啟動 Vertex AI 類神經架構搜尋實驗前,請先設定環境。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用外部識別資訊提供者 (IdP),請先 使用聯合身分登入 gcloud CLI。
-
如要初始化 gcloud CLI,請執行下列指令:
gcloud init -
初始化 gcloud CLI 後,請更新並安裝必要元件:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用外部識別資訊提供者 (IdP),請先 使用聯合身分登入 gcloud CLI。
-
如要初始化 gcloud CLI,請執行下列指令:
gcloud init -
初始化 gcloud CLI 後,請更新並安裝必要元件:
gcloud components update gcloud components install beta
- 如要授予所有類神經架構搜尋使用者「Vertex AI 使用者」角色 (
roles/aiplatform.user),請與專案管理員聯絡。 - 安裝 Docker。
如果您使用的是 Ubuntu、Debian 等以 Linux 為基礎的作業系統,請將您的使用者名稱加入
docker群組,這樣就能在不使用sudo的情況下執行 Docker:sudo usermod -a -G docker ${USER}將自己加入
docker群組後,您可能需要重新啟動系統。 - 開啟 Docker。如要確認 Docker 正在運作,請執行下列 Docker 指令,這個指令會傳回目前的時間和日期:
docker run busybox date
- 使用
gcloud做為 Docker 的憑證輔助程式:gcloud auth configure-docker
-
(選用) 如要在本機環境中使用 GPU 來執行容器,請安裝
nvidia-docker。 -
指定新值區的名稱。Cloud Storage 中所有值區的名稱皆不得重複。
BUCKET_NAME="YOUR_BUCKET_NAME"
舉例來說,請使用您的專案名稱,並在後面附加
-vertexai-nas:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
檢查您建立的值區名稱。
echo $BUCKET_NAME
-
選取值區的地區,然後設定
REGION環境變數。使用的地區必須與您預計要執行類神經架構搜尋工作的地區相同。
例如,下列程式碼會建立
REGION並設為us-central1:REGION=us-central1
-
建立新值區:
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
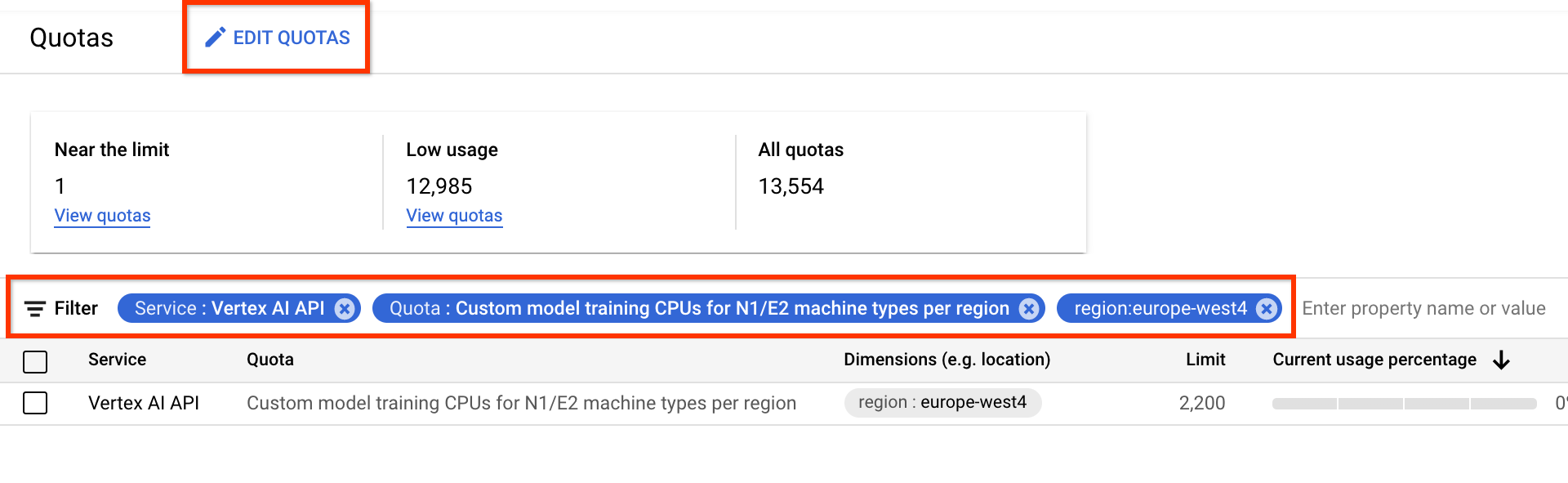
- 在「服務」部分,選取「Vertex AI API」。
- 在「區域」中,選取要篩選的區域。
- 在「配額」部分,選取前置字串為「自訂模型訓練」的加速器名稱。
- 如果是 V100 GPU,值為「每個區域的自訂模型訓練 Nvidia V100 GPU」。
- CPU 的值可以是每個區域的 N1/E2 機器類型自訂模型訓練 CPU。CPU 數量代表 CPU 單位。如要使用 8 個
highmem-16CPU,請申請 8 * 16 = 128 個 CPU 單位。同時輸入「region」的所需值。
設定基本環境變數:
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default login為構件登錄檔設定 Docker 驗證:
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(選用) 設定 Python 3 虛擬環境。建議使用 Python 3,但並非必要:
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activate安裝其他程式庫:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0建立服務帳戶:
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAME將
aiplatform.user和storage.objectAdmin角色指派給服務帳戶:gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdmin開啟新的 Shell 終端機。
執行 Git clone 指令:
git clone https://github.com/google/vertex-ai-nas.git
設定 Cloud Storage 值區
本節說明如何建立新值區。您可以使用現有值區,但該值區的所在地區,必須與您執行 AI Platform 工作的地區相同。此外,如果該值區不屬於您用來執行類神經架構搜尋的專案,您就必須明確地將該值區的存取權授予類神經架構搜尋服務帳戶。
為專案申請更多裝置配額
教學課程會使用約五部 CPU 機器,不需要任何額外配額。執行教學課程後,請執行類神經架構搜尋工作。
類神經架構搜尋作業會平行訓練一批模型。每個訓練好的模型都對應一項試驗。
請參閱設定 number-of-parallel-trials 一節,估算搜尋工作所需的 CPU 和 GPU 數量。舉例來說,如果每個試驗使用 2 個 T4 GPU,且您將 number-of-parallel-trials 設為 20,則搜尋工作需要 40 個 T4 GPU 的總配額。此外,如果每個試驗都使用 highmem-16 CPU,則每個試驗需要 16 個 CPU 單位,20 個平行試驗則需要 320 個 CPU 單位。不過,我們要求至少要有 10 個平行試用配額 (或 20 個 GPU 配額)。GPU 的預設初始配額會因區域和 GPU 類型而異,通常 Tesla_T4 的配額為 0、6 或 12,Tesla_V100 的配額為 0 或 6。CPU 的預設初始配額因地區而異,通常為 20、450 或 2,200。
選用:如果您打算平行執行多個搜尋工作,請擴充配額需求。要求配額不會立即產生費用。 執行工作後,系統就會向您收費。
如果配額不足,且您嘗試啟動的工作需要的資源超出配額,工作將無法啟動,並顯示類似下列內容的錯誤訊息:
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
在某些情況下,如果同一個專案的多個工作同時啟動,但配額不足以支援所有工作,其中一個工作就會處於佇列狀態,無法開始訓練。在這種情況下,請取消排入佇列的工作,並要求更多配額,或等待前一個工作完成。
您可以透過「配額」頁面申請額外裝置配額。您可以套用篩選器,找出要編輯的配額:
建立配額要求後,您會收到 Case number 和後續電子郵件,瞭解要求的狀態。GPU 配額申請大約需要兩到五個工作天才能獲得核准。一般而言,申請約 20 到 30 個 GPU 的配額,大約兩到三天內就能獲得核准;申請約 100 個 GPU 的配額,則可能需要五個工作天。CPU 配額申請最多可能需要兩個工作天才能獲得核准。不過,如果某個區域的 GPU 類型嚴重短缺,即使配額要求很小,也無法保證能取得配額。在這種情況下,系統可能會要求您改用其他區域或 GPU 類型。一般來說,T4 GPU 比 V100 GPU 更容易取得。T4 GPU 需要更多實際時間,但成本效益較高。
詳情請參閱「要求調整配額」。
為專案設定構件登錄檔
您必須為專案和推送 Docker 映像檔的區域設定 Artifact Registry。
前往專案的「Artifact Registry」頁面。 如果尚未啟用,請先為專案啟用 Artifact Registry API:
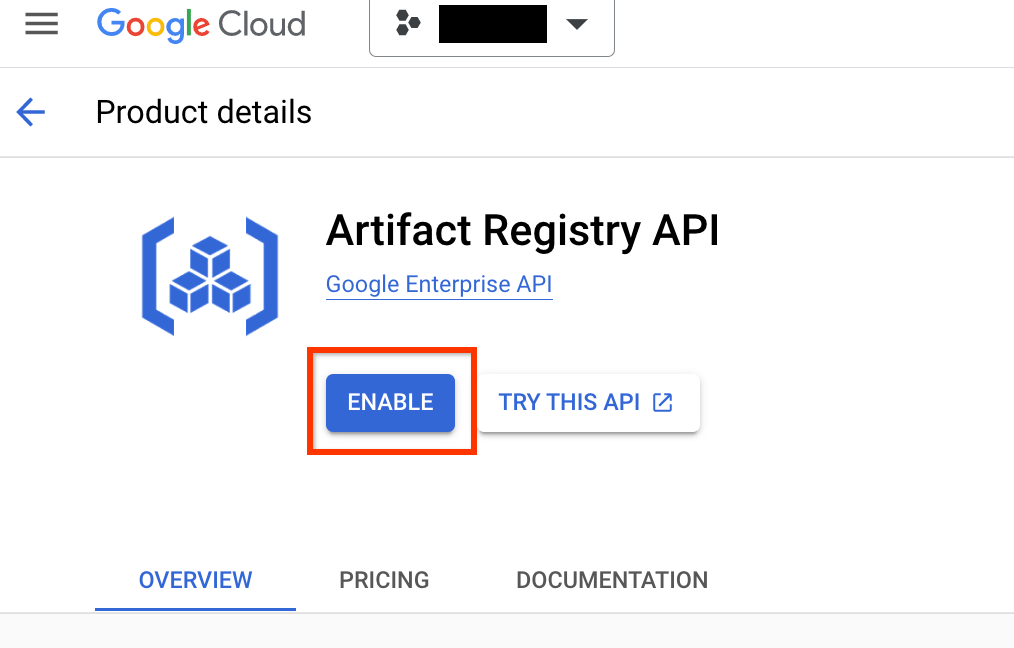
啟用後,按一下「建立存放區」,即可開始建立新存放區:

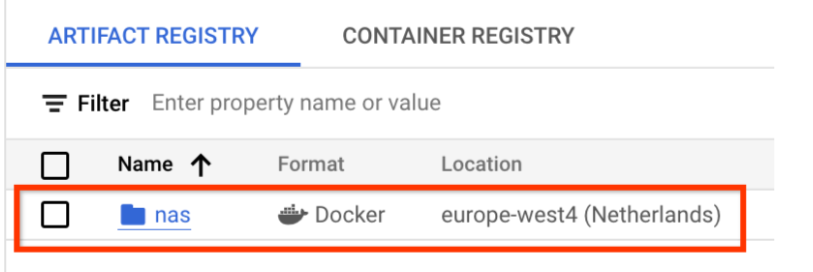
選擇「名稱」做為 nas、「格式」做為「Docker」,以及「位置類型」做為「區域」。在「區域」中,選取您執行作業的位置,然後按一下「建立」。

這應該會建立您想要的 Docker 存放區,如下所示:
您也需要設定驗證機制,才能將 Docker 推送至這個存放區。下方的本機環境設定部分包含這個步驟。
設定本機環境
您可以使用本機環境中的 Bash 殼層執行這些步驟,也可以從 Vertex AI Workbench 執行個體的筆記本執行這些步驟。
設定服務帳戶
您必須先設定服務帳戶,才能執行 NAS 工作。您可以在本機環境的 Bash 殼層中執行這些步驟,也可以在 Vertex AI Workbench 執行個體的筆記本中執行。
舉例來說,下列指令會在專案 my-nas-project 下建立名為 my-nas-sa 的服務帳戶,並指派 aiplatform.user 和 storage.objectAdmin 角色:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
下載程式碼
如要開始進行 Neural Architecture Search 實驗,請下載範例 Python 程式碼,其中包含預先建構的訓練器、搜尋空間定義和相關聯的用戶端程式庫。
請按照下列步驟下載原始碼。