Saat Anda menggunakan set data untuk melatih model AutoML, Vertex AI membagi data Anda menjadi tiga bagian: bagian pelatihan, bagian validasi, dan bagian pengujian. Tujuan utama saat membuat pemisahan data adalah untuk memastikan bahwa set pengujian Anda mewakili data produksi secara akurat. Hal ini memastikan bahwa metrik evaluasi memberikan sinyal yang akurat tentang performa model terhadap data di dunia nyata.
Halaman ini membahas cara Vertex AI menggunakan set pelatihan, validasi, dan pengujian data Anda untuk melatih model AutoML. Dokumen ini juga menjelaskan cara Anda dapat mengontrol pemisahan data di antara ketiga set ini. Algoritma pemisahan data untuk klasifikasi dan regresi berbeda dengan algoritma pemisahan data untuk perkiraan.
Pemisahan data untuk klasifikasi dan regresi
Cara pemisahan data digunakan
Pemisahan data digunakan dalam proses pelatihan sebagai berikut:
Uji coba model
Set pelatihan digunakan untuk melatih model dengan kombinasi opsi pra-pemrosesan, arsitektur, dan hyperparameter yang berbeda. Vertex AI mengevaluasi model ini berdasarkan set validasi untuk kualitas, yang memandu eksplorasi kombinasi opsi tambahan. Set validasi juga digunakan untuk memilih checkpoint terbaik dari evaluasi berkala selama pelatihan. Vertex AI menggunakan parameter dan arsitektur terbaik yang ditentukan dalam fase penyesuaian paralel untuk melatih dua model ansambel seperti yang dijelaskan di bawah ini.
Evaluasi model
Vertex AI melatih model evaluasi menggunakan set pelatihan dan validasi sebagai data pelatihan. Vertex AI menghasilkan metrik evaluasi model akhir pada model ini, menggunakan set pengujian. Ini adalah pertama kalinya set pengujian digunakan dalam proses. Pendekatan ini memastikan bahwa metrik evaluasi akhir merupakan refleksi yang tidak bias dari seberapa baik performa model akhir yang telah dilatih dalam tahap produksi.
Model inferensi
Vertex AI melatih model dengan set pelatihan, validasi, dan pengujian untuk memaksimalkan jumlah data pelatihan. Gunakan model ini untuk meminta prediksi online atau prediksi batch.
Pemisahan data default
Secara default, Vertex AI menggunakan algoritma pemisahan acak untuk memisahkan data Anda menjadi tiga bagian data. Vertex AI secara acak memilih 80% baris data Anda untuk set pelatihan, 10% untuk set validasi, dan 10% untuk set pengujian. Kami merekomendasikan pemisahan default untuk set data yang:
- Tidak berubah seiring waktu.
- Relatif seimbang.
- Didistribusikan seperti data yang digunakan untuk prediksi dalam produksi.
Untuk menggunakan pemisahan data default, terima nilai default di konsol Google Cloud , atau kosongkan kolom pemisahan untuk API.
Opsi untuk mengontrol pemisahan data
Anda dapat mengontrol baris yang dipilih untuk pemisahannya menggunakan salah satu pendekatan berikut:
- Pemisahan acak: Menetapkan persentase pemisahan dan menetapkan baris data secara acak.
- Pemisahan manual: Memilih baris tertentu yang akan digunakan untuk pelatihan, validasi, dan pengujian di kolom pemisahan data.
- Pemisahan kronologis: Memisahkan data Anda menurut waktu di kolom Waktu.
Pilih hanya salah satu opsi berikut saat melatih model Anda. Beberapa opsi ini memerlukan perubahan pada data pelatihan (misalnya, kolom pemisahan data atau kolom waktu). Menyertakan data untuk opsi pemisahan data tidak mengharuskan Anda menggunakan opsi tersebut; Anda masih dapat memilih opsi lain saat melatih model.
Pemisahan default bukan pilihan terbaik jika:
Anda tidak melatih model perkiraan, tetapi data bersifat sensitif waktu.
Dalam hal ini, gunakan pemisahan kronologis, atau pemisahan manual yang membuat data terbaru digunakan sebagai set pengujian.
Data pengujian Anda menyertakan data dari populasi yang tidak akan direpresentasikan dalam produksi.
Misalnya, Anda melatih model dengan data pembelian dari sejumlah toko. Namun, Anda tahu bahwa model tersebut akan digunakan terutama untuk membuat prediksi untuk toko yang tidak ada dalam data pelatihan. Untuk memastikan bahwa model dapat melakukan generalisasi ke toko yang tidak terlihat, pisahkan set data Anda berdasarkan toko. Dengan kata lain, set pengujian Anda hanya boleh menyertakan penyimpanan yang berbeda dari set validasi, dan set validasi hanya boleh menyertakan penyimpanan yang berbeda dari set pelatihan.
Class Anda tidak seimbang.
Jika Anda memiliki lebih banyak kelas daripada yang lain dalam data pelatihan, Anda mungkin perlu secara manual menyertakan lebih banyak contoh kelas minoritas dalam data pengujian. Vertex AI tidak melakukan pengambilan sampel bertingkat, sehingga set pengujian dapat menyertakan terlalu sedikit atau bahkan nol contoh kelas minoritas.
Pemisahan acak
Pemisahan acak juga dikenal sebagai "pemisahan matematika" atau "pemisahan fraksi".
Secara default, persentase data pelatihan yang digunakan untuk set pelatihan, validasi, dan pengujian masing-masing adalah 80, 10, dan 10. Jika menggunakan konsol Google Cloud , Anda dapat mengubah persentase menjadi nilai apa pun yang jika dijumlahkan totalnya menjadi 100. Jika Anda menggunakan Vertex AI API, gunakan pecahan yang berjumlah 1,0.
Untuk mengubah persentase (pecahan), gunakan objek FractionSplit untuk menentukan pecahan.
Vertex AI memilih baris untuk pemisahan data secara acak, tetapi secara deterministik. Jika Anda tidak puas dengan susunan pemisahan data yang dihasilkan, gunakan pemisahan manual atau ubah data pelatihan. Melatih model baru dengan data pelatihan yang sama akan menghasilkan pemisahan data yang sama.
Pemisahan manual
Pemisahan manual juga disebut sebagai "pemisahan yang telah ditentukan".
Kolom pemisahan data memungkinkan Anda memilih baris tertentu yang akan digunakan untuk pelatihan, validasi, dan pengujian. Saat membuat data pelatihan, tambahkan kolom yang dapat berisi salah satu nilai (peka huruf besar/kecil) berikut:
TRAINVALIDATETESTUNASSIGNED
Nilai dalam kolom ini harus merupakan salah satu dari dua kombinasi berikut:
- Semua
TRAIN,VALIDATE, danTEST - Hanya
TESTdanUNASSIGNED
Setiap baris harus memiliki nilai untuk kolom ini; nilainya tidak boleh berupa string kosong.
Misalnya, dengan semua set ditentukan:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Dengan hanya set pengujian yang ditentukan:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
Kolom pemisahan data dapat memiliki nama kolom yang valid; jenis transformasinya dapat berupa Kategoris, Teks, atau Otomatis.
Jika nilai kolom pemisahan data adalah UNASSIGNED, Vertex AI
akan otomatis menetapkan baris tersebut ke set pelatihan atau validasi.
Tetapkan kolom sebagai kolom pemisahan data selama pelatihan model.
Pemisahan kronologis
Pemisahan kronologis juga dikenal sebagai "pemisahan stempel waktu".
Jika data bergantung pada waktu, Anda dapat menetapkan satu kolom sebagai kolom Waktu. Vertex AI menggunakan kolom Waktu untuk membagi data Anda, dengan baris paling awal digunakan untuk pelatihan, baris berikutnya untuk validasi, dan baris terakhir untuk pengujian.
Vertex AI memperlakukan setiap baris sebagai contoh pelatihan yang terdistribusi secara independen dan identik; menyetel kolom Waktu tidak mengubah hal ini. Kolom Waktu hanya digunakan untuk memisahkan set data.
Jika Anda menentukan kolom Waktu, sertakan nilai kolom Waktu untuk setiap baris dalam set data Anda. Pastikan kolom Waktu memiliki nilai berbeda yang cukup, sehingga set validasi dan pengujian tidak kosong. Biasanya, setidaknya 20 nilai yang berbeda sudah cukup.
Data dalam kolom Waktu harus sesuai dengan salah satu format yang didukung oleh transformasi stempel waktu. Namun, kolom Waktu dapat berisi transformasi apa pun yang didukung, karena transformasi hanya memengaruhi cara kolom tersebut digunakan dalam pelatihan; transformasi tidak memengaruhi pemisahan data.
Anda juga dapat menentukan persentase data pelatihan yang ditetapkan ke setiap set.
Tetapkan kolom sebagai kolom Waktu selama pelatihan model.
Pemisahan data untuk perkiraan
Secara default, Vertex AI menggunakan algoritma pemisahan kronologis untuk memisahkan data perkiraan menjadi tiga bagian data. Sebaiknya gunakan pemisahan default. Namun, jika Anda ingin mengontrol baris data pelatihan yang digunakan untuk pemisahan, gunakan pemisahan manual.
Cara pemisahan data digunakan
Pemisahan data digunakan dalam proses pelatihan sebagai berikut:
Uji coba model
Set pelatihan digunakan untuk melatih model dengan kombinasi opsi pra-pemrosesan, arsitektur, dan hyperparameter yang berbeda. Vertex AI mengevaluasi model ini berdasarkan set validasi untuk kualitas, yang memandu eksplorasi kombinasi opsi tambahan. Set validasi juga digunakan untuk memilih checkpoint terbaik dari evaluasi berkala selama pelatihan. Vertex AI menggunakan parameter dan arsitektur terbaik yang ditentukan dalam fase penyesuaian paralel untuk melatih dua model ansambel seperti yang dijelaskan di bawah ini.
Evaluasi model
Vertex AI melatih model evaluasi menggunakan set pelatihan dan validasi sebagai data pelatihan. Vertex AI menghasilkan metrik evaluasi model akhir pada model ini, menggunakan set pengujian. Ini adalah pertama kalinya set pengujian digunakan dalam proses. Pendekatan ini memastikan bahwa metrik evaluasi akhir merupakan refleksi yang tidak bias dari seberapa baik performa model akhir yang telah dilatih dalam tahap produksi.
Model inferensi
Vertex AI melatih model dengan set pelatihan dan validasi. Model divalidasi (untuk memilih checkpoint terbaik) menggunakan set pengujian. Set pengujian tidak pernah dilatih dalam arti bahwa kerugian dihitung dari set pengujian tersebut. Anda menggunakan model ini untuk mendapatkan inferensi.
Pemisahan default
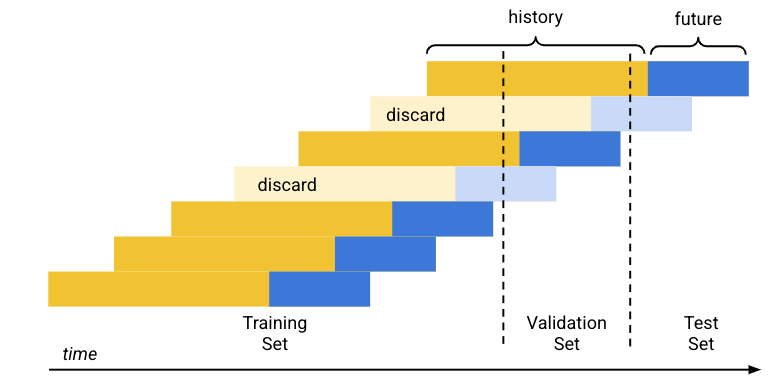
Cara kerja pemisahan data default (kronologis) adalah sebagai berikut:
- Vertex AI mengurutkan data pelatihan berdasarkan tanggal.
- Dengan persentase yang telah ditentukan (80/10/10), Vertex AI memisahkan jangka waktu yang dicakup oleh data pelatihan menjadi tiga blok, masing-masing satu untuk setiap set pelatihan.
- Vertex AI menambahkan baris kosong ke awal setiap deret waktu agar model dapat belajar dari baris yang tidak memiliki cukup histori (jendela konteks). Jumlah baris yang ditambahkan adalah ukuran jendela konteks yang ditetapkan pada waktu pelatihan.
Dengan menggunakan ukuran horizon perkiraan seperti yang ditetapkan pada waktu pelatihan, Vertex AI menggunakan setiap baris yang data mendatangnya (horizon perkiraan) masuk sepenuhnya ke dalam salah satu set data untuk set tersebut. (Vertex AI menghapus baris yang horizon perkiraannya membentang di antara dua set untuk menghindari kebocoran data).
Pemisahan manual
Kolom pemisahan data memungkinkan Anda memilih baris tertentu yang akan digunakan untuk pelatihan, validasi, dan pengujian. Saat membuat data pelatihan, tambahkan kolom yang dapat berisi salah satu nilai (peka huruf besar/kecil) berikut:
TRAINVALIDATETEST
Setiap baris harus memiliki nilai untuk kolom ini; nilainya tidak boleh berupa string kosong.
Contoh:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
Kolom pemisahan data dapat memiliki nama kolom yang valid; jenis transformasinya dapat berupa Kategoris, Teks, atau Otomatis.
Tetapkan kolom sebagai kolom pemisahan data selama pelatihan model.
Pastikan Anda berhati-hati dan menghindari kebocoran data di antara deret waktu.