Quando você usa um conjunto de dados para treinar um modelo do AutoML, a Vertex AI divide seus dados em três divisões: treinamento, validação e teste. O objetivo principal ao criar divisões de dados é garantir que seu conjunto de teste represente dados de produção com precisão. Assim, temos a certeza de que as métricas de avaliação indicam com exatidão como o modelo funcionará com dados reais.
Nesta página, explicamos como a Vertex AI usa os conjuntos de treinamento, validação e teste dos seus dados para treinar um modelo do AutoML. Também descrevemos as maneiras de controlar como os dados são divididos entre esses três conjuntos. Os algoritmos de divisão de dados para classificação e regressão são diferentes dos algoritmos de divisão para previsão.
Divisão de dados para classificação e regressão
Como as divisões de dados são usadas
As divisões de dados são usadas no processo de treinamento da seguinte maneira:
Modelos de avaliação
O conjunto de treinamento é usado para treinar modelos com diferentes combinações de pré-processamento, arquitetura e opções de hiperparâmetros. A Vertex AI avalia esses modelos no conjunto de validação para avaliar a qualidade, o que orienta a exploração de combinações de outras opções. O conjunto de validação também é usado para selecionar o melhor checkpoint na avaliação periódica durante o treinamento. A Vertex AI usa os melhores parâmetros e arquiteturas determinados na fase de ajuste paralelo para treinar dois modelos de conjunto, conforme descrito abaixo.
Avaliação do modelo
O Vertex AI treina um modelo de avaliação usando os conjuntos de treinamento e validação como dados de treinamento. A Vertex AI gera as métricas de avaliação do modelo finais usando o conjunto de teste. Essa é a primeira vez em que o conjunto de teste é usado durante o processo. Essa abordagem garante que as métricas de avaliação finais sejam um reflexo imparcial do desempenho do modelo treinado final na produção.
Modelo de exibição
A Vertex AI treina um modelo com os conjuntos de treinamento, validação e teste para maximizar a quantidade de dados de treinamento. Use esse modelo para solicitar previsões on-line ou em lote.
Divisão de dados padrão
Por padrão, a Vertex IA usa um algoritmo de divisão aleatória para separar seus dados nas três divisões de dados. A Vertex AI seleciona aleatoriamente 80% das linhas de dados para o conjunto de treinamento, 10% para o conjunto de validação e 10% para o conjunto de teste. Recomendamos a divisão padrão para conjuntos de dados que são:
- Mudando com o tempo.
- Relativamente equilibrado.
- Distribuído como os dados usados para previsões na produção.
Para usar a divisão de dados padrão, aceite o padrão no console do Google Cloud ou deixe o campo split vazio para a API.
Opções para controlar divisões de dados
Para controlar quais linhas são selecionadas em cada divisão, use uma das abordagens a seguir:
- Divisão aleatória: define as porcentagens divididas e atribui aleatoriamente as linhas de dados.
- Divisão manual: selecione linhas específicas para usar no treinamento, na validação e nos testes na coluna de divisão de dados.
- Divisão cronológica: divida seus dados por tempo na coluna "Tempo".
Escolha apenas uma dessas opções ao treinar o modelo. Algumas dessas opções exigem alterações nos dados de treinamento (por exemplo, a coluna de divisão de dados ou a coluna de tempo). A inclusão de dados para opções de divisão de dados não exige que você use essas opções. É possível escolher outra opção ao treinar o modelo.
A divisão padrão não é a melhor escolha se:
Você não está treinando um modelo de previsão, mas os dados são sensíveis ao tempo.
Nesse caso, use uma divisão cronológica ou uma divisão manual que resulte na utilização dos dados mais recentes como o conjunto de teste.
Os dados de teste incluem dados de populações que não serão representadas na produção.
Por exemplo, suponha que você treine um modelo com dados de compras de várias lojas. Entretanto, você sabe que o modelo será usado principalmente para fazer previsões para lojas que não fazem parte dos dados de treinamento. Para garantir que o modelo possa generalizar para lojas não vistas, separe os conjuntos de dados por lojas. Em outras palavras, seu conjunto de teste deve incluir somente lojas que não estejam no conjunto de validação, e o conjunto de validação deve, por sua vez, ter apenas lojas que não estejam no conjunto de treinamento.
Não há equilíbrio entre as classes.
Se uma classe tiver muito mais volume do que outras nos dados de treinamento, talvez seja necessário incluir manualmente mais exemplos nas classes minoritárias nos dados de teste. A Vertex AI não realiza uma amostragem estratificada. Portanto, o conjunto de teste pode incluir poucos exemplos ou até mesmo nenhum exemplo da classe minoritária.
Divisão aleatória
A divisão aleatória também é conhecida como "divisão matemática" ou "divisão fracionária".
Por padrão, as porcentagens dos dados de treinamento usados nos conjuntos de treinamento, validação e teste são 80, 10 e 10, respectivamente. Se você usar o console Google Cloud , poderá mudar as porcentagens para valores que totalizem 100. Se você usar a API Vertex AI, use frações que totalizem 1,0.
Para mudar os percentuais (frações), use o objeto FractionSplit para definir as frações.
A Vertex AI seleciona linhas para uma divisão de dados de maneira aleatória, mas determinista. Se você não estiver satisfeito com a composição das divisões de dados geradas, faça a divisão manualmente ou altere os dados de treinamento. Treinar um novo modelo com os mesmos dados de treinamento resulta na mesma divisão de dados.
Divisão manual
A divisão manual também é conhecida como "divisão predefinida".
Na coluna de divisão de dados, é possível selecionar as linhas específicas a serem usadas para treinamento, validação e teste. Ao criar os dados de treinamento, adicione uma coluna que contenha um dos seguintes valores, com diferenciação entre maiúsculas e minúsculas:
TRAINVALIDATETESTUNASSIGNED
A combinação dos valores nesta coluna precisa contemplar uma das seguintes possibilidades:
- Todos
TRAIN,VALIDATEeTEST - Somente
TESTeUNASSIGNED
Todas as linhas precisam ter um valor para essa coluna, ela não pode ser uma string vazia.
Por exemplo, com todos os conjuntos especificados:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Com apenas o conjunto de teste especificado:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
A coluna de divisão de dados pode ter qualquer nome de coluna válido. O tipo de transformação pode ser categórico, de texto ou automático.
Se o valor da coluna de divisão de dados for UNASSIGNED,
a Vertex AI atribuirá a linha automaticamente ao conjunto de treinamento ou
ao conjunto de validação.
Designar uma coluna como uma coluna de divisão de dados durante o treinamento do modelo.
Divisão cronológica
A divisão cronológica também é conhecida como "divisão de carimbo de data/hora".
Se os seus dados dependem do tempo, é possível designar uma coluna como Coluna de tempo. A Vertex AI usa a coluna Data/hora para dividir seus dados, com as primeiras linhas usadas para treinamento, as linhas seguintes para validação e as últimas linhas para teste.
A Vertex AI trata todas as linhas como exemplos de treinamento, distribuídas de maneira independente e idêntica. Definir a Coluna de tempo não mudará isso. A coluna Data/hora é usada apenas para dividir o conjunto de dados.
Se você especificar uma coluna Data/hora, inclua um valor para cada linha no conjunto de dados. Verifique se a coluna Data/hora tem uma quantidade suficiente de valores distintos para que os conjuntos de validação e teste não fiquem vazios. Normalmente, pelo menos 20 valores distintos são suficientes.
Os dados na coluna data/hora precisam estar em conformidade com um dos formatos aceitos pela transformação de carimbo de data/hora. No entanto, a coluna data/hora pode ter qualquer transformação compatível porque ela afeta apenas a maneira como essa coluna é usada no treinamento. As transformações não afetam a divisão de dados.
Também é possível especificar as porcentagens dos dados de treinamento que são atribuídas a cada conjunto.
Designar uma coluna como Coluna de tempo durante o treinamento do modelo.
Divisão de dados para previsão
Por padrão, a Vertex IA usa um algoritmo de divisão cronológica para separar os dados de previsão nas três divisões de dados. Recomendamos usar a divisão padrão. No entanto, se você quiser controlar quais linhas de dados de treinamento são usadas para cada divisão, use uma divisão manual.
Como as divisões de dados são usadas
As divisões de dados são usadas no processo de treinamento da seguinte maneira:
Modelos de avaliação
O conjunto de treinamento é usado para treinar modelos com diferentes combinações de pré-processamento, arquitetura e opções de hiperparâmetros. A Vertex AI avalia esses modelos no conjunto de validação para avaliar a qualidade, o que orienta a exploração de combinações de outras opções. O conjunto de validação também é usado para selecionar o melhor checkpoint na avaliação periódica durante o treinamento. A Vertex AI usa os melhores parâmetros e arquiteturas determinados na fase de ajuste paralelo para treinar dois modelos de conjunto, conforme descrito abaixo.
Avaliação do modelo
O Vertex AI treina um modelo de avaliação usando os conjuntos de treinamento e validação como dados de treinamento. A Vertex AI gera as métricas de avaliação do modelo finais usando o conjunto de teste. Essa é a primeira vez em que o conjunto de teste é usado durante o processo. Essa abordagem garante que as métricas de avaliação finais sejam um reflexo imparcial do desempenho do modelo treinado final na produção.
Modelo de exibição
A Vertex AI treina um modelo com o conjunto de treinamento e validação. O modelo é validado (para selecionar o melhor checkpoint) usando o conjunto de teste. O conjunto de teste nunca é treinado, no sentido de que a perda é calculada com base nele. Use esse modelo para receber inferências.
Divisão padrão
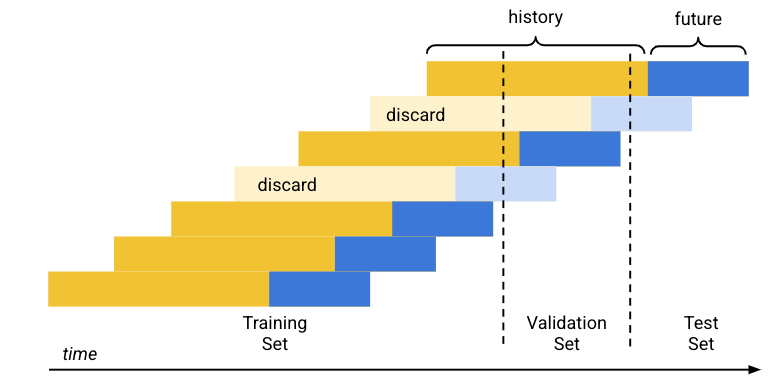
A divisão de dados padrão (cronológica) funciona da seguinte maneira:
- A Vertex AI classifica os dados de treinamento por data.
- Usando as porcentagens de conjunto predeterminadas (80/10/10), a Vertex AI separa o período coberto pelos dados de treinamento em três blocos, um para cada conjunto de treinamento.
- A Vertex AI adiciona linhas vazias ao início de cada série temporal para permitir que o modelo aprenda com linhas que não têm histórico suficiente (janela de contexto). O número de linhas adicionadas é o tamanho da janela de contexto definida no momento do treinamento.
Usando o tamanho do horizonte de previsão definido no momento do treinamento, a Vertex AI usa cada linha com dados futuros (horizonte de previsão) que se enquadra em um dos conjuntos de dados para esse conjunto. (A Vertex AI descarta as linhas cujo horizonte de previsão abrange dois conjuntos para evitar o vazamento de dados.)
Divisão manual
Na coluna de divisão de dados, é possível selecionar as linhas específicas a serem usadas para treinamento, validação e teste. Ao criar os dados de treinamento, adicione uma coluna que contenha um dos seguintes valores, com diferenciação entre maiúsculas e minúsculas:
TRAINVALIDATETEST
Todas as linhas precisam ter um valor para essa coluna, ela não pode ser uma string vazia.
Por exemplo:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
A coluna de divisão de dados pode ter qualquer nome de coluna válido. O tipo de transformação pode ser categórico, de texto ou automático.
Designar uma coluna como uma coluna de divisão de dados durante o treinamento do modelo.
Tome cuidado para evitar o vazamento de dados entre suas séries temporais.