Por predefinição, um modelo da Vertex AI é implementado na sua própria instância de máquina virtual (VM). A Vertex AI oferece a capacidade de alojar modelos em conjunto na mesma VM, o que permite as seguintes vantagens:
- Partilha de recursos em várias implementações.
- Serviço de modelos rentável.
- Utilização melhorada da memória e dos recursos computacionais.
Este guia descreve como partilhar recursos em várias implementações no Vertex AI.
Vista geral
O suporte de alojamento conjunto de modelos introduz o conceito de DeploymentResourcePool, que agrupa implementações de modelos que partilham recursos numa única VM. É possível implementar vários pontos finais na mesma VM num DeploymentResourcePool. Cada ponto final tem um ou mais modelos implementados. Os modelos implementados para um determinado ponto final podem ser agrupados no mesmo DeploymentResourcePool ou num diferente.
No exemplo seguinte, tem quatro modelos e dois pontos finais:
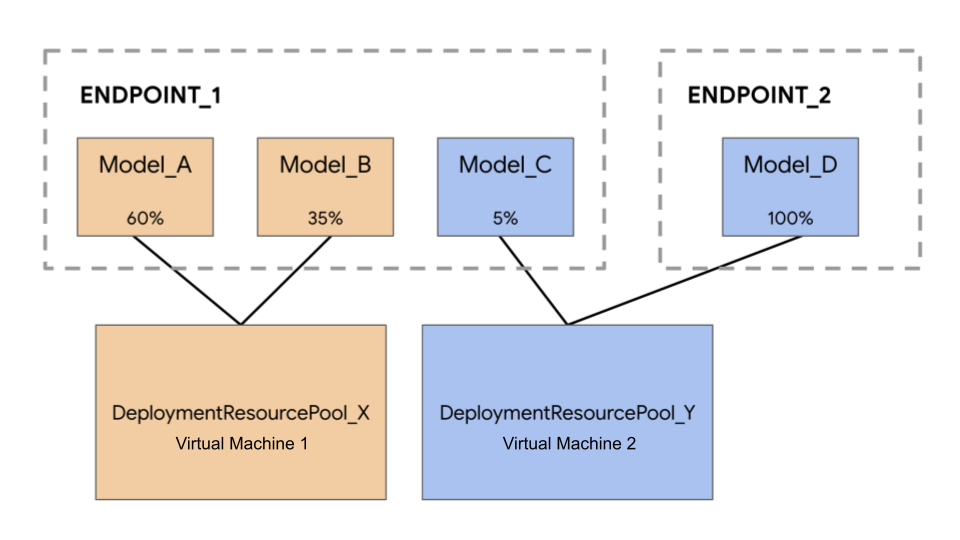
Model_A, Model_B e Model_C são implementados em Endpoint_1 com tráfego encaminhado para todos eles. Model_D é implementado em Endpoint_2, que recebe 100% do tráfego para esse ponto final.
Em vez de ter cada modelo atribuído a uma VM separada, pode agrupar os modelos de uma das seguintes formas:
- Agrupe
Model_AeModel_Bpara partilhar uma VM, o que os torna parte deDeploymentResourcePool_X. - Agrupe
Model_CeModel_D(atualmente não no mesmo ponto final) para partilhar uma VM, o que os torna parte deDeploymentResourcePool_Y.
Os diferentes conjuntos de recursos de implementação não podem partilhar uma VM.
Considerações
Não existe um limite superior para o número de modelos que podem ser implementados num único conjunto de recursos de implementação. Depende do formato da VM escolhido, dos tamanhos dos modelos e dos padrões de tráfego. A coorganização funciona bem quando tem muitos modelos implementados com tráfego esparso, de modo que a atribuição de uma máquina dedicada a cada modelo implementado não usa os recursos de forma eficaz.
Pode implementar modelos no mesmo conjunto de recursos de implementação em simultâneo. No entanto, existe um limite de 20 pedidos de implementação simultâneos em qualquer momento.
Um conjunto de recursos de implementação vazio não consome a sua quota de recursos. Os recursos são aprovisionados para um conjunto de recursos de implementação quando o primeiro modelo é implementado e são libertados quando o último modelo é desimplementado.
Os modelos num único conjunto de recursos de implementação não estão isolados uns dos outros e podem estar em competição pela CPU e pela memória. O desempenho pode ser pior para um modelo se outro modelo estiver a processar um pedido de inferência ao mesmo tempo.
Limitações
Existem as seguintes limitações quando implementa modelos com a partilha de recursos ativada:
- Esta funcionalidade só é suportada para as seguintes configurações:
- Implementações de modelos do TensorFlow que usam contentores pré-criados para o TensorFlow
- Implementações de modelos do PyTorch que usam contentores pré-criados para o PyTorch
- Os contentores pré-criados configurados para outras frameworks não são suportados.
- Os contentores personalizados não são suportados.
- Apenas são suportados modelos personalizados treinados e modelos importados. Os modelos do AutoML não são suportados.
- Só é possível implementar modelos com a mesma imagem de contentor (incluindo a versão da framework) dos contentores pré-criados do Vertex AI para inferência para o TensorFlow ou o PyTorch no mesmo conjunto de recursos de implementação.
- O Vertex Explainable AI não é suportado.
Implemente um modelo
Para implementar um modelo num DeploymentResourcePool, conclua os seguintes passos:
- Crie um conjunto de recursos de implementação, se necessário.
- Crie um ponto final, se necessário.
- Obtenha o ID do ponto final.
- Implemente o modelo no ponto final no conjunto de recursos de implementação.
Crie um conjunto de recursos de implementação
Se estiver a implementar um modelo num DeploymentResourcePool existente, ignore este passo:
Use CreateDeploymentResourcePool para criar um conjunto de recursos.
Cloud Console
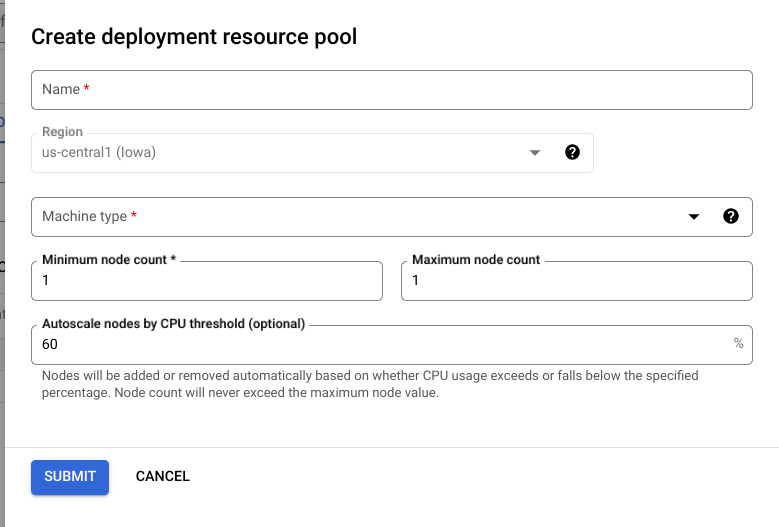
Na Google Cloud consola, aceda à página Pools de recursos de implementação do Vertex AI.
Clique em Criar e preencha o formulário (mostrado abaixo).
REST
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- LOCATION_ID: a região onde está a usar o Vertex AI.
- PROJECT_ID: o seu ID do projeto.
-
MACHINE_TYPE: opcional. Os recursos da máquina usados para cada nó desta implementação. A predefinição é
n1-standard-2. Saiba mais sobre os tipos de máquinas. - ACCELERATOR_TYPE: o tipo de acelerador a anexar à máquina. Opcional se ACCELERATOR_COUNT não for especificado ou for zero. Não recomendado para modelos do AutoML ou modelos preparados personalizados que estejam a usar imagens sem GPU. Saiba mais.
- ACCELERATOR_COUNT: o número de aceleradores que cada réplica deve usar. Opcional. Deve ser zero ou não especificado para modelos AutoML ou modelos preparados personalizados que estão a usar imagens não GPU.
- MIN_REPLICA_COUNT: o número mínimo de nós para esta implementação. O número de nós pode ser aumentado ou diminuído conforme necessário pela carga de inferência, até ao número máximo de nós e nunca inferior a este número de nós. Este valor tem de ser igual ou superior a 1.
- MAX_REPLICA_COUNT: o número máximo de nós para esta implementação. O número de nós pode ser aumentado ou diminuído conforme necessário pela carga de inferência, até este número de nós e nunca inferior ao número mínimo de nós.
- REQUIRED_REPLICA_COUNT: opcional. O número necessário de nós para que esta implementação seja marcada como bem-sucedida. Tem de ser igual ou superior a 1 e inferior ou igual ao número mínimo de nós. Se não for especificado, o valor predefinido é o número mínimo de nós.
-
DEPLOYMENT_RESOURCE_POOL_ID: um nome para o seu
DeploymentResourcePool. O comprimento máximo é de 63 carateres e os carateres válidos são /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.
Método HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
Corpo JSON do pedido:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
Pode sondar o estado da operação até que a resposta inclua "done": true.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
Substitua o seguinte:
DEPLOYMENT_RESOURCE_POOL_ID: um nome para o seuDeploymentResourcePool. O comprimento máximo é de 63 carateres e os carateres válidos são /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE: opcional. Os recursos da máquina usados para cada nó desta implementação. O valor predefinido én1-standard-2. Saiba mais sobre os tipos de máquinas.MIN_REPLICA_COUNT: o número mínimo de nós para esta implementação. O número de nós pode ser aumentado ou diminuído conforme necessário pela carga de inferência, até ao número máximo de nós e nunca inferior a este número de nós. Este valor tem de ser igual ou superior a 1.MAX_REPLICA_COUNT: o número máximo de nós para esta implementação. O número de nós pode ser aumentado ou diminuído conforme necessário pela carga de inferência, até este número de nós e nunca inferior ao número mínimo de nós.
Crie um ponto final
Para criar um ponto final, consulte o artigo Crie um ponto final público através da CLI gcloud ou da API Vertex AI. Este passo é igual ao de uma implementação de modelo único.
Obtenha o ID do ponto final
Para obter o ID do ponto final, consulte o artigo Implemente um modelo através da CLI gcloud ou da API Vertex AI. Este passo é igual ao de uma implementação de modelo único.
Implemente o modelo num conjunto de recursos de implementação
Depois de criar um DeploymentResourcePool e um ponto final, tem tudo pronto para a implementação através do método da API DeployModel. Este processo é semelhante a uma implementação de modelo único. Se existir um DeploymentResourcePool, especifique o shared_resources de DeployModel com o nome do recurso do DeploymentResourcePool que está a implementar.
Cloud Console
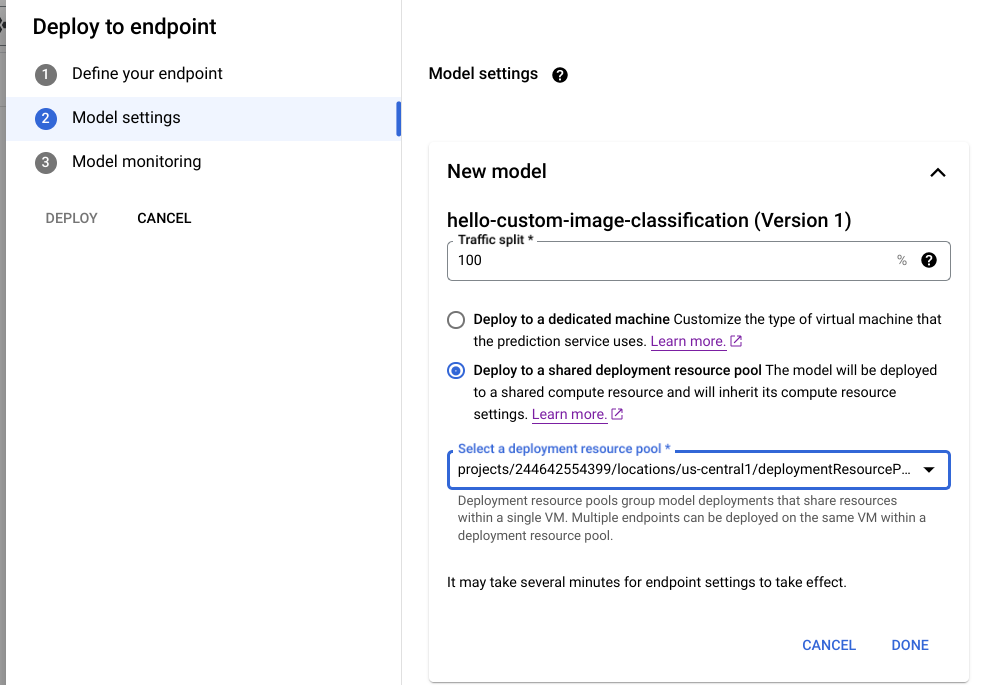
Na Google Cloud consola, aceda à página do Registo de modelos do Vertex AI.
Encontre o seu modelo e clique em Implementar no ponto final.
Em Definições do modelo (mostradas abaixo), selecione Implementar num conjunto de recursos de implementação partilhados.
REST
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- LOCATION_ID: a região onde está a usar o Vertex AI.
- PROJECT: o seu ID do projeto.
- ENDPOINT_ID: o ID do ponto final.
- MODEL_ID: o ID do modelo a implementar.
-
DEPLOYED_MODEL_NAME: um nome para o
DeployedModel. Também pode usar o nome a apresentar doModelpara oDeployedModel. -
DEPLOYMENT_RESOURCE_POOL_ID: um nome para o seu
DeploymentResourcePool. O comprimento máximo é de 63 carateres e os carateres válidos são /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/. - TRAFFIC_SPLIT_THIS_MODEL: A percentagem do tráfego de previsão para este ponto final a encaminhar para o modelo implementado com esta operação. A predefinição é 100. Todas as percentagens de tráfego têm de totalizar 100. Saiba mais acerca das divisões de tráfego.
- DEPLOYED_MODEL_ID_N: opcional. Se outros modelos forem implementados neste ponto final, tem de atualizar as respetivas percentagens de divisão de tráfego para que todas as percentagens totalizem 100.
- TRAFFIC_SPLIT_MODEL_N: o valor da percentagem da divisão de tráfego para a chave do ID do modelo implementado.
- PROJECT_NUMBER: o número do projeto gerado automaticamente do seu projeto
Método HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
Corpo JSON do pedido:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
Substitua MODEL_ID pelo ID do modelo a implementar.
Repita o pedido anterior com modelos diferentes que tenham os mesmos recursos partilhados para implementar vários modelos no mesmo conjunto de recursos de implementação.
Obtenha inferências
Pode enviar pedidos de inferência para um modelo num DeploymentResourcePool, tal como faria para qualquer outro modelo implementado no Vertex AI.