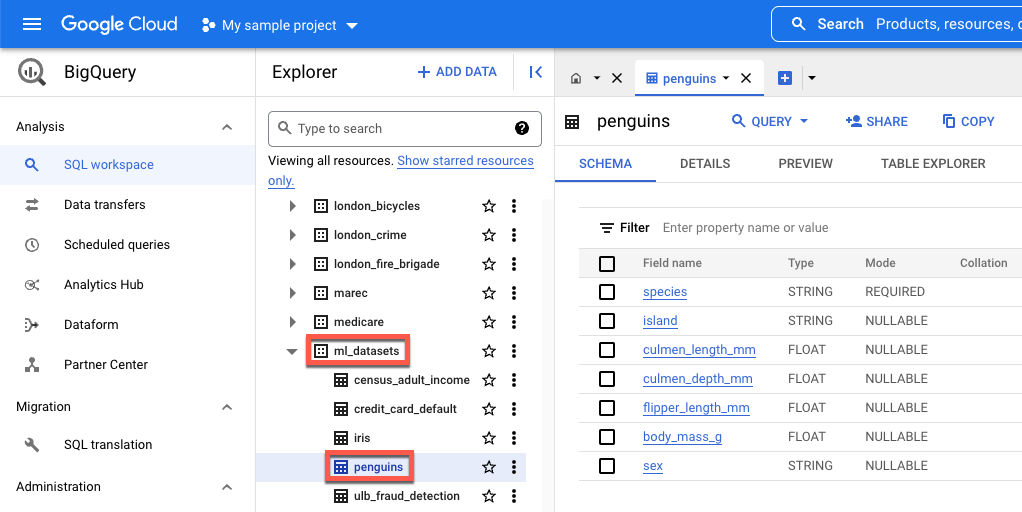
island- 企鵝的所在島嶼。culmen_length_mm:沿著企鵝嘴巴頂端的脊線長度。culmen_depth_mm:企鵝嘴的高度。flipper_length_mm- 企鵝鰭狀翅膀的長度。body_mass_g- 企鵝身體的質量。sex- 企鵝的性別。
下載、預先處理及分割資料
在本節中,您將下載公開的 BigQuery 資料集,並準備資料。如要準備資料,請按照下列步驟操作:
將類別特徵 (以字串而非數字描述的特徵) 轉換為數值資料。舉例來說,您可以將三種企鵝的名稱轉換為數值
0、1和2。移除資料集中未使用的任何資料欄。
移除所有無法使用的資料列。
將資料分割為兩個不同的資料組。每組資料都儲存在 pandas
DataFrame物件中。df_trainDataFrame包含用於訓練模型的資料。df_for_predictionDataFrame包含用於產生預測結果的資料。
處理資料後,程式碼會將三個類別欄的數值對應至其字串值,然後列印這些值,讓您查看資料的實際樣貌。
如要下載及處理資料,請在筆記本中執行下列程式碼:
import numpy as np
import pandas as pd
LABEL_COLUMN = "species"
# Define the BigQuery source dataset
BQ_SOURCE = "bigquery-public-data.ml_datasets.penguins"
# Define NA values
NA_VALUES = ["NA", "."]
# Download a table
table = bq_client.get_table(BQ_SOURCE)
df = bq_client.list_rows(table).to_dataframe()
# Drop unusable rows
df = df.replace(to_replace=NA_VALUES, value=np.NaN).dropna()
# Convert categorical columns to numeric
df["island"], island_values = pd.factorize(df["island"])
df["species"], species_values = pd.factorize(df["species"])
df["sex"], sex_values = pd.factorize(df["sex"])
# Split into a training and holdout dataset
df_train = df.sample(frac=0.8, random_state=100)
df_for_prediction = df[~df.index.isin(df_train.index)]
# Map numeric values to string values
index_to_island = dict(enumerate(island_values))
index_to_species = dict(enumerate(species_values))
index_to_sex = dict(enumerate(sex_values))
# View the mapped island, species, and sex data
print(index_to_island)
print(index_to_species)
print(index_to_sex)
以下是屬性 (非數值) 的列印對應值:
{0: 'Dream', 1: 'Biscoe', 2: 'Torgersen'}
{0: 'Adelie Penguin (Pygoscelis adeliae)', 1: 'Chinstrap penguin (Pygoscelis antarctica)', 2: 'Gentoo penguin (Pygoscelis papua)'}
{0: 'FEMALE', 1: 'MALE'}
前三個值是企鵝可能棲息的島嶼。後三個值很重要,因為它們會對應至您在本教學課程結尾收到的預測結果。第三列顯示 FEMALE 性別特徵對應至 0,而 MALE 性別特徵則對應至 1。
建立表格式資料集以訓練模型
在上一個步驟中,您已下載並處理資料。在這個步驟中,您會將儲存在 df_train DataFrame 中的資料載入 BigQuery 資料集。接著,您可以使用 BigQuery 資料集建立 Vertex AI 表格資料集。這個表格資料集可用於訓練模型。詳情請參閱「使用受管理的資料集」。
建立 BigQuery 資料集
如要建立用於建立 Vertex AI 資料集的 BigQuery 資料集,請執行下列程式碼。create_dataset 指令會傳回新的 BigQuery DataSet。
# Create a BigQuery dataset
bq_dataset_id = f"{project_id}.dataset_id_unique"
bq_dataset = bigquery.Dataset(bq_dataset_id)
bq_client.create_dataset(bq_dataset, exists_ok=True)
建立 Vertex AI 表格資料集
如要將 BigQuery 資料集轉換為 Vertex AI 表格資料集,請執行下列程式碼。您可以忽略關於使用表格資料訓練所需列數的警告。本教學課程旨在快速說明如何取得預測結果,因此我們會使用較少的資料集來說明如何產生預測結果。在實際情境中,表格資料集中至少要有 1, 000 列。create_from_dataframe 指令會傳回 Vertex AI TabularDataset。
# Create a Vertex AI tabular dataset
dataset = aiplatform.TabularDataset.create_from_dataframe(
df_source=df_train,
staging_path=f"bq://{bq_dataset_id}.table-unique",
display_name="sample-penguins",
)
您現在已擁有用於訓練模型的 Vertex AI 表格資料集。
(選用) 在 BigQuery 中查看公開資料集
如要查看本教學課程中使用的公開資料,可以前往 BigQuery 開啟。
在 Google Cloud的「搜尋」中輸入「BigQuery」,然後按下 Enter 鍵。
在搜尋結果中,按一下「BigQuery」
在「Explorer」視窗中,展開「bigquery-public-data」。
在「bigquery-public-data」下方,展開「ml_datasets」,然後點選「penguins」。
按一下「欄位名稱」下方的任何名稱,即可查看該欄位的資料。