Este documento apresenta uma visão geral do pipeline e componentes de AutoML End-to-End. Para saber como treinar um modelo com o AutoML End-to-End, consulte Treinar um modelo com o AutoML End-to-End.
O fluxo de trabalho tabular para o AutoML de ponta a ponta é um pipeline completo do AutoML para tarefas de classificação e regressão. Ele é semelhante à API AutoML, mas permite que você escolha o que controlar e o que automatizar. Em vez de ter controles para o pipeline inteiro, você tem controles para cada etapa no pipeline. Esses controles de pipeline incluem o seguinte:
- Divisão de dados
- Engenharia de atributos
- Pesquisa de arquitetura
- Treinamento de modelo
- Conjunto de modelos
- Destilação de modelo
Vantagens
Confira alguns dos benefícios do fluxo de trabalho tabular para o AutoML de ponta a ponta :
- Suporta grandes conjuntos de dados com vários TB de tamanho e até 1.000 colunas.
- Permite melhorar a estabilidade e reduzir o tempo de treinamento limitando o espaço de pesquisa de tipos de arquitetura ou pulando a pesquisa de arquitetura.
- Permite melhorar a velocidade do treinamento selecionando manualmente o hardware usado para pesquisa de treinamento e arquitetura.
- Permite reduzir o tamanho do modelo e melhorar a latência com destilação ou mudando o tamanho do ensemble.
- Cada componente do AutoML pode ser inspecionado em uma ótima interface de gráfico de pipelines que permite ver as tabelas de dados transformadas, as arquiteturas de modelos avaliadas e muitos outros detalhes.
- Os componentes do AutoML têm mais flexibilidade e transparência, como personalização de parâmetros, hardware, status do processo de visualização, registros e muito mais.
End to End AutoML no Vertex AI Pipelines
O fluxo de trabalho tabular para o AutoML End-to-End é uma instância gerenciada do Vertex AI Pipelines.
O Vertex AI Pipelines é um serviço sem servidor que executa pipelines do Kubeflow. É possível usar pipelines para automatizar e monitorar suas tarefas de machine learning e de preparação de dados. Cada etapa em um pipeline executa parte do fluxo de trabalho do pipeline. Por exemplo, um pipeline pode incluir etapas para dividir dados, transformar tipos de dados e treinar um modelo. Como as etapas são instâncias de componentes do pipeline, as etapas têm entradas, saídas e uma imagem de contêiner. As entradas de etapa podem ser definidas nas entradas do pipeline ou elas podem depender da saída de outras etapas dentro do pipeline. Essas dependências definem o fluxo de trabalho do pipeline como um gráfico acíclico dirigido.
Visão geral do pipeline e dos componentes
O diagrama a seguir mostra o pipeline de modelagem do Fluxo de trabalho tabular para AutoML de ponta a ponta:

Estes são os componentes do pipeline:
- feature-transform-engine: executa a engenharia de atributos. Consulte Feature Transform Engine para saber mais detalhes.
- split-materialized-data:
divida os dados materializados em um conjunto de treinamento, de avaliação e de teste.
Entrada:
- Dados materializados
materialized_data.
Saída:
- Divisão de treinamento materializada
materialized_train_split. - Divisão de avaliação materializada
materialized_eval_split. - Conjunto de teste materializado
materialized_test_split.
- Dados materializados
- merge-materialized-splits: mescla a divisão de avaliação materializada e a divisão de treinamento materializado.
automl-tabular-stage-1-tuner: realiza a pesquisa de arquitetura de modelo e ajusta hiperparâmetros.
- Uma arquitetura é definida por um conjunto de hiperparâmetros.
- Os hiperparâmetros incluem o tipo de modelo e os parâmetros do modelo.
- Os tipos de modelo considerados são redes neurais e árvores aprimoradas.
- O sistema treina um modelo para cada arquitetura considerada.
automl-tabular-cv-trainer: valida arquiteturas cruzadas treinando modelos em diferentes dobras dos dados de entrada.
- As arquiteturas consideradas são aquelas que fornecem os melhores resultados na etapa anterior.
- O sistema seleciona aproximadamente dez melhores arquiteturas. O número exato é definido pelo orçamento de treinamento.
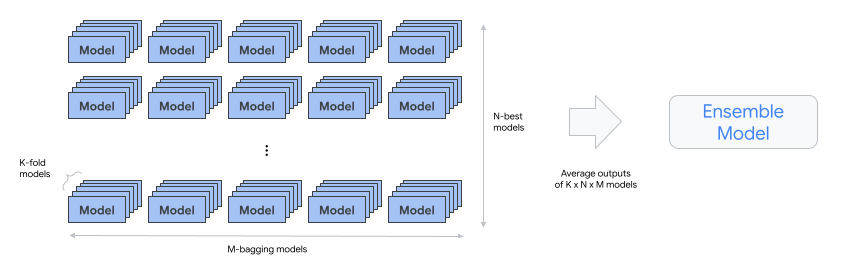
automl-tabular-ensemble: combina as melhores arquiteturas para produzir um modelo final.
- O diagrama a seguir ilustra a validação cruzada do K-fold com bagging:
condition-is-distill: opcional. Cria uma versão menor do modelo de conjunto.
- Um modelo menor reduz a latência e o custo da inferência.
automl-tabular-infra-validator: valida se o modelo treinado é válido.
model-upload: faz o upload do modelo.
condition-is-evaluation: opcional. Usa o conjunto de teste para calcular métricas de avaliação.