소개
이 페이지에서는 Vertex AI와 함께 제공되는 특성 기여 분석 메서드의 개념을 간략히 설명합니다. 자세한 기술 논의는 AI Explanations 백서를 참조하세요.
전역 특성 중요도 (모델 특성 기여 분석)는 각 특성이 모델에 미치는 영향을 보여줍니다. 이 값은 각 특성의 백분율로 제공됩니다. 백분율이 높을수록 특성이 모델 학습에 더 큰 영향을 미칩니다. 모델의 전역 특성 중요도를 보려면 평가 측정항목을 조사합니다.
시계열 모델의 로컬 특성 기여 분석은 데이터의 각 특성이 예상된 결과에 미치는 영향을 나타냅니다. 이 정보를 활용하여 모델이 예상대로 작동하는지 확인하고, 모델의 편향을 인식하고, 모델 및 학습 데이터를 개선할 수 있는 방법에 대한 아이디어를 얻을 수 있습니다. 추론을 요청하면 예측 값이 모델에 적절하게 표시됩니다. 설명을 요청하면 특성 기여 분석 정보와 함께 추론이 표시됩니다.
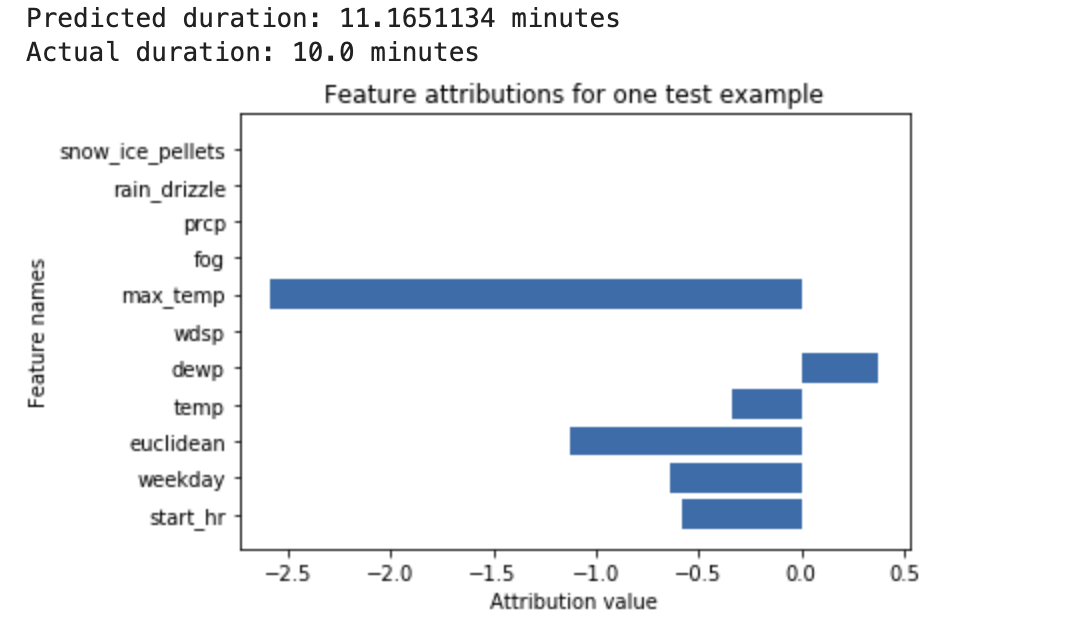
다음 예시를 살펴보겠습니다. 심층신경망은 날씨 데이터와 이전의 차량 공유 데이터를 기반으로 자전거 주행 시간을 예측하도록 학습됩니다. 이 모델에서 추론만 요청하면 예상 자전거 주행 시간이 분 단위로 표시됩니다. 설명을 요청하면 설명 요청의 각 특성에 대한 기여 분석 점수와 함께 자전거 여행 예상 시간이 표시됩니다. 기여 분석 점수는 지정한 기준 값을 기준으로 특성이 추론 값의 변경에 얼마나 영향을 주었는지 표시합니다. 모델에 적합한 의미 있는 기준을 선택합니다. 이 경우 자전거 주행 시간의 중앙값입니다.
특성 기여 점수를 플롯으로 나타내어 결과 추론에 가장 많이 기여한 특성을 확인할 수 있습니다.
온라인 추론 작업 또는 일괄 추론 작업을 수행할 때 로컬 특성 기여 분석을 생성하고 쿼리할 수 있습니다.
장점
특정 인스턴스를 검사하고 학습 데이터세트 전체에서 특성 기여 분석을 집계하면 모델 작동 방식에 대해 더 자세히 파악할 수 있습니다. 다음과 같은 장점이 있습니다.
디버깅 모델: 특성 기여 분석은 표준 모델 평가 기술이 일반적으로 놓칠 수 있는 데이터 문제를 감지하는 데 도움이 됩니다.
모델 최적화: 덜 중요한 특성을 식별하고 제거하여 모델의 효율성을 높일 수 있습니다.
개념적 제한사항
특성 기여 분석의 제한사항을 고려하세요.
AutoML의 로컬 특성 중요도를 포함하여 특성 기여 분석은 개별 추론에 따라 달라집니다. 개별 추론에 대한 특성 기여도를 검사하면 우수한 통계를 얻을 수 있지만 그러한 통계를 개별 인스턴스의 전체 클래스 또는 전체 모델에 일반화할 수는 없습니다.
AutoML 모델에 대해 보다 일반화 가능한 통계를 얻으려면 모델 특성 중요도를 참조하세요. 다른 모델에 대해 보다 일반화 가능한 통계를 얻으려면 데이터 세트의 하위 집합 또는 전체 데이터 세트에 대해 기여 분석을 집계합니다.
각 기여 분석은 특정 예시에 대해 특성이 추론에 영향을 미친 정도를 나타냅니다. 단일 기여 분석은 모델의 전체 동작을 반영하지 않을 수 있습니다. 전체 데이터세트의 전반적인 모델 동작을 이해하려면 전체 데이트세트에 대한 기여 분석을 집계하세요.
특성 기여 분석이 모델 디버깅에 도움이 될 수 있지만 문제가 모델에서 발생했는지 또는 모델이 학습된 데이터에서 발생했는지 항상 명확하게 나타내는 것은 아닙니다. 최선의 판단을 내리고 일반적인 데이터 문제를 진단하여 잠재적 원인의 범위를 좁혀야 합니다.
기여 분석은 모델을 학습시키는 데 사용되는 모델 및 데이터에 전적으로 의존합니다. 이러한 값은 모델이 데이터에서 찾아내는 패턴에는 영향을 미치지만 데이터에서 근본적인 관계를 밝히지는 못합니다. 특정한 특성에 대한 강력한 기여 분석이 존재하는지 여부가 해당 특성과 타겟 간에 관계가 있는지 여부를 의미하지 않습니다. 기여 분석은 모델이 추론에 특성을 사용 중인지 여부만 나타냅니다.
기여 분석만으로는 모델이 공평하고 편향되지 않으며 품질을 신뢰할 수 있는지 여부를 알 수 없습니다. 기여 분석 외에 학습 데이터 및 평가 측정항목을 신중하게 평가해야 합니다.
제한사항에 대한 자세한 내용은 AI Explanations 백서를 참조하세요.
특성 기여 분석 개선
특성 기여 분석에 가장 큰 영향을 미치는 요소는 다음과 같습니다.
- 기여 분석 방법은 Shapley 값의 근사치를 계산합니다. 샘플링된 Shapley 메서드의 경로 수를 늘려 근사치의 정밀도를 개선할 수 있습니다. 결과적으로 기여 분석 결과가 크게 달라질 수 있습니다.
- 기여 분석은 기준 값을 기준으로 특성이 추론 값의 변경에 얼마나 영향을 주었는지만 표시합니다. 모델에 물어보려는 질문과 관련된 의미 있는 기준을 선택해야 합니다. 기준 값을 전환하면 기여 분석 값과 그 해석이 크게 변경될 수 있습니다.
알고리즘
Vertex AI는 특정 출력에 대해 한 게임의 각 플레이어에 크레딧을 할당하는 협력 게임 이론 알고리즘인 Shapley 값을 사용하여 특정 기여 분석을 제공합니다. 머신러닝 모델에 적용하면 각 모델 특성이 게임에서 '플레이어'로 취급되고 크레딧이 특정 추론의 결과에 비례해서 할당됩니다. 구조화된 데이터 모델의 경우 Vertex AI는 샘플링된 Shapley라는 정확한 Shapley 값의 샘플링 근사값을 사용합니다.
샘플링된 Shapley 메서드의 작동 방식에 대한 자세한 내용은 샘플링 기반 Shapley 값 근사값의 추정 오차 경계 지정 백서를 참조하세요.
다음 단계
다음 리소스는 추가로 유용한 교육 자료를 제공합니다.