Auf dieser Seite lesen Sie, wie Sie mit dem tabellarischen Workflow für Prognosen ein Prognosemodell aus einem tabellarischen Dataset trainieren.
Weitere Informationen zu den von diesem Workflow verwendeten Dienstkonten finden Sie unter Dienstkonten für tabellarische Workflows.
Wenn Sie beim Ausführen eines tabellarischen Workflows für Prognosen einen Kontingentfehler erhalten, müssen Sie möglicherweise ein höheres Kontingent anfordern. Weitere Informationen finden Sie unter Kontingente für tabellarische Workflows verwalten.
Der Modellexport wird im tabellarischen Workflow für Prognosen nicht unterstützt.
Workflow-APIs
Dieser Workflow verwendet folgende APIs:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
URI des vorherigen Hyperparameter-Feinabstimmungsergebnisses abrufen
Wenn Sie bereits einen tabellarischen Workflow für Prognosen ausgeführt haben, können Sie das Ergebnis der Hyperparameter-Feinabstimmung aus der vorherigen Ausführung verwenden, um Trainingszeit und Ressourcen zu sparen. Sie können das Ergebnis der vorherigen Hyperparameter-Abstimmung über die Google Cloud -Konsole abrufen oder es programmatisch mit der API laden.
Google Cloud Console
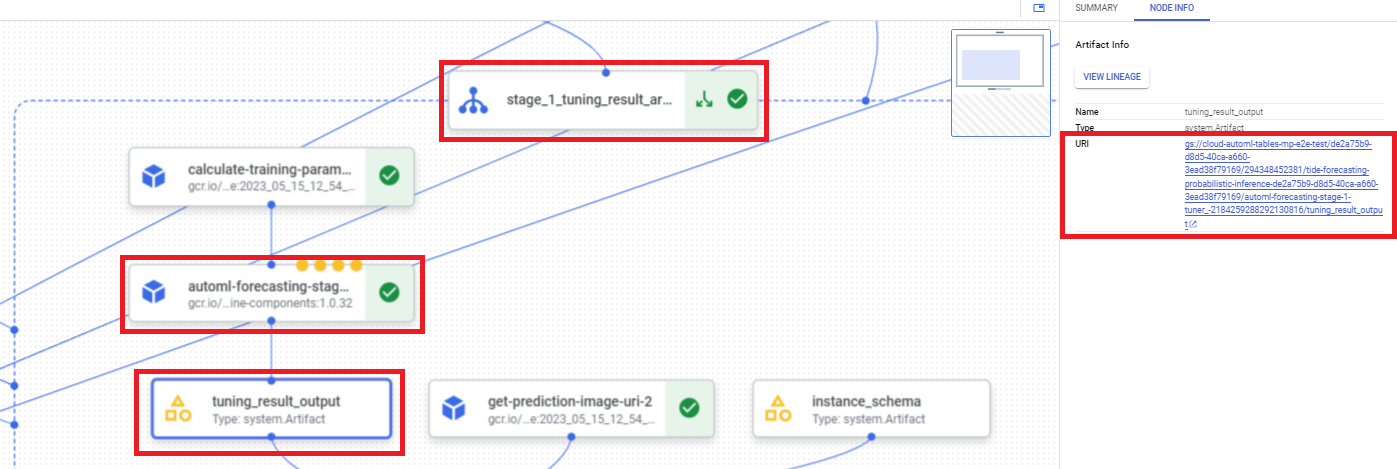
Führen Sie die folgenden Schritte aus, um den URI des Ergebnisses der Hyperparameter-Abstimmung mit der Google Cloud Console zu finden:
Rufen Sie in der Google Cloud Console im Abschnitt „Vertex AI“ die Seite Pipelines auf.
Wählen Sie den Tab Ausführungen aus.
Wählen Sie die Pipelineausführung aus, die Sie verwenden möchten.
Wählen Sie Artefakte maximieren aus.
Klicken Sie auf die Komponente exit-handler-1.
Klicken Sie auf die Komponente stage_1_tuning_result_artifact_uri_empty.
Suchen Sie die Komponente automl-forecasting-stage-1-tuner.
Klicken Sie auf das zugehörige Artefakt tuning_result_output.
Wählen Sie den Tab Knoteninformationen aus.
Kopieren Sie den URI zur Verwendung im Schritt Modell trainieren.
API: Python
Der folgende Beispielcode zeigt, wie Sie das Ergebnis der Hyperparameter-Abstimmung mit der API laden. Die Variable job bezieht sich auf die vorherige Ausführung der Modelltrainings-Pipeline.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Modell trainieren
Der folgende Beispielcode zeigt, wie eine Modelltrainings-Pipeline ausgeführt werden kann:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
Mit dem optionalen Parameter service_account in job.run() können Sie das Vertex AI Pipelines-Dienstkonto auf ein Konto Ihrer Wahl festlegen.
Vertex AI unterstützt die folgenden Methoden zum Trainieren Ihres Modells:
Time series Dense Encoder (TiDE) Um diese Modelltrainingsmethode zu verwenden, definieren Sie Ihre Pipeline und Parameterwerte mit der folgenden Funktion:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Temporal Fusion Transformer (TFT) Um diese Modelltrainingsmethode zu verwenden, definieren Sie Ihre Pipeline und Parameterwerte mit der folgenden Funktion:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). Um diese Modelltrainingsmethode zu verwenden, definieren Sie Ihre Pipeline und Parameterwerte mit der folgenden Funktion:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. Um diese Modelltrainingsmethode zu verwenden, definieren Sie Ihre Pipeline und Parameterwerte mit der folgenden Funktion:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Weitere Informationen finden Sie unter Methoden für das Modelltraining.
Die Trainingsdaten können entweder eine CSV-Datei in Cloud Storage oder eine Tabelle in BigQuery sein.
Im Folgenden finden Sie einige der Parameter für das Modelltraining:
| Parametername | Typ | Definition |
|---|---|---|
optimization_objective |
String | Standardmäßig minimiert Vertex AI die Wurzel der mittleren Fehlerquadratsumme (Root Mean Squared Error, RMSE). Wenn Sie ein anderes Optimierungsziel für Ihr Prognosemodell benötigen, wählen Sie eine der Optionen unter Optimierungsziele für Prognosemodelle aus. Wenn Sie den Quantilverlust minimieren möchten, müssen Sie auch einen Wert für quantiles angeben. |
enable_probabilistic_inference |
Boolesch | Wenn der Wert auf true gesetzt ist, modelliert Vertex AI die Wahrscheinlichkeitsverteilung der Prognose. Die probabilistische Inferenz kann die Modellqualität verbessern, indem ungenaue Daten verarbeitet und Unsicherheiten quantifiziert werden. Wenn quantiles angegeben sind, gibt Vertex AI auch die Quantile der Wahrscheinlichkeitsverteilung zurück. Die probabilistische Inferenz ist nur mit den Zeitachsen für Dense Encoder (TiDE) und AutoML (L2L) kompatibel. Die probabilistische Inferenz ist nicht mit dem Optimierungsziel minimize-quantile-loss kompatibel. |
quantiles |
List[float] | Quantile für das minimize-quantile-loss-Optimierungsziel und die probabilistische Inferenz. Geben Sie eine Liste mit bis zu fünf eindeutigen Zahlen zwischen 0 und 1 an. |
time_column |
String | Spalte "Time" (Zeit). Weitere Informationen finden Sie unter Anforderungen an die Datenstruktur. |
time_series_identifier_columns |
List[str] | Spalten für Zeitreihenkennzeichnungen. Weitere Informationen finden Sie unter Anforderungen an die Datenstruktur. |
weight_column |
String | (Optional) Die Gewichtungsspalte. Weitere Informationen finden Sie unter Trainingsdaten Gewichtungen hinzufügen. |
time_series_attribute_columns |
List[str] | (Optional) Der Name oder die Namen der Spalten, die Zeitreihenattribute sind. Weitere Informationen finden Sie unter Featuretyp und Verfügbarkeit bei Prognose. |
available_at_forecast_columns |
List[str] | (Optional) Der Name oder die Namen der kovariativen Spalten, deren Wert zum Zeitpunkt der Prognose bekannt ist. Weitere Informationen finden Sie unter Featuretyp und Verfügbarkeit bei Prognose. |
unavailable_at_forecast_columns |
List[str] | (Optional) Der Name oder die Namen der kovariativen Spalten, deren Wert zum Zeitpunkt der Prognose unbekannt ist. Weitere Informationen finden Sie unter Featuretyp und Verfügbarkeit bei Prognose. |
forecast_horizon |
Ganzzahl | (Optional) Der Prognosezeitraum bestimmt, wie weit das Modell den Zielwert für jede Zeile mit Inferenzdaten prognostiziert. Weitere Informationen finden Sie unter Prognosezeitraum, Kontextfenster und Prognosefenster. |
context_window |
Ganzzahl | (Optional) Das Kontextfenster legt fest, wie weit das Modell während des Trainings (und für Prognosen) zurückblickt. Mit anderen Worten: Für jeden Trainingsdatenpunkt bestimmt das Kontextfenster, wie weit das Modell nach Vorhersagemustern sucht. Weitere Informationen finden Sie unter Prognosezeitraum, Kontextfenster und Prognosefenster. |
window_max_count |
Ganzzahl | (Optional) Vertex AI generiert anhand einer Strategie mit rollierenden Zeitfenstern Prognosefenster aus den Eingabedaten. Die Standardstrategie ist Anzahl. Der Standardwert für die maximale Anzahl an Zeitfenstern ist 100,000,000. Legen Sie diesen Parameter fest, um einen benutzerdefinierten Wert für die maximale Anzahl an Fenstern anzugeben. Weitere Informationen finden Sie unter Strategien mit rollierenden Zeitfenstern. |
window_stride_length |
Ganzzahl | (Optional) Vertex AI generiert anhand einer Strategie mit rollierenden Zeitfenstern Prognosefenster aus den Eingabedaten. Zum Auswählen der Strategie Schritt legen Sie für diesen Parameter den Wert der Schrittlänge fest. Weitere Informationen finden Sie unter Strategien mit rollierenden Zeitfenstern. |
window_predefined_column |
String | (Optional) Vertex AI generiert anhand einer Strategie mit rollierenden Zeitfenstern Prognosefenster aus den Eingabedaten. Zum Auswählen der Strategie Spalte legen Sie für diesen Parameter den Namen der Spalte mit True- oder False-Werten fest. Weitere Informationen finden Sie unter Strategien mit rollierenden Zeitfenstern. |
holiday_regions |
List[str] | : (Optional) Sie können eine oder mehrere geografische Regionen auswählen, um die Effektmodellierung für Feiertage zu aktivieren. Während des Trainings erstellt Vertex AI innerhalb des Modells kategoriale Features basierend auf dem Datum aus time_column und den angegebenen geografischen Regionen. Standardmäßig ist die Effektmodellierung deaktiviert. Weitere Informationen finden Sie unter Feiertagsregionen. |
predefined_split_key |
String | (Optional) Standardmäßig verwendet Vertex AI einen chronologischen Aufteilungsalgorithmus, um Ihre Prognosedaten in die drei Datenaufteilungen zu unterteilen. Wenn Sie steuern möchten, welche Trainingsdatenzeilen für welche Aufteilung verwendet werden, geben Sie den Namen der Spalte an, die die Datenaufteilungswerte enthält (TRAIN, VALIDATION, TEST). Weitere Informationen finden Sie unter Datenaufteilungen für Prognosen. |
training_fraction |
Float | (Optional) Standardmäßig verwendet Vertex AI einen chronologischen Aufteilungsalgorithmus, um Ihre Prognosedaten in die drei Datenaufteilungen zu unterteilen. 80 % der Daten werden dem Trainings-Dataset, 10 % der Validierungsaufteilung und 10 % der Testaufteilung zugewiesen. Legen Sie diesen Parameter fest, wenn Sie den Anteil der Daten anpassen möchten, der dem Trainings-Dataset zugewiesen wird. Weitere Informationen finden Sie unter Datenaufteilungen für Prognosen. |
validation_fraction |
Float | (Optional) Standardmäßig verwendet Vertex AI einen chronologischen Aufteilungsalgorithmus, um Ihre Prognosedaten in die drei Datenaufteilungen zu unterteilen. 80 % der Daten werden dem Trainings-Dataset, 10 % der Validierungsaufteilung und 10 % der Testaufteilung zugewiesen. Legen Sie diesen Parameter fest, wenn Sie den Anteil der Daten anpassen möchten, der dem Validierungs-Dataset zugewiesen wird. Weitere Informationen finden Sie unter Datenaufteilungen für Prognosen. |
test_fraction |
Float | (Optional) Standardmäßig verwendet Vertex AI einen chronologischen Aufteilungsalgorithmus, um Ihre Prognosedaten in die drei Datenaufteilungen zu unterteilen. 80 % der Daten werden dem Trainings-Dataset, 10 % der Validierungsaufteilung und 10 % der Testaufteilung zugewiesen. Legen Sie diesen Parameter fest, wenn Sie den Anteil der Daten anpassen möchten, der dem Test-Dataset zugewiesen wird. Weitere Informationen finden Sie unter Datenaufteilungen für Prognosen. |
data_source_csv_filenames |
String | Ein URI für eine in Cloud Storage gespeicherte CSV-Datei. |
data_source_bigquery_table_path |
String | Ein URI für eine BigQuery-Tabelle. |
dataflow_service_account |
String | (Optional) Benutzerdefiniertes Dienstkonto zum Ausführen von Dataflow-Jobs. Sie können den Dataflow-Job so konfigurieren, dass private IP-Adressen und ein bestimmtes VPC-Subnetz verwendet werden. Dieser Parameter dient als Überschreibung für das Standarddienstkonto des Dataflow-Workers. |
run_evaluation |
Boolesch | Wenn der Wert auf True gesetzt ist, bewertet Vertex AI das erstellte Modell anhand der Testaufteilung. |
evaluated_examples_bigquery_path |
String | Der Pfad des BigQuery-Datasets, das bei der Modellbewertung verwendet wird. Das Dataset dient als Ziel für die vorhergesagten Beispiele. Sie müssen den Parameterwert festlegen, wenn run_evaluation auf True festgelegt ist. Er muss das folgende Format haben: bq://[PROJECT].[DATASET]. |
Transformationen
Sie können Featurespalten eine Wörterbuchzuordnung von auto- oder type-Auflösungen zuordnen. Folgende Typen werden unterstützt: „auto“, „numeric“, „categorical“, „text“ und „timestamp“.
| Parametername | Typ | Definition |
|---|---|---|
transformations |
Dict[str, List[str]] | Wörterbuchzuordnung von auto- oder type-Auflösungen |
Der folgende Code enthält eine Hilfsfunktion zum Ausfüllen des Parameters transformations. Er zeigt auch, wie Sie mit dieser Funktion automatische Transformationen auf einen Satz Spalten anwenden können, die durch eine features-Variable definiert werden.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
Weitere Informationen zu Transformationen finden Sie unter Datentypen und Transformationen.
Optionen zur Workflow-Anpassung
Sie können den tabellarischen Workflow für Prognosen anpassen, indem Sie Argumentwerte definieren, die während der Pipelinedefinition übergeben werden. Sie können Ihren Workflow so anpassen:
- Hardware konfigurieren
- Architektursuche überspringen
Hardware konfigurieren
Mit dem folgenden Parameter für das Modelltraining können Sie die Maschinentypen und die Anzahl der Maschinen für das Training konfigurieren. Diese Option ist eine gute Wahl, wenn Sie ein großes Dataset haben und die Hardware der Maschine entsprechend optimieren möchten.
| Parametername | Typ | Definition |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (Optional) Benutzerdefinierte Konfiguration der Maschinentypen und der Anzahl der Maschinen für das Training. Mit diesem Parameter wird die automl-forecasting-stage-1-tuner-Komponente der Pipeline konfiguriert. |
Der folgende Code zeigt, wie Sie den Maschinentyp n1-standard-8 für den TensorFlow-Hauptknoten und den Maschinentyp n1-standard-4 für den TensorFlow-Bewertungsknoten festlegen:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Architektursuche überspringen
Mit dem folgenden Modelltrainingsparameter können Sie die Pipeline ohne die Architektursuche ausführen und stattdessen eine Reihe von Hyperparametern aus einer vorherigen Pipelineausführung bereitstellen.
| Parametername | Typ | Definition |
|---|---|---|
stage_1_tuning_result_artifact_uri |
String | (Optional) URI des Ergebnisses der Hyperparameter-Abstimmung aus einer vorherigen Pipelineausführung. |
Nächste Schritte
- Batchinferenzen für Prognosemodelle
- Preise für das Modelltraining