Este guia para principiantes é uma introdução à preparação personalizada no Vertex AI. A preparação personalizada refere-se à preparação de um modelo através de uma framework de ML, como o TensorFlow, o PyTorch ou o XGBoost.
Objetivos de aprendizagem
Nível de experiência do Vertex AI: principiante
Tempo de leitura estimado: 15 minutos
O que vai aprender:
- Vantagens da utilização de um serviço gerido para preparação personalizada.
- Práticas recomendadas para a preparação do código de preparação.
- Como enviar e monitorizar uma tarefa de preparação.
Por que motivo deve usar um serviço de preparação gerido?
Imagine que está a trabalhar num novo problema de ML. Abre um notebook, importa os seus dados e executa a experimentação. Neste cenário, cria um modelo com a estrutura de ML à sua escolha e executa células do bloco de notas para executar um ciclo de preparação. Quando a preparação estiver concluída, avalie os resultados do modelo, faça alterações e, em seguida, volte a executar a preparação. Este fluxo de trabalho é útil para a experimentação, mas, à medida que começa a pensar em criar aplicações de produção com ML, pode descobrir que a execução manual das células do seu bloco de notas não é a opção mais conveniente.
Por exemplo, se o conjunto de dados e o modelo forem grandes, pode experimentar a preparação distribuída. Além disso, num ambiente de produção, é improvável que só precise de formar o modelo uma vez. Ao longo do tempo, volta a formar o modelo para se certificar de que se mantém atualizado e continua a produzir resultados valiosos. Quando quiser automatizar a experimentação em grande escala ou voltar a preparar modelos para uma aplicação de produção, a utilização de um serviço de preparação de ML gerido simplifica os seus fluxos de trabalho.
Este guia apresenta uma introdução à preparação de modelos personalizados no Vertex AI. Uma vez que o serviço de preparação é totalmente gerido, o Vertex AI aprovisiona automaticamente recursos de computação, executa a tarefa de preparação e garante a eliminação dos recursos de computação assim que a tarefa de preparação estiver concluída. Tenha em atenção que existem personalizações, funcionalidades e formas adicionais de interagir com o serviço que não são abordadas aqui. Este guia destina-se a fornecer uma vista geral. Para mais detalhes, consulte a documentação do Vertex AI Training.
Vista geral da formação personalizada
A preparação de modelos personalizados no Vertex AI segue este fluxo de trabalho padrão:
Empacote o código da aplicação de preparação.
Configure e envie uma tarefa de preparação personalizada.
Monitorize a tarefa de preparação personalizada.
Código da aplicação de formação sobre embalagens
A execução de uma tarefa de preparação personalizada no Vertex AI é feita com contentores. Os contentores são pacotes do código da sua aplicação, neste caso, o código de preparação, juntamente com dependências, como versões específicas de bibliotecas necessárias para executar o seu código. Além de ajudar na gestão de dependências, os contentores podem ser executados praticamente em qualquer lugar, o que permite uma maior portabilidade. A criação de um pacote do código de preparação com os respetivos parâmetros e dependências num contentor para criar um componente portátil é um passo importante quando move as suas aplicações de ML do protótipo para a produção.
Antes de poder iniciar uma tarefa de preparação personalizada, tem de criar um pacote da sua aplicação de preparação. Neste caso, a aplicação de preparação refere-se a um ficheiro ou a vários ficheiros que executam tarefas como carregar dados, pré-processar dados, definir um modelo e executar um ciclo de preparação. O serviço de preparação do Vertex AI executa qualquer código que fornecer, pelo que depende inteiramente de si os passos que inclui na sua aplicação de preparação.
O Vertex AI oferece contentores pré-criados para o TensorFlow, o PyTorch, o XGBoost e o Scikit-learn. Estes contentores são atualizados regularmente e incluem bibliotecas comuns que pode precisar no seu código de preparação. Pode optar por executar o seu código de preparação com um destes contentores ou criar um contentor personalizado com o seu código de preparação e dependências pré-instaladas.
Existem três opções para criar pacotes do seu código no Vertex AI:
- Envie um único ficheiro Python.
- Crie uma distribuição de origem do Python.
- Use contentores personalizados.
Ficheiro Python
Esta opção é adequada para experimentação rápida. Pode usar esta opção se todo o código necessário para executar a sua aplicação de preparação estiver num ficheiro Python e um dos contentores de preparação do Vertex AI pré-criados tiver todas as bibliotecas necessárias para executar a sua aplicação. Para ver um exemplo de como criar um pacote da sua aplicação de preparação como um único ficheiro Python, consulte o tutorial do bloco de notas Preparação personalizada e inferência em lote.
Distribuição de origem do Python
Pode criar uma distribuição de origem Python que contenha a sua aplicação de preparação. Armazena a distribuição de origem com o código de preparação e as dependências num contentor do Cloud Storage. Para ver um exemplo de como criar um pacote da sua aplicação de preparação como uma distribuição de origem do Python, consulte o tutorial do bloco de notas Preparar, otimizar e implementar um modelo de classificação do PyTorch.
Contentor personalizado
Esta opção é útil quando quer ter mais controlo sobre a sua aplicação ou quando quer executar código que não foi escrito em Python. Neste caso, tem de escrever um Dockerfile, criar a sua imagem personalizada e enviá-la para o Artifact Registry. Para ver um exemplo de contentorização da sua aplicação de preparação, consulte o tutorial do bloco de notas Crie um perfil do desempenho da preparação de modelos com o Profiler.
Estrutura da aplicação de preparação recomendada
Se optar por agrupar o seu código como uma distribuição de origem Python ou como um contentor personalizado, recomendamos que estruture a sua aplicação da seguinte forma:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Crie um diretório para armazenar todo o código da aplicação de preparação. Neste caso, training-application-dir. Este diretório contém um ficheiro setup.py se estiver a usar uma distribuição de origem do Python ou um ficheiro Dockerfile se estiver a usar um contentor personalizado.
Em ambos os cenários, este diretório de nível superior também contém um subdiretório
trainer, que contém todo o código para executar a preparação. Em trainer,
task.py é o ponto de entrada principal da sua aplicação. Este ficheiro executa o
preparação de modelos. Pode optar por colocar todo o código neste ficheiro, mas para aplicações de produção, é provável que tenha ficheiros adicionais, por exemplo, model.py, data.py e utils.py, entre outros.
Executar treino personalizado
As tarefas de preparação na Vertex AI aprovisionam automaticamente recursos de computação, executam o código da aplicação de preparação e garantem a eliminação dos recursos de computação assim que a tarefa de preparação estiver concluída.
À medida que cria fluxos de trabalho mais complicados, é provável que use o SDK Vertex AI para Python para configurar, enviar e monitorizar as suas tarefas de preparação. No entanto, na primeira vez que executar uma tarefa de preparação personalizada, pode ser mais fácil usar a Google Cloud consola.
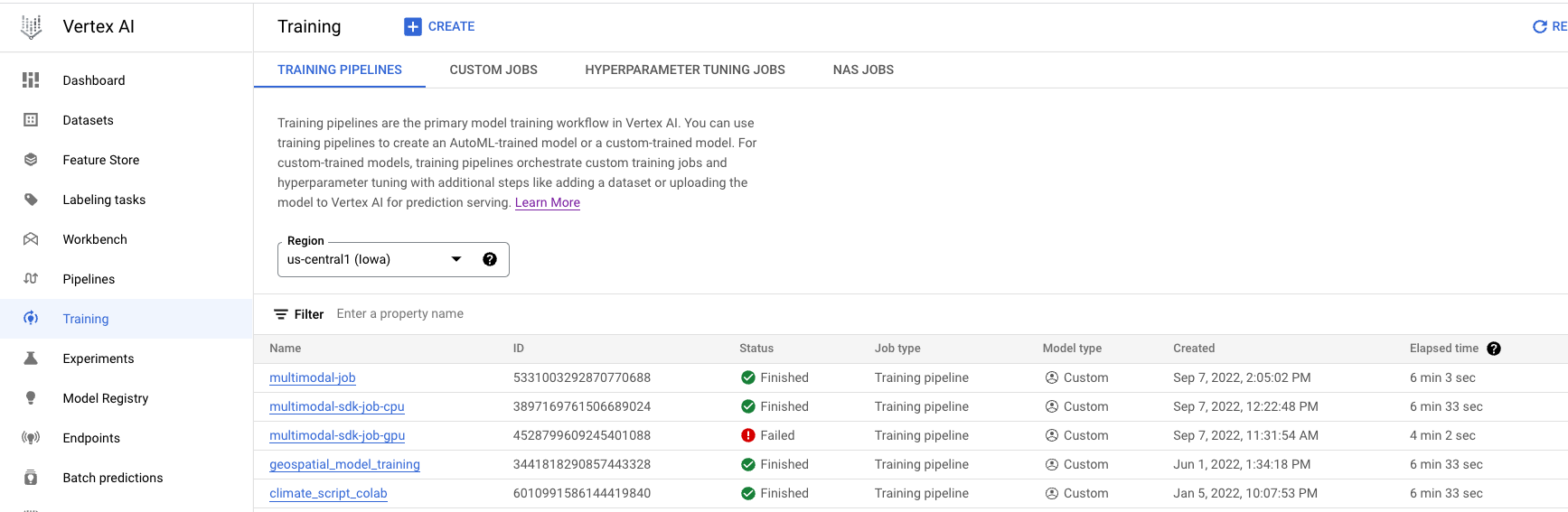
- Navegue para Preparação na secção Vertex AI da Cloud Console. Pode criar uma nova tarefa de preparação clicando no botão CRIAR.

- Em Método de preparação do modelo, selecione Preparação personalizada (avançada).

- Na secção Contentor de preparação, selecione o contentor pré-criado ou personalizado, consoante a forma como preparou a sua aplicação.
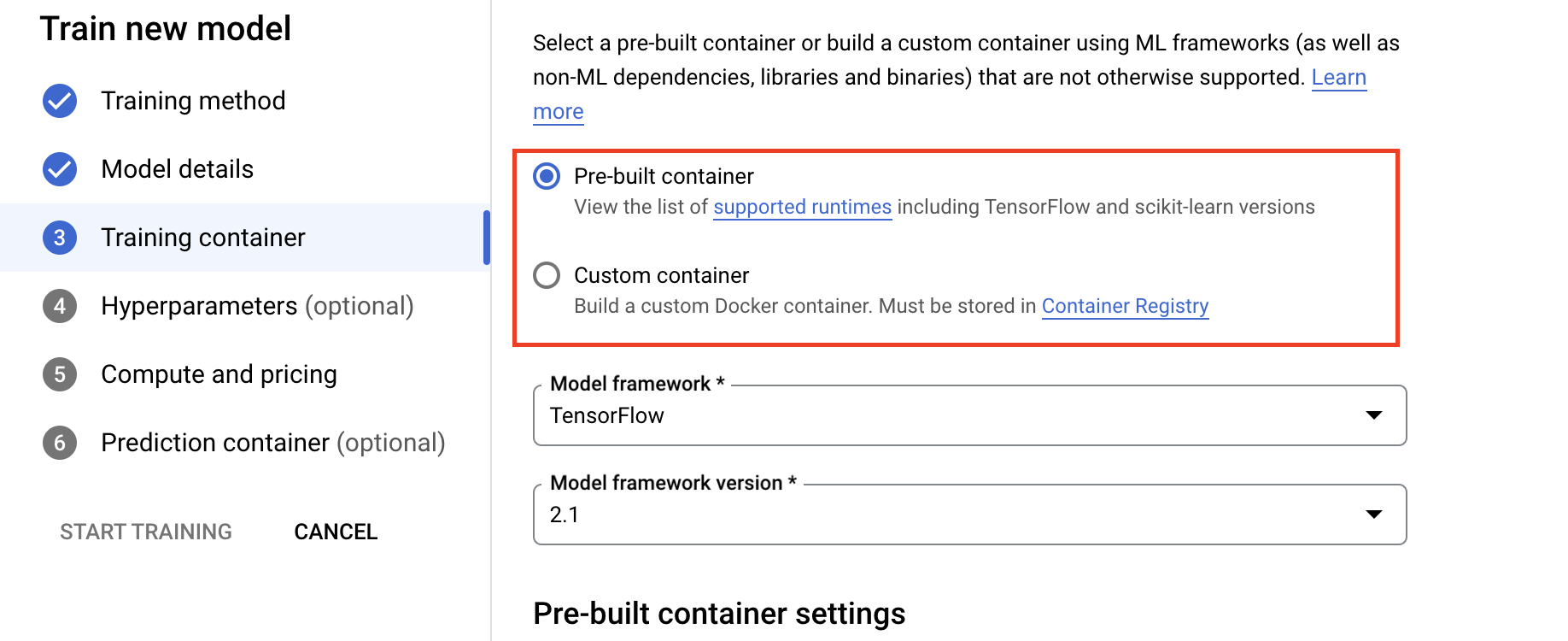
- Em Computação e preços, especifique o hardware para a tarefa de preparação. Para a formação de nó único, só precisa de configurar o Worker Pool 0. Se tiver interesse em executar a preparação distribuída, tem de compreender os outros conjuntos de trabalhadores. Pode saber mais sobre a preparação distribuída.

A configuração do contentor de inferência é opcional. Se quiser apenas preparar um modelo no Vertex AI e aceder aos artefactos do modelo guardado resultantes, pode ignorar este passo. Se quiser alojar e implementar o modelo resultante no serviço de inferência gerido do Vertex AI, tem de configurar um contentor de inferência. Para saber mais, consulte o artigo Obtenha inferências a partir de um modelo com preparação personalizada.
Monitorização de tarefas de preparação
Pode monitorizar a tarefa de preparação na Google Cloud consola. É apresentada uma lista de todas as tarefas que foram executadas. Pode clicar numa tarefa específica e examinar os registos se algo correr mal.