Einführung
Diese Seite bietet eine kurze konzeptionelle Übersicht über die Methoden zur Attribution von Features, die mit Vertex AI verfügbar sind. Eine ausführliche technische Erläuterung finden Sie in unserem Whitepaper zu AI Explanations.
Die globale Featurewichtigkeit (Modell-Featureattributionen) zeigt, wie stark sich jedes Feature auf ein Modell auswirkt. Die Werte werden für jedes Feature als Prozentsatz angegeben. Je höher der Prozentsatz, desto stärker wirkt sich das Feature auf das Modelltraining aus. Prüfen Sie die Bewertungsmesswerte, um die globale Featurewichtigkeit für Ihr Modell zu sehen.
Lokale Feature-Attributionen für Zeitreihenmodelle geben an, wie viel die einzelnen Features in den Daten zum vorhergesagten Ergebnis beigetragen haben. Anhand dieser Informationen können Sie prüfen, ob sich das Modell wie erwartet verhält, Verzerrungen in Ihren Modellen erkennen und Ideen zur Verbesserung Ihres Modells und Ihrer Trainingsdaten erhalten. Wenn Sie Inferenzanfragen stellen, erhalten Sie entsprechende vorhergesagte Werte für Ihr Modell. Wenn Sie Erläuterungen anfordern, erhalten Sie die Inferenz zusammen mit Informationen zur Feature-Attribution.
Beispiel: Ein neuronales Deep-Learning-Netzwerk wird trainiert, um die Dauer einer Fahrradtour auf Basis von Wetterdaten und älteren Freigabedaten vorherzusagen. Wenn Sie nur Vorhersagen von diesem Modell anfordern, erhalten Sie die vorhergesagte Dauer von Fahrradtouren in Minuten. Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Fahrzeit sowie einen Attributionswert für jedes Feature in Ihrer Erläuterungsanfrage. Die Attributionswerte geben an, wie stark sich das Feature relativ zum von Ihnen angegebenen Referenzwert auf die Änderung des Inferenzwerts auswirkt. Wählen Sie eine aussagekräftige Referenz für Ihr Modell aus. In diesem Fall die mittlere Fahrtzeit.
Sie können die Feature-Attributionswerte grafisch darstellen, um zu sehen, welche Features am stärksten zur resultierenden Inferenz beigetragen haben:
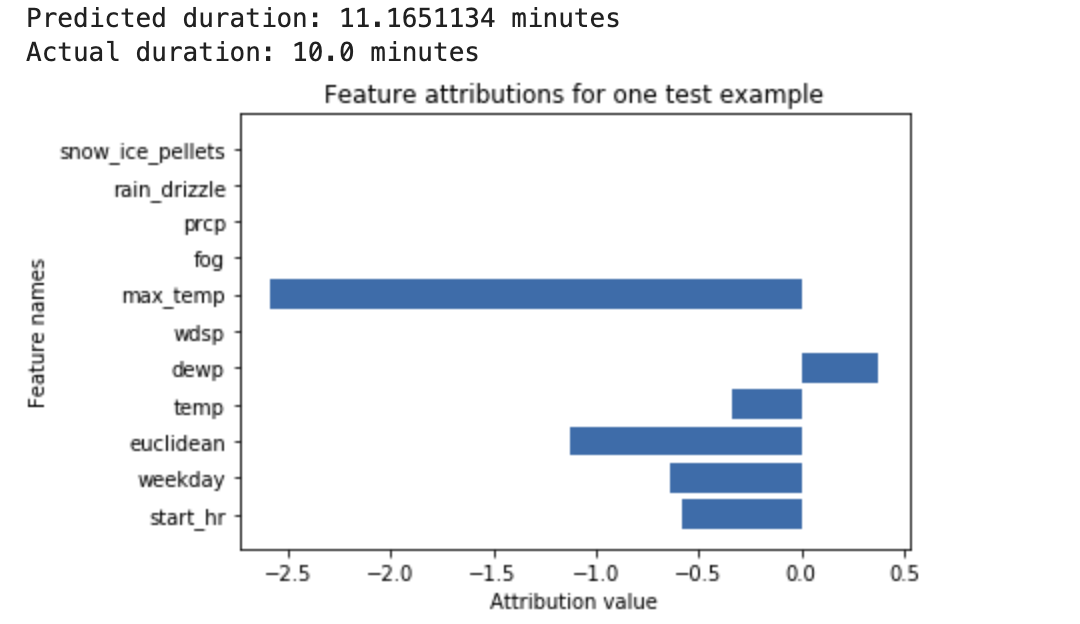
Lokale Feature-Attributionen generieren und abfragen, wenn Sie einen Online-Inferenzjob oder einen Batch-Inferenzjob ausführen.
Vorteile
Wenn Sie bestimmte Instanzen prüfen und darüber hinaus Feature-Attributionen in Ihrem Trainings-Dataset erzeugen, erhalten Sie genauere Einblicke in die Funktionsweise Ihres Modells. Beachten Sie die folgenden Vorteile:
Fehlerbehebungsmodelle: Mithilfe von Feature-Attributionen können Probleme in den Daten erkannt werden, die mit den Standardtechniken der Modellbewertung in der Regel nicht ermittelt werden.
Modelle optimieren: Sie können weniger wichtige Features identifizieren und entfernen, was zu effizienteren Modellen führt.
Konzeptionelle Einschränkungen
Berücksichtigen Sie die folgenden Einschränkungen für Attributionen von Attributen:
Feature-Attributionen, einschließlich der lokalen Merkmalwichtigkeit für AutoML, gelten für einzelne Inferenzen. Die Prüfung der Feature-Attributionen für eine einzelne Inferenz bietet möglicherweise einen guten Einblick, aber die Informationen sind eventuell nicht für die gesamte Klasse dieser einzelnen Instanz oder für das gesamte Modell verallgemeinerbar.
Verallgemeinerbare Informationen zu AutoML-Modellen finden Sie in der Merkmalwichtigkeit des Modells. Für verallgemeinerbare Informationen zu anderen Modellen aggregieren Sie Attributionen für Teilmengen des Datasets oder für das gesamte Dataset.
Jede Attribution zeigt nur an, wie stark sich das Feature auf die Inferenz für dieses bestimmte Beispiel auswirkt. Eine einzelne Attribution spiegelt unter Umständen nicht das Gesamtverhalten des Modells wider. Aggregieren Sie Attributionen für das gesamte Dataset, um das ungefähre Modellverhalten für ein gesamtes Dataset zu verstehen.
Obwohl Feature-Attributionen bei der Fehlerbehebung für Modelle hilfreich sein können, geben sie nicht immer deutlich genug an, ob ein Problem durch das Modell oder die Daten entsteht, auf denen das Modell trainiert wird. Gehen Sie nach bestem Wissen vor und diagnostizieren Sie häufige Datenprobleme, um mögliche Ursachen zu minimieren.
Die Attributionen hängen vollständig vom Modell und den Daten ab, die zum Trainieren des Modells verwendet werden. Sie können nur die Muster erkennen, die vom Modell in den Daten gefunden wurden, keine grundlegenden Beziehungen in den Daten. Das Vorhandensein oder Fehlen einer starken Attribution zu einem bestimmten Feature bedeutet also nicht, dass eine Beziehung zwischen diesem Feature und dem Ziel besteht. Die Attribution zeigt lediglich, dass das Modell das Feature in seinen Inferenzen verwendet oder nicht.
Mit Attributionen allein lässt sich nicht feststellen, ob Ihr Modell angemessen, verzerrungsfrei oder von guter Qualität ist. Prüfen Sie Ihre Trainingsdaten und Evaluierungsmesswerte zusätzlich zu den Attributionen sorgfältig.
Weitere Informationen zu Einschränkungen finden Sie im Whitepaper zu AI Explanations.
Featureattributionen verbessern
Die folgenden Faktoren haben die größte Auswirkung auf Featureattributionen:
- Die Attributionsmethoden entsprechen ungefähr dem Shapley-Wert. Sie können die Genauigkeit der Näherung erhöhen, indem Sie die Anzahl der Pfade für die Stichproben-Shapley-Methode erhöhen. Dadurch können sich die Attributionen drastisch ändern.
- Die Attributionen geben nur an, wie stark sich das Feature auf die Änderung des Inferenzwerts relativ zum Baselinewert auswirkt. Wählen Sie eine aussagekräftige Baseline, die für die Frage, die Sie dem Modell stellen, relevant ist. Die Attributionswerte und ihre Interpretation können sich erheblich ändern, wenn Sie Baselines wechseln.
Algorithmus
Vertex AI bietet Feature-Attributionen unter Verwendung von Shapley Values, einem kooperativen Spieltheorie-Algorithmus, der jedem Spieler in einem Spiel eine Gewichtung für ein bestimmtes Ergebnis zuweist. Auf ML-Modelle angewendet bedeutet dies, dass jedes Modell-Feature als „Spieler“ im Spiel behandelt wird und eine proportionale Gewichtung für das Ergebnis einer bestimmten Inferenz erhält. Vertex AI verwendet für strukturierte Datenmodelle eine Stichprobenapproximation für exakte Shapley-Werte, die Sampled Shapley genannt werden.
Ausführliche Informationen zur Sampled-Shapley-Methode finden Sie im Artikel Bounding the Emulationation Error of Sampling-based Shapley Value Approximation (nur auf Englisch verfügbar).
Nächste Schritte
Die folgenden Ressourcen bieten weitere nützliche Lehrmaterialien: