Esta página apresenta percursos de dados tabulares com o AutoML. Para compreender as principais diferenças entre o AutoML e a preparação personalizada, consulte o artigo Escolher um método de preparação.
Exemplos de utilização de dados tabulares
Imagine que trabalha no departamento de marketing de um retalhista digital. A sua equipa e o anunciante estão a criar um programa de email personalizado com base em personagens fictícias de clientes. Criou as personas
e os emails de marketing estão prontos. Agora, tem de criar um sistema que agrupe os clientes
em cada persona com base nas preferências de retalho e no comportamento de gastos, mesmo quando são clientes
novos. Para maximizar a interação dos clientes, também quer prever os respetivos hábitos de gastos para poder otimizar o momento de envio dos emails.
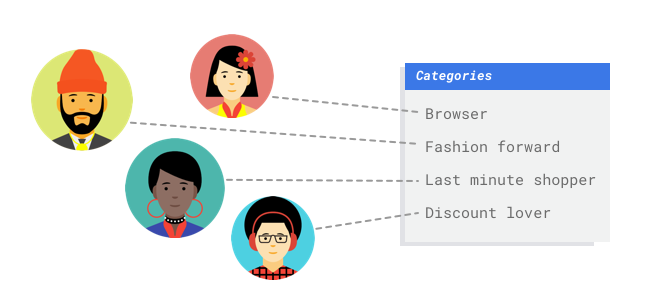
Uma vez que é um retalhista digital, tem dados sobre os seus clientes e as compras que fizeram. Mas e os novos clientes? As abordagens tradicionais podem calcular estes valores para clientes existentes com longos históricos de compras, mas não funcionam bem com clientes com poucos dados do histórico. E se pudesse criar um sistema para prever estes valores e aumentar a velocidade com que oferece programas de marketing personalizados a todos os seus clientes?
Felizmente, a aprendizagem automática e o Vertex AI estão bem posicionados para resolver estes problemas.
Este guia explica como funciona a Vertex AI para conjuntos de dados e modelos do AutoML, e ilustra os tipos de problemas que a Vertex AI foi concebida para resolver.
Como funciona o Vertex AI?
O Vertex AI aplica a aprendizagem automática supervisionada para alcançar um resultado desejado. As especificidades do algoritmo e dos métodos de preparação mudam com base no tipo de dados e no exemplo de utilização. Muitas subcategorias diferentes de aprendizagem automática resolvem problemas diferentes e funcionam dentro de restrições diferentes.
Prepara um modelo de aprendizagem automática com dados de exemplo. O Vertex AI
usa dados tabulares (estruturados) para preparar um modelo de aprendizagem automática para fazer
inferências sobre novos dados. Uma coluna do seu conjunto de dados, denominada destino, é o que o modelo vai aprender a prever. Algumas das outras colunas de dados são entradas (denominadas caraterísticas) a partir das quais o modelo vai aprender padrões. Pode
usar as mesmas caraterísticas de entrada para criar vários tipos de modelos apenas alterando
a coluna de destino e as opções de preparação. No exemplo de email marketing, isto significa que pode criar modelos com as mesmas caraterísticas de entrada, mas com inferências de destino diferentes. Um modelo pode prever o perfil fictício de um cliente (um alvo categórico), outro modelo pode prever os respetivos gastos mensais (um alvo numérico) e outro pode prever a procura diária dos seus produtos para os próximos três meses (série de alvos numéricos).
Fluxo de trabalho do Vertex AI
O Vertex AI usa um fluxo de trabalho de aprendizagem automática padrão:
- Reúna os seus dados: determine os dados de que precisa para preparar e testar o modelo com base no resultado que quer alcançar.
- Prepare os dados: certifique-se de que os dados estão formatados e etiquetados corretamente.
- Preparação: defina parâmetros e crie o seu modelo.
- Avalie: reveja as métricas do modelo.
- Implemente e preveja: disponibilize o seu modelo para utilização.
Antes de começar a recolher os seus dados, pense no problema que está a tentar resolver. Isto informa os seus requisitos de dados.
Preparação de dados
Avalie o seu exemplo de utilização
Comece pelo seu problema: que resultado quer alcançar?
Que tipo de dados é a coluna de destino? A que quantidade de dados tem acesso? Com base nas suas respostas, a Vertex AI cria o modelo necessário para resolver o seu exemplo de utilização:
- Os modelos de classificação binária preveem um resultado binário (uma de duas classes). Use este tipo de modelo para perguntas de sim ou não. Por exemplo, pode querer criar um modelo de classificação binária para prever se um cliente compraria uma subscrição. Geralmente, um problema de classificação binária requer menos dados do que outros tipos de modelos.
- Os modelos de classificação multiclasse preveem uma classe a partir de três ou mais classes discretas. Use este tipo de modelo para a categorização. Por exemplo, como retalhista, pode querer criar um modelo de classificação de várias classes para segmentar os clientes em diferentes personagens fictícias.
- Os modelos de regressão preveem um valor contínuo. Por exemplo, como retalhista, pode querer criar um modelo de regressão para prever quanto um cliente vai gastar no próximo mês.
- Os modelos de previsão preveem uma sequência de valores. Por exemplo, como retalhista, pode querer prever a procura diária dos seus produtos para os próximos 3 meses, de modo a poder armazenar adequadamente os inventários de produtos antecipadamente.
A previsão em dados tabulares difere da classificação e da regressão de duas formas principais:
Na classificação e na regressão, o valor previsto do destino depende apenas dos valores das colunas de caraterísticas na mesma linha. Na previsão, os valores previstos também dependem dos valores de contexto do alvo e das caraterísticas.
Em problemas de regressão e classificação, a saída é um valor. Nos problemas de previsão, a saída é uma sequência de valores.
Reúna os seus dados
Depois de estabelecer o seu exemplo de utilização, recolha os dados que lhe permitem criar o modelo pretendido.
 Depois de estabelecer o seu exemplo de utilização, tem de recolher dados para preparar o modelo.
A obtenção e a preparação de dados são passos essenciais para criar um modelo de aprendizagem automática.
Os dados que tem disponíveis determinam o tipo de problemas que pode resolver. Quantos dados tem disponíveis? Os seus dados são relevantes para as perguntas às quais está a tentar responder? Ao
recolher os seus dados, tenha em atenção as seguintes considerações importantes.
Depois de estabelecer o seu exemplo de utilização, tem de recolher dados para preparar o modelo.
A obtenção e a preparação de dados são passos essenciais para criar um modelo de aprendizagem automática.
Os dados que tem disponíveis determinam o tipo de problemas que pode resolver. Quantos dados tem disponíveis? Os seus dados são relevantes para as perguntas às quais está a tentar responder? Ao
recolher os seus dados, tenha em atenção as seguintes considerações importantes.
Selecione funcionalidades relevantes
Uma funcionalidade é um atributo de entrada usado para a preparação de modelos. As funcionalidades são a forma como o seu modelo identifica padrões para fazer inferências, pelo que têm de ser relevantes para o seu problema. Por exemplo, para criar um modelo que preveja se uma transação de cartão de crédito é fraudulenta ou não, tem de criar um conjunto de dados que contenha detalhes da transação, como o comprador, o vendedor, o valor, a data e a hora, e os artigos comprados. Outras funcionalidades úteis podem ser informações históricas sobre o comprador e o vendedor, e a frequência com que o artigo comprado esteve envolvido em fraudes. Que outras funcionalidades podem ser relevantes?
Considere o exemplo de utilização de marketing por email de retalho da introdução. Seguem-se algumas colunas de atributos que pode precisar:
- Lista de artigos comprados (incluindo marcas, categorias, preços e descontos)
- Número de artigos comprados (último dia, semana, mês, ano)
- Soma do dinheiro gasto (último dia, semana, mês, ano)
- Para cada artigo, número total vendido por dia
- Para cada item, total em stock por dia
- Quer esteja a apresentar uma promoção para um dia específico
- Perfil demográfico conhecido do comprador
Inclua dados suficientes
 Em geral, quanto mais exemplos de preparação tiver, melhor será o resultado. A quantidade de dados de exemplo necessários também varia consoante a complexidade do problema que está a tentar resolver. Não
precisa de tantos dados para ter um modelo de classificação binária preciso em comparação com um modelo de várias classes
porque é menos complicado prever uma classe a partir de duas do que de muitas.
Em geral, quanto mais exemplos de preparação tiver, melhor será o resultado. A quantidade de dados de exemplo necessários também varia consoante a complexidade do problema que está a tentar resolver. Não
precisa de tantos dados para ter um modelo de classificação binária preciso em comparação com um modelo de várias classes
porque é menos complicado prever uma classe a partir de duas do que de muitas.
Não existe uma fórmula perfeita, mas existem mínimos recomendados de dados de exemplo:
- Problema de classificação: 50 linhas x o número de funcionalidades
- Problema de previsão:
- 5000 linhas x o número de funcionalidades
- 10 valores únicos na coluna do identificador da série cronológica x o número de caraterísticas
- Problema de regressão: 200 vezes o número de caraterísticas
Variação de captura
O conjunto de dados deve captar a diversidade do seu espaço de problemas. Quanto mais diversos forem os exemplos que um modelo vê durante a preparação, mais facilmente consegue generalizar para exemplos novos ou menos comuns. Imagine que o seu modelo de retalho foi preparado apenas com dados de compras do inverno. Seria capaz de prever com êxito as preferências de vestuário de verão ou os comportamentos de compra?
Prepare os seus dados
 Depois de identificar os dados disponíveis, tem de se certificar de que estão prontos para a preparação.
Se os seus dados forem tendenciosos ou contiverem valores em falta ou erróneos, isto afeta a qualidade do modelo. Tenha em atenção o seguinte antes de começar a preparar o modelo.
Saiba mais.
Depois de identificar os dados disponíveis, tem de se certificar de que estão prontos para a preparação.
Se os seus dados forem tendenciosos ou contiverem valores em falta ou erróneos, isto afeta a qualidade do modelo. Tenha em atenção o seguinte antes de começar a preparar o modelo.
Saiba mais.
Impeça a fuga de dados e a discrepância entre a preparação e a publicação
A fuga de dados ocorre quando usa funcionalidades de entrada durante a preparação que "deixam escapar" informações sobre o destino que está a tentar prever e que não estão disponíveis quando o modelo é realmente publicado. Isto pode ser detetado quando uma funcionalidade altamente correlacionada com a coluna de destino é incluída como uma das funcionalidades de entrada. Por exemplo, se estiver a criar um modelo para prever se um cliente vai inscrever-se numa subscrição no próximo mês e uma das funcionalidades de entrada for um pagamento de subscrição futuro desse cliente. Isto pode levar a um forte desempenho do modelo durante os testes, mas não quando implementado em produção, uma vez que as informações de pagamento de subscrições futuras não estão disponíveis no momento da publicação.
A discrepância entre a preparação e a publicação ocorre quando as funcionalidades de entrada usadas durante a preparação são diferentes das fornecidas ao modelo no momento da publicação, o que resulta numa má qualidade do modelo em produção. Por exemplo, criar um modelo para prever as temperaturas de hora em hora, mas prepará-lo com dados que apenas contêm as temperaturas semanais. Outro exemplo: fornecer sempre as notas de um aluno nos dados de preparação quando prevê a desistência do aluno, mas não fornecer estas informações no momento da publicação.
Compreender os seus dados de preparação é importante para evitar a fuga de dados e a divergência entre a preparação e a publicação:
- Antes de usar quaisquer dados, certifique-se de que sabe o que significam e se deve ou não usá-los como uma funcionalidade
- Verifique a correlação no separador Treinar. As correlações elevadas devem ser sinalizadas para revisão.
- Divergência entre preparação e publicação: certifique-se de que só fornece funcionalidades de entrada ao modelo que estão disponíveis exatamente da mesma forma no momento da publicação.
Limpe dados em falta, incompletos e inconsistentes
É comum ter valores em falta e incorretos nos seus dados de exemplo. Dedique tempo a rever e, quando possível, melhorar a qualidade dos seus dados antes de os usar para preparação. Quanto mais valores em falta, menos úteis serão os seus dados para preparar um modelo de aprendizagem automática.
- Verifique se existem valores em falta nos dados e corrija-os, se possível, ou deixe o valor em branco se a coluna estiver definida como anulável. O Vertex AI pode processar valores em falta, mas é mais provável que obtenha resultados ideais se todos os valores estiverem disponíveis.
- Para a previsão, verifique se o intervalo entre as linhas de dados de preparação é consistente. O Vertex AI pode imputar valores em falta, mas é mais provável que obtenha resultados ideais se todas as linhas estiverem disponíveis.
- Limpe os seus dados corrigindo ou eliminando erros ou ruído nos dados. Torne os seus dados consistentes: Reveja a ortografia, as abreviaturas e a formatação.
Analise os seus dados após a importação
O Vertex AI oferece uma vista geral do seu conjunto de dados após a importação. Reveja o conjunto de dados importado para se certificar de que cada coluna tem o tipo de variável correto. O Vertex AI deteta automaticamente o tipo de variável com base nos valores das colunas, mas é melhor rever cada um. Também deve rever a capacidade de aceitar valores nulos de cada coluna, que determina se uma coluna pode ter valores em falta ou NULL.
Prepare o modelo
Depois de importar o conjunto de dados, o passo seguinte é preparar um modelo. O Vertex AI gera um modelo de aprendizagem automática fiável com as predefinições de preparação, mas pode querer ajustar alguns dos parâmetros com base no seu exemplo de utilização.
Tente selecionar o maior número possível de colunas de funcionalidades para a preparação, mas reveja cada uma para se certificar de que é adequada para a preparação. Tenha em atenção o seguinte para a seleção de funcionalidades:
- Não selecione colunas de atributos que criem ruído, como colunas de identificadores atribuídos aleatoriamente com um valor único para cada linha.
- Certifique-se de que compreende cada coluna de caraterísticas e os respetivos valores.
- Se estiver a criar vários modelos a partir de um conjunto de dados, remova as colunas de destino que não fazem parte do problema de inferência atual.
- Recorde os princípios de equidade: está a preparar o seu modelo com uma funcionalidade que possa levar a uma tomada de decisões tendenciosa ou injusta para grupos marginalizados?
Como o Vertex AI usa o seu conjunto de dados
O seu conjunto de dados é dividido em conjuntos de preparação, validação e testes. A divisão predefinida que o Vertex AI aplica depende do tipo de modelo que está a preparar. Também pode especificar as divisões (divisões manuais) se
for necessário. Para mais informações, consulte o artigo Acerca das divisões de dados para modelos do AutoML.
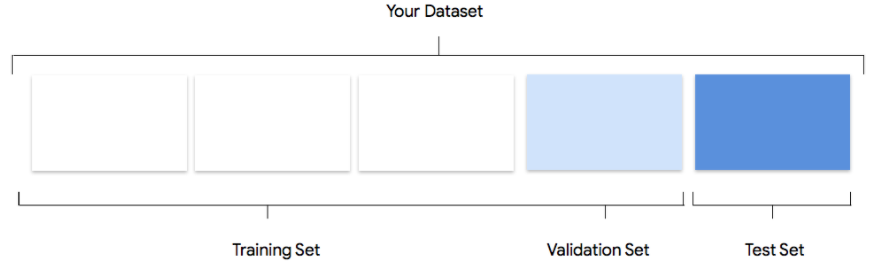
Conjunto de preparação
 A grande maioria dos seus dados deve estar no conjunto de preparação. Estes são os dados que o modelo "vê" durante o treino: são usados para aprender os parâmetros do modelo, nomeadamente os pesos das ligações entre os nós da rede neural.
A grande maioria dos seus dados deve estar no conjunto de preparação. Estes são os dados que o modelo "vê" durante o treino: são usados para aprender os parâmetros do modelo, nomeadamente os pesos das ligações entre os nós da rede neural.
Conjunto de validação
 O conjunto de validação, por vezes também denominado conjunto "dev", também é usado durante o processo de preparação.
Depois de a estrutura de aprendizagem do modelo incorporar dados de preparação durante cada iteração do processo de preparação, usa o desempenho do modelo no conjunto de validação para ajustar os hiperparâmetros do modelo, que são variáveis que especificam a estrutura do modelo. Se tentou usar o conjunto de preparação para ajustar os hiperparâmetros, é muito provável que o modelo acabe por se concentrar demasiado nos dados de preparação e tenha dificuldade em generalizar para exemplos que não correspondam exatamente aos dados de preparação.
A utilização de um conjunto de dados algo novo para aperfeiçoar a estrutura do modelo significa que o modelo vai generalizar melhor.
O conjunto de validação, por vezes também denominado conjunto "dev", também é usado durante o processo de preparação.
Depois de a estrutura de aprendizagem do modelo incorporar dados de preparação durante cada iteração do processo de preparação, usa o desempenho do modelo no conjunto de validação para ajustar os hiperparâmetros do modelo, que são variáveis que especificam a estrutura do modelo. Se tentou usar o conjunto de preparação para ajustar os hiperparâmetros, é muito provável que o modelo acabe por se concentrar demasiado nos dados de preparação e tenha dificuldade em generalizar para exemplos que não correspondam exatamente aos dados de preparação.
A utilização de um conjunto de dados algo novo para aperfeiçoar a estrutura do modelo significa que o modelo vai generalizar melhor.
Conjunto de testes
 O conjunto de testes não está envolvido no processo de preparação. Depois de o modelo concluir a preparação, o Vertex AI usa o conjunto de testes como um desafio totalmente novo para o modelo.
O desempenho do seu modelo no conjunto de testes destina-se a dar-lhe uma ideia bastante boa de como
o seu modelo vai funcionar com dados reais.
O conjunto de testes não está envolvido no processo de preparação. Depois de o modelo concluir a preparação, o Vertex AI usa o conjunto de testes como um desafio totalmente novo para o modelo.
O desempenho do seu modelo no conjunto de testes destina-se a dar-lhe uma ideia bastante boa de como
o seu modelo vai funcionar com dados reais.
Avalie, teste e implemente o seu modelo
Avalie o modelo
 Após a preparação do modelo, recebe um resumo do respetivo desempenho. As métricas de avaliação do modelo baseiam-se no desempenho do modelo em comparação com uma fatia do seu conjunto de dados (o conjunto de dados de teste). Existem algumas métricas e conceitos importantes a considerar quando determinar se o seu modelo está pronto para ser usado com dados reais.
Após a preparação do modelo, recebe um resumo do respetivo desempenho. As métricas de avaliação do modelo baseiam-se no desempenho do modelo em comparação com uma fatia do seu conjunto de dados (o conjunto de dados de teste). Existem algumas métricas e conceitos importantes a considerar quando determinar se o seu modelo está pronto para ser usado com dados reais.
Métricas de classificação
Limite da pontuação
Considere um modelo de aprendizagem automática que preveja se um cliente vai comprar um casaco no próximo ano. Qual a certeza que o modelo tem de ter antes de prever que um determinado cliente vai comprar um casaco? Nos modelos de classificação, é atribuída uma pontuação de confiança a cada inferência, ou seja, uma avaliação numérica da certeza do modelo de que a classe prevista está correta. O limite do resultado é o número que determina quando um determinado resultado é convertido numa decisão sim ou não, ou seja, o valor no qual o seu modelo diz "sim, este resultado de confiança é suficientemente elevado para concluir que este cliente vai comprar um casaco no próximo ano.
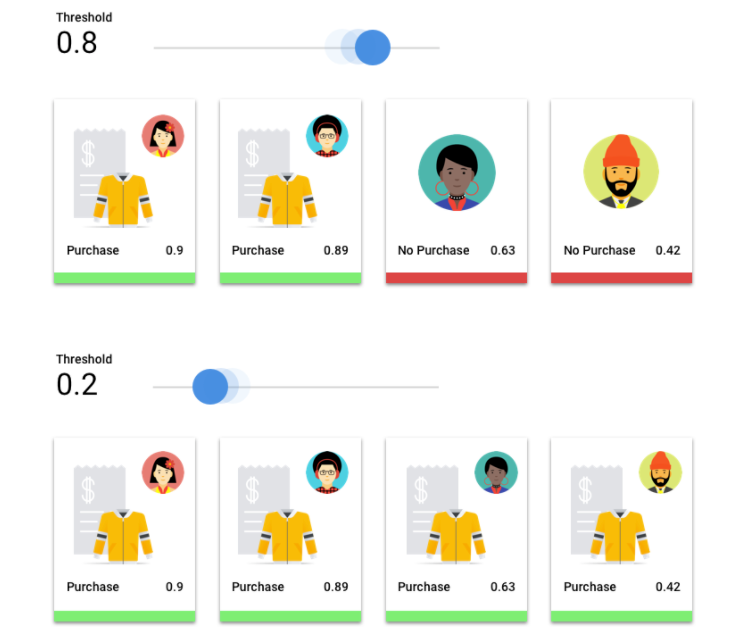
Se o limite da pontuação for baixo, o modelo corre o risco de classificação incorreta. Por esse motivo, o limite da pontuação deve basear-se num determinado exemplo de utilização.
Resultados da inferência
Depois de aplicar o limite da pontuação, as inferências feitas pelo seu modelo vão enquadrar-se numa de quatro categorias. Para compreender estas categorias, imagine novamente um modelo de classificação binária de casacos. Neste exemplo, a classe positiva (o que o modelo está a tentar prever) é que o cliente vai comprar um casaco no próximo ano.
- Verdadeiro positivo: o modelo prevê corretamente a classe positiva. O modelo previu corretamente que um cliente comprou um casaco.
- Falso positivo: o modelo prevê incorretamente a classe positiva. O modelo previu que um cliente comprou um casaco, mas não o fez.
- Negativo verdadeiro: o modelo prevê corretamente a classe negativa. O modelo previu corretamente que um cliente não comprou um casaco.
- Falso negativo: o modelo prevê incorretamente uma classe negativa. O modelo previu que um cliente não comprou um casaco, mas comprou.

Precisão e revocação
As métricas de precisão e recall ajudam a compreender o desempenho do seu modelo na captura de informações e o que está a omitir. Saiba mais sobre a precisão e a revocação.
- A precisão é a fração das inferências positivas que estavam corretas. De todas as inferências de uma compra de cliente, que fração foram compras reais?
- A recolha é a fração de linhas com esta etiqueta que o modelo previu corretamente. De todas as compras de clientes que poderiam ter sido identificadas, qual foi a fração que o foi?
Consoante o exemplo de utilização, pode ter de otimizar a precisão ou a capacidade de memorização.
Outras métricas de classificação
- AUC PR: a área abaixo da curva de precisão-revocação (PR). Este valor varia entre zero e um, em que um valor mais elevado indica um modelo de qualidade superior.
- AUC ROC: a área abaixo da curva de caraterísticas de funcionamento do recetor (ROC). Este intervalo varia de zero a um, em que um valor mais elevado indica um modelo de maior qualidade.
- Precisão: a fração de inferências de classificação produzidas pelo modelo que estavam corretas.
- Perda logarítmica: a entropia cruzada entre as inferências do modelo e os valores de destino. Este intervalo varia de zero ao infinito, em que um valor mais baixo indica um modelo de qualidade superior.
- Pontuação de F1: o meio harmónico de precisão e revocação. A pontuação F1 é uma métrica útil se estiver à procura de um equilíbrio entre a precisão e a capacidade de identificação, e existir uma distribuição desigual das classes.
Métricas de previsão e regressão
Depois de criar o modelo, o Vertex AI disponibiliza várias métricas padrão para revisão. Não existe uma resposta perfeita sobre como avaliar o seu modelo. Considere as métricas de avaliação no contexto do seu tipo de problema e o que quer alcançar com o seu modelo. A seguinte lista é uma vista geral de algumas métricas que o Vertex AI pode fornecer.
Erro absoluto médio (MAE)
O EAM é a diferença absoluta média entre os valores de destino e previstos. Mede a magnitude média dos erros, ou seja, a diferença entre um valor previsto e um valor real num conjunto de inferências. Além disso, como usa valores absolutos, o EAM não considera a direção da relação nem indica um desempenho inferior ou superior. Ao avaliar o EMA, um valor mais pequeno indica um modelo de qualidade superior (0 representa um preditor perfeito).
Raiz do erro quadrático médio (RMSE)
O RMSE é a raiz quadrada da diferença média elevada ao quadrado entre os valores alvo e previstos. O RMSE é mais sensível a valores atípicos do que o MAE, por isso, se tiver preocupações com erros grandes, o RMSE pode ser uma métrica mais útil para avaliar. Semelhante ao EMA, um valor mais pequeno indica um modelo de qualidade superior (0 representa um preditor perfeito).
Raiz do erro logarítmico quadrático médio (RMSLE)
O RMSLE é o RMSE na escala logarítmica. O RMSLE é mais sensível a erros relativos do que a erros absolutos e preocupa-se mais com o desempenho inferior do que com o desempenho superior.
Quantil observado (apenas para previsões)
Para um determinado quantil alvo, o quantil observado mostra a fração real de valores observados abaixo dos valores de inferência do quantil especificado. O quantil observado mostra a distância ou a proximidade do modelo em relação ao quantil de destino. Uma diferença menor entre os dois valores indica um modelo de qualidade superior.
Perda de pinball em escala (apenas para previsão)
Mede a qualidade de um modelo num determinado quantil alvo. Um número mais baixo indica um modelo de qualidade superior. Pode comparar a métrica de perda de pinball escalada em diferentes quantis para determinar a precisão relativa do seu modelo entre esses diferentes quantis.
Teste o seu modelo
A avaliação das métricas do modelo é a principal forma de determinar se o modelo está pronto para implementação, mas também pode testá-lo com novos dados. Carregue novos dados para ver se as inferências do modelo correspondem às suas expetativas. Com base nas métricas de avaliação ou nos testes com novos dados, pode ter de continuar a melhorar o desempenho do seu modelo.
Implemente o modelo
Quando estiver satisfeito com o desempenho do modelo, é altura de o usar. Talvez isso signifique uma utilização à escala de produção ou talvez seja um pedido de inferência único. Consoante o seu exemplo de utilização, pode usar o modelo de diferentes formas.
Inferência em lote
A inferência em lote é útil para fazer muitos pedidos de inferência em simultâneo. A inferência em lote é assíncrona, o que significa que o modelo aguarda até processar todos os pedidos de inferência antes de devolver um ficheiro CSV ou uma tabela do BigQuery com valores de inferência.
Inferência online
Implemente o seu modelo para o disponibilizar para pedidos de inferência através de uma API REST. A inferência online é síncrona (em tempo real), o que significa que devolve rapidamente uma inferência, mas só aceita um pedido de inferência por chamada da API. A inferência online é útil se o seu modelo fizer parte de uma aplicação e partes do seu sistema dependerem de um tempo de processamento rápido da inferência.
Limpar
Para ajudar a evitar cobranças indesejadas, anule a implementação do modelo quando não estiver a ser usado.
Quando terminar de usar o modelo, elimine os recursos que criou para evitar incorrer em encargos indesejados na sua conta.