Vertex AI 신경망 아키텍처 검색 실험을 시작하기 전에 환경을 설정합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면, 다음 명령어를 실행합니다.
gcloud init -
gcloud CLI를 초기화한 후 업데이트하고 필요한 구성요소를 설치합니다.
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면, 다음 명령어를 실행합니다.
gcloud init -
gcloud CLI를 초기화한 후 업데이트하고 필요한 구성요소를 설치합니다.
gcloud components update gcloud components install beta
- 모든 신경망 아키텍처 검색 사용자에게 Vertex AI 사용자 역할(
roles/aiplatform.user)을 부여하려면 프로젝트 관리자에게 문의하세요. - Docker를 설치합니다.
Ubuntu나 Debian과 같은 Linux 기반 운영체제를 사용하는 경우
sudo를 사용하지 않고 Docker를 실행할 수 있도록 사용자 이름을docker그룹에 추가합니다.sudo usermod -a -G docker ${USER}사용자를
docker그룹에 추가하고 나면 시스템을 다시 시작해야 할 수도 있습니다. - Docker를 엽니다. Docker가 실행 중인지 확인하려면 다음 Docker 명령어를 실행합니다. 현재 시간과 날짜가 반환됩니다.
docker run busybox date
- Docker의 사용자 인증 정보 도우미로
gcloud를 사용합니다.gcloud auth configure-docker
-
(선택사항) GPU를 사용하여 컨테이너를 로컬에서 실행하려면
nvidia-docker를 설치합니다. -
새 버킷의 이름을 지정합니다. 이름은 Cloud Storage의 모든 버킷에서 중복되지 않아야 합니다.
BUCKET_NAME="YOUR_BUCKET_NAME"
예를 들어 프로젝트 이름에
-vertexai-nas을 추가하여 사용합니다.PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
만든 버킷 이름을 확인합니다.
echo $BUCKET_NAME
-
버킷 리전을 선택하고
REGION환경 변수를 설정합니다.신경망 아키텍처 검색 작업을 실행하려는 것과 동일한 리전을 사용합니다.
예를 들어 다음 코드는
REGION을 생성하고us-central1로 설정합니다.REGION=us-central1
-
새 버킷을 만듭니다.
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
- 서비스에서 Vertex AI API를 선택합니다.
- 리전에서 필터링할 리전을 선택합니다.
- 할당량에서 프리픽스 커스텀 모델 학습인 가속기 이름을 선택합니다.
- V100 GPU의 경우 값은 리전별 커스텀 모델 학습 Nvidia V100 GPU입니다.
- CPU의 경우 값은 리전별 N1/E2 머신 유형의 커스텀 모델 학습 CPU입니다. CPU 번호는 CPU 단위를 나타냅니다.
highmem-16CPU 8개를 원하는 경우 8 * 16 = 128개의 CPU 단위에 대해 할당량을 요청합니다. 또한 원하는 리전 값을 입력합니다.
기본 환경 변수를 설정합니다.
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginArtifact Registry에 대해 Docker 인증을 설정합니다.
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(선택사항) Python 3 가상 환경을 구성합니다. Python 3 사용이 권장되지만 필수가 아닙니다.
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activate추가 라이브러리 설치:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0서비스 계정을 만듭니다.
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAME서비스 계정에
aiplatform.user및storage.objectAdmin역할을 할당합니다.gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdmin새 셸 터미널을 엽니다.
Git 클론 명령어를 실행합니다.
git clone https://github.com/google/vertex-ai-nas.git
Cloud Storage 버킷 설정
이 섹션에서는 새 버킷을 만드는 방법을 설명합니다. 기존 버킷을 사용할 수도 있지만 해당 버킷이 AI Platform 작업을 실행 중인 리전과 동일한 리전에 있어야 합니다. 또한 신경망 아키텍처 검색을 실행하기 위해 사용 중인 프로젝트에 속하지 않는 경우, 신경망 아키텍처 검색 서비스 계정에 대해 액세스 권한을 명시적으로 부여해야 합니다.
프로젝트의 추가 기기 할당량 요청
튜토리얼은 약 5개의 CPU 머신을 사용하며 추가 할당량이 필요하지 않습니다. 튜토리얼을 실행한 후 신경망 아키텍처 검색 작업을 실행합니다.
신경망 아키텍처 검색 작업은 모델 배치를 병렬로 학습시킵니다. 각 학습된 모델은 시도에 해당합니다.
number-of-parallel-trials 설정 섹션을 읽고 검색 작업에 필요한 CPU 및 GPU 양을 추정하세요.
예를 들어 각 시도에서 2개의 T4 GPU를 사용하고 number-of-parallel-trials를 20으로 설정하면 검색 작업당 총 40개의 T4 GPU 할당량이 필요합니다. 또한 각 시도에서 highmem-16 CPU를 사용하는 경우 시도당 16개의 CPU 단위가 필요합니다. 이는 20번의 병렬 시도에서 CPU 단위 320개입니다.
하지만 최소 10개의 병렬 시도 할당량(또는 20개의 GPU 할당량)이 필요합니다.
GPU의 기본 초기 할당량은 리전 및 GPU 유형에 따라 다르며 일반적으로 Tesla_T4의 경우 0, 6, 12, Tesla_V100의 경우 0 또는 6입니다. CPU의 기본 초기 할당량은 리전에 따라 다르며 일반적으로 20, 450, 2,200입니다.
선택사항: 여러 검색 작업을 동시에 실행하려면 할당량 요구사항을 확장합니다. 할당량을 요청해도 즉시 요금이 청구되지는 않습니다. 작업을 실행하면 요금이 청구됩니다.
할당량이 충분하지 않고 할당량보다 많은 리소스가 필요한 작업을 실행하려고 하면 작업이 시작되지 않고 다음과 같은 오류가 발생합니다.
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
일부 경우에는 동일한 프로젝트의 여러 작업이 동시에 시작되었고 모든 작업에 할당량에 충분하지 않은 경우 작업 중 하나가 큐에 추가된 상태로 남아 있고 학습이 시작되지 않습니다. 이 경우 큐에 추가된 작업을 취소하고 추가 할당량을 요청하거나 이전 작업이 완료될 때까지 기다립니다.
할당량 페이지에서 추가 기기 할당량을 요청할 수 있습니다.
필터를 적용하여 수정할 할당량을 찾을 수 있습니다. 
할당량 요청을 만들면 Case number를 수신하고 요청 상태에 대한 후속 이메일을 받게 됩니다. GPU 할당량 승인은 영업일 기준 약 2~5일이 걸릴 수 있습니다. 일반적으로 약 2~30개의 GPU 할당량은 약 2~3일 내에 빠르게 승인되며 약 100개 GPU에 대한 승인을 받으려면 영업일 기준 5일이 소요됩니다. CPU 할당량 승인은 영업일 기준 최대 2일이 걸릴 수 있습니다.
하지만 리전에 GPU 유형이 크게 부족하면 적은 할당량 요청이어도 보장할 수 없습니다.
이 경우 다른 리전 또는 다른 GPU 유형을 이동하라는 메시지가 표시될 수 있습니다. 일반적으로 T4 GPU는 V100보다 쉽게 구할 수 있습니다. T4 GPU는 실제 경과 시간이 더 길지만 더 경제적입니다.
자세한 내용은 할당량 조정 요청을 참고하세요.
프로젝트의 Artifact Registry 설정
Docker 이미지를 푸시할 프로젝트 및 리전에 대해 Artifact Registry를 설정해야 합니다.
프로젝트의 Artifact Registry 페이지로 이동합니다. 아직 프로젝트에 Artifact Registry API를 사용 설정하지 않았다면 먼저 사용 설정합니다.
사용 설정했으면 저장소 만들기를 클릭하여 새 저장소를 만듭니다.
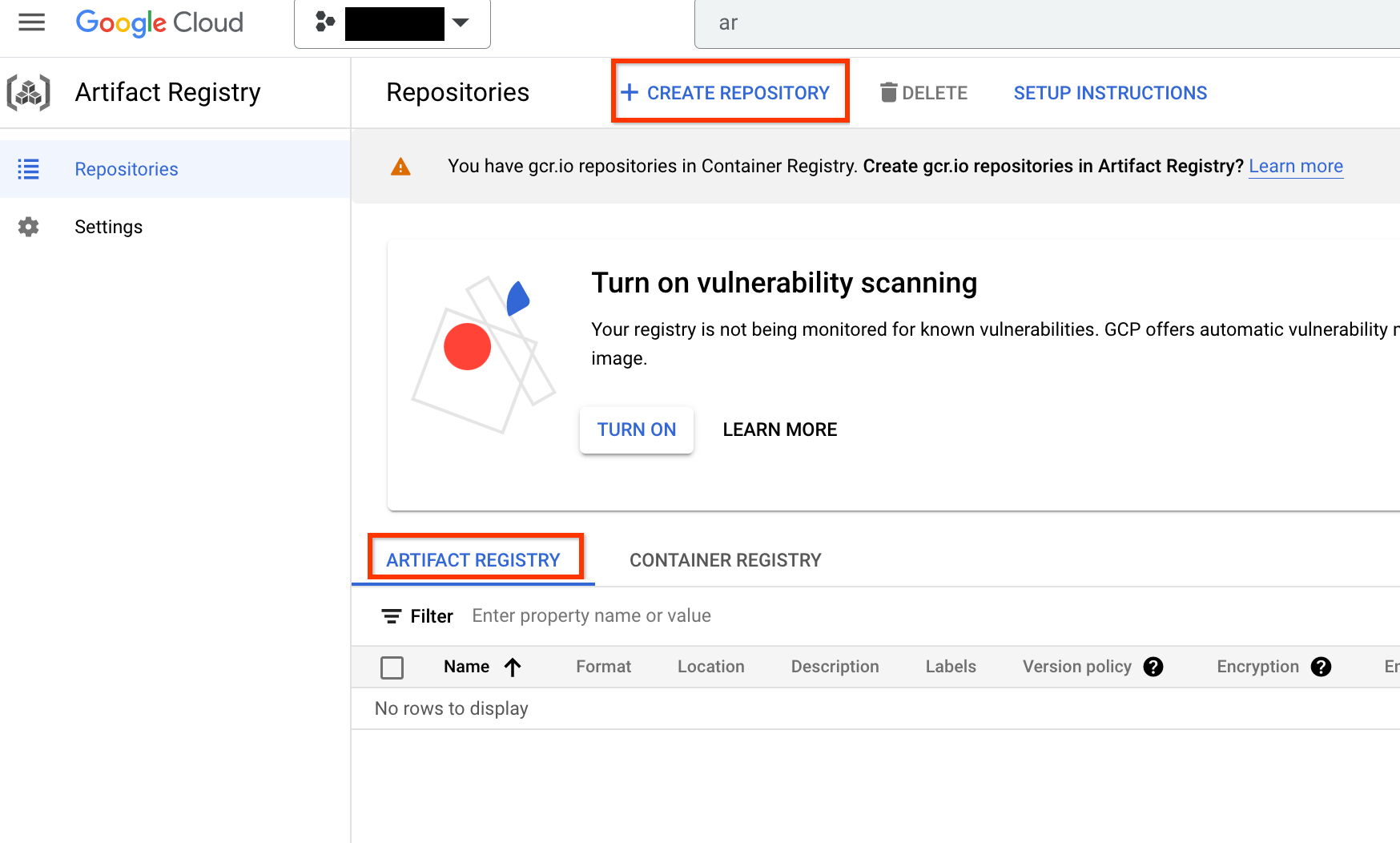
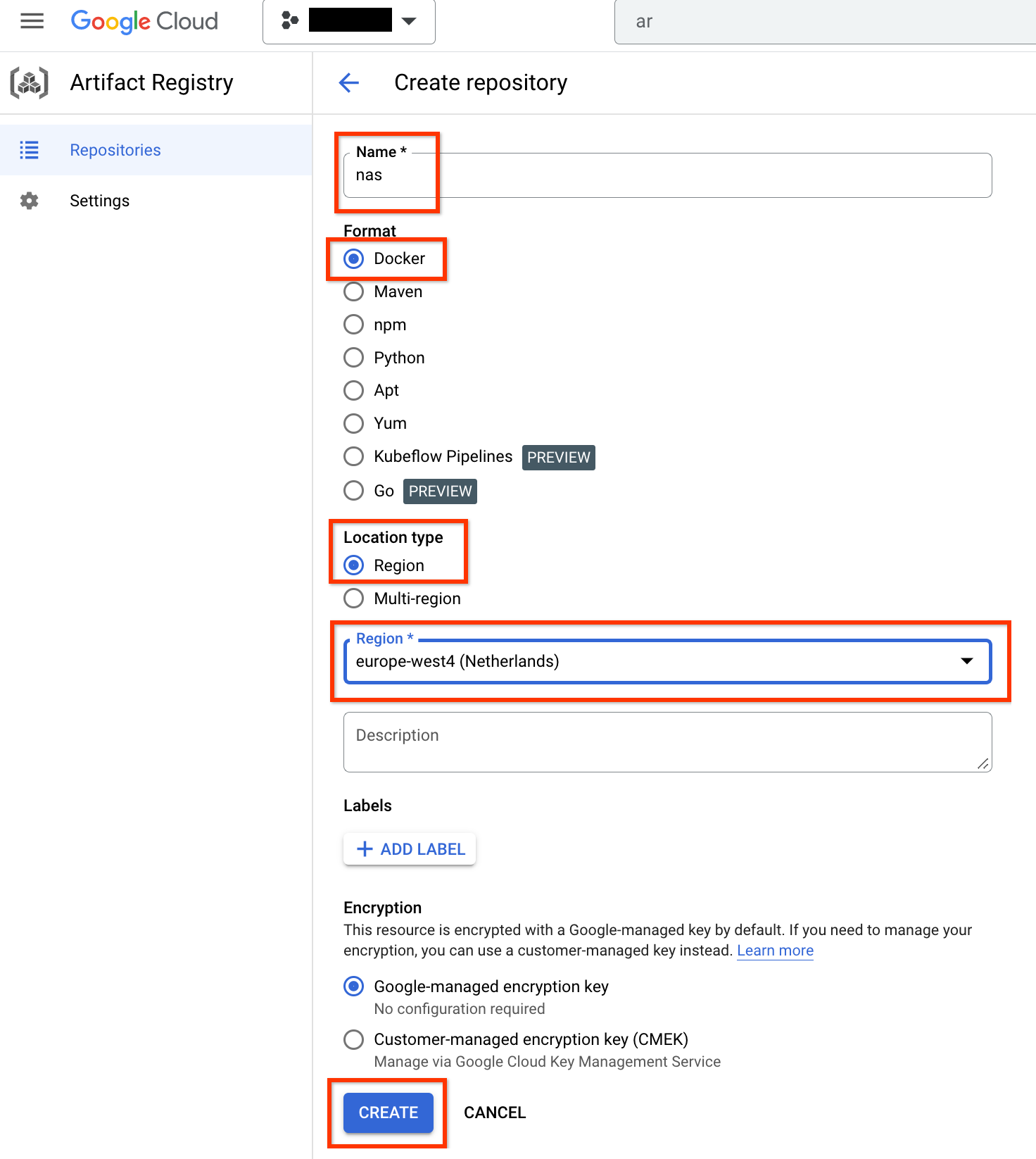
이름을 nas로, 형식을 Docker로, 위치 유형을 리전으로 선택합니다. 리전에서 작업을 실행하는 위치를 선택한 후 만들기를 클릭합니다.
이렇게 하면 아래와 같이 원하는 Docker 저장소가 생성됩니다.
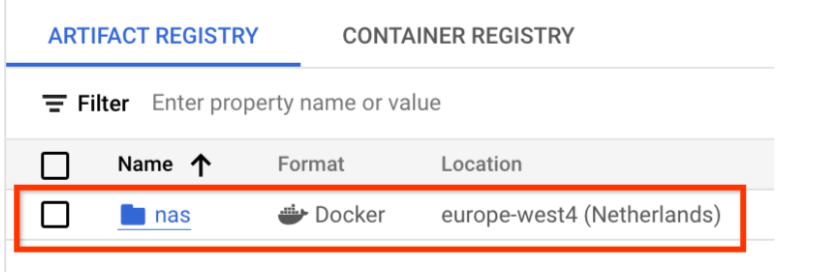
또한 이 저장소에 Docker를 푸시하도록 인증을 설정해야 합니다. 아래 로컬 환경 설정 섹션에 이 단계가 포함되어 있습니다.
로컬 환경 설정
로컬 환경에서 Bash 셸을 사용해서 이 단계를 실행하거나 Vertex AI Workbench 인스턴스의 노트북에서 실행할 수 있습니다.
서비스 계정 설정
NAS 작업을 실행하기 전에 서비스 계정을 설정해야 합니다. 로컬 환경에서 Bash 셸을 사용하여 이 단계를 실행하거나 Vertex AI Workbench 인스턴스의 노트북에서 실행할 수 있습니다.
예를 들어 다음 명령어는 my-nas-project 프로젝트에 aiplatform.user 및 storage.objectAdmin 역할을 가진 my-nas-sa라는 서비스 계정을 만듭니다.
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
코드 다운로드
Neural Architecture Search 실험을 시작하려면 사전 빌드된 트레이너, 검색 공간 정의, 관련 클라이언트 라이브러리가 포함된 샘플 Python 코드를 다운로드해야 합니다.
다음 단계를 실행하여 소스 코드를 다운로드합니다.