Questa pagina introduce i percorsi dei dati tabulari con AutoML. Per comprendere le principali differenze tra AutoML e l'addestramento personalizzato, consulta Scegliere un metodo di addestramento.
Casi d'uso dei dati tabulari
Immagina di lavorare nel reparto marketing di un rivenditore digitale. Tu e il tuo team state
creando un programma email personalizzato basato sulle buyer persona. Hai creato le buyer persona
e le email di marketing sono pronte per essere inviate. Ora devi creare un sistema che raggruppi i clienti
in ogni buyer persona in base alle preferenze di vendita al dettaglio e al comportamento di spesa, anche quando si tratta di nuovi
clienti. Per massimizzare il coinvolgimento dei clienti, vuoi anche prevedere le loro abitudini di spesa in modo da poter ottimizzare i tempi di invio delle email.
In qualità di rivenditore digitale, disponi di dati sui tuoi clienti e sugli acquisti che hanno effettuato. Ma che dire dei nuovi clienti? Gli approcci tradizionali possono calcolare questi valori per i clienti esistenti con lunghe cronologie acquisti, ma non funzionano bene con i clienti con pochi dati storici. E se potessi creare un sistema per prevedere questi valori e aumentare la velocità con cui offri programmi di marketing personalizzati a tutti i tuoi clienti?
Fortunatamente, il machine learning e Vertex AI sono ben posizionati per risolvere questi problemi.
Questa guida illustra il funzionamento di Vertex AI per i modelli e i set di dati AutoML e mostra i tipi di problemi che Vertex AI è progettata per risolvere.
Come funziona Vertex AI?
Vertex AI applica il machine learning supervisionato per ottenere il risultato desiderato. I dettagli dell'algoritmo e dei metodi di addestramento cambiano in base al tipo di dati e al caso d'uso. Molte sottocategorie diverse del machine learning risolvono problemi diversi e operano entro vincoli diversi.
Addestri un modello di machine learning con dati di esempio. Vertex AI
utilizza i dati tabulari (strutturati) per addestrare un modello di machine learning per fare
inferenze sui nuovi dati. Il modello imparerà a fare previsioni sui dati di una singola colonna del set di dati, chiamata target. Alcune delle altre colonne di dati
sono gli input (chiamati caratteristiche) da cui il modello apprenderà i pattern. Puoi
utilizzare le stesse caratteristiche di input per creare diversi tipi di modelli semplicemente modificando
la colonna target e le opzioni di addestramento. Dall'esempio di email marketing, ciò
significa che potresti creare modelli con le stesse caratteristiche di input, ma con inferenze
di target diverse. Un modello potrebbe prevedere la persona tipo di un cliente (un
target categorico), un altro modello potrebbe prevedere la sua spesa mensile (un
target numerico) e un altro ancora potrebbe prevedere la domanda giornaliera dei tuoi prodotti
per i prossimi tre mesi (una serie di target numerici).
Flusso di lavoro di Vertex AI
Vertex AI utilizza un flusso di lavoro di machine learning standard:
- Raccogli i dati: determina i dati necessari per l'addestramento e il test del modello in base al risultato che vuoi ottenere.
- Prepara i dati: assicurati che siano formattati ed etichettati correttamente.
- Addestra: imposta i parametri e crea il modello.
- Valuta: esamina le metriche del modello.
- Esegui il deployment e la previsione: rendi disponibile il tuo modello.
Prima di iniziare a raccogliere i dati, pensa al problema che stai cercando di risolvere. Ciò determina i requisiti dei dati.
Preparazione dei dati
Valuta il tuo caso d'uso
Inizia dal tuo problema: qual è il risultato che vuoi ottenere?
Che tipo di dati contiene la colonna target? A quanti dati hai accesso? A seconda delle tue risposte, Vertex AI crea il modello necessario per risolvere il tuo caso d'uso:
- I modelli di classificazione binaria prevedono un risultato binario (una delle due classi). Utilizza questo tipo di modello per le domande con risposta sì o no. Ad esempio, potresti voler creare un modello di classificazione binaria per prevedere se un cliente acquisterà un abbonamento. In genere, un problema di classificazione binaria richiede meno dati rispetto ad altri tipi di modelli.
- I modelli di classificazione multi-classe prevedono una classe tra tre o più classi discrete. Utilizza questo tipo di modello per la categorizzazione. Ad esempio, in qualità di rivenditore, potresti voler creare un modello di classificazione multiclasse per segmentare i clienti in diverse buyer persona.
- I modelli di regressione prevedono un valore continuo. Ad esempio, in qualità di rivenditore, potresti voler creare un modello di regressione per prevedere quanto spenderà un cliente il mese successivo.
- I modelli di previsione prevedono una sequenza di valori. Ad esempio, in qualità di rivenditore, potresti voler prevedere la domanda giornaliera dei tuoi prodotti per i prossimi tre mesi, in modo da poter fare scorta di inventari in anticipo.
La previsione sui dati tabulari è diversa dalla classificazione e dalla regressione in due modi principali:
Nella classificazione e nella regressione, il valore previsto del target dipende solo dai valori delle colonne delle funzionalità nella stessa riga. Nella previsione, i valori previsti dipendono anche dai valori di contesto della destinazione e delle funzionalità.
Nei problemi di regressione e classificazione, l'output è un valore. Nei problemi di previsione, l'output è una sequenza di valori.
Raccogliere i dati
Dopo aver stabilito il caso d'uso, raccogli i dati che ti consentono di creare il modello che preferisci.
 Dopo aver stabilito il caso d'uso, devi raccogliere i dati per addestrare il modello.
L'ottenimento e la preparazione dei dati sono passaggi fondamentali per la creazione di un modello di machine learning.
I dati a tua disposizione determinano il tipo di problemi che puoi risolvere. Quanti dati hai a disposizione? I dati sono pertinenti alle domande a cui stai cercando di rispondere? Durante la
raccolta dei dati, tieni presente le seguenti considerazioni chiave.
Dopo aver stabilito il caso d'uso, devi raccogliere i dati per addestrare il modello.
L'ottenimento e la preparazione dei dati sono passaggi fondamentali per la creazione di un modello di machine learning.
I dati a tua disposizione determinano il tipo di problemi che puoi risolvere. Quanti dati hai a disposizione? I dati sono pertinenti alle domande a cui stai cercando di rispondere? Durante la
raccolta dei dati, tieni presente le seguenti considerazioni chiave.
Seleziona le funzionalità pertinenti
Una funzionalità è un attributo di input utilizzato per l'addestramento del modello. Le funzionalità sono il modo in cui il modello identifica i pattern per fare inferenze, quindi devono essere pertinenti al problema. Ad esempio, per creare un modello che preveda se una transazione con carta di credito è fraudolenta o meno, devi creare un set di dati che contenga i dettagli della transazione, come acquirente, venditore, importo, data e ora e articoli acquistati. Altre funzionalità utili potrebbero essere informazioni storiche sull'acquirente e sul venditore e la frequenza con cui l'articolo acquistato è stato coinvolto in frodi. Quali altre funzionalità potrebbero essere pertinenti?
Considera il caso d'uso del marketing via email per la vendita al dettaglio dell'introduzione. Ecco alcune colonne delle funzionalità che potresti richiedere:
- Elenco degli articoli acquistati (inclusi brand, categorie, prezzi, sconti)
- Numero di articoli acquistati (ultimo giorno, settimana, mese, anno)
- Somma di denaro speso (ultimo giorno, settimana, mese, anno)
- Per ogni articolo, il numero totale venduto ogni giorno
- Per ogni articolo, il totale disponibile ogni giorno
- Se stai organizzando una promozione per un giorno specifico
- Profilo demografico noto dell'acquirente
Includere dati sufficienti
 In generale, più esempi di addestramento hai, migliore sarà il risultato. La quantità di dati di esempio
richiesti varia anche in base alla complessità del problema che stai cercando di risolvere. Non avrai bisogno di tanti dati per ottenere un modello di classificazione binaria accurato rispetto a un modello multiclasse
perché è meno complicato prevedere una classe da due piuttosto che da molte.
In generale, più esempi di addestramento hai, migliore sarà il risultato. La quantità di dati di esempio
richiesti varia anche in base alla complessità del problema che stai cercando di risolvere. Non avrai bisogno di tanti dati per ottenere un modello di classificazione binaria accurato rispetto a un modello multiclasse
perché è meno complicato prevedere una classe da due piuttosto che da molte.
Non esiste una formula perfetta, ma sono consigliati valori minimi per i dati di esempio:
- Problema di classificazione: 50 righe x il numero di caratteristiche
- Problema di previsione:
- 5000 righe x il numero di caratteristiche
- 10 valori univoci nella colonna dell'identificatore della serie temporale x il numero di funzionalità
- Problema di regressione: 200 x il numero di funzionalità
Acquisizione della variante
Il set di dati deve riflettere la diversità dello spazio del problema. Più esempi diversi vede un modello durante l'addestramento, più facilmente può generalizzare a esempi nuovi o meno comuni. Immagina se il tuo modello di vendita al dettaglio fosse addestrato solo utilizzando i dati di acquisto invernali. Sarebbe in grado di prevedere correttamente le preferenze di abbigliamento estivo o i comportamenti di acquisto?
Preparare i dati
 Dopo aver identificato i dati disponibili, devi assicurarti che siano pronti per l'addestramento.
Se i dati sono distorti o contengono valori mancanti o errati, la qualità del modello ne risente. Prima di iniziare ad addestrare il modello, considera quanto segue.
Scopri di più.
Dopo aver identificato i dati disponibili, devi assicurarti che siano pronti per l'addestramento.
Se i dati sono distorti o contengono valori mancanti o errati, la qualità del modello ne risente. Prima di iniziare ad addestrare il modello, considera quanto segue.
Scopri di più.
Prevenire la perdita di dati e il disallineamento tra addestramento e distribuzione
La perdita di dati si verifica quando utilizzi feature di input durante l'addestramento che "rivelano" informazioni sul target che stai cercando di prevedere e che non sono disponibili quando il modello viene effettivamente utilizzato. Ciò può essere rilevato quando una funzionalità altamente correlata alla colonna target viene inclusa come una delle funzionalità di input. Ad esempio, se stai creando un modello per prevedere se un cliente si abbonerà il mese successivo e una delle funzionalità di input è un futuro pagamento dell'abbonamento da parte di quel cliente. Ciò può portare a un buon rendimento del modello durante il test, ma non durante il deployment in produzione, poiché i dati di pagamento dell'abbonamento futuro non sono disponibili al momento della pubblicazione.
Il disallineamento addestramento/produzione si verifica quando le funzionalità di input utilizzate durante l'addestramento sono diverse da quelle fornite al modello al momento della pubblicazione, causando una scarsa qualità del modello in produzione. Ad esempio, la creazione di un modello per prevedere le temperature orarie, ma l'addestramento con dati che contengono solo le temperature settimanali. Un altro esempio: fornire sempre i voti di uno studente nei dati di addestramento quando si prevede l'abbandono degli studi, ma non fornire queste informazioni al momento della pubblicazione.
Comprendere i dati di addestramento è importante per prevenire la perdita di dati e il disallineamento tra addestramento e distribuzione:
- Prima di utilizzare i dati, assicurati di sapere cosa significano e se devi utilizzarli come funzionalità
- Controlla la correlazione nella scheda Train. Le correlazioni elevate devono essere segnalate per la revisione.
- Disallineamento addestramento/produzione: assicurati di fornire al modello solo le funzionalità di input disponibili esattamente nella stessa forma al momento della pubblicazione.
Pulire i dati mancanti, incompleti e incoerenti
È normale che nei dati di esempio siano presenti valori mancanti e imprecisi. Prenditi il tempo necessario per esaminare e, se possibile, migliorare la qualità dei dati prima di utilizzarli per l'addestramento. Più valori mancanti ci sono, meno utili saranno i dati per l'addestramento di un modello di machine learning.
- Controlla se nei dati sono presenti valori mancanti e correggili, se possibile, oppure lascia vuoto il valore se la colonna è impostata in modo da accettare valori nulli. Vertex AI è in grado di gestire i valori mancanti, ma è più probabile che tu ottenga risultati ottimali se tutti i valori sono disponibili.
- Per la previsione, verifica che l'intervallo tra le righe di addestramento sia coerente. Vertex AI può imputare i valori mancanti, ma è più probabile ottenere risultati ottimali se tutte le righe sono disponibili.
- Pulisci i dati correggendo o eliminando errori o rumore. Rendi coerenti i dati: Controlla l'ortografia, le abbreviazioni e la formattazione.
Analizzare i dati dopo l'importazione
Vertex AI fornisce una panoramica del set di dati dopo l'importazione. Controlla il set di dati importato per assicurarti che ogni colonna abbia il tipo di variabile corretto. Vertex AI rileverà automaticamente il tipo di variabile in base ai valori delle colonne, ma è consigliabile esaminare ciascuna variabile. Devi anche esaminare la nullabilità di ogni colonna, che determina se una colonna può avere valori mancanti o NULL.
Addestramento del modello
Dopo aver importato il set di dati, il passaggio successivo consiste nell'addestramento di un modello. Vertex AI genererà un modello di machine learning affidabile con i valori predefiniti di addestramento, ma potresti voler modificare alcuni parametri in base al tuo caso d'uso.
Cerca di selezionare il maggior numero possibile di colonne di funzionalità per l'addestramento, ma esamina ciascuna per assicurarti che sia adatta all'addestramento. Tieni presente quanto segue per la selezione delle funzionalità:
- Non selezionare colonne di funzionalità che creano rumore, ad esempio colonne di identificatori assegnati casualmente con un valore univoco per ogni riga.
- Assicurati di comprendere ogni colonna delle funzionalità e i relativi valori.
- Se stai creando più modelli da un set di dati, rimuovi le colonne di destinazione che non fanno parte del problema di inferenza corrente.
- Ricorda i principi di equità: stai addestrando il modello con una funzionalità che potrebbe portare a processi decisionali di parte o ingiusti per i gruppi emarginati?
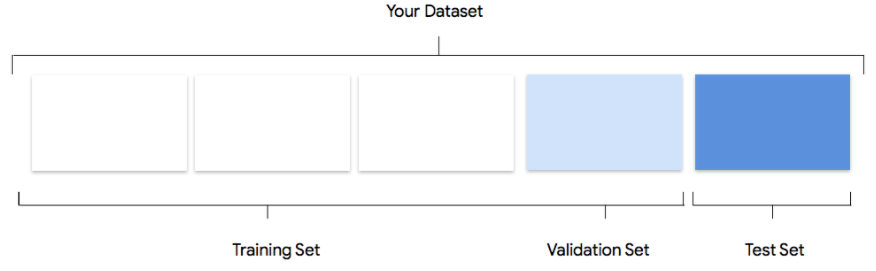
Come Vertex AI utilizza il tuo set di dati
Il set di dati verrà suddiviso in set di addestramento, convalida e test. La
divisione predefinita applicata da Vertex AI dipende dal tipo di modello che
stai addestrando. Se necessario, puoi anche specificare le suddivisioni (suddivisioni manuali). Per saperne di più, consulta Informazioni sulle suddivisioni di dati per i modelli AutoML.
Set di addestramento
 La maggior parte dei dati dovrebbe essere presente nel set di addestramento. Questi sono i dati che il modello "vede"
durante l'addestramento: vengono utilizzati per apprendere i parametri del modello, ossia i pesi delle
connessioni tra i nodi della rete neurale.
La maggior parte dei dati dovrebbe essere presente nel set di addestramento. Questi sono i dati che il modello "vede"
durante l'addestramento: vengono utilizzati per apprendere i parametri del modello, ossia i pesi delle
connessioni tra i nodi della rete neurale.
Set di convalida
 Il set di convalida, talvolta chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento.
Dopo che i dati di addestramento sono stati incorporati durante ogni iterazione del processo di addestramento, il framework di apprendimento del modello utilizza le prestazioni del modello sul set di convalida per ottimizzarne gli iperparametri, che sono variabili che specificano la struttura del modello. Se si cercasse di utilizzare il set di addestramento per ottimizzare gli iperparametri, è molto probabile che il modello finirebbe per concentrarsi eccessivamente sui dati di addestramento e avrebbe difficoltà a generalizzare in base a esempi che non corrispondono esattamente.
L'utilizzo di un set di dati nuovo per ottimizzare la struttura del modello consente una migliore generalizzazione da parte del modello.
Il set di convalida, talvolta chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento.
Dopo che i dati di addestramento sono stati incorporati durante ogni iterazione del processo di addestramento, il framework di apprendimento del modello utilizza le prestazioni del modello sul set di convalida per ottimizzarne gli iperparametri, che sono variabili che specificano la struttura del modello. Se si cercasse di utilizzare il set di addestramento per ottimizzare gli iperparametri, è molto probabile che il modello finirebbe per concentrarsi eccessivamente sui dati di addestramento e avrebbe difficoltà a generalizzare in base a esempi che non corrispondono esattamente.
L'utilizzo di un set di dati nuovo per ottimizzare la struttura del modello consente una migliore generalizzazione da parte del modello.
Set di test
 Il set di test non è coinvolto in alcun modo nel processo di addestramento. Al termine dell'addestramento del modello, Vertex AI utilizza il set di test come risorsa di verifica completamente nuova per il modello.
Le prestazioni del modello in base al set di test hanno lo scopo di dare un'idea abbastanza precisa di come
il modello si comporterà utilizzando dati reali.
Il set di test non è coinvolto in alcun modo nel processo di addestramento. Al termine dell'addestramento del modello, Vertex AI utilizza il set di test come risorsa di verifica completamente nuova per il modello.
Le prestazioni del modello in base al set di test hanno lo scopo di dare un'idea abbastanza precisa di come
il modello si comporterà utilizzando dati reali.
Valuta, testa ed esegui il deployment del modello
Valuta il modello
 Dopo l'addestramento del modello, riceverai un riepilogo delle sue prestazioni. Le metriche di valutazione del modello si basano sul rendimento del modello rispetto a una sezione del set di dati (il set di dati di test). Esistono alcune metriche e concetti chiave da considerare per determinare se il modello è pronto per essere utilizzato con dati reali.
Dopo l'addestramento del modello, riceverai un riepilogo delle sue prestazioni. Le metriche di valutazione del modello si basano sul rendimento del modello rispetto a una sezione del set di dati (il set di dati di test). Esistono alcune metriche e concetti chiave da considerare per determinare se il modello è pronto per essere utilizzato con dati reali.
Metriche di classificazione
Soglia punteggio
Prendi in considerazione un modello di machine learning che preveda se un cliente acquisterà una giacca nel prossimo
anno. Quanto deve essere sicuro il modello prima di prevedere che un determinato cliente acquisterà una
giacca? Nei modelli di classificazione, a ogni inferenza viene assegnato un punteggio di confidenza, ovvero una valutazione numerica del livello di certezza del modello che la classe prevista sia corretta. La soglia del punteggio è
il numero che determina quando un determinato punteggio viene convertito in una decisione affermativa o negativa, ovvero
il valore in corrispondenza del quale il modello afferma "Sì, questo punteggio di confidenza è sufficientemente alto per concludere che
questo cliente acquisterà un cappotto nel prossimo anno".
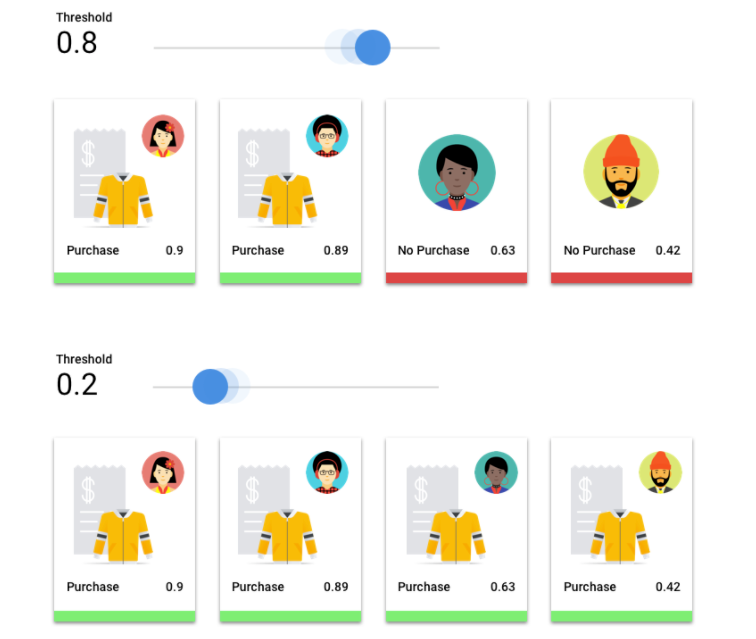
Se la soglia del punteggio è bassa, il modello rischia di essere classificato in modo errato. Per questo motivo, la soglia del punteggio deve essere basata su un determinato caso d'uso.
Risultati dell'inferenza
Dopo aver applicato la soglia del punteggio, le inferenze effettuate dal modello rientreranno in una delle quattro categorie. Per comprendere queste categorie, immagina di nuovo un modello di classificazione binaria di una giacca. In questo esempio, la classe positiva (ciò che il modello tenta di prevedere) è che il cliente acquisterà una giacca nel prossimo anno.
- Vero positivo: il modello prevede correttamente la classe positiva. Il modello ha previsto correttamente che un cliente ha acquistato una giacca.
- Falso positivo: il modello prevede in modo errato la classe positiva. Il modello ha previsto che un cliente ha acquistato una giacca, ma non è così.
- Vero negativo: il modello prevede correttamente la classe negativa. Il modello ha previsto correttamente che un cliente non ha acquistato una giacca.
- Falso negativo: il modello prevede in modo errato una classe negativa. Il modello ha previsto che un cliente non ha acquistato una giacca, ma l'ha fatto.

Precisione e richiamo
Le metriche di precisione e richiamo ti aiutano a capire se il modello sta acquisendo informazioni adeguate e cosa sta tralasciando. Scopri di più su precisione e richiamo.
- Per precisione si intende la frazione delle inferenze positive che sono risultate corrette. Tra tutte le inferenze di acquisto di un cliente, qual è la frazione di acquisti effettivi?
- Per richiamo si intende la frazione delle righe con questa etichetta che sono state previste correttamente dal modello. Tra tutte le previsioni che un cliente potrebbe aver identificato, qual è la frazione prevista correttamente?
A seconda del caso d'uso, potrebbe essere necessario ottimizzare la precisione o il richiamo.
Altre metriche di classificazione
- AUC PR: l'area sotto la curva di precisione-richiamo (PR). Il valore va da zero a uno, dove un valore più elevato indica un modello di qualità superiore.
- AUC ROC: l'area sotto la curva della caratteristica operativa del ricevitore (ROC). Il valore varia in un intervallo da zero a uno, dove un valore più elevato indica un modello di qualità superiore.
- Accuratezza: la frazione delle inferenze di classificazione prodotte dal modello che sono risultate corrette.
- Perdita logaritmica: l'entropia incrociata tra le inferenze del modello e i valori target. L'intervallo va da zero a infinito, dove un valore più basso indica un modello di qualità superiore.
- Punteggio F1: la media armonica di precisione e richiamo. F1 è una metrica utile per trovare un equilibrio tra precisione e richiamo qualora esista una distribuzione non uniforme delle classi.
Metriche di previsione e regressione
Una volta creato il modello, Vertex AI fornisce una serie di metriche standard da esaminare. Non esiste una risposta perfetta su come valutare il modello. Considera le metriche di valutazione nel contesto del tipo di problema e di ciò che vuoi ottenere con il modello. Il seguente elenco è una panoramica di alcune metriche che Vertex AI può fornire.
Errore assoluto medio (MAE)
Il MAE (Mean Absolute Error) indica la differenza media assoluta tra i valori target e quelli previsti. Misura la portata media degli errori, ovvero la differenza tra il valore target e quello previsto, in un insieme di inferenze. Inoltre, poiché utilizza valori assoluti, il MAE non prende in considerazione la direzione della relazione né indica se le prestazioni sono migliori o peggiori. Quando si valuta il MAE, un valore minore indica un modello di qualità migliore (0 rappresenta un predittore perfetto).
Errore quadratico medio (RMSE)
L'RMSE (Root Mean Square Error) è la radice quadrata della media dei quadrati delle differenze tra i valori target e quelli previsti. L'RMSE è più sensibile agli outlier rispetto al MAE. Di conseguenza, se la preoccupazione principale riguarda gli errori di grande entità, l'RMSE può essere una metrica più utile da valutare. Analogamente al MAE, un valore minore indica un modello di qualità migliore (0 rappresenta un predittore perfetto).
Errore logaritmico quadratico medio (RMSLE)
L'errore logaritmico quadratico medio (RMSLE) è l'equivalente in scala logaritmica dell'errore quadratico medio (RMSE). L'RMSLE è più sensibile agli errori relativi rispetto a quelli assoluti e si preoccupa maggiormente del rendimento insoddisfacente rispetto a quello eccessivo.
Quantile osservato (solo previsione)
Per un dato quantile target, il quantile osservato mostra la frazione effettiva dei valori osservati al di sotto dei valori di inferenza del quantile specificato. Il quantile osservato mostra quanto il modello si avvicina o si allontana dal quantile target. Una differenza minore tra i due valori indica un modello di qualità migliore.
Scaled pinball loss (solo previsione)
Misura la qualità di un modello in un dato quantile target. Un numero più basso indica un modello di qualità migliore. Puoi confrontare la metrica della perdita a forma di flipper scalata in diversi quantili per determinare l'accuratezza relativa del modello tra questi quantili.
Testa il tuo modello
La valutazione delle metriche del modello è il modo principale per determinare se il modello è pronto per la distribuzione, ma è anche possibile testarlo con nuovi dati. Carica nuovi dati per vedere se le inferenze del modello corrispondono alle tue aspettative. In base alle metriche di valutazione o ai test con nuovi dati, potrebbe essere necessario continuare a migliorare le prestazioni del modello.
Esegui il deployment del modello
Se ritieni che le prestazioni del modello vadano bene, puoi iniziare a utilizzarlo. Potresti utilizzarlo in produzione o potrebbe essere una richiesta di inferenza una tantum. In base al caso d'uso, puoi usare il modello in vari modi.
Inferenza batch
L'inferenza batch è utile per fare molte richieste di inferenza contemporaneamente. L'inferenza batch è asincrona, il che significa che il modello attende di elaborare tutte le richieste di inferenza prima di restituire un file CSV o una tabella BigQuery con i valori di inferenza.
Inferenza online
Esegui il deployment del modello per renderlo disponibile per le richieste di inferenza utilizzando un'API REST. L'inferenza online è sincrona (in tempo reale), il che significa che restituirà rapidamente i risultati, ma accetta una sola richiesta di inferenza per ogni chiamata API. L'inferenza online è utile se il modello fa parte di un'applicazione e alcune parti del tuo sistema dipendono da risposte rapide restituite dall'inferenza.
Esegui la pulizia
Per evitare addebiti indesiderati, annulla il deployment del modello quando non è in uso.
Quando hai finito di utilizzare il modello, elimina le risorse che hai creato per evitare addebiti indesiderati sul tuo account.
- Introduzione ai dati di immagine: pulizia del progetto
- Introduzione ai dati tabulari: pulizia del progetto