos principales del día anterior, de hace dos días, de hace tres días, etc. (para todos los pares de fechas de un periodo de aproximadamente un mes).sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
El SQL que se utiliza se encapsula en una cadena de Python y, a continuación, se pasa al método
query()para ejecutar una consulta. El métodoto_dataframeespera a que finalice la consulta y descarga los resultados en un DataFrame de pandas mediante la API Storage de BigQuery.Haz clic en Ejecutar celda.
Las primeras filas de los resultados de la consulta aparecen debajo de la celda de código.
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
Para obtener más información sobre cómo usar las bibliotecas de cliente de BigQuery, consulta la guía de inicio rápido Usar bibliotecas de cliente.
Consultar datos mediante la integración de BigQuery en Vertex AI Workbench
La integración de BigQuery ofrece dos métodos adicionales para consultar datos. Estos métodos son diferentes a los que se usan con el comando mágico %%bigquery.
El editor de consultas en la celda es un tipo de celda que puedes usar en tus archivos de cuaderno.
El editor de consultas independiente se abre en una pestaña independiente de JupyterLab.
In-cell
Para usar el editor de consultas en la celda y consultar datos de una tabla de BigQuery, sigue estos pasos:
En JupyterLab, abre un archivo de cuaderno (IPYNB) o crea uno.
Para crear un editor de consultas en la celda, haz clic en la celda y, a continuación, en el botón Integración de BigQuery situado a la derecha de la celda. También puedes introducir
#@BigQueryen una celda de Markdown.La integración de BigQuery convierte la celda en un editor de consultas insertado en la celda.
En una línea nueva debajo de
#@BigQuery, escribe tu consulta con las declaraciones y los dialectos de SQL compatibles de BigQuery. Si se detectan errores en tu consulta, aparecerá un mensaje de error en la esquina superior derecha del editor de consultas. Si la consulta es válida, se muestra el número estimado de bytes que se van a procesar.Haz clic en Enviar consulta. Aparecerán los resultados de la consulta. De forma predeterminada, los resultados de las consultas se paginan en 100 filas por página y se limitan a 1000 filas en total, pero puede cambiar estos ajustes en la parte inferior de la tabla de resultados. En el editor de consultas, limita la consulta a los datos que necesites para verificarla. Volverás a ejecutar esta consulta en una celda de cuaderno, donde podrás ajustar el límite para obtener el conjunto de resultados completo si quieres.
Puedes hacer clic en Consultar y cargar como DataFrame para añadir automáticamente una nueva celda que contenga un segmento de código que importe la biblioteca de cliente de BigQuery para Python, ejecute tu consulta en una celda de cuaderno y almacene los resultados en un DataFrame de pandas llamado
df.
Independientes
Para usar el editor de consultas independiente y consultar datos de una tabla de BigQuery, sigue estos pasos:
En JupyterLab, en el panel BigQuery in Notebooks (BigQuery en cuadernos), haz clic con el botón derecho en una tabla y selecciona Query table (Consultar tabla). También puedes hacer doble clic en una tabla para abrir una descripción en una pestaña independiente y, a continuación, hacer clic en el enlace Query table (Consultar tabla).
Escribe tu consulta con las instrucciones y los dialectos de SQL admitidos de BigQuery. Si se detectan errores en tu consulta, aparecerá un mensaje de error en la esquina superior derecha del editor de consultas. Si la consulta es válida, se muestra el número estimado de bytes que se van a procesar.
Haz clic en Enviar consulta. Aparecerán los resultados de la consulta. De forma predeterminada, los resultados de las consultas se paginan en 100 filas por página y se limitan a 1000 filas en total, pero puede cambiar estos ajustes en la parte inferior de la tabla de resultados. En el editor de consultas, limita la consulta a los datos que necesites para verificarla. Volverás a ejecutar esta consulta en una celda de cuaderno, donde podrás ajustar el límite para obtener el conjunto de resultados completo si quieres.
Puedes hacer clic en Copiar código de DataFrame para copiar un segmento de código que importe la biblioteca cliente de BigQuery para Python, ejecute tu consulta en una celda de un cuaderno y almacene los resultados en un DataFrame de pandas llamado
df. Pega este código en una celda del cuaderno donde quieras ejecutarlo.
Ver el historial de consultas y reutilizar consultas
Para ver el historial de consultas como una pestaña en JupyterLab, sigue estos pasos:
En el menú de navegación de JupyterLab, haz clic en
BigQuery in Notebooks (BigQuery en cuadernos) para abrir el panel
BigQuery.En el panel BigQuery, desplázate hacia abajo y haz clic en Historial de consultas.
Se abrirá una lista de tus consultas en una pestaña nueva, donde podrás realizar tareas como las siguientes:
- Para ver los detalles de una consulta, como su ID de trabajo, cuándo se ejecutó y cuánto tiempo tardó, haz clic en la consulta.
- Para revisar la consulta, volver a ejecutarla o copiarla en tu cuaderno para usarla más adelante, haz clic en Abrir consulta en el editor.
Siguientes pasos
Para ver ejemplos de cómo visualizar los datos de tus tablas de BigQuery, consulta Consulta y visualiza datos en BigQuery desde JupyterLab.
Para obtener más información sobre cómo escribir consultas para BigQuery, consulta Ejecutar tareas de consulta interactivas y por lotes.
Consulta cómo controlar el acceso a los conjuntos de datos de BigQuery.