Halaman ini menunjukkan cara membuat perkiraan menggunakan model perkiraan terlatih Anda.
Untuk membuat perkiraan, buat permintaan inferensi batch secara langsung ke model perkiraan. Tentukan sumber input dan lokasi output untuk menyimpan hasil perkiraan.
Perkiraan dengan AutoML tidak kompatibel dengan deployment endpoint atau inferensi online. Untuk meminta inferensi online dari model perkiraan, gunakan Tabular Workflow untuk Perkiraan.
Anda dapat meminta inferensi dengan penjelasan (juga disebut atribusi fitur) untuk melihat bagaimana model Anda menghasilkan inferensi. Nilai kepentingan fitur lokal menunjukkan seberapa besar kontribusi setiap fitur terhadap hasil inferensi. Untuk ringkasan konseptual, lihat Atribusi fitur untuk perkiraan.
Sebelum memulai
Sebelum dapat membuat perkiraan, latih model perkiraan. Untuk mengetahui informasi selengkapnya, lihat Melatih model perkiraan.
Data input
Data input untuk permintaan inferensi batch adalah data yang digunakan model Anda untuk membuat perkiraan. Anda dapat memberikan data input dalam salah satu dari dua format:
- Objek CSV di Cloud Storage
- Tabel BigQuery
Sebaiknya gunakan format data input yang sama seperti yang digunakan untuk melatih model. Misalnya, jika Anda melatih model menggunakan data di BigQuery, sebaiknya gunakan tabel BigQuery sebagai input untuk inferensi batch Anda. Karena Vertex AI memperlakukan semua kolom input CSV sebagai string, menggabungkan format data input dan pelatihan dapat menyebabkan error.
Sumber data Anda harus berisi data tabulasi yang menyertakan semua kolom, dalam urutan apa pun, yang digunakan untuk melatih model. Anda dapat menyertakan kolom yang tidak ada dalam data pelatihan, atau yang ada dalam data pelatihan, tetapi tidak digunakan dalam pelatihan. Kolom tambahan ini disertakan dalam output, tetapi tidak memengaruhi hasil perkiraan.
Persyaratan data input
Input untuk model perkiraan harus mematuhi persyaratan berikut:
- Semua nilai dalam kolom waktu harus ada dan valid.
- Semua kolom yang digunakan dalam permintaan inferensi harus ada dalam data input. Jika kolom kosong atau tidak ada, Vertex AI akan melakukan padding data secara otomatis.
- Frekuensi data untuk data input dan data pelatihan harus cocok. Jika ada baris yang hilang dalam deret waktu, Anda harus memasukkannya secara manual sesuai dengan pengetahuan domain yang tepat.
- Deret waktu dengan stempel waktu duplikat akan dihapus dari inferensi. Untuk menyertakannya, hapus stempel waktu duplikat.
- Berikan data historis untuk setiap deret waktu yang akan diperkirakan. Untuk perkiraan yang paling akurat, jumlah data harus sama dengan jendela konteks, yang ditetapkan selama pelatihan model. Misalnya, jika periode konteksnya adalah 14 hari, berikan data historis setidaknya selama 14 hari. Jika Anda memberikan lebih sedikit data, Vertex AI akan melakukan padding data tersebut dengan nilai kosong.
- Perkiraan dimulai pada baris pertama dari deret waktu (diurutkan berdasarkan waktu)
dengan nilai null di kolom target. Nilai null harus berkelanjutan
dalam deret waktu. Misalnya, jika kolom target diurutkan berdasarkan
waktu, Anda tidak boleh memiliki urutan seperti
1,2,null,3,4,null,nulluntuk satu deret waktu. Untuk file CSV, Vertex AI memperlakukan string kosong sebagai null, dan untuk BigQuery, nilai null didukung secara native.
Tabel BigQuery
Jika memilih Tabel BigQuery sebagai input, Anda harus memastikan hal-hal berikut:
- Tabel sumber data BigQuery tidak boleh berukuran lebih dari 100 GB.
- Jika tabel berada dalam project lain, Anda harus memberikan
peran
BigQuery Data Editorke akun layanan Vertex AI dalam project tersebut.
File CSV
Jika memilih objek CSV di Cloud Storage sebagai input, Anda harus memastikan hal-hal berikut:
- Sumber data harus dimulai pada baris header dengan nama kolom.
- Setiap objek sumber data tidak boleh berukuran lebih dari 10 GB. Anda dapat menyertakan beberapa file, dengan total ukuran maksimum 100 GB.
- Jika bucket Cloud Storage berada di project lain, Anda harus memberikan
peran
Storage Object Creatorke akun layanan Vertex AI dalam project tersebut. - Anda harus menyertakan semua string dalam tanda kutip ganda (").
Format output
Format output permintaan inferensi batch Anda tidak harus sama dengan format input. Misalnya, jika menggunakan tabel BigQuery sebagai input, Anda dapat menampilkan hasil perkiraan ke objek CSV di Cloud Storage.
Membuat permintaan inferensi batch ke model Anda
Untuk membuat permintaan inferensi batch, Anda dapat menggunakan konsol Google Cloud atau Vertex AI API. Sumber data input dapat berupa objek CSV yang disimpan di bucket Cloud Storage atau Tabel BigQuery. Bergantung pada jumlah data yang Anda kirimkan sebagai input, tugas inferensi batch dapat memerlukan waktu beberapa saat untuk diselesaikan.
Google Cloud console
Gunakan konsol Google Cloud untuk meminta inferensi batch.
- Di konsol Google Cloud , di bagian Vertex AI, buka halaman Inferensi batch.
- Klik Buat untuk membuka jendela Inferensi batch baru.
- Di bagian Tentukan inferensi batch Anda, selesaikan langkah-langkah berikut:
- Masukkan nama untuk inferensi batch.
- Untuk Nama model, pilih nama model yang akan digunakan untuk inferensi batch ini.
- Untuk Versi, pilih versi model.
- Untuk Pilih sumber, pilih apakah data input sumber Anda berupa file CSV
di Cloud Storage atau tabel di BigQuery.
- Untuk file CSV, tentukan lokasi Cloud Storage tempat file input CSV Anda berada.
- Untuk tabel BigQuery, tentukan project ID tempat tabel berada, ID set data BigQuery, dan tabel BigQuery atau ID tampilan.
- Untuk Output inferensi batch, pilih CSV atau BigQuery.
- Untuk CSV, tentukan bucket Cloud Storage tempat Vertex AI menyimpan output Anda.
- Untuk BigQuery, Anda dapat menentukan project ID atau set data
yang sudah ada:
- Untuk menentukan project ID, masukkan project ID di kolom project ID Google Cloud. Vertex AI membuat set data output baru untuk Anda.
- Untuk menentukan set data yang ada, masukkan jalur BigQuery-nya
di kolom project ID Google Cloud, seperti
bq://projectid.datasetid.
- Opsional. Jika tujuan output Anda adalah BigQuery atau JSONL di Cloud Storage, Anda dapat mengaktifkan atribusi fitur selain inferensi. Untuk melakukannya, pilih Aktifkan atribusi fitur untuk model ini. Atribusi fitur tidak didukung untuk CSV di Cloud Storage. Pelajari lebih lanjut.
- Opsional: Analisis Pemantauan Model
untuk inferensi batch tersedia di Pratinjau. Lihat
Prasyarat
untuk menambahkan konfigurasi deteksi skew ke tugas inferensi
batch Anda.
- Klik untuk mengaktifkan Enable model monitoring for this batch inference.
- Pilih Sumber data pelatihan. Masukkan jalur data atau lokasi untuk sumber data pelatihan yang Anda pilih.
- Opsional: Di bagian Nilai minimum pemberitahuan, tentukan nilai minimum untuk memicu pemberitahuan.
- Di bagian Email notifikasi, masukkan satu atau beberapa alamat email, dengan dipisahkan koma, yang akan menerima pemberitahuan saat model melebihi nilai minimum pemberitahuan.
- Opsional: Di bagian Saluran notifikasi, tambahkan saluran Cloud Monitoring untuk menerima pemberitahuan saat model melebihi nilai minimum pemberitahuan. Anda dapat memilih saluran Cloud Monitoring yang sudah ada atau membuat yang baru dengan mengklik Kelola saluran notifikasi. Konsol mendukung saluran notifikasi PagerDuty, Slack, dan Pub/Sub.
- Klik Buat.
API : BigQuery
REST
Anda menggunakan metode batchPredictionJobs.create untuk meminta inferensi batch.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- LOCATION_ID: Region tempat Model disimpan dan tugas inferensi batch dijalankan. Misalnya,
us-central1. - PROJECT_ID: Project ID Anda
- BATCH_JOB_NAME: Nama tampilan untuk tugas batch
- MODEL_ID: ID yang digunakan oleh model untuk membuat inferensi
-
INPUT_URI: Referensi ke sumber data BigQuery. Di dalam formulir:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: Referensi ke tujuan BigQuery (tempat
inferensi ditulis). Tentukan project ID dan, secara opsional,
ID set data yang ada. Gunakan formulir berikut:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: Nilai defaultnya adalah salah. Tetapkan ke benar untuk mengaktifkan atribusi fitur. Untuk mempelajari lebih lanjut, lihat Atribusi fitur untuk perkiraan.
Metode HTTP dan URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Isi JSON permintaan:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Anda akan menerima respons JSON yang mirip dengan yang berikut ini:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di panduan memulai Vertex AI menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi API Java Vertex AI.
Untuk melakukan autentikasi ke Vertex AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Pada contoh berikut, ganti INSTANCES_FORMAT dan PREDICTIONS_FORMAT dengan `bigquery`. Untuk mempelajari cara mengganti placeholder lain, lihat tab `REST & CMD LINE` di bagian ini.Python
Untuk mempelajari cara menginstal atau mengupdate Vertex AI SDK untuk Python, lihat Menginstal Vertex AI SDK untuk Python. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi API Python.
API: Cloud Storage
REST
Anda menggunakan metode batchPredictionJobs.create untuk meminta inferensi batch.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- LOCATION_ID: Region tempat Model disimpan dan tugas inferensi batch dijalankan. Misalnya,
us-central1. - PROJECT_ID:
- BATCH_JOB_NAME: Nama tampilan untuk tugas batch
- MODEL_ID: ID yang digunakan oleh model untuk membuat inferensi
-
URI: Jalur (URI) ke bucket Cloud Storage yang berisi data pelatihan.
Bisa lebih dari satu. Setiap URI memiliki format:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: Jalur ke tujuan Cloud Storage tempat
inferensi akan ditulis. Vertex AI menulis inferensi batch ke subdirektori dengan
stempel waktu dari jalur ini. Tetapkan nilai ini ke string dengan format berikut:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: Nilai defaultnya adalah salah. Tetapkan ke benar untuk mengaktifkan atribusi fitur. Opsi ini hanya tersedia jika tujuan output Anda adalah JSONL. Atribusi fitur tidak didukung untuk CSV di Cloud Storage. Untuk mempelajari lebih lanjut, lihat Atribusi fitur untuk perkiraan.
Metode HTTP dan URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Isi JSON permintaan:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
Untuk mempelajari cara menginstal atau mengupdate Vertex AI SDK untuk Python, lihat Menginstal Vertex AI SDK untuk Python. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi API Python.
Mengambil hasil inferensi batch
Vertex AI mengirim output inferensi batch ke tujuan yang Anda tentukan. Tujuan ini dapat berupa BigQuery atau Cloud Storage.
Output Cloud Storage untuk atribusi fitur tidak didukung.
BigQuery
Set data output
Jika Anda menggunakan BigQuery, output inferensi batch disimpan dalam set data output. Jika Anda telah menyediakan set data ke Vertex AI, nama set data (BQ_DATASET_NAME) adalah nama yang telah Anda berikan sebelumnya. Jika Anda tidak menyediakan set data output, Vertex AI akan membuatnya untuk Anda. Anda dapat menemukan namanya (BQ_DATASET_NAME) dengan langkah-langkah berikut:
- Di konsol Google Cloud , buka halaman Inferensi batch Vertex AI.
- Pilih inferensi yang Anda buat.
-
Set data output diberikan di Lokasi ekspor. Nama set data
diformat sebagai berikut:
prediction_MODEL_NAME_TIMESTAMP
Tabel output
Set data output berisi satu atau beberapa dari tiga tabel output berikut:
-
Tabel inferensi
Tabel ini berisi baris untuk setiap baris dalam data input Anda, tempat inferensi diminta (yaitu, dengan TARGET_COLUMN_NAME = null). Misalnya, jika input Anda menyertakan 14 entri null untuk kolom target (seperti penjualan selama 14 hari ke depan), permintaan inferensi Anda akan menampilkan 14 baris, yaitu jumlah penjualan untuk setiap hari. Jika permintaan inferensi Anda melebihi periode perkiraan model, Vertex AI hanya akan menampilkan inferensi hingga ke periode perkiraan.
-
Tabel validasi error
Tabel ini berisi baris untuk setiap error non-kritis yang ditemukan selama fase penggabungan yang terjadi sebelum inferensi batch. Setiap error non-kritis berkaitan dengan baris dalam data input yang perkiraannya tidak dapat ditampilkan oleh Vertex AI.
-
Tabel error
Tabel ini berisi baris untuk setiap error non-kritis yang ditemukan selama inferensi batch. Setiap error non-kritis berkaitan dengan baris dalam data input yang perkiraannya tidak dapat ditampilkan oleh Vertex AI.
Tabel prediksi
Nama tabel (BQ_PREDICTIONS_TABLE_NAME) dibuat dengan
menambahkan `predictions_` dengan stempel waktu saat tugas inferensi batch
dimulai: predictions_TIMESTAMP
Untuk mengambil tabel inferensi:
-
Di konsol, buka halaman BigQuery.
Buka BigQuery -
Jalankan kueri berikut:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI menyimpan inferensi di kolom predicted_TARGET_COLUMN_NAME.value.
Jika Anda melatih model
dengan Temporal Fusion Transformer (TFT), Anda dapat menemukan output penafsiran TFT di kolom
predicted_TARGET_COLUMN_NAME.tft_feature_importance.
Kolom ini dibagi lagi menjadi:
context_columns: Fitur perkiraan yang nilai jendela konteks-nya berfungsi sebagai input ke Encoder TFT Long Short-Term Memory (LSTM).context_weights: Bobot nilai penting fitur yang terkait dengan setiapcontext_columnsuntuk instance yang diprediksi.horizon_columns: Fitur perkiraan yang nilai horizon perkiraannya berfungsi sebagai input untuk Decoder TFT Long Short-Term Memory (LSTM).horizon_weights: Bobot nilai penting fitur yang terkait dengan setiaphorizon_columnsuntuk instance yang diprediksi.attribute_columns: Fitur perkiraan yang merupakan invarian waktu.attribute_weights: Bobot yang terkait dengan masing-masing dariattribute_columns.
Jika model Anda
dioptimalkan untuk kerugian kuantil dan kumpulan kuantil Anda menyertakan median,
predicted_TARGET_COLUMN_NAME.value adalah nilai inferensi pada
median. Jika tidak, predicted_TARGET_COLUMN_NAME.value adalah
nilai inferensi pada kuantil terendah dalam kumpulan. Misalnya, jika kumpulan kuantil Anda
adalah [0.1, 0.5, 0.9], value adalah inferensi untuk kuantil 0.5.
Jika kumpulan kuantil Anda adalah [0.1, 0.9], value adalah inferensi untuk
kuantil 0.1.
Selain itu, Vertex AI menyimpan nilai kuantil dan inferensi di kolom berikut:
-
predicted_TARGET_COLUMN_NAME.quantile_values: Nilai kuantil, yang ditetapkan selama pelatihan model. Misalnya, nilai ini dapat berupa0.1,0.5, dan0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: Nilai inferensi yang terkait dengan nilai kuantil.
Jika model Anda menggunakan inferensi probabilistik,
predicted_TARGET_COLUMN_NAME.value berisi minimizer
tujuan pengoptimalan. Misalnya, jika tujuan pengoptimalan Anda adalah minimize-rmse,
predicted_TARGET_COLUMN_NAME.value berisi nilai rata-rata. Jika
minimize-mae, predicted_TARGET_COLUMN_NAME.value
berisi nilai median.
Jika model Anda menggunakan inferensi probabilistik dengan kuantil, Vertex AI akan menyimpan nilai kuantil dan inferensi dalam kolom berikut:
-
predicted_TARGET_COLUMN_NAME.quantile_values: Nilai kuantil, yang ditetapkan selama pelatihan model. Misalnya, nilai ini dapat berupa0.1,0.5, dan0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: Nilai inferensi yang terkait dengan nilai kuantil.
Jika mengaktifkan atribusi fitur, Anda juga dapat menemukannya di tabel inferensi. Agar dapat mengakses atribusi untuk fitur BQ_FEATURE_NAME, jalankan kueri berikut:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Untuk mempelajari lebih lanjut, lihat Atribusi fitur untuk perkiraan.
Tabel validasi error
Nama tabel (BQ_ERRORS_VALIDATION_TABLE_NAME)
dibuat dengan menambahkan `errors_validation` dengan stempel waktu saat
tugas inferensi batch dimulai: errors_validation_TIMESTAMP
-
Di konsol, buka halaman BigQuery.
Buka BigQuery -
Jalankan kueri berikut:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
Tabel error
Nama tabel (BQ_ERRORS_TABLE_NAME) dibuat dengan
menambahkan `errors_` dengan stempel waktu saat tugas inferensi batch
dimulai: errors_TIMESTAMP
-
Di konsol, buka halaman BigQuery.
Buka BigQuery -
Jalankan kueri berikut:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Jika Anda menentukan Cloud Storage sebagai tujuan output, hasil permintaan inferensi batch akan ditampilkan sebagai objek CSV di folder baru dalam bucket yang Anda tentukan. Nama folder adalah nama model Anda, yang diawali dengan "prediction-" dan ditambah dengan stempel waktu saat tugas inferensi batch dimulai. Anda dapat menemukan nama folder Cloud Storage di tab Prediksi batch untuk model Anda.
Folder Cloud Storage berisi dua jenis objek:-
Objek inferensi
Objek inferensi diberi nama `predictions_1.csv`, `predictions_2.csv`, dan seterusnya. Objek tersebut berisi baris header dengan nama kolom, dan baris untuk setiap perkiraan yang ditampilkan. Jumlah nilai inferensi bergantung pada input inferensi dan periode perkiraan Anda. Misalnya, jika input Anda menyertakan 14 entri null untuk kolom target (seperti penjualan selama 14 hari ke depan), permintaan inferensi Anda akan menampilkan 14 baris, yaitu jumlah penjualan untuk setiap hari. Jika permintaan inferensi Anda melebihi periode perkiraan model, Vertex AI hanya akan menampilkan inferensi hingga ke periode perkiraan.
Nilai perkiraan ditampilkan dalam kolom bernama `predicted_TARGET_COLUMN_NAME`. Untuk perkiraan kuantil, kolom output berisi inferensi kuantil dan nilai kuantil dalam format JSON.
-
Objek error
Objek yang berisi error tersebut diberi nama `errors_1.csv`, `errors_2.csv`, dan seterusnya. Objek ini berisi baris header, dan satu baris untuk setiap baris dalam data input Anda yang perkiraannya tidak dapat ditampilkan oleh Vertex AI (misalnya, jika fitur non-nullable bernilai null).
Catatan: Jika hasilnya besar, hasil akan dibagi menjadi beberapa objek.
Contoh kueri atribusi fitur di BigQuery
Contoh 1: Menentukan atribusi untuk satu inferensi
Misalnya, untuk pertanyaan berikut:
Seberapa besar iklan untuk sebuah produk meningkatkan prediksi penjualan pada 24 November di toko tertentu?
Kueri yang sesuai adalah sebagai berikut:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
Contoh 2: Menentukan nilai penting fitur global
Misalnya, untuk pertanyaan berikut:
Berapa besar kontribusi setiap fitur terhadap prediksi penjualan secara keseluruhan?
Anda dapat menghitung nilai penting fitur global secara manual dengan menggabungkan atribusi nilai penting fitur lokal. Kueri yang sesuai adalah sebagai berikut:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
Contoh output inferensi batch di BigQuery
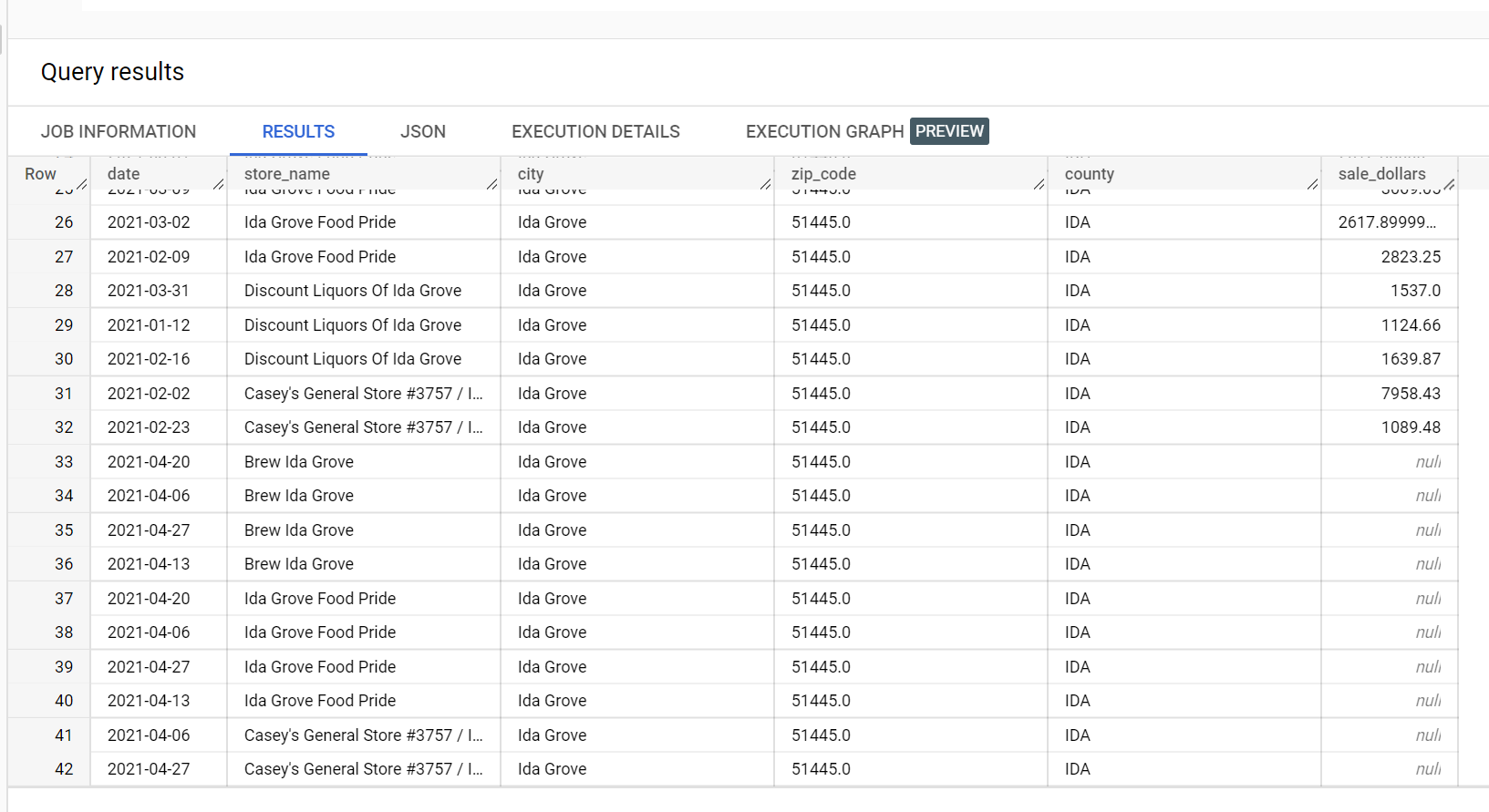
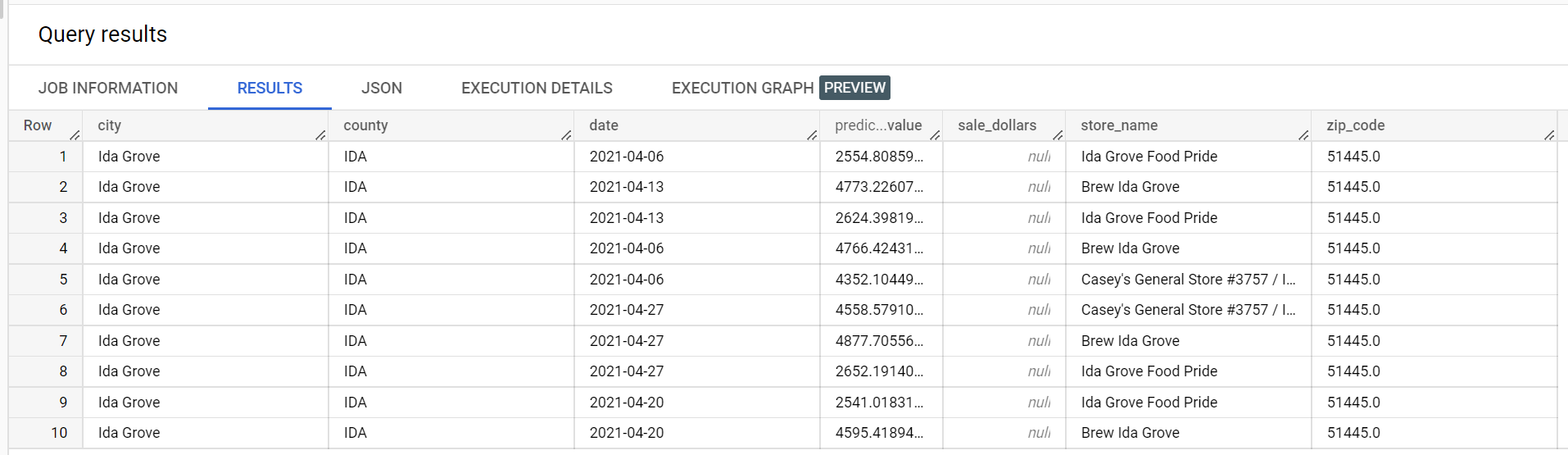
Dalam contoh set data penjualan minuman keras, ada empat toko di kota
"Ida Grove": "Ida Grove Food Pride", "Discount Liquors of Ida Grove",
"Casey's General Store #3757", dan "Brew Ida Grove". store_name adalah
series identifier dan tiga dari empat toko meminta inferensi untuk
kolom target sale_dollars. Error validasi dibuat karena
tidak ada perkiraan yang diminta untuk "Discount Liquors of Ida Grove".
Berikut ini adalah cuplikan dari set data input yang digunakan untuk inferensi:
Berikut adalah cuplikan dari hasil inferensi:
Berikut ini adalah cuplikan dari error validasi:

Contoh output inferensi batch untuk model yang dioptimalkan untuk pengurangan kuantil
Contoh berikut adalah output inferensi batch untuk model yang dioptimalkan untuk pengurangan kuantil. Dalam skenario ini, model perkiraan memprediksi penjualan selama 14 hari ke depan untuk setiap toko.
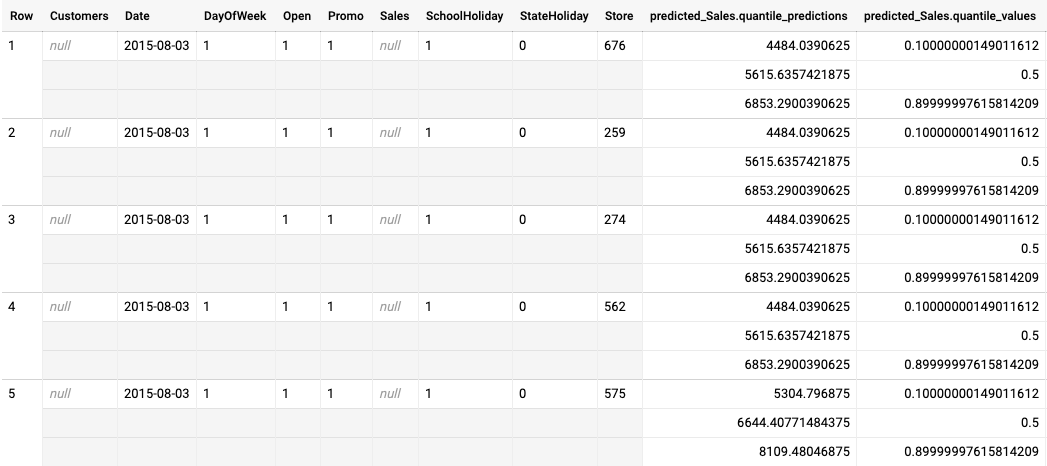
Nilai kuantil diberikan dalam kolom predicted_Sales.quantile_values. Dalam
contoh ini, model memprediksi nilai pada kuantil 0.1, 0.5, dan
0.9.
Nilai inferensi diberikan di kolom predicted_Sales.quantile_predictions.
Ini adalah array nilai penjualan, yang dipetakan ke nilai kuantil di
kolom predicted_Sales.quantile_values. Di baris pertama, kita melihat bahwa probabilitas nilai penjualan lebih rendah dari 4484.04 adalah 10%. Probabilitas nilai penjualan
lebih rendah dari 5615.64 adalah 50%. Probabilitas nilai penjualan lebih rendah dari
6853.29 adalah 90%. Inferensi untuk baris pertama, yang ditampilkan sebagai satu nilai, adalah
5615.64.