Wenn Sie ein AutoML-Modell mit einem Dataset trainieren, teilt Vertex AI Ihre Daten in drei Aufteilungen auf: eine Trainingsaufteilung, eine Validierungsaufteilung und eine Testaufteilung. Das Hauptziel beim Erstellen von Datenaufteilungen ist, dass das Testset Produktionsdaten genau darstellt. Sie erhalten dadurch anhand der Bewertungsmesswerte einen genauen Einblick, wie gut das Modell mit realen Daten funktioniert.
Auf dieser Seite wird beschrieben, wie Vertex AI die Trainings-, Validierungs- und Test-Datasets zum Trainieren eines AutoML-Modells verwendet. Außerdem wird beschrieben, wie Sie die Aufteilung Ihrer Daten in diese drei Datasets steuern können. Die Algorithmen für die Datenaufteilung bei Klassifizierung und Regression unterscheiden sich von den Algorithmen für die Datenaufteilung bei der Prognose.
Datenaufteilung für Klassifizierung und Regression
So werden Datenaufteilungen verwendet
Die Datenaufteilungen werden im Trainingsprozess so verwendet:
Modelltests
Das Trainings-Dataset wird zum Trainieren von Modellen mit verschiedenen Kombinationen aus Vorverarbeitungs-, Architektur- und Hyperparameteroptionen verwendet. Vertex AI bewertet diese Modelle mit dem Validierungs-Dataset hinsichtlich der Qualität. Dabei wird ermittelt, welche zusätzlichen Optionskombinationen nützlich sein könnten. Das Validierungs-Dataset wird auch verwendet, um während des Trainings den besten Prüfpunkt aus der regelmäßigen Bewertung auszuwählen. Vertex AI verwendet die in der parallelen Abstimmungsphase ermittelten besten Parameter und Architekturen, um zwei Ensemble-Modelle zu trainieren, wie unten beschrieben.
Modellbewertung
Vertex AI trainiert ein Bewertungsmodell und verwendet dazu die Trainings- und Validierungs-Datasets als Trainingsdaten. Die endgültigen Bewertungsmesswerte für dieses Modell werden von Vertex AI mithilfe des Test-Datasets generiert. Hierbei wird das Test-Dataset zum ersten Mal verwendet. Durch diesen Ansatz liefern die abschließenden Bewertungsmesswerte ein verzerrungsfreies Abbild der Leistung des endgültigen Trainingsmodells in der Produktion.
Bereitstellungsmodell
Vertex AI trainiert ein Modell mit den Trainings-, Validierungs- und Test-Datasets, um den Umfang an Trainingsdaten zu maximieren. Mit diesem Modell fordern Sie Online-Vorhersagen oder Batch-Vorhersagen an.
Standard-Datenaufteilung
Standardmäßig verwendet Vertex AI einen zufälligen Aufteilungsalgorithmus, um Ihre Daten in die drei Datenaufteilungen zu unterteilen. Vertex AI wählt nach dem Zufallsprinzip 80 % Ihrer Datenzeilen für das Trainings-Dataset, 10 % für das Validierungs-Dataset und 10 % für das Test-Dataset aus. Wir empfehlen die Standardaufteilung für Datasets:
- Im Laufe der Zeit unverändert bleiben.
- Relativ ausgeglichen.
- Verteilt wie die für Vorhersagen in der Produktion verwendeten Daten.
Übernehmen Sie zur Bestätigung der Standarddatenaufteilung die Standardeinstellung in der Google Cloud Console oder lassen Sie das Feld Split für die API leer.
Optionen zur Steuerung von Datenaufteilungen
Sie können mit einem der folgenden Ansätze steuern, welche Zeilen für welche Aufteilung ausgewählt werden:
- Zufallsaufteilung: Bestimmt die Aufteilungsprozentsätze und weist Datenzeilen nach dem Zufallsprinzip zu.
- Manuelle Aufteilung: Wählen Sie bestimmte Zeilen aus, die für das Training, die Validierung und das Testen in der Spalte für die Datenaufteilung verwendet werden sollen.
- Chronologische Aufteilung: Teilen Sie Ihre Daten in der Spalte "Zeit" nach Zeit auf.
Sie wählen nur eine dieser Optionen aus. Dies entscheiden Sie beim Trainieren des Modells. Einige dieser Optionen erfordern Änderungen an den Trainingsdaten, z. B. an der Datenaufteilungs- oder der Zeitspalte. Sie müssen diese Optionen nicht verwenden, um Daten für die Datenaufteilungsoptionen hinzuzufügen. Sie können beim Trainieren Ihres Modells noch eine andere Option auswählen.
Die Standardaufteilung ist in folgenden Fällen nicht die beste Wahl:
Sie trainieren kein Prognosemodell, aber Ihre Daten sind zeitkritisch.
Verwenden Sie in diesem Fall eine chronologische Aufteilung oder eine manuelle Aufteilung, durch die für das Test-Dataset die neuesten Daten genutzt werden.
Ihre Testdaten enthalten Daten aus Gruppen, die in der Produktion nicht vertreten sind.
Angenommen, Sie trainieren ein Modell mit den Kaufdaten mehrerer Geschäfte. Sie wissen jedoch, dass das Modell in erster Linie für Vorhersagen für Geschäfte verwendet wird, die nicht in den Trainingsdaten enthalten sind. Damit das Modell für nicht vorhandene Geschäfte verallgemeinert werden kann, sollten Sie die Datasets nach Geschäften segmentieren. Mit anderen Worten, Ihr Test-Dataset sollte nur Geschäfte enthalten, die sich von dem Validierungs-Dataset unterscheiden. Das Validierungs-Dataset sollte nur Geschäfte enthalten, die sich von dem Trainings-Dataset unterscheiden.
Die Klassen sind unausgeglichen.
Wenn in den Trainingsdaten die Beispiele einer Klasse deutlich überwiegen, sollten Sie die Testdaten gegebenenfalls manuell durch weitere Beispiele der Minderheitenklasse ergänzen. Mit Vertex AI werden keine geschichteten Stichproben durchgeführt. Das Test-Dataset kann daher zu wenig oder gar keine Beispiele der Minderheitenklasse enthalten.
Zufällige Aufteilung
Die zufällige Aufteilung wird auch als "mathematische Aufteilung" oder "Bruchaufteilung" bezeichnet.
Standardmäßig werden für die Trainings-, Validierungs- und Test-Datasets die Prozentsätze 80, 10 und 10 verwendet. Wenn Sie die Google Cloud -Konsole verwenden, können Sie die Prozentsätze in beliebige Werte ändern, die insgesamt 100 ergeben. Wenn Sie die Vertex AI API verwenden, nutzen Sie Bruchwerte, die insgesamt 1,0 ergeben.
Die Prozentsätze ändern Sie mit dem Objekt FractionSplit.
Vertex AI wählt Zeilen für eine Datenaufteilung nach dem Zufallsprinzip, aber deterministisch aus. Wenn Sie mit den automatisch generierten Aufteilungen der Daten nicht zufrieden sind, können Sie diese manuell aufteilen oder die Trainingsdaten ändern. Das Training eines neuen Modells mit denselben Trainingsdaten führt zur gleichen Datenaufteilung.
Manuelle Aufteilung
Die manuelle Aufteilung wird auch als "vordefinierte Aufteilung" bezeichnet.
Über Spalten für die Datenaufteilung können Sie bestimmte Zeilen auswählen, die für Training, Validierung und Tests verwendet werden sollen. Fügen Sie beim Erstellen der Trainingsdaten eine Spalte hinzu, die – unter Berücksichtigung der Groß- und Kleinschreibung – einen der folgenden Werte enthalten kann:
TRAINVALIDATETESTUNASSIGNED
Die Werte in dieser Spalte müssen eine der beiden folgenden Kombinationen sein:
- Sowohl
TRAIN,VALIDATEals auchTEST - Nur
TESTundUNASSIGNED
Jede Zeile muss einen Wert für diese Spalte haben. Sie kann keinen leeren String enthalten.
Zum Beispiel mit allen angegebenen Datasets:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Nur mit dem angegebenen Test-Dataset:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
Die Spalte für die Datenaufteilung kann jeden gültigen Spaltennamen haben. Der Transformationstyp kann Kategorial, Text oder Auto sein.
Wenn der Wert der Spalte für die Datenaufteilung UNASSIGNED ist, weist Vertex AI diese Zeile automatisch dem Trainings- oder Validierungs-Dataset zu.
Bestimmen Sie eine Spalte beim Modelltraining als Spalte für die Datenaufteilung.
Chronologische Aufteilung
Die chronologische Aufteilung wird auch als "Zeitstempelaufteilung" bezeichnet.
Wenn Ihre Daten zeitabhängig sind, können Sie eine Spalte als Zeitspalte festlegen. AI Platform verwendet dann die Zeitspalte für die Datenaufteilung, wobei die zeitlich frühesten Zeilen für das Training, die nächsten Zeilen für die Validierung und die neuesten Zeilen für Tests verwendet werden.
Vertex AI behandelt jede Zeile als unabhängiges und gleich verteiltes Trainingsbeispiel. Das Festlegen der Spalte "Zeit" ändert nichts daran. Die Spalte "Time" (Zeit) wird nur zum Aufteilen des Datasets verwendet.
Wenn Sie eine Spalte „Zeit“ angeben, müssen Sie für jede Zeile in Ihrem Dataset einen Wert für die Spalte „Zeit“ angeben. Achten Sie darauf, dass die Spalte "Time" (Zeit) genügend verschiedene Werte hat, damit die Validierungs- und Test-Datasets nicht leer sind. Normalerweise sind mindestens 20 verschiedene Werte ausreichend.
Die Daten in der Spalte „Zeit“ müssen mit einem der von der Zeitstempeltransformation unterstützten Formate übereinstimmen. Die Spalte „Zeit“ kann jedoch jede beliebige Transformation enthalten, da sich die Transformation nur auf die Verwendung dieser Spalte im Training auswirkt. Transformationen wirken sich nicht auf die Datenaufteilung aus.
Sie können auch die Prozentsätze der Trainingsdaten bestimmen, die pro Satz zugewiesen werden.
Eine Spalte während des Modelltrainings als Zeitspalte bestimmen.
Datenaufteilungen für Prognosen
Standardmäßig verwendet Vertex AI einen chronologischen Aufteilungsalgorithmus, um Ihre Prognosedaten in die drei Datenaufteilungen zu unterteilen. Wir empfehlen die Verwendung der Standardaufteilung. Wenn Sie jedoch steuern möchten, welche Trainingsdatenzeilen für welche Aufteilung verwendet werden, verwenden Sie eine manuelle Aufteilung.
So werden Datenaufteilungen verwendet
Die Datenaufteilungen werden im Trainingsprozess so verwendet:
Modelltests
Das Trainings-Dataset wird zum Trainieren von Modellen mit verschiedenen Kombinationen aus Vorverarbeitungs-, Architektur- und Hyperparameteroptionen verwendet. Vertex AI bewertet diese Modelle mit dem Validierungs-Dataset hinsichtlich der Qualität. Dabei wird ermittelt, welche zusätzlichen Optionskombinationen nützlich sein könnten. Das Validierungs-Dataset wird auch verwendet, um während des Trainings den besten Prüfpunkt aus der regelmäßigen Bewertung auszuwählen. Vertex AI verwendet die in der parallelen Abstimmungsphase ermittelten besten Parameter und Architekturen, um zwei Ensemble-Modelle zu trainieren, wie unten beschrieben.
Modellbewertung
Vertex AI trainiert ein Bewertungsmodell und verwendet dazu die Trainings- und Validierungs-Datasets als Trainingsdaten. Die endgültigen Bewertungsmesswerte für dieses Modell werden von Vertex AI mithilfe des Test-Datasets generiert. Hierbei wird das Test-Dataset zum ersten Mal verwendet. Durch diesen Ansatz liefern die abschließenden Bewertungsmesswerte ein verzerrungsfreies Abbild der Leistung des endgültigen Trainingsmodells in der Produktion.
Bereitstellungsmodell
Vertex AI trainiert ein Modell mit dem Trainings- und Validierungs-Dataset. Das Modell wird mit dem Test-Dataset validiert (um den besten Prüfpunkt auszuwählen). Das Test-Dataset wird trainiert, da der Verlust daraus berechnet wird. Mit diesem Modell erhalten Sie Inferenzdaten.
Standardaufteilung
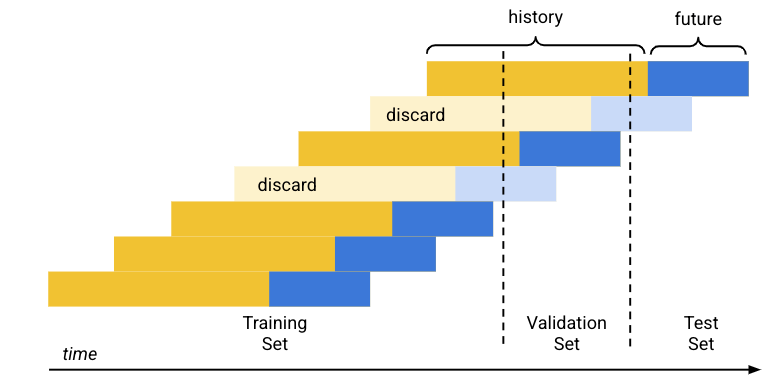
Die standardmäßige (chronologische) Datenaufteilung funktioniert so:
- Vertex AI sortiert die Trainingsdaten nach Datum.
- Unter Verwendung der vordefinierten Prozentsätze (80/10/10) wird der von den Trainingsdaten abgedeckte Zeitraum in drei Blöcke unterteilt, einen für jeden Trainingssatz.
- Vertex AI fügt am Anfang jeder Zeitachse leere Zeilen hinzu, damit das Modell aus Zeilen lernen kann, die nicht genügend Verlauf haben (Verlaufszeitraum). Die Anzahl der hinzugefügten Zeilen ist die Größe des Verlaufszeitraums, der zur Trainingszeit festgelegt wurde.
Wenn Sie den Prognosehorizont zum Zeitpunkt des Trainings verwenden, wird jede Zeile, deren zukünftige Daten (Prognosehorizont) vollständig in einen der Datensätze fallen, für diesen Datensatz verwendet. (Vertex AI verwirft Zeilen, deren Vorhersagehorizont sich über zwei Datensätze erstreckt, um Datenverluste zu vermeiden.)
Manuelle Aufteilung
Über Spalten für die Datenaufteilung können Sie bestimmte Zeilen auswählen, die für Training, Validierung und Tests verwendet werden sollen. Fügen Sie beim Erstellen der Trainingsdaten eine Spalte hinzu, die – unter Berücksichtigung der Groß- und Kleinschreibung – einen der folgenden Werte enthalten kann:
TRAINVALIDATETEST
Jede Zeile muss einen Wert für diese Spalte haben. Sie kann keinen leeren String enthalten.
Beispiel:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
Die Spalte für die Datenaufteilung kann jeden gültigen Spaltennamen haben. Der Transformationstyp kann Kategorial, Text oder Auto sein.
Bestimmen Sie eine Spalte beim Modelltraining als Spalte für die Datenaufteilung.
Achten Sie darauf, Datenlecks zwischen Ihren Zeitachsen zu vermeiden.