本文档简要介绍端到端 AutoML 流水线和组件。如需了解如何使用端到端 AutoML 训练模型,请参阅使用端到端 AutoML 训练模型。
端到端 AutoML 的表格工作流是用于分类和回归任务的完整 AutoML 流水线。它与 AutoML API 类似,但允许您选择要控制的内容及自动化的内容。您可以控制流水线中的每个步骤,而不是控制整个流水线。这些流水线控制包括:
- 数据拆分
- 特征工程
- 架构搜索
- 模型训练
- 模型集成学习
- 模型提炼
优势
以下列出了用于端到端 AutoML 表格工作流的一些优势:
- 支持大小超过 1 TB 且最多包含 1,000 列的大型数据集。
- 使您能够通过限制架构类型的搜索空间或跳过架构搜索来提高稳定性并缩短训练时间。
- 允许您通过手动选择用于训练和架构搜索的硬件来提高训练速度。
- 允许您通过精馏或更改集成学习规模来缩减模型规模并缩短延迟时间。
- 每个 AutoML 组件都可以在强大的流水线图界面中进行检查,使您可以查看转换后的数据表、评估的模型架构以及更多详细信息。
- 每个 AutoML 组件都可提供更高的灵活性和透明度,例如能够自定义参数、硬件,查看进程状态、日志等。
Vertex AI Pipelines 上的端到端 AutoML
端到端 AutoML 表格工作流是 Vertex AI Pipelines 的代管式实例。
Vertex AI Pipelines 是一种用于运行 Kubeflow 流水线的无服务器服务。您可以使用流水线来自动执行及监控机器学习和数据准备任务。流水线中的每个步骤都会执行流水线工作流的一部分。例如,一个流水线可以包含用于拆分数据、转换数据类型和训练模型的各个步骤。由于步骤是流水线组件的实例,因此步骤中包含输入、输出和容器映像。步骤输入可根据流水线的输入进行设置,也可以依赖于此流水线中其他步骤的输出。这些依赖项将流水线的工作流定义为有向非循环图。
流水线和组件概览
下图显示了端到端 AutoML 的表格工作流的建模流水线:

流水线组件包括:
- feature-transform-engine:执行特征工程。如需了解详情,请参阅 Feature Transform Engine。
- split-materialized-data:将具体化数据拆分为训练集、评估集和测试集。
输入:
- 具体化数据
materialized_data。
输出:
- 具体化训练拆分
materialized_train_split。 - 具体化评估拆分
materialized_eval_split。 - 具体化测试集
materialized_test_split。
- 具体化数据
- merge-materialized-splits - 合并具体化评估拆分和具体化训练拆分。
automl-tabular-stage-1-tuner - 执行模型架构搜索和调整超参数。
- 架构由一组超参数定义。
- 超参数包括模型类型和模型参数。
- 考虑的模型类型是神经网络和提升树。
- 系统会针对考虑的每个架构训练一个模型。
automl-tabular-cv-trainer - 通过在输入数据的不同折上训练模型来交叉验证架构。
- 考虑的架构是上一步中提供最佳结果的架构。
- 系统会选择大约 10 个最佳架构。确切的数量由训练预算定义。
automl-tabular-ensemble - 集成最佳架构来生成最终模型。
- 下图展示了带 bagging 的 K 折交叉验证:
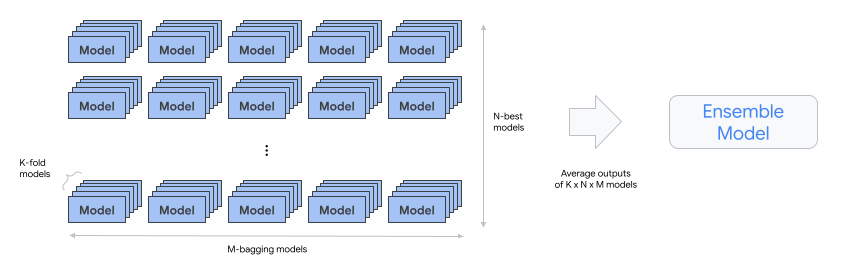
condition-is-distill - 可选。创建较小版本的集成模型。
- 模型越小,推理的延迟时间和费用就越低。
automl-tabular-infra-validator - 验证经过训练的模型是否为有效模型。
model-upload - 上传模型。
condition-is-evaluation - 可选。使用测试集计算评估指标。