Ein Vertex AI-Modell wird standardmäßig auf seiner eigenen VM-Instanz bereitgestellt. Mit Vertex AI können auch mehrere Modelle in einer einzigen VM gehostet werden. Dies bietet folgende Möglichkeiten:
- Ressourcen für mehrere Bereitstellungen gemeinsam nutzen
- Kostengünstige Modellbereitstellung
- Verbesserte Auslastung von Speicher- und Rechenressourcen
In diesem Leitfaden wird die gemeinsame Nutzung von Ressourcen für mehrere Bereitstellungen in Vertex AI beschrieben.
Übersicht
Mit Unterstützung des Co-Hostings-Modells wird das Konzept eines DeploymentResourcePool eingeführt, der Modellbereitstellungen in Gruppen zusammenfasst, die Ressourcen innerhalb einer einzigen VM teilen. Innerhalb eines DeploymentResourcePool können mehrere Endpunkte auf derselben VM bereitgestellt werden. Jeder Endpunkt hat ein oder mehrere bereitgestellte Modelle. Die bereitgestellten Modelle für einen bestimmten Endpunkt können in demselben oder einem anderen DeploymentResourcePool gruppiert werden.
Im folgenden Beispiel gibt es vier Modelle und zwei Endpunkte:
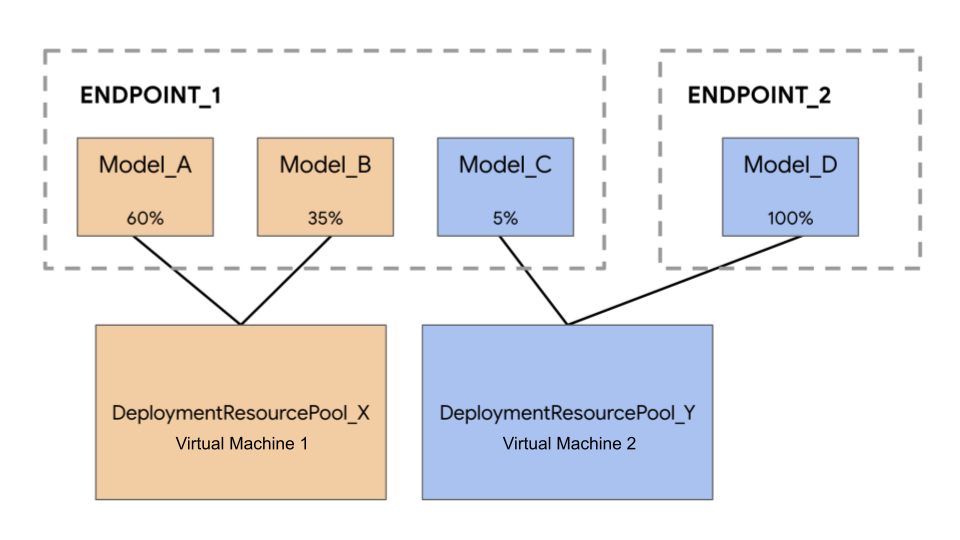
Model_A, Model_B und Model_C werden in Endpoint_1 bereitgestellt und der Traffic wird an alle weitergeleitet. Model_D wird für Endpoint_2 bereitgestellt, der 100 % des Traffics für diesen Endpunkt empfängt.
Statt jedes Modell einer eigenen VM zuzuweisen, können Sie Modelle auf eine der folgenden Arten gruppieren:
- Gruppieren Sie
Model_AundModel_B, um eine VM gemeinsam zu nutzen, wodurch sie Teil vonDeploymentResourcePool_Xsind. - Gruppieren Sie
Model_CundModel_D(derzeit nicht im selben Endpunkt), um eine VM gemeinsam zu nutzen, wodurch sie Teil vonDeploymentResourcePool_Ysind.
Unterschiedliche Deployment-Ressourcenpools können keine VM gemeinsam nutzen.
Hinweise
Es gibt keine Obergrenze für die Anzahl der Modelle, die in einem einzelnen Deployment-Ressourcenpool bereitgestellt werden können. Sie hängt von der ausgewählten VM-Form, den Modellgrößen und den Trafficmustern ab. Co-Hosting funktioniert gut, wenn Sie viele bereitgestellte Modelle mit geringem Traffic haben, sodass bei der Zuweisung einer dedizierten Maschine zu jedem bereitgestellten Modell Ressourcen nicht effizient genutzt werden.
Sie können Modelle gleichzeitig im selben Deployment-Ressourcenpool bereitstellen. Es gilt jedoch ein Limit von jeweils 20 gleichzeitigen Bereitstellungsanfragen.
Durch einen leeren Deployment-Ressourcenpool wird Ihr Ressourcenkontingent nicht verbraucht. Ressourcen werden in einem Deployment-Ressourcenpool bereitgestellt, wenn das erste Modell bereitgestellt wird, und freigegeben, wenn die Bereitstellung des letzten Modells aufgehoben wird.
Modelle in einem einzelnen Bereitstellungsressourcenpool sind nicht voneinander isoliert und können um CPU und Arbeitsspeicher konkurrieren. Die Leistung eines Modells kann schlechter sein, wenn ein anderes Modell gleichzeitig eine Inferenzanfrage verarbeitet.
Beschränkungen
Die folgenden Einschränkungen gelten bei der Bereitstellung von Modellen mit aktivierter Ressourcenfreigabe:
- Diese Funktion wird nur für die folgenden Konfigurationen unterstützt:
- TensorFlow-Modellbereitstellungen, die vordefinierte Container für TensorFlow verwenden
- PyTorch-Modellbereitstellungen, die vordefinierte Container für PyTorch verwenden
- Vordefinierte Container, die für andere Frameworks konfiguriert sind, werden nicht unterstützt.
- Benutzerdefinierte Container werden nicht unterstützt.
- Nur benutzerdefiniert trainierte Modelle und importierte Modelle werden unterstützt. AutoML-Modelle werden nicht unterstützt.
- Nur Modelle mit demselben Container-Image (einschließlich Framework-Version) vordefinierter Vertex AI-Container für die Inferenz für TensorFlow oder PyTorch können im selben Bereitstellungsressourcenpool bereitgestellt werden.
- Vertex Explainable AI wird nicht unterstützt.
Modell bereitstellen
Führen Sie die folgenden Schritte aus, um ein Modell in einem DeploymentResourcePool bereitzustellen:
- Erstellen Sie bei Bedarf einen Deployment-Ressourcenpool.
- Erstellen Sie bei Bedarf einen Endpunkt.
- Rufen Sie die Endpunkt-ID.
- Stellen Sie das Modell am Endpunkt im Deployment-Ressourcenpool bereit.
Deployment-Ressourcenpool erstellen
Wenn Sie ein Modell in einem vorhandenen DeploymentResourcePool bereitstellen, können Sie diesen Schritt überspringen:
Verwenden Sie CreateDeploymentResourcePool, um einen Ressourcenpool zu erstellen.
Cloud Console
Rufen Sie in der Google Cloud Console die Vertex AI-Seite Ressourcenpools für Bereitstellung auf.
Klicken Sie auf Erstellen und füllen Sie das Formular aus (siehe unten).

REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- LOCATION_ID: Die Region, in der Sie Vertex AI verwenden.
- PROJECT_ID: Ihre Projekt-ID.
-
MACHINE_TYPE: Optional. Die für jeden Knoten dieser Bereitstellung verwendeten Maschinenressourcen. Die Standardeinstellung ist
n1-standard-2. Weitere Informationen zu Maschinentypen. - ACCELERATOR_TYPE: Der Typ des Beschleunigers, der an die Maschine angehängt werden soll. Optional, wenn ACCELERATOR_COUNT nicht angegeben oder null ist. Nicht empfohlen für AutoML-Modelle oder benutzerdefinierte Modelle, die keine GPU-Images verwenden. Weitere Informationen
- ACCELERATOR_COUNT: Die Anzahl der Beschleuniger, die für jedes Replikat verwendet werden soll. Optional. Sollte für AutoML-Modelle oder benutzerdefiniert trainierte Modelle, die keine GPU-Images verwenden, null oder nicht angegeben sein.
- MIN_REPLICA_COUNT: Die minimale Anzahl von Knoten für diese Bereitstellung. Die Knotenzahl kann je nach der Inferenzlast erhöht oder verringert werden, bis zur maximalen Anzahl von Knoten und niemals auf weniger als diese Anzahl von Knoten. Dieser Wert muss größer oder gleich 1 sein.
- MAX_REPLICA_COUNT: Die maximale Anzahl von Knoten für diese Bereitstellung. Die Knotenzahl kann je nach der Inferenzlast erhöht oder verringert werden, bis zu dieser Anzahl von Knoten und niemals auf weniger als die minimale Anzahl von Knoten.
- REQUIRED_REPLICA_COUNT: Optional. Die erforderliche Anzahl von Knoten, damit diese Bereitstellung als erfolgreich markiert wird. Muss größer oder gleich 1 und kleiner oder gleich der Mindestanzahl von Knoten sein. Wenn keine Angabe erfolgt, ist der Standardwert die Mindestanzahl von Knoten.
-
DEPLOYMENT_RESOURCE_POOL_ID: Ein Name für Ihren
DeploymentResourcePool. Die maximale Länge beträgt 63 Zeichen. Folgende Zeichen sind gültig: /^[az]([a-z0-9-]{0,61}[a-z0-9])?$/.
HTTP-Methode und URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
JSON-Text anfordern:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten in etwa folgende JSON-Antwort erhalten:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
Sie können den Status des Vorgangs abfragen, bis in der Antwort "done": true angegeben wird.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
Ersetzen Sie Folgendes:
DEPLOYMENT_RESOURCE_POOL_ID: Ein Name für IhrenDeploymentResourcePool. Die maximale Länge beträgt 63 Zeichen. Folgende Zeichen sind gültig: /^[az]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE: Optional. Die für jeden Knoten dieser Bereitstellung verwendeten Maschinenressourcen. Der Standardwert istn1-standard-2. Weitere Informationen zu Maschinentypen.MIN_REPLICA_COUNT: Die Mindestanzahl von Knoten für diese Bereitstellung. Die Knotenzahl kann je nach der Inferenzlast erhöht oder verringert werden, bis zur maximalen Anzahl von Knoten und niemals auf weniger als diese Anzahl von Knoten. Dieser Wert muss größer oder gleich 1 sein.MAX_REPLICA_COUNT: Die maximale Anzahl von Knoten für diese Bereitstellung. Die Knotenzahl kann je nach der Inferenzlast erhöht oder verringert werden, bis zu dieser Anzahl von Knoten und niemals auf weniger als die minimale Anzahl von Knoten.
Endpunkt erstellen
Informationen zum Erstellen eines Endpunkts finden Sie unter Öffentlichen Endpunkt mit der gcloud CLI oder der Vertex AI API erstellen. Dieser Schritt ist mit der Bereitstellung eines einzelnen Modells identisch.
Endpunkt-ID abrufen
Informationen zum Abrufen der Endpunkt-ID finden Sie unter Modell mit der gcloud CLI oder der Vertex AI API bereitstellen. Dieser Schritt ist mit der Bereitstellung eines einzelnen Modells identisch.
Modell in einem Deployment-Ressourcenpool bereitstellen
Nachdem Sie einen DeploymentResourcePool und einen Endpunkt erstellt haben, können Sie mit der API-Methode DeployModel Bereitstellungen vornehmen. Dieser Vorgang ähnelt der Bereitstellung eines einzelnen Modells. Wenn ein DeploymentResourcePool vorhanden ist, geben Sie shared_resources von DeployModel durch den Ressourcennamen des DeploymentResourcePool an, den Sie bereitstellen.
Cloud Console
Rufen Sie in der Google Cloud Console die Seite Vertex AI Model Registry auf.
Suchen Sie das Modell und klicken Sie auf Auf Endpunkt bereitstellen.
Wählen Sie unter Modelleinstellungen (siehe unten) In einem gemeinsam genutzten Ressourcenpool für die Bereitstellung bereitstellen aus.

REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- LOCATION_ID: Die Region, in der Sie Vertex AI verwenden.
- PROJECT: Ihre Projekt-ID.
- ENDPOINT_ID: Die ID des Endpunkts.
- MODEL_ID: Die ID des bereitzustellenden Modells.
-
DEPLOYED_MODEL_NAME: Ein Name für
DeployedModel. Sie können auch den Anzeigenamen vonModelfürDeployedModelverwenden. -
DEPLOYMENT_RESOURCE_POOL_ID: Ein Name für Ihren
DeploymentResourcePool. Die maximale Länge beträgt 63 Zeichen. Folgende Zeichen sind gültig: /^[az]([a-z0-9-]{0,61}[a-z0-9])?$/. - TRAFFIC_SPLIT_THIS_MODEL: Der Prozentsatz des Vorhersagetraffics an diesen Endpunkt, der an das Modell mit diesem Vorgang weitergeleitet werden soll. Die Standardeinstellung ist 100. Alle Traffic-Prozentsätze müssen zusammen 100 % ergeben. Weitere Informationen zu Traffic-Splits
- DEPLOYED_MODEL_ID_N: Optional. Wenn andere Modelle für diesen Endpunkt bereitgestellt werden, müssen Sie die Prozentsätze der Trafficaufteilung aktualisieren, sodass alle Prozentsätze zusammen 100 % ergeben.
- TRAFFIC_SPLIT_MODEL_N: Der Prozentwert der Trafficaufteilung für den bereitgestellten Modell-ID-Schlüssel.
- PROJECT_NUMBER: Die automatisch generierte Projektnummer Ihres Projekts.
HTTP-Methode und URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
JSON-Text anfordern:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
Ersetzen Sie MODEL_ID durch die ID des bereitzustellenden Modells.
Wiederholen Sie die obige Anfrage mit verschiedenen Modellen mit denselben gemeinsam genutzten Ressourcen, um mehrere Modelle im selben Deployment-Ressourcenpool bereitzustellen.
Schlussfolgerungen ziehen
Sie können Inferenzanfragen an ein Modell in einem DeploymentResourcePool auf die gleiche Weise senden, wie bei jedem anderen in Vertex AI bereitgestellten Modell.