Halaman ini menunjukkan cara untuk melatih model perkiraan dari set data yang berbentuk tabulasi dengan Tabular Workflow for Forecasting.
Untuk mempelajari akun layanan yang digunakan alur kerja ini, lihat Akun layanan untuk Tabular Workflows.
Jika Anda menerima error kuota saat menjalankan Tabular Workflow for Forecasting, Anda mungkin perlu meminta kuota yang lebih tinggi. Untuk mempelajari lebih lanjut, lihat Mengelola kuota untuk Tabular Workflows.
Tabular Workflow for Forecasting tidak mendukung pengeksporan model.
API Alur Kerja
Alur kerja ini menggunakan API berikut:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
Mendapatkan URI dari hasil penyesuaian hyperparameter sebelumnya
Jika sebelumnya Anda telah menyelesaikan Tabular Workflow for Forecasting yang dijalankan, Anda dapat menggunakan hasil penyesuaian hyperparameter dari proses sebelumnya untuk menghemat waktu dan resource pelatihan. Temukan hasil penyesuaian hyperparameter sebelumnya dengan menggunakan konsol Google Cloud atau dengan memuatnya secara terprogram menggunakan API.
Google Cloud console
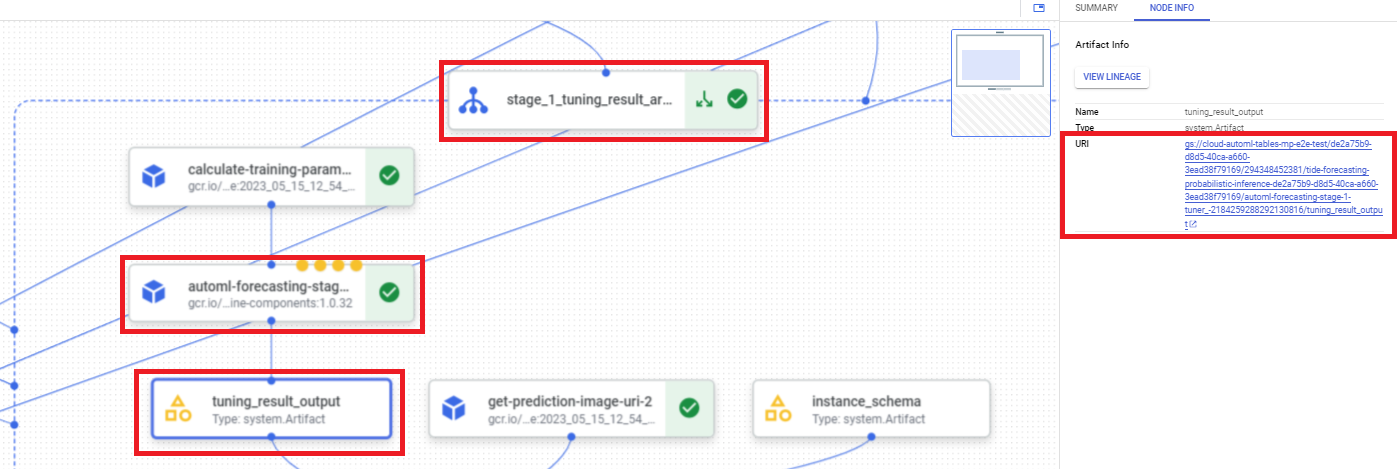
Untuk menemukan URI hasil penyesuaian hyperparameter menggunakan konsol Google Cloud , lakukan langkah-langkah berikut:
Di konsol Google Cloud , di bagian Vertex AI, buka halaman Pipelines.
Pilih tab Operasi.
Pilih operasi pipeline yang ingin Anda gunakan.
Pilih Luaskan Artefak.
Klik komponen exit-handler-1.
Klik komponen stage_1_tuning_result_artifact_uri_empty.
Cari komponen automl-forecasting-stage-1-tuner.
Klik artefak terkait tuning_result_output.
Pilih tab Info Node.
Salin URI untuk digunakan di dalam langkah Melatih model.
API: Python
Kode contoh berikut menunjukkan cara memuat hasil penyesuaian hyperparameter menggunakan API. Variabel job mengacu pada operasi pipeline
pelatihan model sebelumnya.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Melatih model
Kode contoh berikut menunjukkan cara menjalankan pipeline pelatihan model:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
Parameter service_account opsional di job.run() memungkinkan Anda menetapkan
akun layanan Vertex AI Pipelines ke akun pilihan Anda.
Vertex AI mendukung metode berikut untuk melatih model Anda:
Time series Dense Encoder (TiDE). Untuk menggunakan metode pelatihan model ini, tentukan pipeline dan nilai parameter Anda menggunakan fungsi berikut ini:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Temporal Fusion Transformer (TFT). Untuk menggunakan metode pelatihan model ini, tentukan pipeline dan nilai parameter Anda menggunakan fungsi berikut ini:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). Untuk menggunakan metode pelatihan model ini, tentukan pipeline dan nilai parameter Anda menggunakan fungsi berikut ini:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. Untuk menggunakan metode pelatihan model ini, tentukan pipeline dan nilai parameter Anda menggunakan fungsi berikut ini:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Untuk mempelajari lebih lanjut, lihat Metode pelatihan model.
Data pelatihan dapat berupa file CSV di dalam Cloud Storage, atau tabel di dalam BigQuery.
Berikut ini adalah subset parameter pelatihan model:
| Nama parameter | Jenis | Definisi |
|---|---|---|
optimization_objective |
String | Secara default, Vertex AI meminimalkan error akar rata-rata kuadrat (RMSE). Jika Anda menginginkan tujuan pengoptimalan yang berbeda untuk model perkiraan, pilih salah satu opsi di Tujuan pengoptimalan untuk model perkiraan. Jika Anda memilih untuk meminimalkan kerugian kuantil, Anda juga harus menentukan nilai untuk quantiles. |
enable_probabilistic_inference |
Boolean | Jika ditetapkan ke true, Vertex AI akan memodelkan distribusi probabilitas perkiraan. Inferensi probabilistik dapat meningkatkan kualitas model dengan menangani data yang tidak akurat dan mengukur ketidakpastian. Jika quantiles ditentukan, Vertex AI juga akan menampilkan kuantil distribusi. Inferensi probabilistik hanya kompatibel dengan metode pelatihan Time series Dense Encoder (TiDE) dan AutoML (L2L). Inferensi probabilistik tidak kompatibel dengan tujuan pengoptimalan minimize-quantile-loss. |
quantiles |
List[float] | Kuantil yang akan digunakan untuk minimize-quantile-loss tujuan pengoptimalan dan inferensi probabilistik. Berikan daftar hingga lima angka unik antara 0 dan 1, eksklusif. |
time_column |
String | Kolom waktu. Untuk mempelajari lebih lanjut, lihat Persyaratan struktur data. |
time_series_identifier_columns |
List[str] | Kolom ID deret waktu. Untuk mempelajari lebih lanjut, lihat Persyaratan struktur data. |
weight_column |
String | (Opsional) Kolom bobot. Untuk mempelajari lebih lanjut, lihat Menambahkan bobot ke data pelatihan Anda. |
time_series_attribute_columns |
List[str] | (Opsional) Nama atau nama kolom yang merupakan atribut deret waktu. Untuk mempelajari lebih lanjut, lihat Jenis dan ketersediaan fitur pada perkiraan. |
available_at_forecast_columns |
List[str] | (Opsional) Nama atau nama kolom kovariat yang nilainya diketahui pada waktu perkiraan. Untuk mempelajari lebih lanjut, lihat Jenis dan ketersediaan fitur pada perkiraan. |
unavailable_at_forecast_columns |
List[str] | (Opsional) Nama atau nama kolom kovariat yang nilainya tidak diketahui pada waktu perkiraan. Untuk mempelajari lebih lanjut, lihat Jenis dan ketersediaan fitur pada perkiraan. |
forecast_horizon |
Bilangan bulat | (Opsional) Horizon perkiraan menentukan seberapa jauh model memperkirakan nilai target untuk setiap baris data inferensi di masa mendatang. Untuk mempelajari lebih lanjut, lihat Horizon perkiraan, periode konteks, dan periode perkiraan. |
context_window |
Bilangan bulat | (Opsional) Periode konteks akan menyetel seberapa jauh modelnya terlihat selama pelatihan (dan untuk perkiraan). Dengan kata lain, untuk setiap titik data pelatihan, periode konteks menentukan seberapa jauh model mencari pola prediktif. Untuk mempelajari lebih lanjut, lihat Horizon perkiraan, periode konteks, dan periode perkiraan. |
window_max_count |
Bilangan Bulat | (Opsional) Vertex AI menghasilkan periode perkiraan dari data input menggunakan strategi periode yang berjalan terus-menerus. Strategi defaultnya adalah Count. Nilai default untuk jumlah maksimum periode tersebut adalah 100,000,000. Tetapkan parameter ini untuk memberikan nilai kustom untuk jumlah maksimum periode. Untuk mempelajari lebih lanjut, lihat Strategi periode yang berjalan terus-menerus. |
window_stride_length |
Bilangan Bulat | (Opsional) Vertex AI menghasilkan periode perkiraan dari data input menggunakan strategi periode yang berjalan terus-menerus. Untuk memilih strategi Stride, tetapkan parameter ini ke nilai panjang langkah. Untuk mempelajari lebih lanjut, lihat Strategi periode yang berjalan terus-menerus. |
window_predefined_column |
String | (Opsional) Vertex AI menghasilkan periode perkiraan dari data input menggunakan strategi periode yang berjalan terus-menerus. Untuk memilih strategi Column, tetapkan parameter ini ke nama kolom yang memiliki nilai True, atau False. Untuk mempelajari lebih lanjut, lihat Strategi periode yang berjalan terus-menerus. |
holiday_regions |
List[str] | (Opsional) Anda dapat memilih satu atau beberapa wilayah geografis untuk mengaktifkan pemodelan efek hari libur. Selama pelatihan, Vertex AI membuat fitur kategori liburan dalam model berdasarkan tanggal dari time_column dan wilayah geografis yang ditentukan. Secara default, pemodelan efek liburan dinonaktifkan. Untuk mempelajari lebih lanjut, lihat Wilayah liburan. |
predefined_split_key |
String | (Opsional) Secara default, Vertex AI menggunakan algoritma pemisahan secara kronologis untuk memisahkan data perkiraan menjadi tiga data yang terpisah. Jika Anda ingin mengontrol baris data pelatihan yang akan digunakan untuk pemisahan yang dituju, masukkan nama kolom yang berisi nilai pemisahan data (TRAIN, VALIDATION, TEST). Untuk mempelajari lebih lanjut, lihat Pemisahan data untuk perkiraan. |
training_fraction |
Float | (Opsional) Secara default, Vertex AI menggunakan algoritma pemisahan secara kronologis untuk memisahkan data perkiraan menjadi tiga data yang terpisah. 80% data ditetapkan ke set pelatihan, 10% ditetapkan ke pemisahan validasi, dan 10% ditetapkan ke pemisahan pengujian. Tetapkan parameter ini jika Anda ingin menyesuaikan jumlah data yang ditetapkan ke set pelatihan tersebut. Untuk mempelajari lebih lanjut, lihat Pemisahan data untuk perkiraan. |
validation_fraction |
Float | (Opsional) Secara default, Vertex AI menggunakan algoritma pemisahan secara kronologis untuk memisahkan data perkiraan menjadi tiga data yang terpisah. 80% data ditetapkan ke set pelatihan, 10% ditetapkan ke pemisahan validasi, dan 10% ditetapkan ke pemisahan pengujian. Tetapkan parameter ini jika Anda ingin menyesuaikan jumlah data yang ditetapkan ke set pelatihan tersebut. Untuk mempelajari lebih lanjut, lihat Pemisahan data untuk perkiraan. |
test_fraction |
Float | (Opsional) Secara default, Vertex AI menggunakan algoritma pemisahan secara kronologis untuk memisahkan data perkiraan menjadi tiga data yang terpisah. 80% data ditetapkan ke set pelatihan, 10% ditetapkan ke pemisahan validasi, dan 10% ditetapkan ke pemisahan pengujian. Tetapkan parameter ini jika Anda ingin menyesuaikan jumlah data yang ditetapkan ke set pelatihan tersebut. Untuk mempelajari lebih lanjut, lihat Pemisahan data untuk perkiraan. |
data_source_csv_filenames |
String | URI untuk CSV yang disimpan di Cloud Storage. |
data_source_bigquery_table_path |
String | URI untuk tabel BigQuery. |
dataflow_service_account |
String | (Opsional) Akun layanan kustom untuk menjalankan tugas Dataflow. Anda dapat mengonfigurasi tugas Dataflow untuk menggunakan IP pribadi dan subnet VPC tertentu. Parameter ini berfungsi sebagai pengganti untuk akun layanan worker Dataflow default. |
run_evaluation |
Boolean | Jika ditetapkan ke True, Vertex AI akan mengevaluasi model ansambel pada pemisahan pengujian. |
evaluated_examples_bigquery_path |
String | Jalur set data BigQuery yang digunakan selama evaluasi model. Set data berfungsi sebagai tujuan untuk contoh yang diprediksi. Anda harus menetapkan nilai parameter jika run_evaluation ditetapkan ke True, dan harus memiliki format berikut: bq://[PROJECT].[DATASET]. |
Transformations
Anda dapat memberikan pemetaan kamus resolusi otomatis atau resolusi jenis untuk kolom kolom. Jenis yang didukung adalah: otomatis, numerik, kategoris, teks, dan stempel waktu.
| Nama parameter | Jenis | Definisi |
|---|---|---|
transformations |
Dict[str, List[str]] | Pemetaan kamus untuk resolusi otomatis, atau jenis |
Kode berikut ini menyediakan fungsi bantuan untuk mengisi parameter
transformations. Contoh ini juga menunjukkan cara menggunakan fungsi ini untuk menerapkan transformasi
otomatis ke dalam kumpulan kolom yang telah ditentukan oleh variabel features.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
Untuk mempelajari transformasi lebih lanjut, lihat Jenis dan transformasi data.
Opsi penyesuaian alur kerja
Anda dapat menyesuaikan Tabular Workflow for Forecasting dengan menentukan nilai argumen yang diteruskan selama definisi pipeline. Anda dapat menyesuaikan alur kerja Anda dengan cara berikut ini:
- Mengonfigurasi hardware
- Melewati penelusuran arsitektur
Mengonfigurasi hardware
Parameter pelatihan model berikut memungkinkan Anda untuk mengonfigurasi jenis mesin dan jumlah mesin yang akan dilatih. Opsi ini adalah pilihan yang tepat jika Anda memiliki set data yang besar, dan ingin mengoptimalkan hardware mesin.
| Nama parameter | Jenis | Definisi |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (Opsional) Konfigurasi kustom jenis mesin, dan jumlah mesin untuk pelatihan. Parameter ini mengonfigurasi komponen automl-forecasting-stage-1-tuner dari pipeline tersebut. |
Kode berikut menunjukkan cara menetapkan jenis mesin n1-standard-8 untuk
node utama TensorFlow dan jenis mesin n1-standard-4 untuk
node evaluator TensorFlow:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Melewati penelusuran arsitektur
Parameter pelatihan model berikut memungkinkan Anda menjalankan pipeline tanpa penelusuran arsitektur dan menyediakan sekumpulan hyperparameter dari operasi pipeline sebelumnya.
| Nama parameter | Jenis | Definisi |
|---|---|---|
stage_1_tuning_result_artifact_uri |
String | (Opsional) URI hasil penyesuaian hyperparameter dari operasi pipeline sebelumnya. |
Langkah berikutnya
- Pelajari inferensi batch untuk model perkiraan.
- Mempelajari harga untuk pelatihan model.