Vertex AI 模型默认部署到其自己的虚拟机实例。Vertex AI 提供在同一虚拟机上共同托管多个模型的功能,这具有以下优势:
- 跨多个部署共享资源。
- 经济实惠的模型部署。
- 更高的内存和计算资源利用率。
本指南介绍如何在 Vertex AI 上跨多个部署共享资源。
概览
模型共同托管支持引入了 DeploymentResourcePool 的概念,它将共享同一个虚拟机中资源的模型部署分组到一起。您可以在 DeploymentResourcePool 内的同一虚拟机上部署多个端点。每个端点都有一个或多个已部署的模型。给定端点的已部署模型可以分组到相同或不同的 DeploymentResourcePool 下。
在以下示例中,您有四个模型和两个端点:
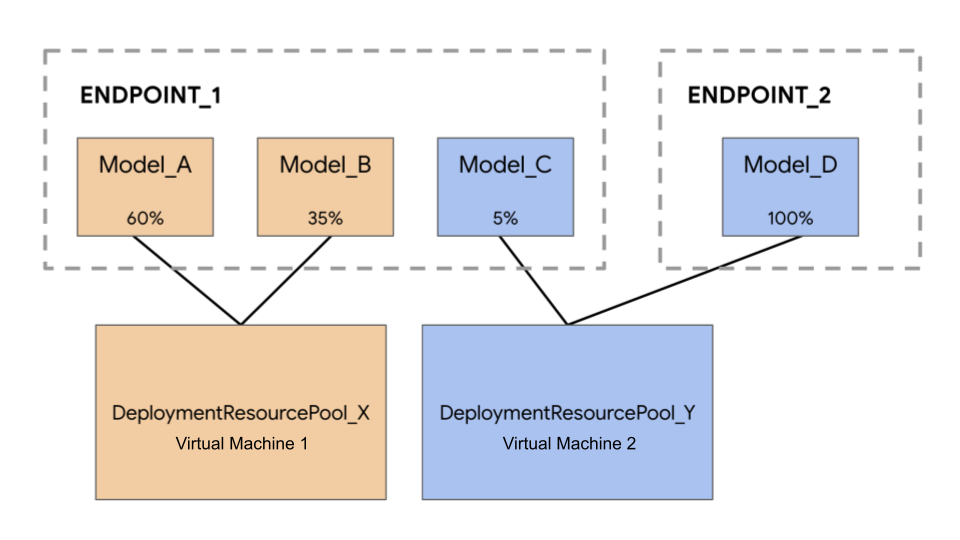
Model_A、Model_B 和 Model_C 部署到 Endpoint_1,并且流量会路由到所有这些模型。Model_D 部署到 Endpoint_2,它接收该端点的全部流量。您可以按照以下某个方式将模型分组,而不是将每个模型分配给一个单独的虚拟机:
- 将
Model_A和Model_B分组到一起以共享一个虚拟机,这使它们成为DeploymentResourcePool_X的一部分。 - 将
Model_C和Model_D(当前不在同一端点中)分组到一起以共享一个虚拟机,这使它们成为DeploymentResourcePool_Y的一部分。
不同的部署资源池不能共享一个虚拟机。
注意事项
可以部署到单个部署资源池的模型数量没有上限。这取决于所选虚拟机形式、模型大小和流量模式。如果多个已部署模型具有稀疏的流量,为每个已部署模型分配专用机器将无法有效利用资源,在这种情况下,共同托管非常实用。
您可以将模型并发地部署到同一部署资源池中。但在任何给定时刻,并发部署请求的数量不能超过 20 个。
空部署资源池不会占用您的资源配额。部署第一个模型时,资源会被预配到部署资源池;取消部署最后一个模型时,资源会被释放。
单个部署资源池中的模型彼此之间未隔离,并且可能会争夺 CPU 和内存。如果另一个模型同时处理推断请求,则一个模型的性能可能会变差。
限制
部署启用了资源共享的模型时,存在以下限制:
- 仅以下配置支持此功能:
- 使用 TensorFlow 预构建容器的 TensorFlow 模型部署
- 使用 PyTorch 预构建容器的 PyTorch 模型部署
- 不支持其他模型框架和自定义容器。
- 仅支持自定义训练的模型和导入的模型。不支持 AutoML 模型。
- 只有具有相同的用于 TensorFlow 或 PyTorch 预测的 Vertex AI 预构建容器的容器映像(包括框架版本)的模型才能部署到同一部署资源池中。
- 不支持 Vertex Explainable AI。
部署模型
如需将模型部署到 DeploymentResourcePool,请完成以下步骤:
创建部署资源池
如果您要将模型部署到现有 DeploymentResourcePool,请跳过此步骤:
使用 CreateDeploymentResourcePool 创建资源池。
Cloud Console
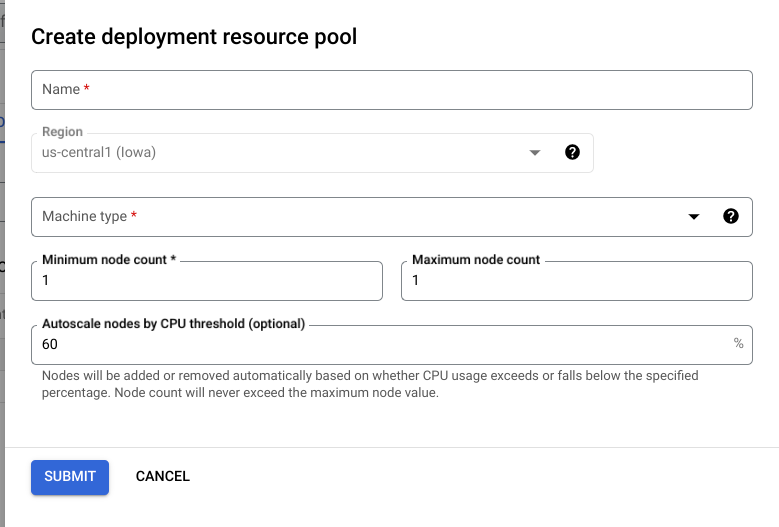
在 Google Cloud 控制台中,前往 Vertex AI 部署资源池页面。
点击创建,然后填写表单(如下所示)。
REST
在使用任何请求数据之前,请先进行以下替换:
- LOCATION_ID:您在其中使用 Vertex AI 的区域。
- PROJECT_ID:您的项目 ID。
-
MACHINE_TYPE:可选。用于此部署的每个节点的机器资源。其默认设置为
n1-standard-2。详细了解机器类型。 - ACCELERATOR_TYPE:要挂接到机器的加速器类型。如果未指定 ACCELERATOR_COUNT 或为零,则可选。建议不要用于使用非 GPU 映像的 AutoML 模型或自定义训练模型。了解详情。
- ACCELERATOR_COUNT:每个副本要使用的加速器数量。可选。对于使用非 GPU 映像的 AutoML 模型或自定义模型,应该为零或未指定。
- MIN_REPLICA_COUNT:此部署的最小节点数。 节点数可根据预测负载的需要而增加或减少,直至达到节点数上限并且绝不会少于此节点数。此值必须大于或等于 1。
- MAX_REPLICA_COUNT:此部署的节点数上限。 节点数可根据预测负载的需要而增加或减少,直至达到此节点数并且绝不会少于节点数下限。
-
DEPLOYMENT_RESOURCE_POOL_ID:您的
DeploymentResourcePool的名称。最大长度为 63 个字符,有效字符为 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/。
HTTP 方法和网址:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
请求 JSON 正文:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
您可以轮询操作状态,直到响应包含 "done": true。
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
替换以下内容:
DEPLOYMENT_RESOURCE_POOL_ID:您的DeploymentResourcePool的名称。最大长度为 63 个字符,有效字符为 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/。MACHINE_TYPE:可选。用于此部署的每个节点的机器资源。默认值为n1-standard-2。 详细了解机器类型。MIN_REPLICA_COUNT:此部署的最小节点数。节点数可根据预测负载的需要而增加或减少,直至达到节点数上限并且绝不会少于此节点数。此值必须大于或等于 1。MAX_REPLICA_COUNT:此部署的节点数上限。节点数可根据预测负载的需要而增加或减少,直至达到此节点数并且绝不会少于节点数下限。
创建端点
如需创建端点,请参阅将模型部署到端点。此步骤与单模型部署相同。
检索端点 ID
如需检索端点 ID,请参阅将模型部署到端点。此步骤与单模型部署相同。
在部署资源池中部署模型
创建 DeploymentResourcePool 和端点后,您就可以使用 DeployModel API 方法进行部署。此过程与单模型部署类似。如果存在 DeploymentResourcePool,请使用您要部署的 DeploymentResourcePool 的资源名称指定 DeployModel 的 shared_resources。
Cloud Console
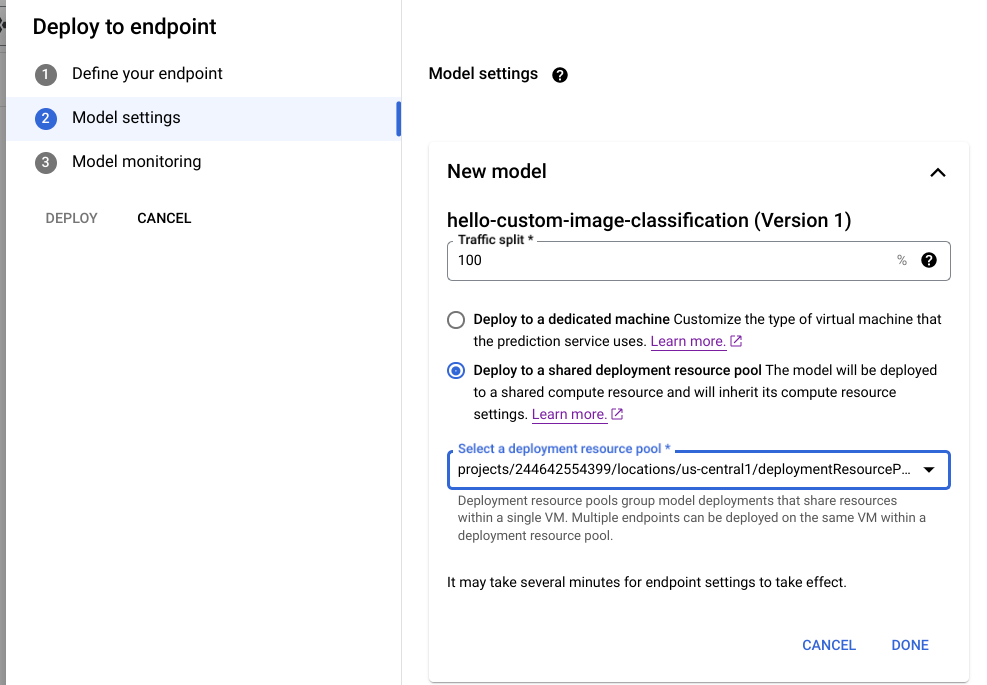
在 Google Cloud 控制台中,进入 Vertex AI Model Registry 页面。
找到您的模型,然后点击部署到端点。
在模型设置(如下所示)下,选择部署到共享部署资源池。
REST
在使用任何请求数据之前,请先进行以下替换:
- LOCATION_ID:您在其中使用 Vertex AI 的区域。
- PROJECT:您的项目 ID。
- ENDPOINT_ID:端点的 ID。
- MODEL_ID:要部署的模型的 ID。
-
DEPLOYED_MODEL_NAME:
DeployedModel的名称。您还可以将Model的显示名用于DeployedModel。 -
DEPLOYMENT_RESOURCE_POOL_ID:您的
DeploymentResourcePool的名称。最大长度为 63 个字符,有效字符为 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/。 - TRAFFIC_SPLIT_THIS_MODEL:流向此端点的要路由到使用此操作部署的模型的预测流量百分比。默认值为 100。所有流量百分比之和必须为 100。详细了解流量拆分。
- DEPLOYED_MODEL_ID_N:可选。如果将其他模型部署到此端点,您必须更新其流量拆分百分比,以便所有百分比之和等于 100。
- TRAFFIC_SPLIT_MODEL_N:已部署模型 ID 密钥的流量拆分百分比值。
- PROJECT_NUMBER:自动生成的项目编号
HTTP 方法和网址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
请求 JSON 正文:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
将 MODEL_ID 替换为要部署的模型的 ID。
使用具有相同共享资源的不同模型重复上述请求,以将多个模型部署到同一部署资源池中。
获取预测结果
您可以向 DeploymentResourcePool 中的模型发送预测请求,这与部署在 Vertex AI 上的任何其他模型是一样的。