데이터 세트를 사용하여 AutoML 모델을 학습시킬 때 Vertex AI는 데이터를 학습 분할, 검증 분할, 테스트 분할의 3가지 분할로 나눕니다. 데이터 분할을 만들 때의 핵심 목표는 테스트 세트가 프로덕션 데이터를 정확하게 나타내는지 확인하는 것입니다. 이렇게 해야 평가 측정항목을 통해 모델이 실제 데이터에서 어떤 성능을 보일지 정확하게 판단할 수 있습니다.
이 페이지에서는 Vertex AI가 AutoML 모델을 학습시키기 위해 데이터의 학습, 검증, 테스트 세트를 사용하는 방법을 설명합니다. 또한 이 세 가지 세트 간에 데이터가 분할되는 방식을 제어하는 방법도 설명합니다. 분류 및 회귀를 위한 데이터 분할 알고리즘은 예측을 위한 데이터 분할 알고리즘과 다릅니다.
분류와 회귀를 위한 데이터 분할
데이터 분할 사용 방법
데이터 분할은 다음과 같은 학습 프로세스에 사용됩니다.
모델 무료 체험
학습 세트는 다양한 사전 처리, 아키텍처, 초매개변수 옵션 조합으로 모델을 학습시키는 데 사용됩니다. Vertex AI는 품질 검증 세트로 이러한 모델을 평가하며 이를 통해 추가 옵션 조합을 살펴볼 수 있습니다. 검증 세트는 학습 중 주기적인 평가에서 가장 좋은 체크포인트를 선택하는 데도 사용됩니다. Vertex AI는 병렬 조정 단계에서 결정된 최적의 매개변수와 아키텍처를 사용하여 아래에 설명된 두 앙상블 모델을 학습시킵니다.
모델 평가
Vertex AI는 학습 및 검증 세트를 학습 데이터로 사용하여 평가 모델을 학습시킵니다. Vertex AI는 테스트 세트를 사용하여 이 모델에 대한 최종 모델 평가 측정항목을 생성합니다. 테스트 세트는 전체 과정 중 이 시점에서 처음으로 사용되며, 이 접근 방식을 사용하면 최종 평가 측정항목이 최종 학습된 모델을 프로덕션 단계에 배포했을 때의 성능을 편향 없이 반영할 수 있습니다.
서빙 모델
Vertex AI는 학습, 검증, 테스트 세트로 모델을 학습시켜 학습 데이터 양을 극대화합니다. 이 모델을 사용하여 온라인 예측 또는 일괄 예측을 요청합니다.
기본 데이터 분할
기본적으로 Vertex AI는 무작위 분할 알고리즘을 사용하여 데이터를 3개의 데이터 분할로 구분합니다. Vertex AI는 학습 데이터 세트의 80%를 학습 세트로, 10%를 검증 세트로, 10%를 테스트 세트로 무작위 선택합니다. 다음과 같은 데이터 세트에 기본 분할을 사용하는 것이 좋습니다.
- 시간이 지나도 변하지 않습니다.
- 상대적으로 균형이 잡혀 있습니다.
- 프로덕션에서 예측에 사용되는 데이터와 같이 분산됩니다.
기본 데이터 분할을 사용하려면 Google Cloud 콘솔에서 기본값을 수락하거나 API의 split 필드를 비워 둡니다.
데이터 분할 제어 옵션
다음 접근 방법 중 하나를 사용해 어떤 분할에 어떤 열을 선택할지 제어할 수 있습니다.
- 무작위 분할: 분할 비율을 설정하고 데이터 행을 무작위로 할당합니다.
- 수동 분할: 데이터 분할 열에서 학습, 검증, 테스트에 사용할 특정 행을 선택합니다.
- 시간순 분할: 시간 열에서 데이터를 시간별로 분할합니다.
위의 옵션 중 하나만 선택할 수 있으며, 모델을 학습시킬 때 선택하게 됩니다. 이러한 옵션 중 일부에서는 학습 데이터를 변경해야 합니다 (예를 들어 데이터 분할 열 또는 시간 열). 데이터 분할 옵션을 사용하기 위해 이들 옵션을 위한 데이터를 포함할 필요는 없습니다. 즉, 모델을 학습시킬 때 여전히 다른 옵션을 선택할 수 있습니다.
다음과 같은 경우 기본 분할이 최선의 선택은 아닙니다.
예측 모델을 학습시키고 있지 않지만 데이터는 시간에 민감합니다.
이때는 시간순 분할을 사용하거나, 수동 분할을 사용해 가장 최근 데이터가 테스트 세트로 사용되도록 해야 합니다.
테스트 데이터에 프로덕션 단계에서는 표시되지 않는 모집단의 데이터가 있습니다.
예를 들어 여러 매장의 구매 데이터로 모델을 학습시킨다고 가정해 보겠습니다. 하지만 이 모델의 주 용도는 학습 데이터에 없는 매장에 대한 예측을 수행하는 것입니다. 모델이 입력되지 않은 매장도 일반화할 수 있도록 데이터 세트를 매장별로 분리하세요. 즉, 테스트 세트에는 검증 세트에 속하지 않는 매장만 포함해야 하며 검증 세트에는 학습 세트에 속하지 않는 매장만 포함해야 합니다.
클래스의 균형이 맞지 않습니다.
학습 데이터에 특정 클래스가 다른 클래스보다 지나치게 많다면, 테스트 데이터에 소수 범주 예시를 수동으로 추가해야 할 수도 있습니다. Vertex AI는 계층화된 샘플링을 수행하지 않으므로 테스트 세트에 소수 범주가 너무 적거나 아예 없을 수도 있습니다.
무작위 분할
무작위 분할을 '수학적 분할' 또는 '비율 분할'이라고도 합니다.
기본적으로 학습, 검증, 테스트 세트에 사용되는 학습 데이터의 비율은 각각 80, 10, 10입니다. Google Cloud 콘솔을 사용하는 경우 합이 최대 100이 되는 모든 값으로 비율을 변경할 수 있습니다. Vertex AI API를 사용하는 경우 합이 최대 1.0이 되는 분수를 사용합니다.
비율 (백분율)을 변경하려면 FractionSplit 객체를 사용하여 비율을 정의하세요.
Vertex AI는 데이터 분할의 행을 무작위로, 하지만 확정적으로 선택합니다. 생성된 데이터 분할 구성이 마음에 들지 않는다면 수동 분할을 이용하거나 학습 데이터를 변경하세요. 동일한 학습 데이터로 새 모델을 학습시켜도 동일한 데이터 분할이 생성됩니다.
수동 분할
수동 분할을 '사전 정의된 분할'이라고도 합니다.
데이터 분할 열을 사용하면 학습, 검증, 테스트에 사용할 구체적인 행을 선택할 수 있습니다. 학습 데이터를 만들 때 다음 값 중 하나 (대소문자 구분)를 포함할 수 있는 열을 추가해야 합니다.
TRAINVALIDATETESTUNASSIGNED
이 열의 값은 다음 두 조합 중 하나여야 합니다.
TRAIN,VALIDATE,TEST전체TEST와UNASSIGNED만
모든 행에 이 열의 값이 있어야 하며, 이 값은 빈 문자열일 수 없습니다.
예를 들어 모든 세트를 지정한 경우 값은 다음과 같습니다.
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
테스트 세트만 지정한 경우 값은 다음과 같습니다.
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
데이터 분할 열에 모든 유효한 열 이름을 지정할 수 있습니다. 변환 유형은 범주형, 텍스트 또는 자동일 수 있습니다.
데이터 분할 열의 값이 UNASSIGNED이면 Vertex AI는 자동으로 해당 행을 학습 또는 검증 세트에 할당합니다.
모델 학습 중에 열을 데이터 분할 열로 지정합니다.
시간순 분할
시간순 분할을 '타임스탬프 분할'이라고도 합니다.
데이터가 시간에 종속되는 경우, 열 하나를 시간 열로 지정할 수 있습니다. Vertex AI는 시간 열을 사용하여 데이터를 분할하고, 학습에 사용되는 행을 가장 먼저 표시하고, 그 다음에 검증에 사용되는 행, 테스트에 사용되는 행을 순서대로 표시합니다.
Vertex AI는 각 행을 독립적이고 동일한 분포의 학습 예시로 취급하므로, 시간 열을 설정해도 행은 변경되지 않습니다. 시간 열은 데이터 세트를 분할하는 데만 사용됩니다.
시간 열을 지정하는 경우 데이터 세트의 모든 행에 시간 열 값을 포함해야 합니다. 검증 세트와 테스트 세트가 비어 있지 않도록 시간 열에 고유 값이 충분히 있는지 확인하세요. 일반적으로 20개 이상의 고유 값이면 충분합니다.
시간 열의 데이터는 타임스탬프 변환에서 지원되는 형식 중 하나를 준수해야 합니다. 그러나 변환은 열이 학습에 사용되는 방식에만 영향을 주기 때문에 시간 열에는 지원되는 모든 변환이 있을 수 있습니다. 변환은 데이터 분할에 영향을 미치지 않습니다.
또한 각 세트에 할당되는 학습 데이터의 백분율도 지정할 수 있습니다.
모델 학습 중에 열을 시간 열로 지정합니다.
예측을 위한 데이터 분할
기본적으로 Vertex AI는 시간순 분할 알고리즘을 사용하여 예측 데이터를 데이터 분할 3개로 분리합니다. 기본 분할을 사용하는 것이 좋습니다. 그러나 어떤 분할에 어떤 학습 데이터 행을 사용할지를 제어하려면 수동 분할을 사용합니다.
데이터 분할 사용 방법
데이터 분할은 다음과 같은 학습 프로세스에 사용됩니다.
모델 무료 체험
학습 세트는 다양한 사전 처리, 아키텍처, 초매개변수 옵션 조합으로 모델을 학습시키는 데 사용됩니다. Vertex AI는 품질 검증 세트로 이러한 모델을 평가하며 이를 통해 추가 옵션 조합을 살펴볼 수 있습니다. 검증 세트는 학습 중 주기적인 평가에서 가장 좋은 체크포인트를 선택하는 데도 사용됩니다. Vertex AI는 병렬 조정 단계에서 결정된 최적의 매개변수와 아키텍처를 사용하여 아래에 설명된 두 앙상블 모델을 학습시킵니다.
모델 평가
Vertex AI는 학습 및 검증 세트를 학습 데이터로 사용하여 평가 모델을 학습시킵니다. Vertex AI는 테스트 세트를 사용하여 이 모델에 대한 최종 모델 평가 측정항목을 생성합니다. 테스트 세트는 전체 과정 중 이 시점에서 처음으로 사용되며, 이 접근 방식을 사용하면 최종 평가 측정항목이 최종 학습된 모델을 프로덕션 단계에 배포했을 때의 성능을 편향 없이 반영할 수 있습니다.
서빙 모델
Vertex AI는 학습 및 검증 세트로 모델을 학습시킵니다. 테스트 세트를 사용하여 모델을 검증합니다 (최적의 체크포인트를 선택하기 위해). 테스트 세트는 손실이 계산된다는 점에서 학습되지 않습니다. 이 모델을 사용하여 추론을 가져옵니다.
기본 분할
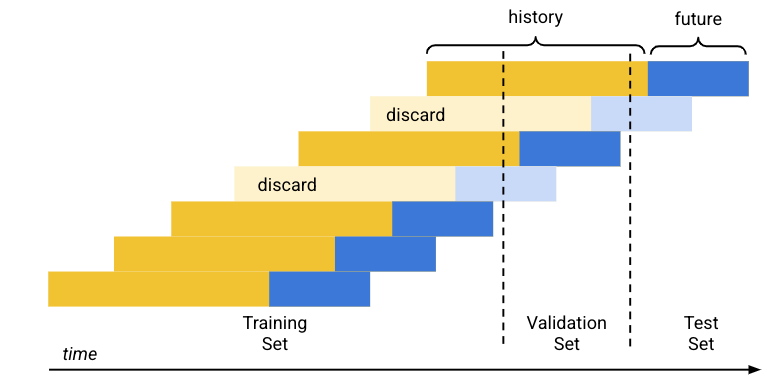
기본(시간순) 데이터 분할은 다음과 같이 작동합니다.
- Vertex AI는 학습 데이터를 날짜별로 정렬합니다.
- 미리 정해진 세트 비율 (80/10/10)을 사용하여 Vertex AI는 학습 데이터가 적용되는 기간을 각 학습 세트당 세 개의 블록으로 분리합니다.
- Vertex AI는 모델이 기록이 충분하지 않은 행(컨텍스트 윈도우)에서 학습할 수 있도록 각 시계열의 시작 부분에 빈 행을 추가합니다. 추가된 행의 수는 학습 시점에 설정된 환경설정 기간의 크기입니다.
학습 시점에 설정된 예측 범위 크기를 사용하여 Vertex AI는 향후 데이터 (예측 범위)가 하나의 데이터 세트 중 하나에 완전히 속하는 각 행을 해당 세트에 사용합니다. 데이터 유출을 방지하기 위해 예측 범위가 두 세트에 걸쳐 있는 행은 Vertex AI에서 삭제됩니다.
수동 분할
데이터 분할 열을 사용하면 학습, 검증, 테스트에 사용할 구체적인 행을 선택할 수 있습니다. 학습 데이터를 만들 때 다음 값 중 하나 (대소문자 구분)를 포함할 수 있는 열을 추가해야 합니다.
TRAINVALIDATETEST
모든 행에 이 열의 값이 있어야 하며, 이 값은 빈 문자열일 수 없습니다.
예를 들면 다음과 같습니다.
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
데이터 분할 열에 모든 유효한 열 이름을 지정할 수 있습니다. 변환 유형은 범주형, 텍스트 또는 자동일 수 있습니다.
모델 학습 중에 열을 데이터 분할 열로 지정합니다.
시계열의 데이터 유출을 방지하세요.