Partindo do princípio de que já executou os tutoriais, esta página descreve as práticas recomendadas para a pesquisa de arquitetura neural. A primeira secção resume um fluxo de trabalho completo, que pode seguir para a sua tarefa de pesquisa de arquitetura neural. As outras secções fornecem uma descrição detalhada de cada passo. Recomendamos vivamente que consulte esta página na íntegra antes de executar a sua primeira tarefa de pesquisa de arquitetura neural.
Fluxo de trabalho sugerido
Aqui, resumimos um fluxo de trabalho sugerido para a pesquisa de arquitetura neural e fornecemos links para as secções correspondentes para mais detalhes:
- Divida o conjunto de dados de preparação para a pesquisa de fase 1.
- Certifique-se de que o seu espaço de pesquisa cumpre as nossas diretrizes.
- Execute a preparação completa com o modelo de base e obtenha uma curva de validação.
- Execute ferramentas de design de tarefas de proxy para encontrar a melhor tarefa de proxy.
- Faça verificações finais para a sua tarefa de proxy.
- Defina o número adequado de ensaios totais e ensaios paralelos e, em seguida, inicie a pesquisa.
- Monitorize o gráfico de pesquisa e pare-o quando convergir ou mostrar um grande número de erros ou não mostrar sinais de convergência.
- Execute a preparação completa com as ~10 principais tentativas escolhidas na sua pesquisa para o resultado final. Para o treino completo, pode usar mais aumento ou pesos pré-treinados para conseguir o melhor desempenho possível.
- Analise as métricas/dados guardados da pesquisa e tire conclusões para iterações futuras do espaço de pesquisa.
Pesquisa de arquitetura neural típica
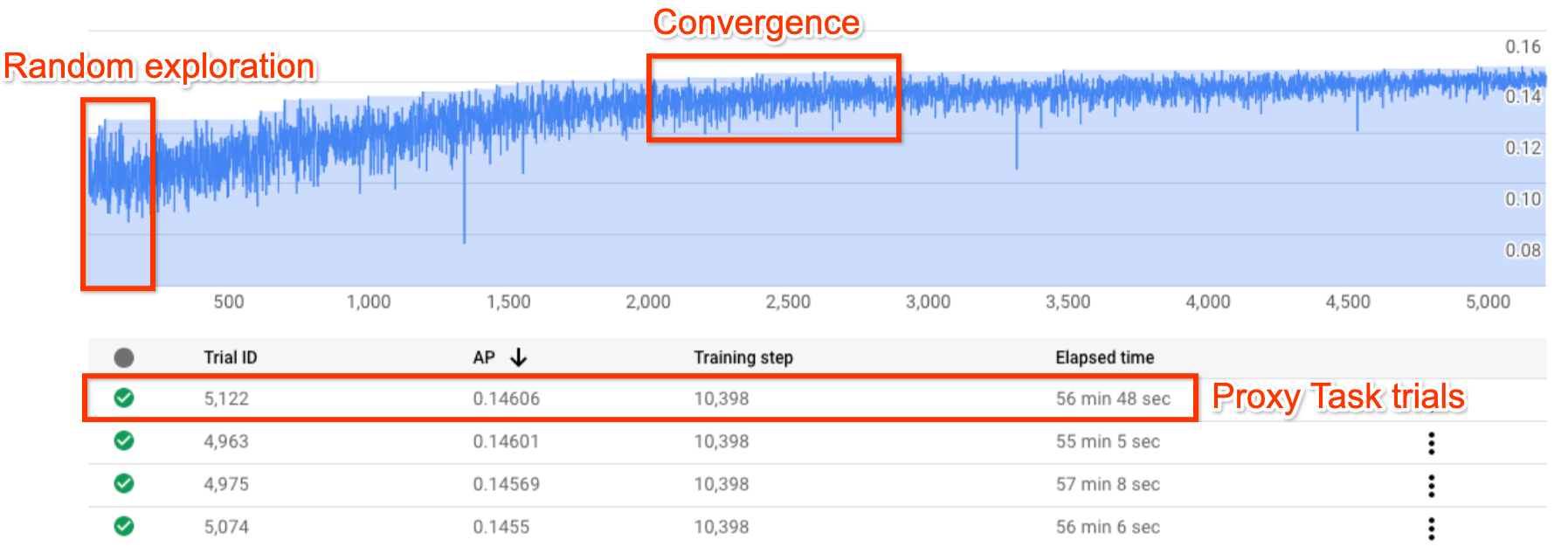
A figura acima mostra uma curva de pesquisa de arquitetura neural típica.
O Y-axis aqui mostra as recompensas de avaliação e o
X-axis mostra o número de avaliações lançadas até agora.
As primeiras ~100 a 200 tentativas são, na sua maioria, explorações aleatórias
do espaço de pesquisa pelo controlador.
Durante estas explorações iniciais, as recompensas apresentam uma grande variação porque estão a ser experimentados muitos tipos de modelos no espaço de pesquisa.
À medida que o número de testes aumenta, o controlador começa a encontrar modelos melhores. Por conseguinte, primeiro, a recompensa começa a aumentar e, mais tarde, a variação da recompensa e o crescimento da recompensa começam a diminuir, mostrando, assim, a convergência. O número de testes em que a convergência ocorre pode variar com base no tamanho do espaço de pesquisa, mas normalmente é da ordem de ~2000 testes.
Duas fases da pesquisa de arquitetura neural: tarefa de proxy e preparação completa
A pesquisa de arquitetura neural funciona em duas fases:
A pesquisa de fase 1 usa uma representação muito menor da preparação completa, que normalmente termina no prazo de 1 a 2 horas. Esta representação é denominada tarefa de proxy e ajuda a manter o custo de pesquisa baixo.
A fase 2 de preparação completa envolve a preparação completa dos principais ~10 modelos de pontuação da fase 1 de pesquisa. Devido à natureza estocástica da pesquisa, o modelo mais acima da fase 1 de pesquisa pode não ser o modelo mais acima durante a fase 2 de preparação completa e, por isso, é importante selecionar um conjunto de modelos para a preparação completa.
Uma vez que o controlador recebe o sinal de recompensa da tarefa de proxy mais pequena, em vez do treino completo, é importante encontrar uma tarefa de proxy ideal para a sua tarefa.
Custo da Neural Architecture Search
O custo da pesquisa de arquitetura neural é dado por:
search-cost = num-trials-to-converge * avg-proxy-task-cost.
Partindo do princípio de que o tempo de computação da tarefa de proxy é cerca de 1/30 do tempo de preparação completo e que o número de testes necessários para convergir é de cerca de 2000, o custo de pesquisa torna-se de cerca de 67 * full-training-cost.
Uma vez que o custo da pesquisa de arquitetura neural é elevado, é aconselhável dedicar tempo ao ajuste da tarefa de proxy e usar um espaço de pesquisa mais pequeno para a primeira pesquisa.
Divisão do conjunto de dados entre duas fases da pesquisa de arquitetura neural
Partindo do princípio de que já tem os dados de preparação e os dados de validação para a preparação de base, a seguinte divisão do conjunto de dados é recomendada para as duas fases da pesquisa de arquitetura neural (NAS):
- Stage1-search training: ~90% of training-data
Validação de pesquisa da fase 1: ~10% dos dados de preparação
Preparação de Stage2-full-training: 100% dos dados de preparação
Stage2-full-training validation: 100% of validation-data
A divisão de dados de stage2-full-training é igual à formação normal. No entanto, o stage1-search usa uma divisão de dados de preparação para validação. A utilização de dados de validação diferentes na fase 1 e na fase 2 ajuda a detetar qualquer parcialidade de pesquisa do modelo devido à divisão do conjunto de dados. Certifique-se de que os dados de preparação são bem misturados antes de os particionar ainda mais e que a divisão final de 10% dos dados de preparação tem uma distribuição semelhante à dos dados de validação originais.
Dados pequenos ou desequilibrados
A pesquisa de arquitetura não é recomendada com dados de preparação limitados ou para conjuntos de dados altamente desequilibrados em que algumas classes são muito raras. Se já estiver a usar aumentos pesados para a preparação de base devido à falta de dados, não recomendamos a pesquisa de modelos.
Neste caso, só pode executar a augmentation-search para pesquisar a melhor política de aumento em vez de pesquisar uma arquitetura ideal.
Design do espaço de pesquisa
A pesquisa de arquitetura não deve ser misturada com a pesquisa de aumento nem com a pesquisa de hiperparâmetros (como a taxa de aprendizagem ou as definições do otimizador). O objetivo da pesquisa de arquitetura é comparar o desempenho do modelo A com o do modelo B quando existem apenas diferenças baseadas na arquitetura. Por conseguinte, as definições de aumento e hiperparâmetros devem permanecer inalteradas.
A pesquisa de aumento pode ser feita numa fase diferente após a conclusão da pesquisa de arquitetura.
A pesquisa de arquitetura neural pode atingir 10^20 no tamanho do espaço de pesquisa. No entanto, se o seu espaço de pesquisa for maior, pode dividi-lo em partes mutuamente exclusivas. Por exemplo, pode pesquisar o codificador separadamente do descodificador ou do cabeçalho primeiro. Se ainda quiser fazer uma pesquisa conjunta em todas elas, pode criar um espaço de pesquisa mais pequeno em torno das melhores opções individuais encontradas anteriormente.
(Opcional) Pode dimensionar modelos a partir de blocos de design quando conceber um espaço de pesquisa. A pesquisa de design de blocos deve ser feita primeiro com um modelo reduzido. Isto pode manter o custo do tempo de execução da tarefa de proxy muito mais baixo. Em seguida, pode fazer uma pesquisa separada para aumentar a escala do modelo. Para mais informações, consulte
Examples of scaled down models.
Otimizar o tempo de formação e de pesquisa
Antes de executar a pesquisa de arquitetura neural, é importante otimizar o tempo de preparação do modelo de base. Isto permite-lhe poupar custos a longo prazo. Seguem-se algumas das opções para otimizar a preparação:
- Maximize a velocidade de carregamento de dados:
- Certifique-se de que o contentor onde os seus dados residem está na mesma região que a sua tarefa.
- Se usar o TensorFlow, consulte
Best practice summary. Também pode experimentar usar o formato TFRecord para os seus dados. - Se usar o PyTorch, siga as diretrizes para uma preparação eficiente do PyTorch.
- Use a programação distribuída para tirar partido de vários aceleradores ou várias máquinas.
- Use a formação de precisão mista
para obter uma aceleração significativa da formação e uma redução na utilização da memória.
Para a formação de precisão mista do TensorFlow,
consulte
Mixed Precision. - Alguns aceleradores (como o A100) são normalmente mais rentáveis.
- Ajuste o tamanho do lote para garantir que está a maximizar a utilização da GPU.
O gráfico seguinte mostra a subutilização das GPUs (a 50%).
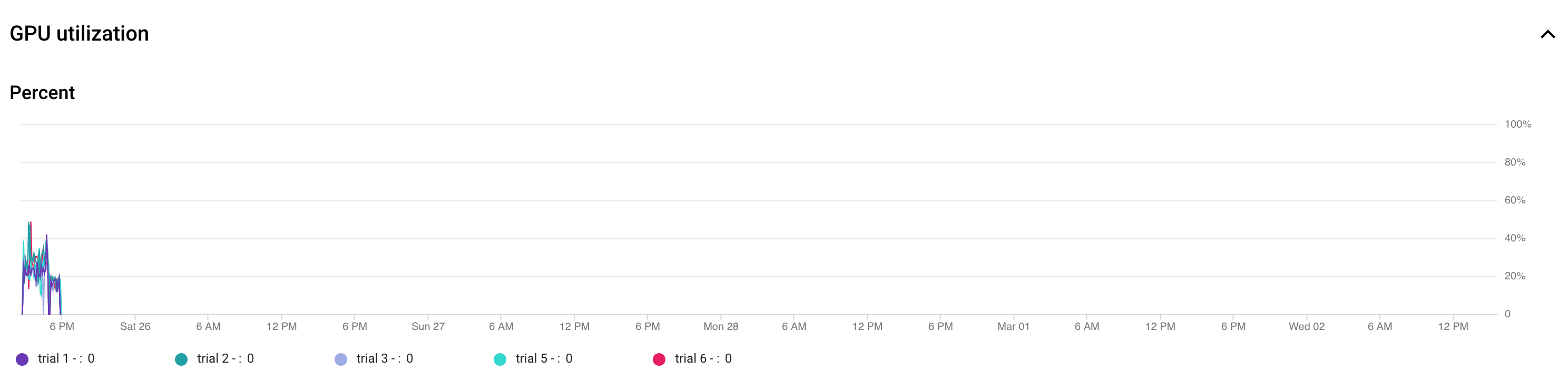 Aumentar o tamanho do lote pode ajudar a usar mais GPUs. No entanto, o tamanho do lote deve ser aumentado cuidadosamente, uma vez que pode aumentar os erros de falta de memória durante a pesquisa.
Aumentar o tamanho do lote pode ajudar a usar mais GPUs. No entanto, o tamanho do lote deve ser aumentado cuidadosamente, uma vez que pode aumentar os erros de falta de memória durante a pesquisa. - Se determinados blocos de arquitetura forem independentes do espaço de pesquisa, pode tentar carregar pontos de verificação pré-treinados para estes blocos para um treino mais rápido. Os pontos de verificação pré-formados devem ser iguais no espaço de pesquisa e não devem introduzir um desvio. Por exemplo, se o seu espaço de pesquisa for apenas para o descodificador, o codificador pode usar pontos de verificação pré-treinados.
Número de GPUs para cada teste de pesquisa
Use um número menor de GPUs por teste para reduzir o tempo de início. Por exemplo, o início de 2 GPUs demora 5 minutos, enquanto o início de 8 GPUs demora 20 minutos. É mais eficiente usar 2 GPUs por teste para executar uma tarefa de proxy de trabalho de pesquisa de arquitetura neural.
Avaliações totais e avaliações paralelas para a pesquisa
Total de definições de avaliação
Depois de pesquisar e selecionar a melhor tarefa de proxy, está tudo pronto para iniciar uma pesquisa completa. Não é possível saber antecipadamente quantos testes são necessários para a convergência. O número de testes em que a convergência ocorre pode variar com base no tamanho do espaço de pesquisa, mas, normalmente,é da ordem de aproximadamente 2000 testes.
Recomendamos uma definição muito elevada
para o --max_nas_trial: aproximadamente 5000 a 10 000 e,em seguida,cancelar a tarefa de pesquisa mais cedo se o
gráfico de pesquisa mostrar convergência.
Também tem a opção de retomar uma tarefa de pesquisa anterior através do comando search_resume.
No entanto, não pode retomar a pesquisa a partir de outra tarefa de retoma de pesquisa.
Por conseguinte, só pode retomar uma tarefa de pesquisa original uma vez.
Definição de testes paralelos
A tarefa stage1-search faz o processamento em lote executando --max_parallel_nas_trial tentativas em paralelo de cada vez. Isto é fundamental para reduzir o tempo de execução geral da tarefa de pesquisa. Pode calcular o número esperado de dias para a pesquisa:
days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Nota: inicialmente, pode usar 3000 como uma estimativa aproximada de trials-to-converge, que é um bom limite superior para começar. Pode usar inicialmente 2 horas como uma estimativa aproximada para o avg-trial-duration-in-hours, que é um bom limite superior para o tempo necessário para cada tarefa de proxy.
Recomendamos que use a definição --max_parallel_nas_trial de ~20 a 50, consoante a quantidade de quota de acelerador que o seu projeto tem e days-required-for-search.
Por exemplo, se definir --max_parallel_nas_trial como 20 e cada tarefa de proxy usar duas GPUs NVIDIA T4, deve ter reservado uma quota de, pelo menos, 40 GPUs NVIDIA T4. A definição
--max_parallel_nas_trial não afeta o resultado geral da pesquisa, mas afeta o days-required-for-search.
Também é possível uma definição mais pequena para max_parallel_nas_trial, como aproximadamente 10 (20 GPUs), mas, nesse caso, deve estimar aproximadamente o days-required-for-search e certificar-se de que está dentro do limite de tempo limite da tarefa.
Por predefinição, a tarefa stage2-full-training forma normalmente todas as experiências em paralelo. Normalmente, trata-se dos 10 principais testes em execução em paralelo. No entanto, se cada tentativa de stage2-full-training usar demasiadas GPUs (por exemplo, oito GPUs cada) para o seu exemplo de utilização e não tiver uma quota suficiente, pode executar manualmente tarefas de stage2 em lotes, como executar um stage2-full-training para apenas cinco tentativas primeiro e, em seguida, executar outro stage2-full-training para as 5 tentativas seguintes.
Limite de tempo predefinido da tarefa
O limite de tempo predefinido da tarefa de NAS é de 14 dias e, após esse período, a tarefa é cancelada. Se prevê que a tarefa vai ser executada durante mais tempo, pode tentar retomar a tarefa de pesquisa apenas mais uma vez durante 14 dias. Em geral, pode executar uma tarefa de pesquisa durante 28 dias, incluindo o currículo.
Definição de tentativas falhadas máximas
O número máximo de tentativas falhadas deve ser definido para cerca de 1/3 da definição de max_nas_trial. A tarefa é cancelada quando o número de tentativas com falhas atinge este limite.
Quando parar a pesquisa
Deve parar a pesquisa quando:
A curva de pesquisa começa a convergir (a variância diminui):
Nota: se não for usada nenhuma restrição de latência ou se for usada a restrição de latência rígida com um limite de latência flexível, a curva pode não mostrar um aumento na recompensa, mas deve continuar a mostrar a convergência. Isto deve-se ao facto de o controlador já ter observado boas precisões no início da pesquisa.Mais de 20% dos seus testes estão a apresentar recompensas inválidas (falhas):
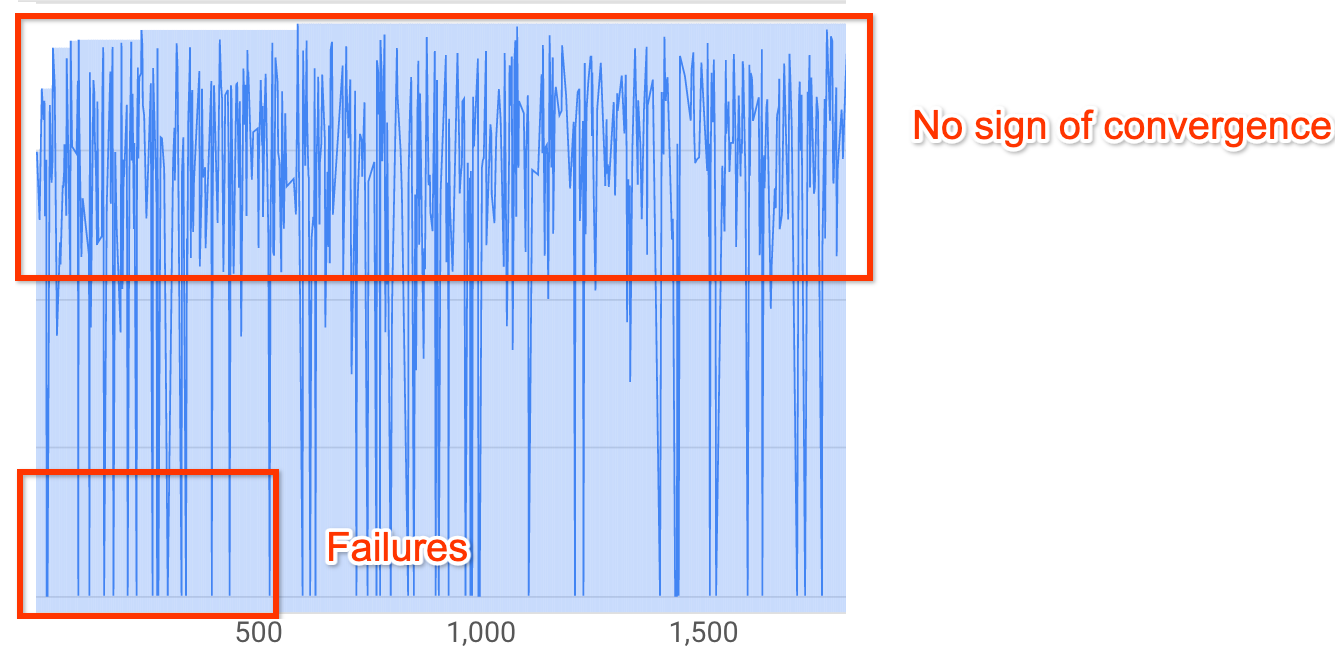
A curva de pesquisa não aumenta nem converge (conforme mostrado acima), mesmo após ~500 tentativas. Se mostrar algum aumento da recompensa ou diminuição da variância, pode continuar.