本部分介绍 Vertex AI 服务,它们可帮助您使用机器学习 (ML) 工作流实现机器学习操作 (MLOps)。
部署模型后,模型必须与环境中变化的数据保持同步,以获得最佳性能并保持相关性。MLOps 是一套有助于提高机器学习系统的稳定性和可靠性的做法。
Vertex AI MLOps 工具可帮助您与 AI 团队协作,并通过预测模型监控、提醒、诊断和具有可操作性的解释来改进模型。所有工具都是模块化的,因此您可以根据需要将它们集成到现有系统中。
如需详细了解 MLOps,请参阅机器学习中的持续交付和自动化流水线和 MLOps 从业人员指南。
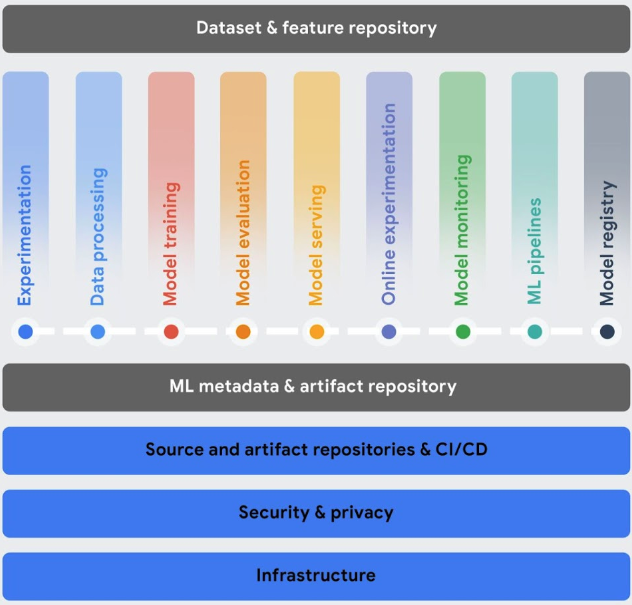
编排工作流:手动训练和应用模型可能非常耗时且容易出错,尤其是在您需要重复多次该过程时。
- Vertex AI Pipelines 可帮助您自动执行、监控和管理机器学习工作流。
跟踪在机器学习系统中使用的元数据:在数据科学中,跟踪在机器学习工作流中使用的参数、工件和指标非常重要,尤其是当您多次重复执行工作流时。
- 通过 Vertex ML Metadata,您可以记录在机器学习系统中使用的元数据、参数和工件。然后,您可以查询该元数据,以帮助分析、调试和审核机器学习系统或它所生成工件的性能。
确定使用场景的最佳模型:当您尝试新的训练算法时,您需要知道哪个经过训练的模型表现最佳。
借助 Vertex AI Experiments,您可以跟踪和分析不同的模型架构、超参数和训练环境,以确定最适合您的使用场景的模型。
Vertex AI TensorBoard 可帮助您跟踪、直观呈现和比较机器学习实验,以衡量模型的性能。
管理模型版本:将模型添加到中央代码库有助于您跟踪模型版本。
- Vertex AI Model Registry 提供了模型的概览,以便您可以更好地组织、跟踪和训练新版本。在 Model Registry 中,您可以评估模型、将模型部署到端点、创建批量推理以及查看有关特定模型和模型版本的详细信息。
管理功能:跨多个团队重复使用机器学习功能时,您需要快速、高效地共享和应用功能。
- Vertex AI Feature Store 提供了一个用于整理、存储和应用机器学习特征的集中式存储库。使用中央特征存储区,组织可以大规模地重复使用机器学习特征,并加快开发和部署新的机器学习应用的速度。
监控模型质量:在生产环境中部署的模型在使用与训练数据类似的推理输入数据时表现最佳。当输入数据与用于训练模型的数据存在差异时,即使模型本身未更改,模型的性能也会降低。
- Vertex AI Model Monitoring 会监控模型是否存在训练-应用偏差和推理偏移,并在传入的推理数据偏离训练基准太远时向您发送提醒。 您可以使用提醒和功能分布来评估是否需要重新训练模型。
扩缩 AI 和 Python 应用:Ray 是一种开源框架,可用于扩缩 AI 和 Python 应用。Ray 提供了用于为机器学习 (ML) 工作流执行分布式计算和并行处理的基础设施。
- Ray on Vertex AI 旨在让您能够使用相同的开源 Ray 代码在 Vertex AI 上编写程序和开发应用,并且只需极少的更改。然后,您可以在机器学习 (ML) 工作流中使用 Vertex AI 与其他 Google Cloud 服务(例如 Vertex AI Inference 和 BigQuery)的集成。