Antes de executar um job de pesquisa de arquitetura neural para procurar um modelo ideal, defina sua tarefa de proxy. O Stage1-search usa uma representação muito menor de um treinamento de modelo completo, que normalmente termina em duas horas. Essa representação é chamada de tarefa de proxy e reduz significativamente o custo de pesquisa. Cada teste durante a pesquisa treina um modelo usando as configurações de tarefa de proxy.
As seções a seguir descrevem o que está envolvido na aplicação do design de tarefas de proxy:
- Abordagens para criar uma tarefa de proxy.
- Requisitos de uma boa tarefa de proxy.
- Como usar as três ferramentas de design de tarefas de proxy para encontrar a tarefa de proxy ideal, o que reduz o custo da pesquisa e mantém a qualidade da pesquisa.
Abordagens para criar uma tarefa de proxy
Há três abordagens comuns para criar uma tarefa de proxy, incluindo:
- Usar menos etapas de treinamento.
- Usar um conjunto de dados de treinamento subamostrado.
- Usar um modelo reduzido.
Usar menos etapas de treinamento
A maneira mais simples de criar uma tarefa de proxy é reduzir o número de etapas de treinamento do treinador e informar uma pontuação ao controlador com base neste treinamento parcial.
Usar um conjunto de dados de treinamento subamostrado
Nesta seção, descrevemos o uso de um conjunto de dados de treinamento subamostrado para uma pesquisa de arquitetura e uma de política de aumento.
Pesquisa de arquitetura
Uma tarefa de proxy pode ser criada usando um conjunto de dados de treinamento subamostrado durante a pesquisa de arquitetura. No entanto, ao subamostrar, siga estas diretrizes:
- Embaralhar os dados aleatoriamente entre os fragmentos.
- Se os dados de treinamento não estiverem balanceados, subamostre-os para balancear os dados.
Pesquisa de aumento de política usando aumento automático
Pule esta seção se você não estiver executando uma pesquisa apenas de aumento e se estiver apenas executando a pesquisa de arquitetura regular. Use o aumento automático para pesquisar a política de aumento. É recomendável subamostrar os dados de treinamento e executar um treinamento completo do que reduzir o número de etapas de treinamento. A execução de treinamento completo com aumento intenso mantém as pontuações mais estáveis. Além disso, use dados de treinamento reduzidos para manter o custo de pesquisa mais baixo.
Tarefa de proxy com base em um modelo reduzido verticalmente
Também é possível reduzir o modelo em relação ao modelo de referência para criar uma tarefa de proxy. Isso também pode ser útil quando você quiser separar block-design-search de scaling-search.
No entanto, quando você reduzir o modelo e quiser usar uma restrição de latência, use uma restrição menor para o modelo reduzido. Dica: é possível reduzir o modelo de linha de base e medir a latência para definir essa restrição de latência mais rígida.
Para o modelo reduzido, também é possível reduzir a quantidade de aumento e regularização em comparação com o modelo de valor de referência original.
Exemplos de um modelo reduzido
Para tarefas de visão computacional em que você treina em imagens, há três maneiras comuns de reduzir um modelo:
- Redução da largura do modelo: número de canais.
- Redução da profundidade do modelo: número de camadas e repetições de blocos.
- Reduzir levemente o tamanho da imagem de treinamento para que ela não elimine recursos ou cortar imagens de treinamento, se permitido pela tarefa.
Leitura sugerida: o artigo EfficientNet (em inglês) oferece ótimos insights sobre o escalonamento de modelos para tarefas de visão computacional. Também é explicado como as três maneiras de escalonamento estão relacionadas.
A pesquisa Spinenet é outro exemplo de escalonamento de modelos usado com a pesquisa de arquitetura neural. Na stage1-search, ele reduz o número de canais e o tamanho da imagem.
Tarefa de proxy com base em uma combinação
As abordagens funcionam de maneira independente e podem ser combinadas em diferentes graus para criar uma tarefa de proxy.
Requisitos de uma boa tarefa de proxy
Uma tarefa de proxy precisa atender a determinados requisitos antes de poder fornecer uma recompensa estável ao controlador e manter a qualidade da pesquisa.
Correlação de classificação entre a pesquisa de nível 1 e o treinamento completo de nível 2
Ao usar uma tarefa de proxy para a pesquisa de arquitetura neural, uma suposição importante de que uma pesquisa seja bem-sucedida é de que, se o modelo-A tiver um desempenho melhor do que o modelo-B durante o estágio 1 de treinamento de tarefa-proxy, o modelo-A também terá um desempenho melhor do que o modelo-B para o treinamento completo do estágio 2. Para validar essa suposição, é necessário avaliar a correlação de classificação entre as recompensas de pesquisa de estágio 1 e o treinamento completo de estágio 2 em aproximadamente 10 modelos no seu espaço de pesquisa. Esses modelos são chamados de modelos de candidatos a correlação.
A figura abaixo mostra um exemplo de correlação ruim (correlação-pontuação = -0,03), o que torna essa tarefa proxy uma má candidata para uma pesquisa:

Cada ponto no gráfico representa um modelo candidato a correlação.
O eixo x representa as pontuações de treinamento completo do estágio 2 para os modelos
e o eixo y representa as pontuações de tarefa de proxy do estágio 1 para os mesmos modelos.
Observe o ponto mais alto. Esse modelo tem a maior pontuação de tarefas de proxy (eixo y), mas tem baixo desempenho durante o treinamento completo do estágio 2 (eixo x) em comparação com outros modelos. Por outro lado, a figura abaixo mostra um exemplo de uma boa correlação (correlation-score = 0,67), o que torna essa tarefa de proxy um bom candidato para uma pesquisa:

Se a pesquisa envolver uma restrição de latência, verifique também uma boa correlação dos valores de latência.
Os prêmios dos modelos candidatos a correlação têm um bom intervalo e uma boa amostragem do intervalo de recompensas. Caso contrário, não é possível avaliar a correlação de classificação. Por exemplo, se todas as recompensas da fase 1 dos modelos candidatos a correlação forem centralizadas em apenas dois valores: 0,9 e 0,1, isso não fornecem uma variação de amostragem suficiente.
Verificação de variação
Outro requisito de uma tarefa de proxy é que ela não precisa ter uma grande variação de precisão ou pontuação de latência quando repetida várias vezes para o mesmo modelo, sem alterações. Se isso acontecer, ele enviará um sinal com ruído de volta para o controlador. Uma ferramenta para medir essa variação é fornecida.
Exemplos são fornecidos para mitigar grandes variações
durante o treinamento. Uma maneira é usar cosine decay como a programação da taxa de aprendizado. O gráfico a seguir compara três estratégias de aprendizado:
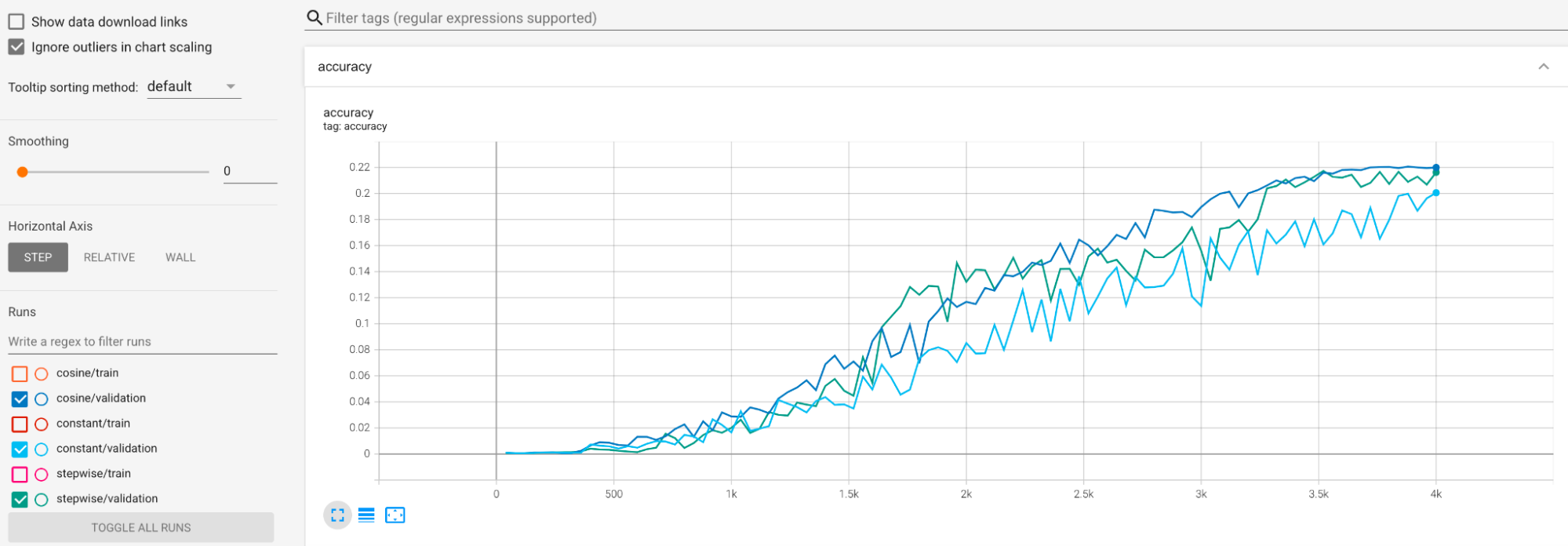
O gráfico mais baixo corresponde a uma taxa de aprendizado constante. Quando a pontuação for transferida ao final do treinamento, uma pequena alteração na escolha do número reduzido de etapas de treinamento poderá causar uma grande alteração na recompensa final da tarefa-proxy. Para tornar a recompensa de tarefa de proxy mais estável, é melhor usar uma redução da taxa de aprendizado do cosseno, conforme mostrado pelas pontuações de validação correspondentes no gráfico superior. Observe como o gráfico superior se torna mais suave no final do treinamento. O gráfico intermediário mostra a pontuação correspondente à redução gradual da taxa de aprendizado. Ela é melhor do que a taxa de constante, mas ainda não é tão suave quanto a redução de cosseno e também requer ajuste manual.
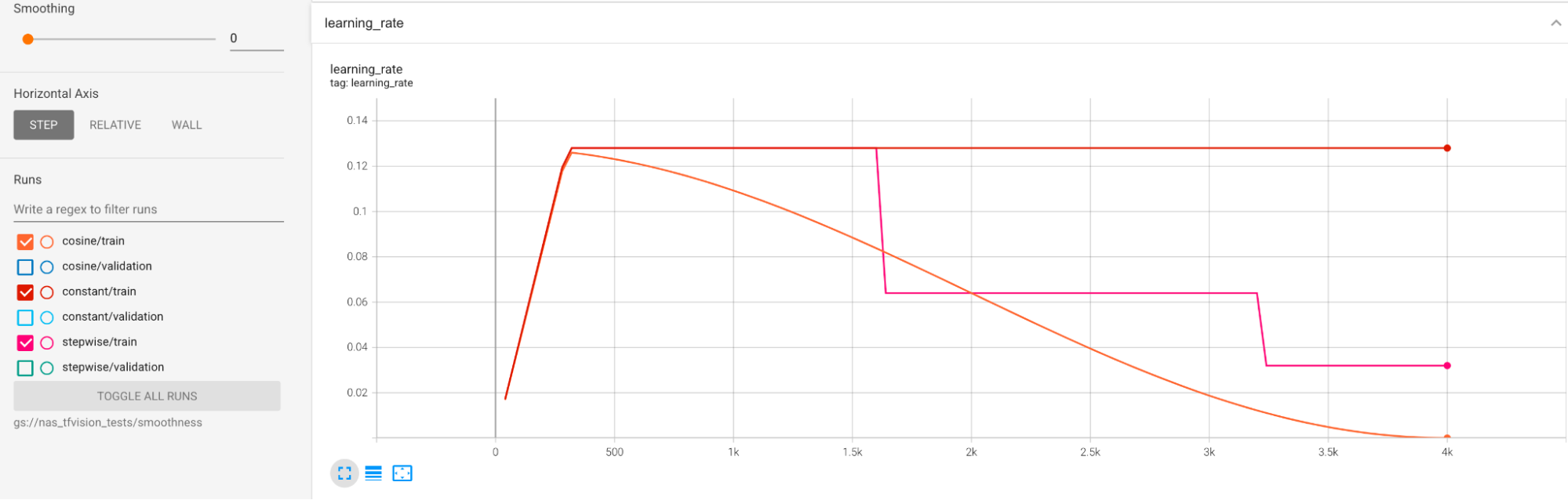
As programações de taxa de aprendizado são mostradas abaixo:
Suavização adicional
Se você estiver usando aumento intenso, sua curva de validação ainda não ficará suave o suficiente com a redução de cosseno. O uso de aumento intenso indica falta de dados de treinamento. Nesse caso, não é recomendável usar a pesquisa de arquitetura neural. Sugerimos usar pesquisa de ampliação.
Se a ampliação pesada não é a causa e você já tentou a redução de cosseno, mas ainda quer uma maior suavidade, use a média móvel exponencial para o TensorFlow-2 ou a média de média ponderada estocástico para o PyTorch. Consulte este ponteiro de código (link em inglês) para ver um exemplo usando o otimizador de média móvel exponencial com o TensorFlow 2 e este exemplo de média ponderada estocástica para o PyTorch.
Se seus gráficos de precisão/época de testes estiverem assim:

Em seguida, aplique técnicas de suavização mencionadas acima (como uma média ponderada estocástica ou usando uma média móvel exponencial) para ter um gráfico mais consistente, como:

Erros relacionados à taxa de aprendizado e a falta de memória (OOM)
O espaço de pesquisa de arquitetura pode gerar modelos muito maiores do que o valor de referência. Você pode ter ajustado o tamanho do lote para o modelo de referência, mas essa configuração pode falhar quando modelos maiores forem analisados durante a pesquisa, resultando em erros de OOM. Nesse caso, é necessário reduzir o tamanho do lote.
O outro tipo de erro é o NaN (não número). Reduza a taxa de aprendizado inicial ou adicione truncamento de gradiente.
Como mencionado no tutorial 2, se mais de 20% dos modelos de espaço de pesquisa estiverem retornando pontuações inválidas, você não executará a pesquisa completa. Nossas ferramentas de design de tarefas de proxy oferecem uma maneira de avaliar a taxa de falhas.
Ferramentas de design para tarefas de proxy
As seções anteriores falam sobre os princípios do design de tarefas de proxy. Nesta seção, fornecemos três ferramentas de design de tarefas de proxy para encontrar automaticamente a tarefa de proxy ideal com base nas diferentes abordagens de design e que atendem a todos os requisitos.
Alterações de código necessárias
Primeiro, é preciso modificar um pouco o código do treinador para que ele possa interagir com as ferramentas de design de tarefas de proxy durante um processo iterativo.
O tf_vision/train_lib.py
mostra um exemplo. Primeiro, você precisa importar nossa biblioteca:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Antes de iniciar um ciclo de treinamento no seu loop de treinamento, verifique se você precisa interromper o treinamento antecipadamente, porque a ferramenta de design de tarefas de proxy quer usar nossa biblioteca:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Depois que cada ciclo de treinamento no loop de treinamento for concluído, atualize a nova pontuação de acurácia, as etapas de início e término do ciclo de treinamento, o tempo do ciclo de treinamento em segundos e o total de etapas de treinamento.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
O tempo do ciclo de treinamento não pode incluir tempo para a avaliação da pontuação de validação. Verifique se seu treinador calcula pontuações de validação com frequência (frequência de avaliação) para que você tenha amostragem suficiente da sua curva de validação. Se você estiver usando a restrição de latência, atualize a métrica de latência depois de computação de latência:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
A ferramenta de seleção de modelos exige
o carregamento do checkpoint anterior para iteração sucessiva.
Para ativar a reutilização de um checkpoint anterior, adicione um flag ao treinador,
conforme mostrado em tf_vision/cloud_search_main.py:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Carregue este checkpoint antes de treinar o modelo:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
Você também precisa do metric-id correspondente aos valores de precisão
e latência relatados pelo seu treinador. Se o prêmio do treinador
(às vezes uma combinação de precisão e latência) for diferente
da precisão, também
informe a métrica somente de precisão usando other_metrics do seu treinador.
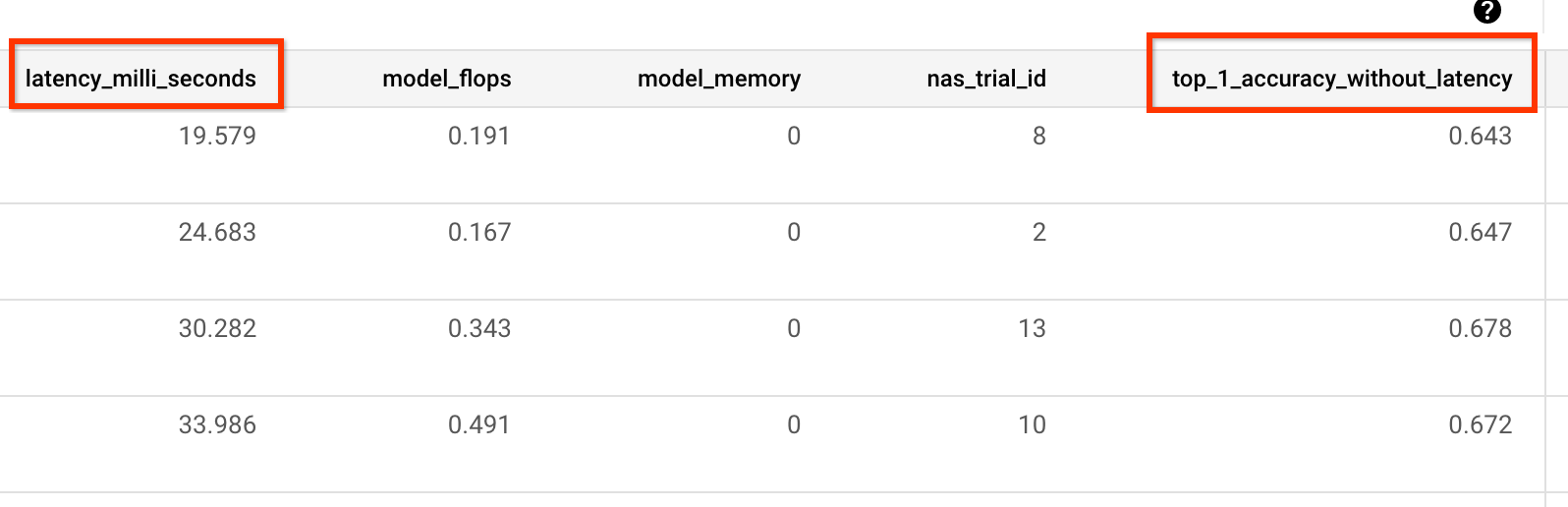
O exemplo a seguir mostra métricas somente de precisão e latência
informadas pelo nosso treinador pré-criado:
Avaliação de variância
Depois de modificar o código do treinador, o primeiro passo é medir a variação no treinador. Para a medição de variação, modifique sua configuração de treinamento de referência para o seguinte:
- diminua as etapas de treinamento para executar por aproximadamente uma hora com apenas uma ou duas GPUs. Precisamos de uma pequena amostra de treinamento completo.
- Use a taxa de aprendizado da redução de cossenos e defina as etapas para que sejam iguais às etapas reduzidas. Assim, a taxa de aprendizado se torna quase zero no final.
A ferramenta de medição de variação analisa um modelo do espaço de pesquisa, verifica se esse modelo pode começar a treinar sem exibir erros de OOM ou NAN e executa cinco cópias desse modelo com as configurações por aproximadamente uma hora e relata a variação e a suavidade da pontuação de treinamento. O custo total para executar essa ferramenta é aproximadamente o mesmo que executar cinco modelos com suas configurações por aproximadamente uma hora.
Inicie o job de medição de variância executando o seguinte comando (você precisa de uma conta de serviço):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Depois de lançar esse job, você vai receber um link dele. O
nome do job precisa começar com o prefixo Variance_Measurement. Veja abaixo um exemplo
de IU de job:
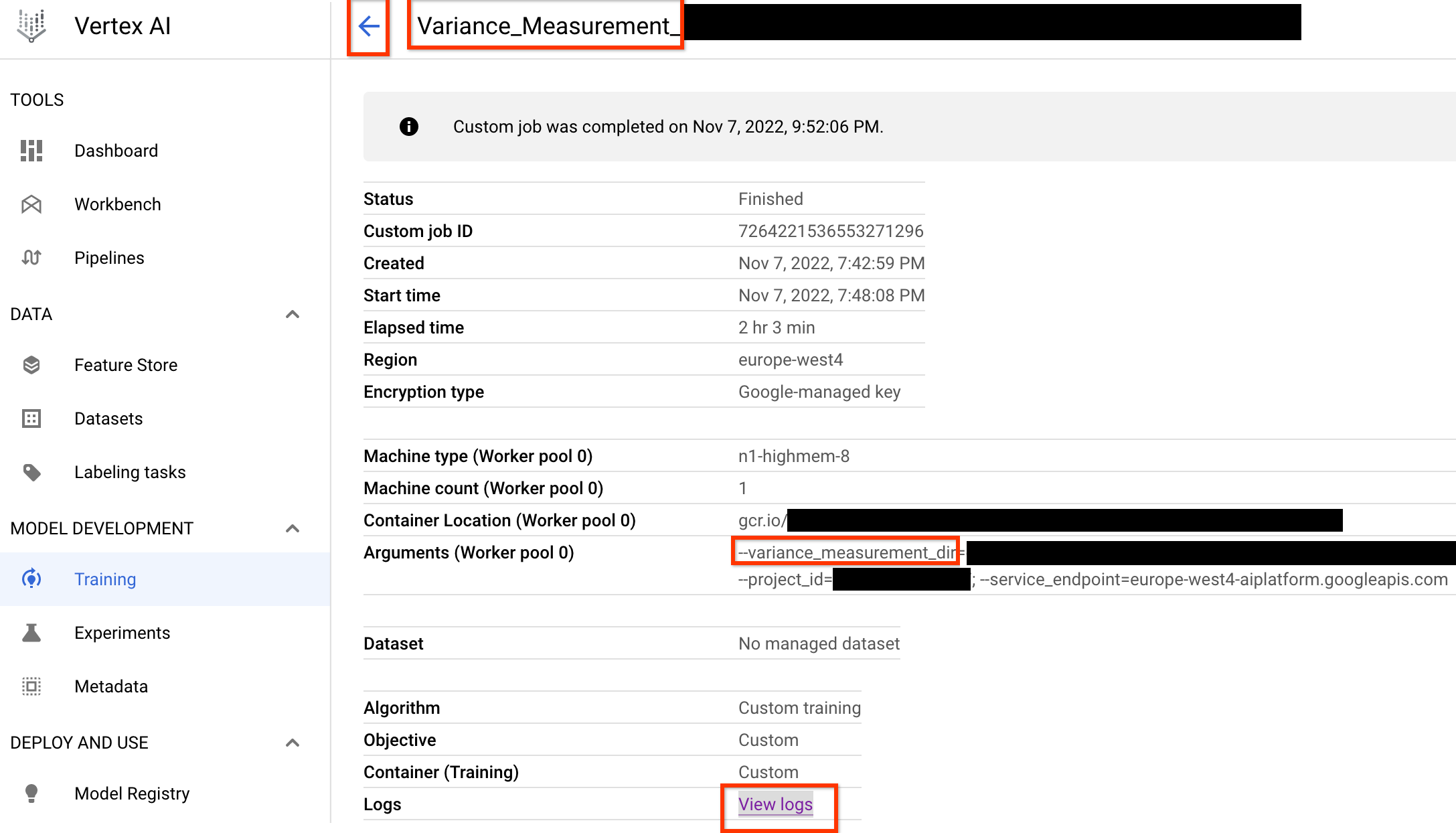
O variance_measurement_dir conterá todas as saídas, e será possível verificar os registros clicando no link Ver registros.
Por padrão, esse job usa uma CPU na nuvem para ser executado em segundo plano como um job personalizado e, em seguida, inicia e gerencia jobs NAS filhos.

Em jobs NAS, você verá um job chamado Find_workable_model_<your job name>. Esse job vai fazer uma
amostragem do espaço de pesquisa para encontrar um modelo, que não gera erros. Depois
que esse modelo for encontrado, o job de medição de variação lançará
outro job NAS <your job name>, que executa cinco cópias dele para o número
de etapas de treinamento definidos anteriormente. Depois que o treinamento desses modelos
é concluído, o job de medição de variações mede a variação e a nitidez
da pontuação e os registra nos registros:
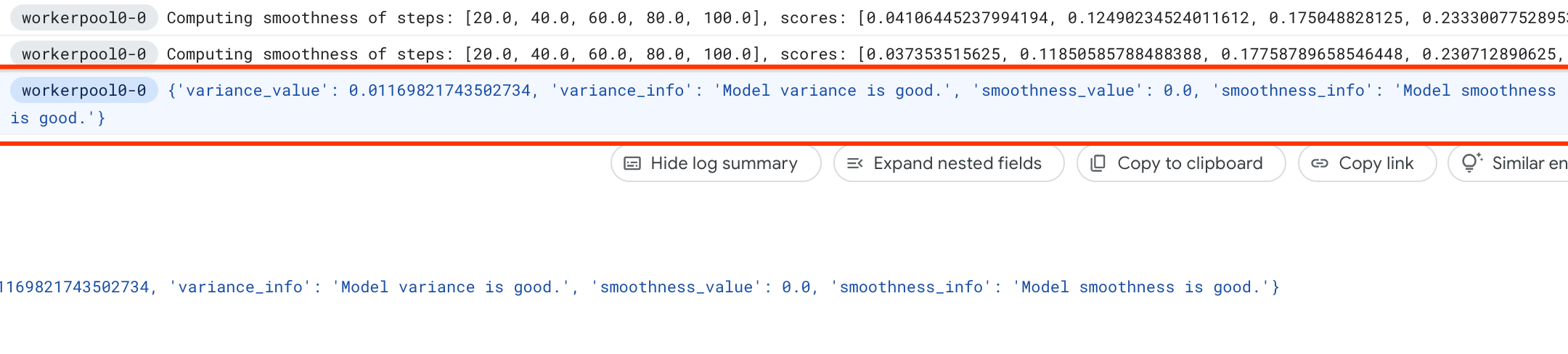
Se a variação for alta, será possível explorar as técnicas listadas aqui.
Seleção de modelos
Após verificar se seu treinador não tem uma alta variação, as próximas etapas são as seguintes:
- para encontrar aproximadamente 10 modelos-correlação-candidato
- Calcular as pontuações de treinamento completo que vão atuar como referência ao calcular as pontuações de correlação de tarefas de proxy para diferentes opções de tarefas de proxy posteriormente.
Nossa ferramenta encontra automaticamente e com eficiência esses modelos candidatos a correlação, além de garantir que eles tenham uma boa distribuição de pontuação para acurácia e latência, de modo que o cálculo futuro da correlação tenha uma boa base. Para isso, a ferramenta faz o seguinte:
- Faz uma amostragem aleatória de
N_beginmodelo do seu espaço de pesquisa. Para o exemplo aqui, vamos considerarN_begin = 30. A ferramenta os treina por 1/30 do tempo completo de treinamento. - Rejeita cinco de 50 modelos, que não adicionam mais à distribuição de acurácia e latência. A figura a seguir mostra isso como exemplo. Os modelos rejeitados são mostrados como pontos vermelhos:
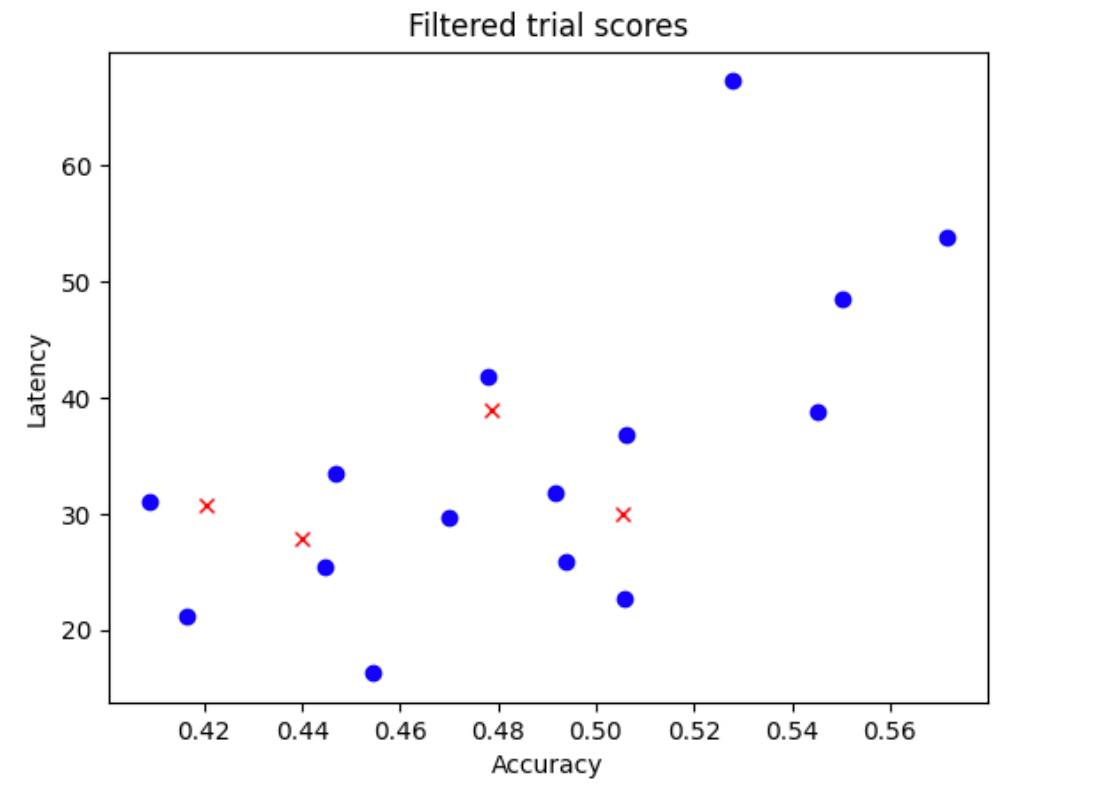
- Treina os 25 modelos selecionados por 1/25 do tempo de treinamento completo e rejeita mais cinco modelos com base nas pontuações até o momento. O treinamento dos 25 modelos continua do ponto de verificação anterior.
- Repete esse processo até que apenas
Nmodelos com uma boa distribuição sejam deixados. - Treina esses últimos
Nmodelos até a conclusão.
A configuração padrão para N_begin é 30 e pode ser encontrada como START_NUM_MODELS
no arquivo proxy_task/proxy_task_model_selection_lib_constants.py.
A configuração padrão para N é 10 e pode ser encontrada como FINAL_NUM_MODELS
no arquivo proxy_task/proxy_task_model_selection_lib_constants.py.
O custo adicional desse processo de seleção de modelo é calculado da seguinte forma:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
No entanto, mantenha a configuração N=10. Posteriormente, a ferramenta de pesquisa de tarefas de proxy executa esses modelos N em paralelo. Portanto, verifique se você tem cota de GPU suficiente para isso. Por exemplo, se a tarefa de proxy usar duas GPUs para um modelo, você terá uma cota de pelo menos 2*N GPUs.
Para o job de seleção de modelo, use a mesma partição de conjunto de dados que o job de treinamento completo do estágio 2 e a mesma configuração de treinador para o treinamento completo de referência.
Agora você está pronto para iniciar o job de seleção de modelo executando o seguinte comando (você precisa de uma conta de serviço):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Depois de iniciar esse job do controlador de seleção de modelo, um link de job é recebido. O
nome do job começa com o prefixo Model_Selection_. Veja abaixo um exemplo
de IU de job:
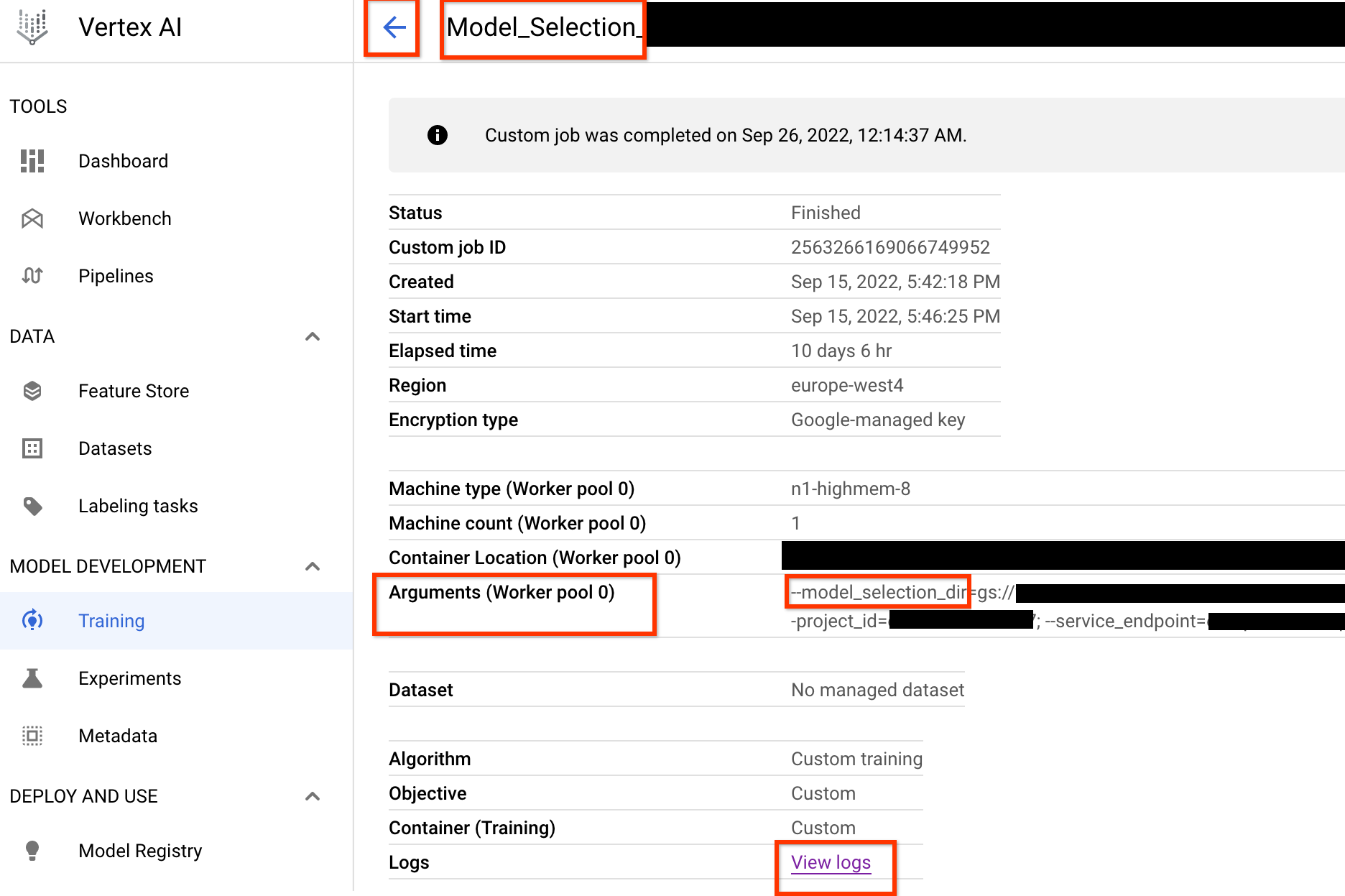
O model_selection_dir contém todas as saídas. Verifique os registros clicando no link View logs.
Por padrão, esse job do controlador de seleção de modelos usa
uma CPU no Google Cloud para ser executado em segundo plano
como um job personalizado e, em seguida, inicia e gerencia o
NAS para cada iteração da seleção de modelo.
Cada job filho NAS tem um nome, como <your_job_name>_iter_3 (exceto para iteração 0). Somente uma iteração é executada por vez. A cada iteração, o número de
modelos (número de testes) é reduzido e a duração do
treinamento aumenta. No final de cada iteração, cada job NAS salva
o arquivo gs://<job-output-dir>/search/filtered_trial_scores.png,
que mostra visualmente quais modelos foram rejeitados nessa iteração.
Você também pode executar o seguinte comando:
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
que mostra um resumo das iterações e o estado atual do job do controlador de seleção de modelo, o nome do job e os links para cada iteração:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
A última iteração tem o número final de modelos de referência com boa distribuição de pontuação. Esses modelos e as pontuações deles são usados para a pesquisa de tarefas de proxy na próxima etapa. Se a acurácia final e o intervalo de pontuação de latência dos modelos de referência parecerem melhores ou mais próximos do modelo de valor de referência atual, o que oferece uma boa indicação inicial sobre o espaço de pesquisa. Se a precisão final e o intervalo da pontuação de latência forem significativamente piores do que o valor de referência, revisite seu espaço de pesquisa.
Se mais de 20% dos testes na primeira iteração falharem, cancele o job de seleção de modelo e identifique a causa raiz das falhas. Isso pode ser um problema com o espaço de pesquisa ou com o tamanho do lote e as configurações de taxa de aprendizado.
Como usar o dispositivo de latência local para a seleção de modelos
Para usar o dispositivo de latência local para a seleção de modelos, execute o comando select_proxy_task_models sem o Docker de latência e as flags de latência do Docker, porque você não quer iniciar o Docker de latência em Google Cloud. Em seguida, use o comando run_latency_calculator_local descrito no
Tutorial 4
para iniciar o job da calculadora de latência local. Em vez de transmitir a flag
--search_job_id, transmita a flag --controller_job_id com
o ID do job de seleção de modelo numérico que você recebe depois de executar o
comando select_proxy_task_models.
Como retomar o job do controlador de seleção de modelos
As situações a seguir exigem que você retome o job do controlador de seleção de modelos:
- Os jobs do controlador de seleção de modelos pai são encerrados (caso raro).
- Você cancela acidentalmente o job do controlador de seleção de modelos.
Primeiro, não cancele o job de iteração NAS filho (guia NAS) se ele já estiver em execução. Em seguida, para retomar
o job do controlador de seleção de modelos pai, execute o comando select_proxy_task_models como antes, mas desta vez transmita a
sinalização --previous_model_selection_dir e defina-a para o
diretório de saída. para o job anterior do controlador de seleção de modelos. O job de controlador de seleção de modelo retomado carrega o estado anterior do diretório e continua funcionando como antes.
Pesquisa de tarefas de proxy
Depois de encontrar os modelos candidatos a correlação e as pontuações de treinamento completo deles, a próxima etapa é usá-los para avaliar as pontuações de correlação para diferentes opções de tarefas de proxy e escolher tarefa de proxy ideal. Nossa ferramenta de pesquisa de tarefas de proxy pode encontrar automaticamente uma tarefa de proxy, que oferece o seguinte:
- O menor custo de pesquisa de NAS.
- Atende a um limite mínimo de correlação necessário depois de fornecer uma definição de espaço de pesquisa de tarefa de proxy.
Lembre-se de que há três dimensões comuns para pesquisar uma tarefa de proxy ideal, incluindo:
- Número reduzido de etapas de treinamento.
- Quantidade reduzida de dados de treinamento.
- Escala de modelo reduzida.
Para criar um espaço de pesquisa de tarefa de proxy distinto, faça a amostragem dessas dimensões, conforme mostrado aqui:

Os números percentuais acima são definidos apenas como uma sugestão aproximada e um exemplo. Na prática, é possível escolher qualquer opção discreta.
Observação: Nós não incluímos a dimensão de etapas de treinamento no
espaço de pesquisa acima. Isso ocorre porque a ferramenta de pesquisa de tarefa de proxy
descobre a etapa de treinamento ideal de acordo com a opção de tarefa de proxy.
Considere uma opção de tarefa de proxy de
[50% training data, 25% model scale]. Defina o número de etapas de treinamento com o mesmo valor do treinamento de referência completo.
Ao avaliar essa tarefa de proxy, a ferramenta de pesquisa da tarefa de proxy
inicia o treinamento dos modelos de correlação de candidatos, monitora a pontuação de precisão atual
e calcula continuamente a pontuação de correlação de classificação
(usando o pontuações de treinamento completo dos modelos de referência):

Assim, a ferramenta de pesquisa de tarefas de proxy pode interromper o treinamento de tarefa de proxy quando a correlação desejada (como 0,65) for alcançada ou também pode ser interrompida antecipadamente se a cota de custo de pesquisa (como 3 limite de horas por tarefa de proxy) for excedido. Portanto, não é preciso fazer pesquisas explicitamente nas etapas de treinamento. A ferramenta de pesquisa de tarefas de proxy avalia cada tarefa de proxy a partir do espaço de pesquisa discreto como uma pesquisa em grade e oferece a melhor opção.
Veja a seguir um exemplo de definição de espaço de pesquisa de tarefa de proxy MnasNet
mnasnet_proxy_task_config_generator,
definido no arquivo proxy_task/proxy_task_search_spaces.py,
para demonstrar como definir seu próprio espaço de pesquisa:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
Neste exemplo, criamos um espaço de pesquisa simples com a porcentagem de dados de treinamento
25, 50, 75 e 95. Observação: 100% dos dados de treinamento
não são usados para pesquisa de estágio 1).
A função mnasnet_proxy_task_config_generator usa um
modelo de valor de referência comum de argumentos de treinamento do Docker e
os modifica para cada tamanho de dados de treinamento desejado
para tarefas de proxy. Depois, é retornada uma lista
de configuração de tarefa de proxy que é
processada posteriormente pela ferramenta de pesquisa de tarefa de proxy uma por uma
na mesma ordem. Cada configuração de tarefa de proxy
tem um name e docker_args_map, que é um mapa de chave-valor para os
argumentos do Docker de tarefa de proxy.
Você tem a liberdade de implementar sua própria definição de espaço de pesquisa de acordo com seus próprios requisitos e criar seus próprios espaços de pesquisa de tarefas de proxy, mesmo para mais de duas dimensões de dados de treinamento ou escala de modelos reduzida. No entanto, não é aconselhável pesquisar explicitamente as etapas de treinamento porque isso envolve desperdício de computação repetida. Deixe que a ferramenta de pesquisa de tarefas de proxy lide com essa dimensão por você.
Para sua primeira pesquisa de tarefas de proxy, tente reduzir apenas os dados de treinamento (como o exemplo MnasNet) e pular a redução de escala do modelo, porque essa escala pode envolver vários parâmetros em image-size, num-filters ou num-blocks.
Na maioria dos casos, os dados de treinamento reduzidos (e a pesquisa implícita sobre as etapas de treinamento reduzidas) são suficientes para encontrar uma boa tarefa de proxy.
Defina o número de etapas de treinamento como o número usado no treinamento de referência completa.
Há diferenças entre as configurações de treinamento de tarefa de proxy da etapa 2 do treinamento completo e da etapa 1. Para tarefas de proxy,
reduza batch-size em comparação
com a configuração de treinamento de valor de referência completa para usar apenas duas ou quatro GPUs.
Normalmente, o treinamento completo usa quatro GPUs, oito ou mais, mas a
tarefa proxy usa apenas duas ou quatro GPUs.
Outra diferença é a
divisão de treinamento e validação.
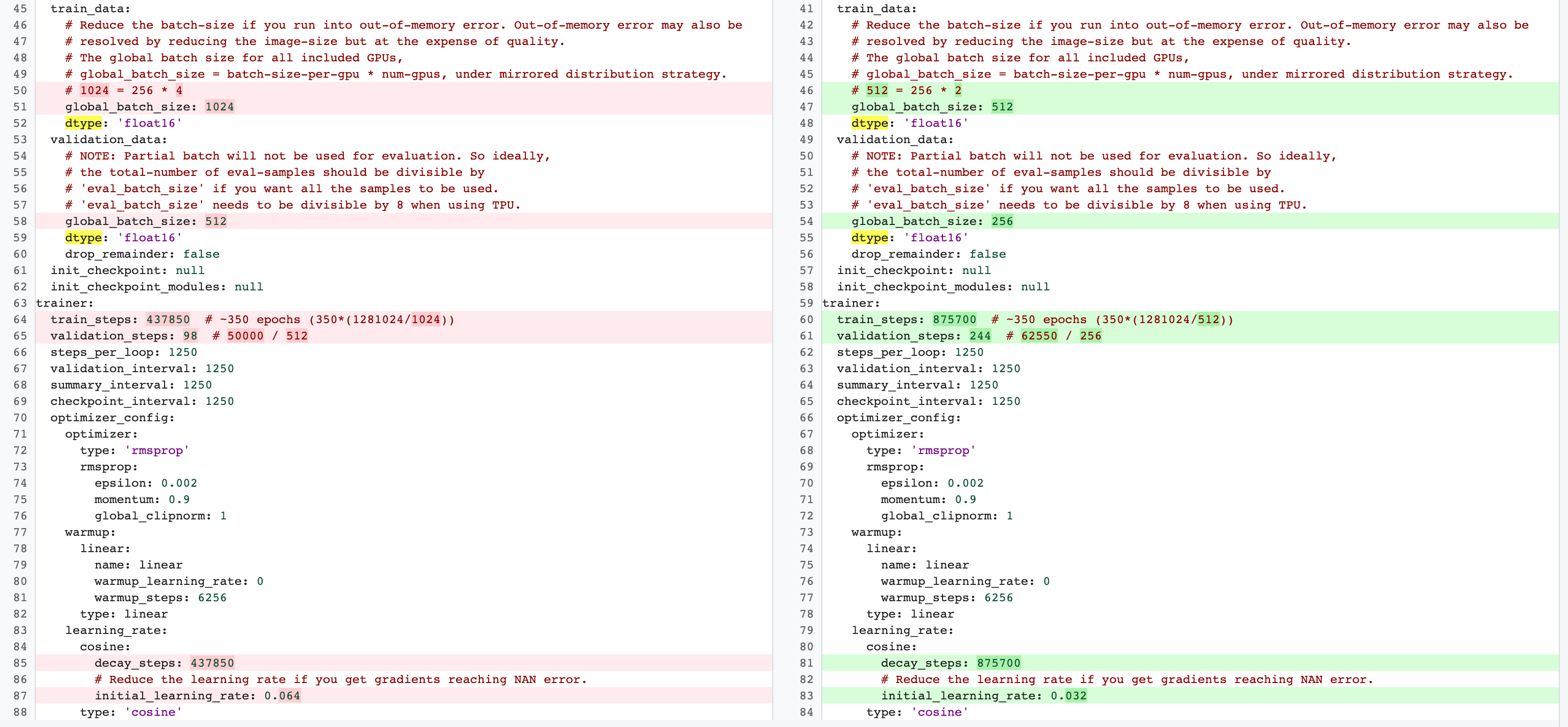
Veja um exemplo de alterações para a configuração do MnasNet que vai de quatro GPUs para treinamento completo do estágio 2 para duas GPUs e uma divisão de validação diferente para pesquisa de tarefas de proxy:
Execute o job a seguir para iniciar o job do controlador de pesquisa da tarefa de proxy executando uma conta de serviço:
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Depois de iniciar esse job do controlador de pesquisa da tarefa de proxy, um link de job é recebido. O
nome do job começa com o prefixo Search_controller_. Veja abaixo um exemplo
de IU de job:

O search_controller_dir conterá todas as saídas, e será possível verificar os registros clicando no link View logs.
Por padrão, esse job usa uma CPU na nuvem para ser executado em segundo plano
como um job personalizado e depois inicia e gerencia
jobs NAS filhos para cada avaliação de tarefa de proxy.
Cada job de NAS de tarefa de proxy
tem um nome como ProxyTask_<your-job-name>_<proxy-task-name>,
em que <proxy-task-name> é o que o
módulo de gerador de configuração de tarefa de proxy fornece para cada tarefa de proxy. Apenas uma avaliação de tarefa de proxy é executada por vez.
Você também pode executar o seguinte comando:
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Esse comando mostra um resumo de todas as avaliações de tarefa de proxy e o estado atual da vaga de controlador de pesquisa, nome do job e links para cada avaliação:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
O proxy_tasks_map armazena a saída de cada avaliação de tarefa de proxy, e best_proxy_task_name registra a melhor tarefa de proxy para a pesquisa. Cada entrada de tarefa de proxy tem dados adicionais, como
proxy_task_stats, que registra o progresso da
correlação de precisão, os valores p, a precisão média
e o tempo médio de treinamento nas etapas de treinamento. Ele também registra a
correlação relacionada à latência, se aplicável, e registra o motivo para
interromper esse job, como o limite de tempo de treinamento
e a etapa de treinamento em que ele para. Também é possível visualizar essas estatísticas como gráficos copiando o conteúdo de search_controller_dir na pasta local executando o seguinte comando:
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
e inspecionar as imagens do gráfico. Por exemplo, o gráfico a seguir mostra a correlação de precisão em relação ao tempo de treinamento da melhor tarefa de proxy:

Sua pesquisa foi concluída e você encontrou a melhor configuração de tarefa de proxy. É necessário fazer o seguinte:
- Defina o número de etapas de treinamento como o
final_training_stepsda tarefa de proxy vencedora. - Defina as etapas de redução de cosseno da mesma forma que
final_training_stepspara que a taxa de aprendizado seja quase zero no fim. - [Opcional] Faça uma avaliação da pontuação de validação ao final do treinamento, que economiza vários custos de avaliação.
Como usar o dispositivo de latência local para pesquisar tarefas de proxy
Para usar o dispositivo de latência local para pesquisar tarefas de proxy, execute o
comando search_proxy_task sem o Docker de latência e
as flags de latência do Docker, porque você não quer iniciar o Docker de latência
em Google Cloud. Em seguida, use o comando run_latency_calculator_local descrito no
Tutorial 4
para iniciar o job da calculadora de latência local. Em vez de transmitir a flag
--search_job_id, transmita a flag --controller_job_id com
o ID do job numérico de proxy de tarefa de busca recebido após a execução do
comando search_proxy_task.
Como retomar o job do controlador de pesquisa da tarefa de proxy
Nas seguintes situações, é necessário retomar o job do controlador de pesquisa da tarefa de proxy:
- Os dados do job principal do controlador de pesquisa da tarefa proxy (caso raro) são desativados.
- Você acidentalmente cancela a tarefa do controlador de pesquisa de tarefa de proxy.
- Você quer estender seu espaço de pesquisa de tarefas de proxy depois (mesmo depois de muitos dias).
Primeiro, não cancele o job de iteração NAS filho (guia NAS) se ele já estiver em execução. Em seguida, para retomar o job principal do controlador de pesquisa de tarefas de proxy pai, execute o comando search_proxy_task como antes, mas desta vez transmita a sinalização --previous_proxy_task_search_dir e defina-a como diretório de saída do job anterior de controlador de pesquisa de tarefa de proxy. O job de controlador de pesquisa de tarefa retomada carrega o estado anterior do diretório e continua funcionando como antes.
Verificações finais
Duas verificações finais para sua tarefa de proxy incluem intervalo de prêmios e economia de dados para análise pós-pesquisa.
Intervalo de recompensas
A recompensa informada ao controlador deve estar dentro do intervalo [1e-3, 10]. Se isso não for verdadeiro, será possível escalonar artificialmente a recompensa para atingir a meta.
Salvar dados para análise pós-pesquisa
O código da tarefa de proxy deve salvar outras métricas e dados
no local do Cloud Storage, o que pode ser útil para analisar o espaço de pesquisa depois. Nossa plataforma de pesquisa de arquitetura neural
só permite a gravação de até cinco other_metrics de ponto flutuante.
Todas as métricas adicionais precisam ser salvas no local do Cloud Storage para análise posterior.